AWS Database Blog
Building Financial Hierarchies with Amazon Neptune for Treasury Operations
In this post, we show how Amazon’s Finance Technology (FinTech) team uses Amazon Neptune to model complex corporate treasury structures as a property graph. These structures include the legal entity relationships, intercompany agreements, and bank account associations that govern payment routing and cash management. We walk through an iterative graph modeling approach, Gremlin (the graph traversal language supported by Neptune) query patterns for real-time payment routing, and a Primary/State node versioning pattern (where primary nodes hold current state and state nodes preserve history).
Large enterprises often manage hundreds of legal entities across dozens of countries, each with its own bank account, intercompany agreements, and payment rules. When a central treasury operation needs to determine which bank account to use for a payment, or trace the accounting path between two entities, the answer depends on traversing a hierarchy of relationships. These traversals sometimes span multiple hops with different rules at each level.
At Amazon, FinTech faced exactly this challenge. Amazon’s centralized treasury structure program manages hundreds of legal entities across multiple jurisdictions with dozens of banking partners and needed to resolve payment routing and accounting paths in real time. The relationships between these entities are not simple parent-child trees: they involve directional payment flows, bidirectional cash pooling, and eligibility rules that vary by entity and transaction type.
The business challenge
In a centralized treasury structure, the entity hierarchy connects central entities to member entities. A central entity can make payments or pool cash on behalf of its members. Each legal entity uses a company code (a short alphanumeric identifier), and intercompany cash agreements govern the relationships between them.
This creates several use cases that require real-time hierarchy traversal:
- POBO routing: The service determines the correct multi-hop accounting path for each transaction. For example, if CORP-B pays on behalf of SUB-1, the accounting path traverses SUB-1 → CORP-A → CORP-B, crossing treasury center boundaries.
- Cash pooling/sweep: Member entities sweep excess cash to their central entity’s bank accounts. Sweeps can flow in both directions and across multiple tiers. For example, entity SUB-4 can sweep directly to its regional central entity CORP-C, which in turn sweeps to global central entity CORP-B. Each sweep is a single bank transaction rather than a route through every intermediate level, which reduces redundant cash movements and transaction costs across the entity structure.
- Bank account eligibility: Determine which bank accounts are available for a given entity, filtered by currency and payment method. This includes the entity’s own accounts, treasury center central entity accounts accessible through the hierarchy, and business continuity plan (BCP) backup accounts. Each treasury center central entity bank account carries its own set of supported payment methods (cross-border, WIRE, EFT, RTP). You apply this information to decide whether a treasury center POBO payment is possible or whether to fall back to a different payment instrument held by the entity directly.
- Intercompany balance tracking and accounting: When bank statements arrive, the service matches the originating and destination bank accounts for each cash movement. The correct treasury center path between these accounts drives intercompany balance tracking across multi-tier relationships and generates the corresponding accounting entries. For example, a sweep from entity SUB-4’s bank account to CORP-B’s EUR account must identify the path SUB-4 → CORP-C → CORP-B, recording an intercompany balance at each hop along with the associated
agreementIdvalues. This path resolution drives both the intercompany balance position and the journal entries for each leg of the movement.
Payment paths and accounting paths can differ for the same transaction. For example, when CORP-B pays on behalf of member entity SUB-4:
- Payment path: SUB-4 → CORP-B (direct, with eligible bank accounts from both SUB-4 and CORP-B).
- Accounting path: SUB-4 → CORP-C → CORP-B (traverses through intermediate entity CORP-C for proper intercompany accounting).
The same graph must handle both paths, so a single data model must support multiple traversal strategies over the same nodes and edges. These access patterns, multi-hop, directional, filtered by relationship type, are the characteristics that make graph databases well-suited for this type of problem. Additionally, an entity might have an intercompany agreement in place but might not be POBO-eligible. For example, the entity’s country might have POBO restrictions. In this case, the entity can participate in cash sweeps but not POBO payment routing.
The data store must support each of these access patterns at high throughput, particularly bank account eligibility, which handles the highest call volume. It must also remain flexible enough to add new hierarchy types without refactoring the existing model.
Choosing a graph database for hierarchy traversal
To reduce payment routing latency and simplify hierarchy traversal logic, we chose a data store built for graph workloads. In Neptune, a single Gremlin query walks the edge chain from member entity to central entity, filters by label and property at each hop, and returns the full path. The following diagram illustrates the graph structure for a treasury center hierarchy, showing how company code nodes connect through labeled edges.
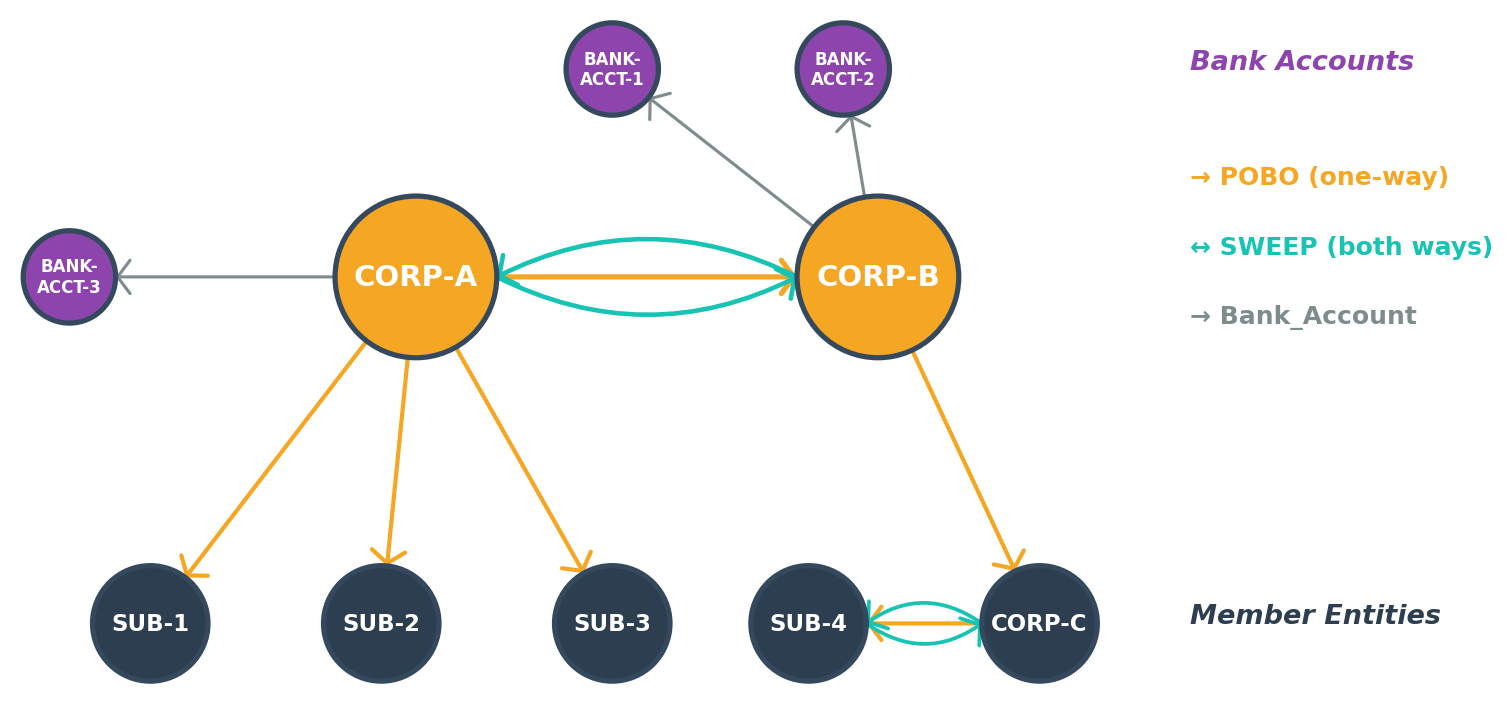
Multi-hop hierarchy traversals have specific requirements:
- Multi-hop paths span multiple levels. Finding the path from SUB-4 to CORP-B (SUB-4 → CORP-C → CORP-B) involves traversing at least two levels, and each additional level adds depth to the traversal.
- Nodes and edges carry distinct attributes, and they must be modeled in a way that scales as the graph grows.
- Traversals must return node metadata along with the path, not only the connected node identifiers.
The Gremlin examples in this post run on any Neptune cluster with a Neptune notebook attached. For setup instructions, see Getting started with Neptune. You can also use Graph Explorer, an open-source low-code visual exploration tool for querying and visualizing graph connections without writing code.
Solution architecture
The following diagram illustrates the high-level architecture of the hierarchy service.
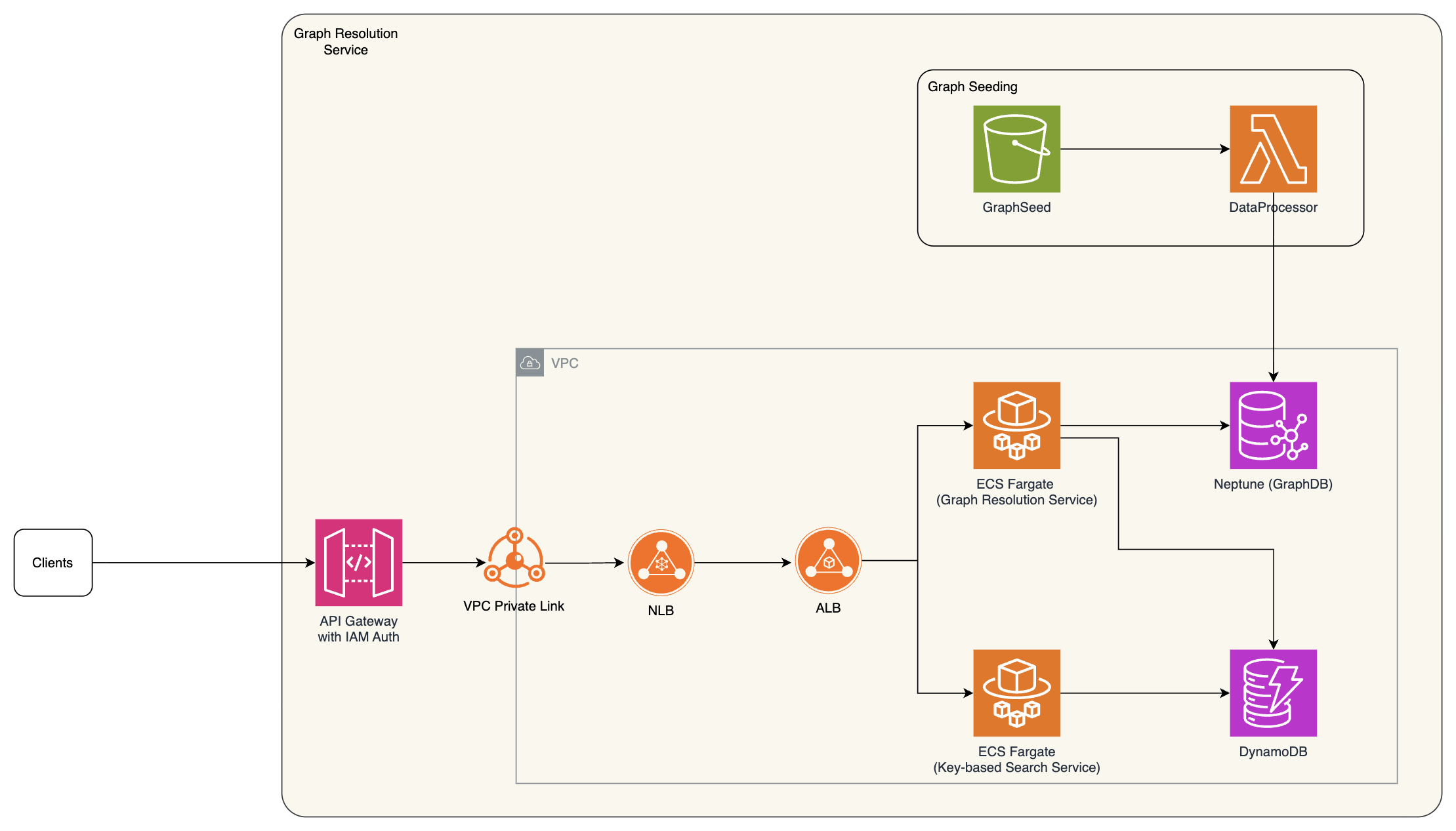
This solution includes the following components:
- We expose the graph resolution service through Amazon API Gateway with AWS Identity and Access Management (IAM) authentication, accepting authenticated API calls from internal clients such as payment planning and intercompany accounting services.
- Traffic routes to the graph resolution service through AWS PrivateLink and Elastic Load Balancing. A Network Load Balancer serves as the PrivateLink endpoint target (required for VPC endpoint connectivity), and an Application Load Balancer handles HTTP-level routing to the underlying Amazon Elastic Container Service (Amazon ECS) and AWS Fargate services. The Application Load Balancer routes hierarchy traversal requests and key-based search to separate microservices based on request path. Each microservice runs within an Amazon Virtual Private Cloud (Amazon VPC) for network isolation.
- The graph resolution service runs Gremlin traversals against Neptune for hierarchy queries. When API responses require full reference data (such as bank account details and payment methods), the service uses key attributes returned from Neptune to look up details in Amazon DynamoDB. This avoids the complexity of maintaining consistent writes across both data stores.
- We store the hierarchy in Neptune as a property graph with labeled nodes (company code or bank account) and labeled directed edges representing relationship types. We keep only the key attributes needed for traversal and filtering (such as
isPOBO,isTreasuryCenterCentral, andfunctionalCurrency) to maintain a minimal graph. - A key-based lookup service on DynamoDB manages the foundational mappings between company codes and their bank accounts (actual ledger) as well as intercompany financial agreements (AGREEMENT ledger). DynamoDB is well-suited for these single-hop, key-value lookups that do not require traversing multiple levels of the hierarchy. For teams that prefer a single-database architecture, these mappings can also be stored as edges in Neptune. We separated them because bank account and agreement attributes change frequently, and isolating high-frequency writes in DynamoDB avoids unnecessary write pressure on the graph.
- DynamoDB serves as the source of truth for full entity and bank account reference data. At runtime, the service enriches Neptune traversal results with DynamoDB lookups for detailed attributes like payment methods, bank names, and country codes.
For guidance on designing the DynamoDB table schema for entity and bank account reference data, including partition key strategy and access patterns, see the Amazon DynamoDB Developer Guide.
This architecture reduces payment routing latency and reconciliation time because Neptune resolves multi-hop paths in a single query, and DynamoDB enforces consistency through conditional writes on the source of truth. The service queries Neptune for graph relationships and traversal, and DynamoDB for reference data lookups. Neptune writes occur only when a relationship changes, such as a new member entity joining a treasury center central entity or the addition of a POBO edge. Frequent attribute updates stay in DynamoDB.
Keeping these high-frequency attribute changes in DynamoDB and limiting Neptune to structural relationship changes minimizes write volume to the graph and avoids bidirectional synchronization complexity. For the read-intensive workload, API Gateway caching reduces the number of calls reaching Neptune. Hierarchy structures change infrequently, because new agreements or entity reorganizations happen on a weekly or monthly cadence. As a result, even the default 300-second TTL absorbs the majority of repeated eligibility lookups without serving stale results. This is a reversible decision: the cache can be disabled (TTL=0), resized, or its TTL adjusted purely through API Gateway stage configuration, without requiring any code changes.
Graph modeling: An iterative approach
We started with an initial representation and progressively added complexity as we validated each use case. This iterative approach keeps each query focused on one use case, so new requirements add edges and labels without rewriting existing traversals. Graph databases enable this pattern through their flexible schema, where structure emerges alongside requirements rather than being defined upfront.
The following five steps show how our model evolved from an initial directed graph to a model with labeled edges, bidirectional relationships, node-level eligibility properties, and bank account vertices. Each step addresses a specific use case that the previous iteration could not support.
Step 1: Basic directed graph for POBO
Our first step was to define company codes as vertices and directed edges pointing from member entity to central entity:
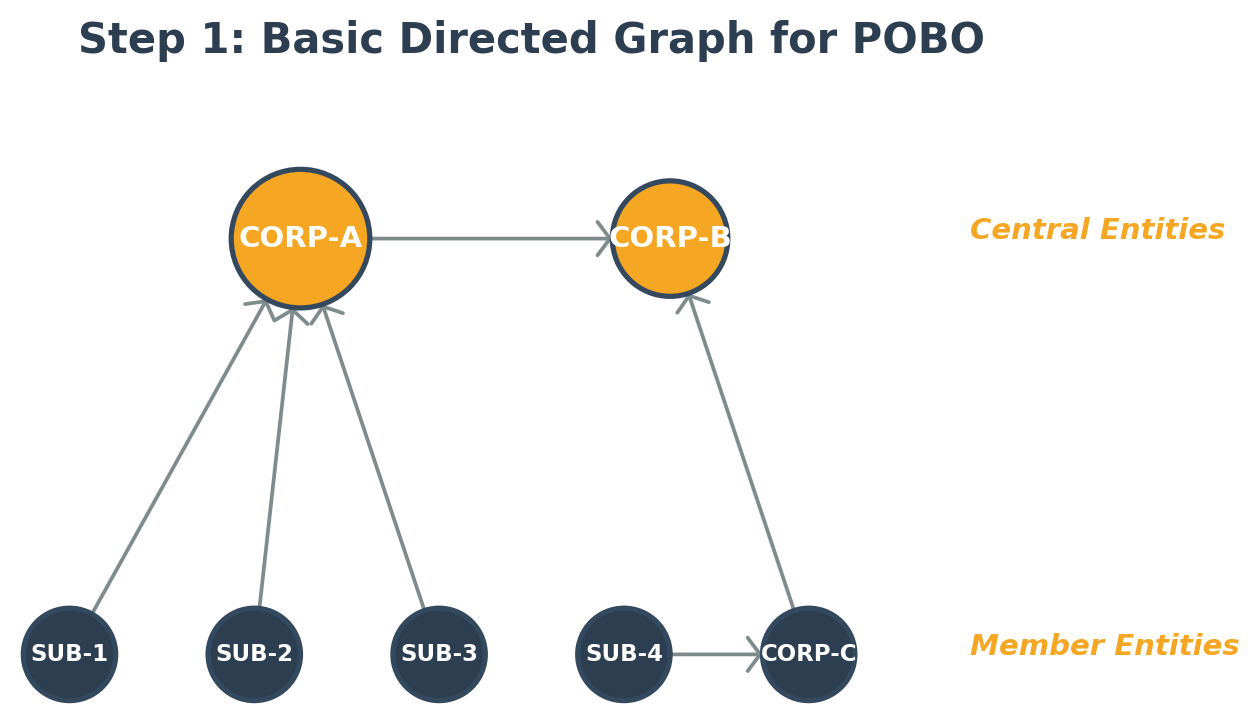
In this model, CORP-A and CORP-B are treasury center central entities. US member entities (SUB-1, SUB-2, SUB-3) connect to US central entity CORP-A, while non-US member entities (SUB-4) connect through CORP-C to CORP-B. The cross-central entity edge from CORP-A to CORP-B supports cross-treasury-center POBO payments. This initial graph already identifies accounting paths. For CORP-B paying on behalf of SUB-1, the traversal follows: SUB-1 → CORP-A → CORP-B.
Step 2: Bank accounts as separate vertices
Next, our API responses needed bank account information. We considered two options: storing bank accounts as properties on company code vertices or modeling them as separate vertices.
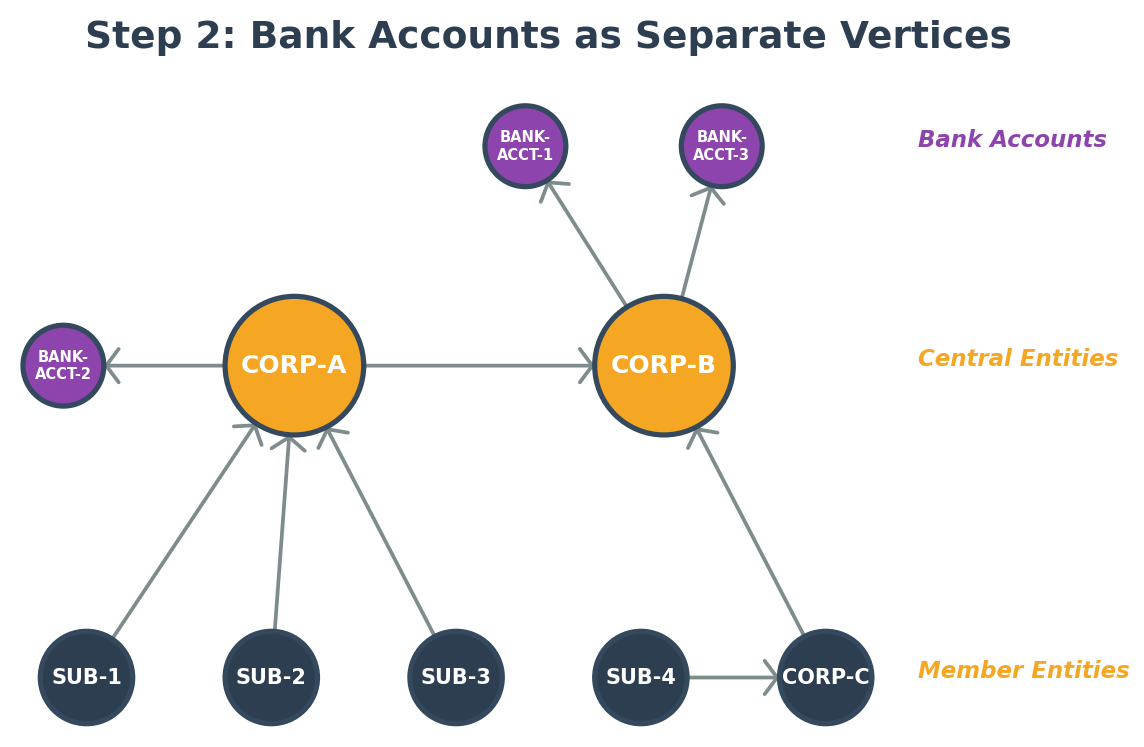
Separate vertices work well here because bank accounts have their own attributes (currency, payment methods, multi-currency eligibility). The relationship between central entities and bank accounts can carry its own metadata, and this approach scales to support future bank-to-bank relationships. Additionally, a single entity can hold multiple bank accounts across different currencies and payment methods, making a separate vertex per bank account the natural graph representation for this one-to-many relationship.
Step 3: Labeled edges for transaction types
In a property graph, every edge must have a label. The next step replaced generic edges with semantically meaningful labels to distinguish transaction types: POBO for pay-on-behalf-of, SWEEP for cash pooling, and Bank Account for company-code-to-bank-account associations.
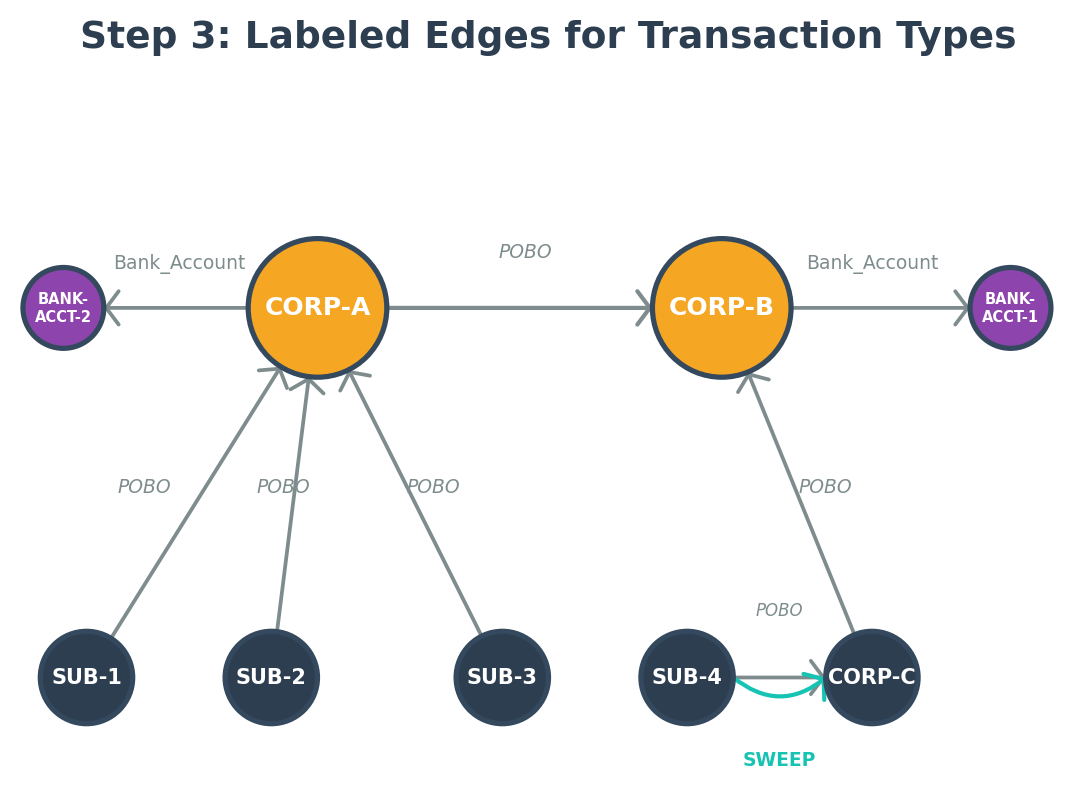
This labeling matters for query filtering. When a payment service asks for the POBO path from SUB-1 to CORP-B, the traversal follows only POBO-labeled edges. When a cash pooling service needs the sweep path, it follows SWEEP-labeled edges.
Step 4: Bidirectional edges for cash pooling
POBO is directional: payments flow from member entity to central entity. But cash pooling can flow in either direction. In a labeled property graph, any edge can be traversed in either direction using Gremlin’s both() step regardless of how it was created. We model SWEEP as separate directional edges to make the business semantics explicit. Each edge represents a distinct cash pooling agreement with its own effective dates. To support this, we added reverse SWEEP edges between central entities:
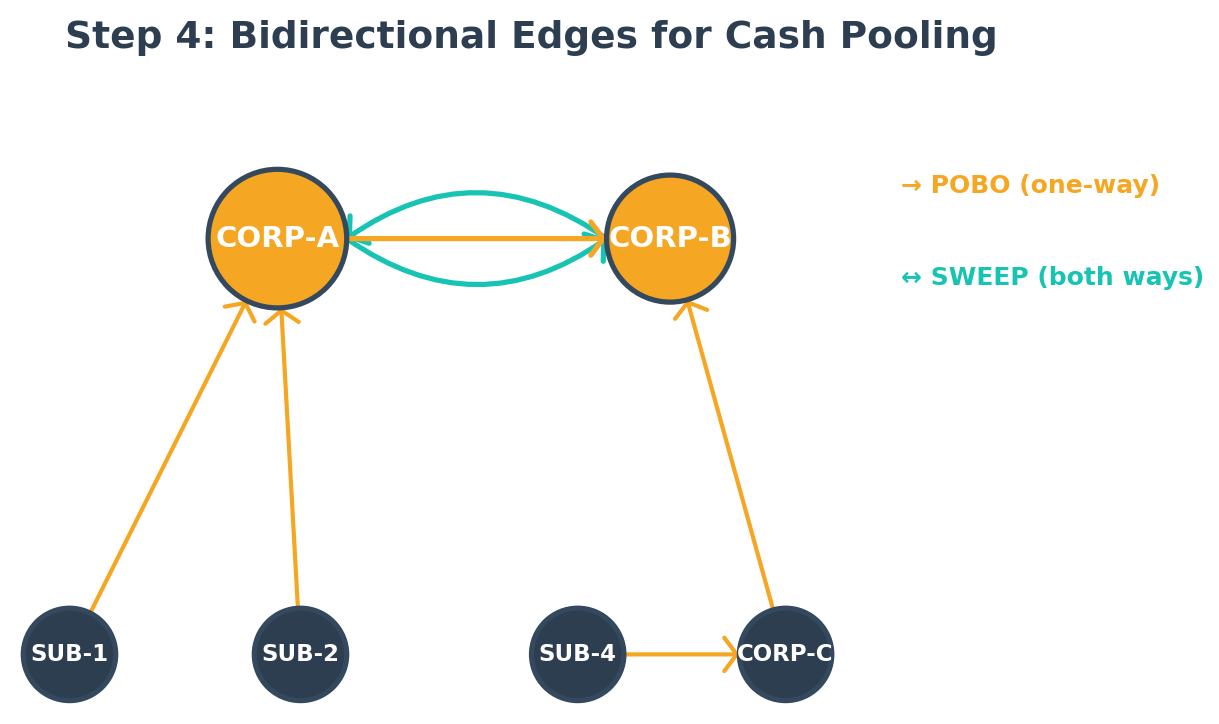
Now the graph supports both use cases:
- POBO path (SUB-1 to CORP-B): SUB-1 →[POBO]→ CORP-A →[POBO]→ CORP-B.
- Cash sweep (CORP-B to CORP-A): CORP-B →[SWEEP]→ CORP-A.
Step 5: Node properties for eligibility
The final challenge is handling POBO eligibility. An entity might have an intercompany agreement (represented by an edge) but might not be POBO-eligible. To address this, we added an isPOBO property to company code nodes:
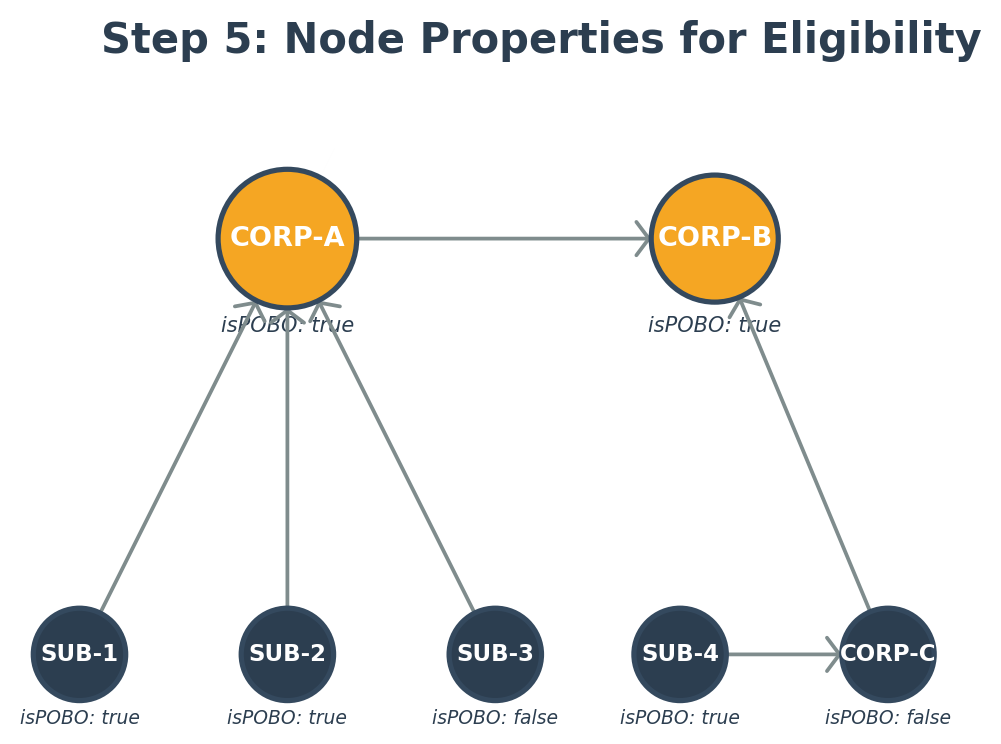
Notice the distinction: edge labels imply the semantic direction of a relationship, while the physical edge construction defines its actual direction in the graph. Node properties determine the eligibility of each entity for specific operations. For example, if CORP-C has isPOBO: false, a POBO traversal skips it, but a SWEEP traversal still works because sweep eligibility does not depend on the isPOBO flag.
Final data model
The following tables summarize the node and edge definitions.
Company Code to Company Code:
| Element | Label | Key Properties |
| Node | CompanyCode | isCentral, isPOBO, functionalCurrency |
| Edge | POBO | agreementId, startDate, endDate |
| Edge | SWEEP | agreementId, startDate, endDate |
Company Code to Bank Account:
| Element | Label | Key Properties |
| Node | BankAccount | accountCurrency, poboEnabled, sweepEnabled |
| Edge | Bank_Account | startDate, endDate |
Place hierarchy-centric properties (agreementId, date ranges) on edges and entity-centric properties (isPOBO, functionalCurrency) on nodes. This distinction aligns with how queries filter and traverse: access patterns are relationship-centric, so edge properties drive traversal logic, while node properties drive eligibility checks.
Gremlin query patterns
With the graph model defined:
- Creating the hierarchy (upsert vertices and edges).
- Finding POBO and SWEEP paths (multi-hop traversals).
- Retrieving eligible bank accounts (filtered by currency and payment method).
The following Gremlin queries implement the core access patterns described earlier. Gremlin is a traversal-based query language where you start at a vertex and walk through the graph step by step. Each chained method (.out(), .has(), .repeat()) adds a filter or movement to the traversal. Neptune also supports openCypher as an alternative query language over the same graph data, so teams already familiar with Cypher from Neo4j can use it interchangeably without migrating their data model.
Building the hierarchy
The following Gremlin query creates the initial treasury center hierarchy:
When CORP-B pays on behalf of SUB-1, the accounting service needs the ordered path. This traversal follows POBO edges from source to target:
Cash sweep path resolution
For cash pooling from SUB-4 through multiple hops to CORP-A (SUB-4 → CORP-C → CORP-B → CORP-A), the traversal follows SWEEP edges:
This traversal follows the full sweep path across multiple hops in a single query.
Getting eligible bank accounts
The highest-volume API, bank account eligibility, is called for every payment. It retrieves eligible bank accounts for a given company code, including treasury center central entity accounts filtered by currency:
This traversal returns results in a single query. The traversal returns key attributes from Neptune. Full bank account details (bank name, payment methods, country code) are then added through a DynamoDB lookup using the bank account identifiers.
Primary/State node pattern for versioning
Financial systems require the ability to reconstruct prior states of entity relationships for audit and regulatory review. The hierarchy service uses a Primary/State node pattern in Neptune to maintain version history while supporting efficient real-time queries. This pattern applies to any use case where you need to track changes to graph entities over time.
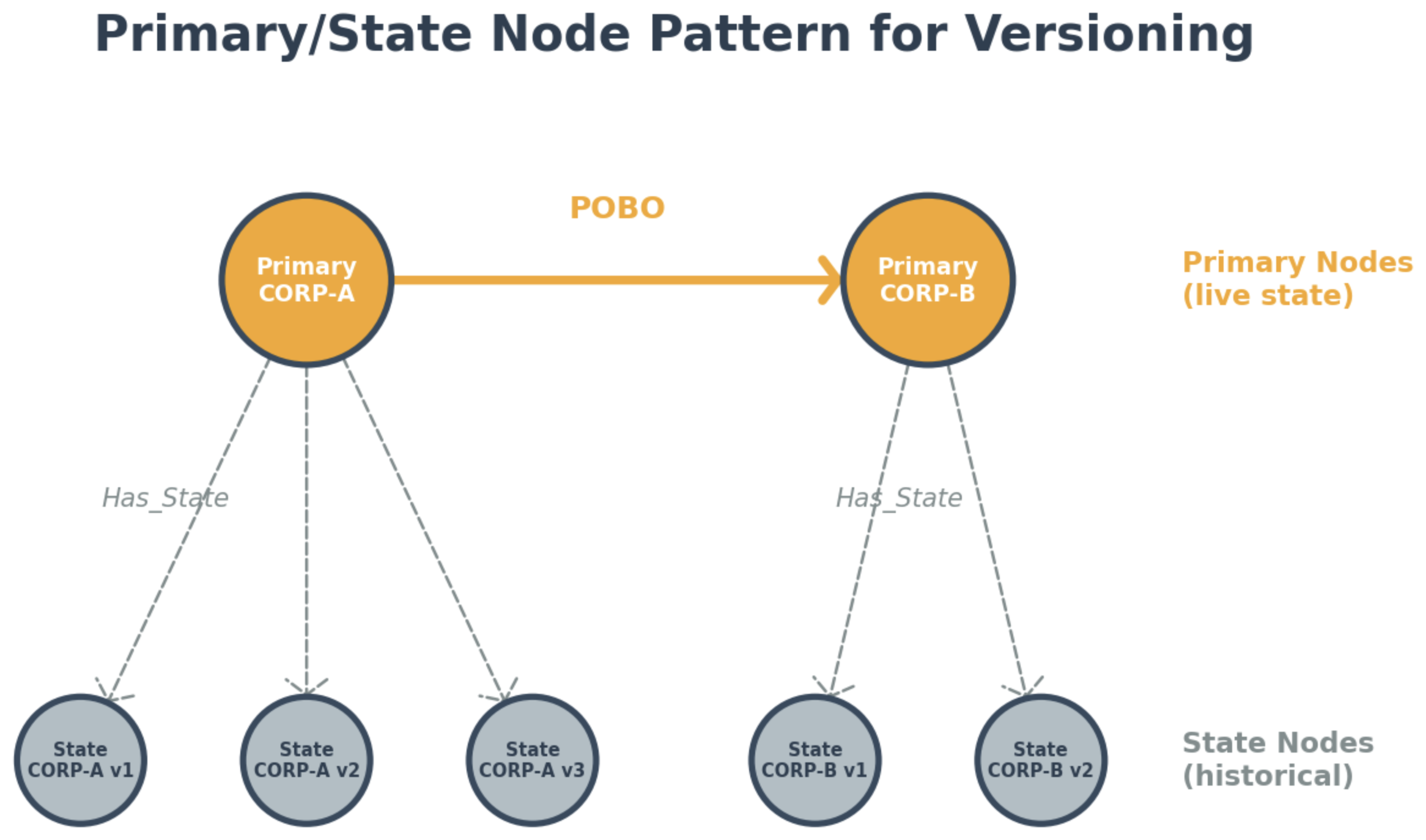
The pattern works as follows:
- Primary nodes represent the current state of each entity. They carry the live hierarchy edges (POBO, SWEEP) and the latest property values. Traversal queries operate on primary nodes.
- State nodes represent historical versions. Each time a primary node is updated, a new state node is created with the previous property values, connected via a HAS_STATE edge with startDate and endDate timestamps.
UPSERT implementation with mergeV and mergeE
This pattern uses the Gremlin mergeV() and mergeE() steps, which provide native upsert semantics. The traversal first attempts to find an existing primary node. If found, it updates the properties and terminates the previous state edge. If not found, it creates a new primary node. In both cases, it creates a new state node to preserve the historical version. In this pattern, the primary node lookup uses a property-based filter (has("CompanyCode", "companyCode", "CORP-A")) rather than a vertex ID lookup, because primary nodes carry a separate isPrimaryNode flag that distinguishes them from their state node counterparts sharing the same logical identifier.
This pattern preserves every hierarchy change as a state node, while keeping traversal queries fast by operating only on primary nodes.
Scaling for diverse relationship types
The graph model supports extensibility. We introduce new node labels and edge labels to serve entirely different hierarchy types from the same Neptune cluster while preserving existing query behavior.
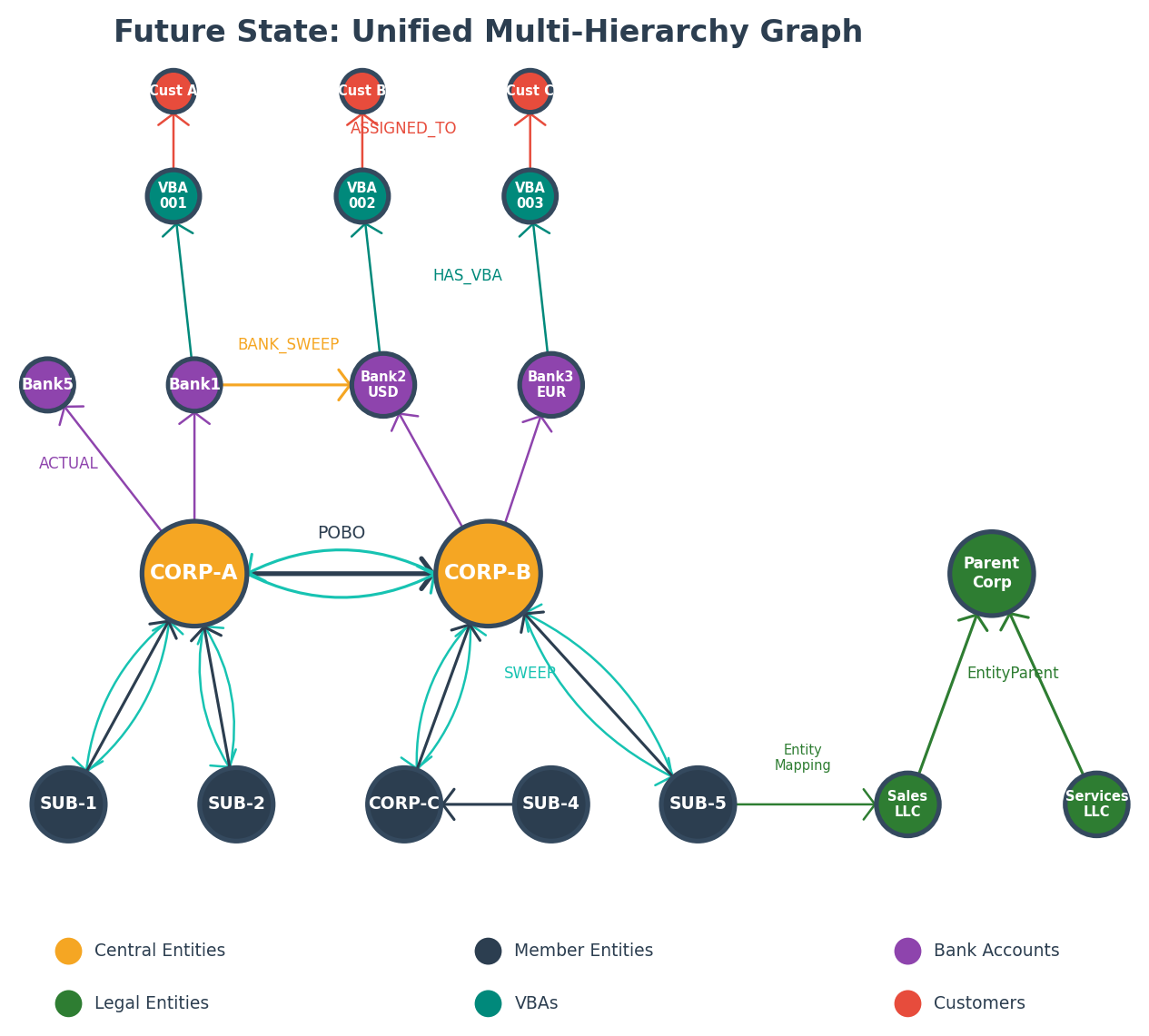
The future-state graph adds three capabilities without modifying existing data:
- Bank-to-bank sweep relationships: BANK_SWEEP edges connect bank accounts directly (for example, Bank5 → Bank2_USD), allowing physical cash movement tracking across treasury center central entities.
- Legal entity hierarchy: LegalEntity nodes connected via EntityParent edges model the corporate ownership structure. EntityMapping edges link company codes to their legal entities.
- Additional treasury center member entities: New company codes join with their own POBO/SWEEP edges and bank account associations.
Each hierarchy type uses distinct edge labels, so queries for one type never interfere with another. For example, a legal entity traversal to find the corporate parent chain for company code “SUB-5” (a specific company code identifier in the hierarchy) would look like:
This query coexists with treasury center hierarchy queries in the same graph without conflict.
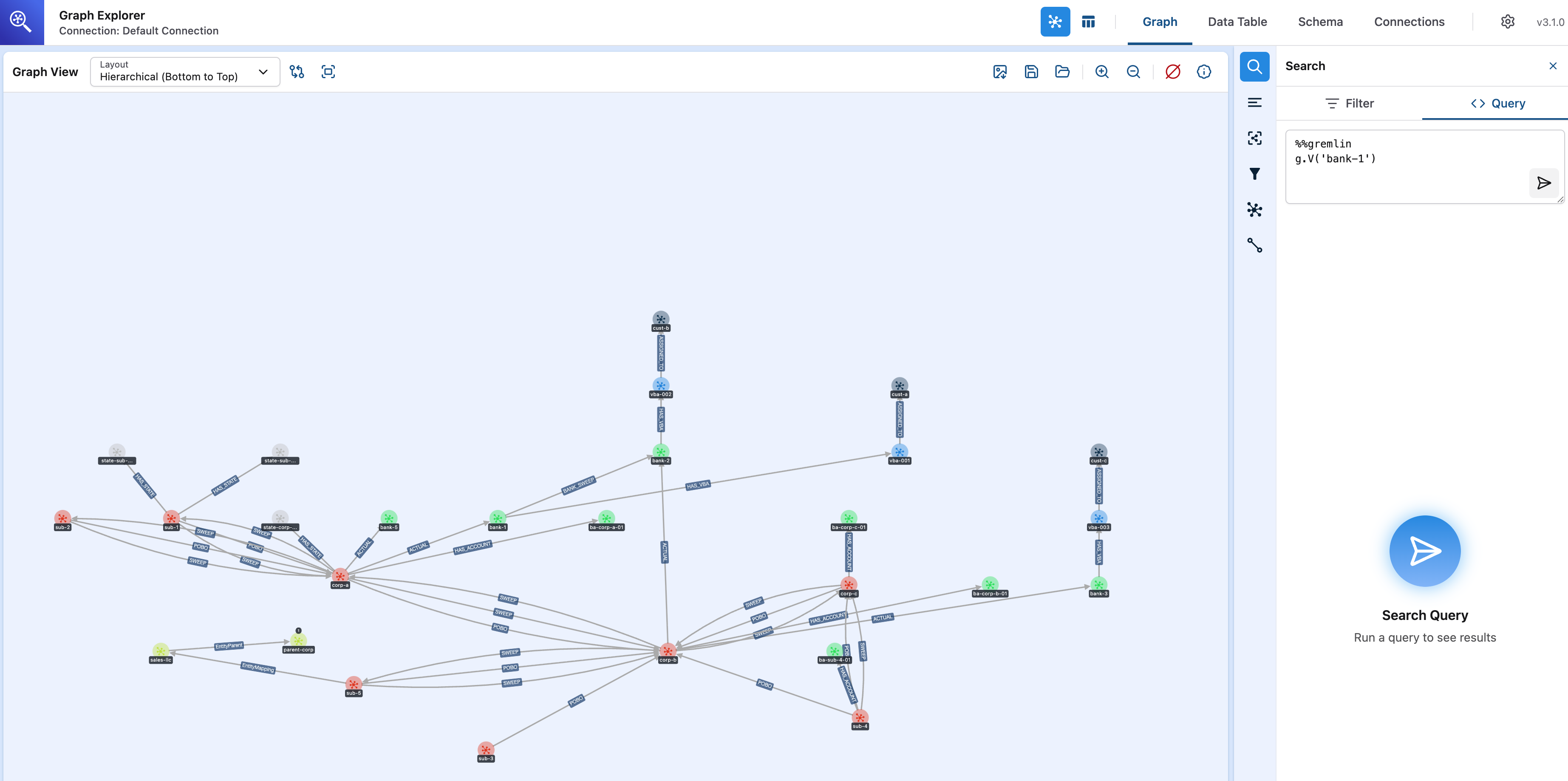
Visualizing the hierarchy in Graph Explorer
The following visualization shows the treasury center hierarchy rendered in Graph Explorer, Neptune’s built-in low-code tool for browsing graph data interactively. The node-edge layout illustrates how company codes connect through labeled POBO and SWEEP edges, with bank accounts attached as separate vertices. This visual representation was generated directly from the Gremlin queries described in this post, without any additional visualization code. Graph Explorer renders query results as interactive diagrams that you can explore by clicking nodes to expand their connections.
Lessons learned
- Iterate on the graph model with real use cases. The model evolved through five iterations, each driven by a specific use case the previous model could not support. Starting simple and adding complexity incrementally helps avoid adding unnecessary complexity.
- Separate relationship semantics from eligibility semantics. The design pattern here is using edge labels for relationship direction and type, and node properties for eligibility flags. This keeps the model clean and avoids duplicating edges for different eligibility states.
- Choose node properties vs. edge properties deliberately. Place hierarchy-centric properties (
agreementId, date ranges) on edges, and entity-centric properties (isPOBO,functionalCurrency) on nodes. Neptune supports Single and Set (default) cardinality for properties but not lists cardinality. Design your data model around this constraint. - Focus Neptune on relationships, not reference attributes. Neptune is best suited for the graph structure: which entities connect to which central entities, through what transaction types, and with what eligibility. Properties that do not affect the relationship itself (bank name, payment methods, country codes) stay in DynamoDB. At runtime, enrich traversal results through DynamoDB lookups for these reference attributes. The additional DynamoDB lookup adds minor latency, but it keeps the graph limited to relationships and the attributes that govern traversal.
- Use Neptune notebooks and Graph Explorer for visualization. Neptune notebooks render traversal results as interactive node-edge diagrams directly in the notebook cell output. For path queries, use path().by(elementMap()) which returns id, label, and properties in a single flat map. For more visual-based exploration, Graph Explorer provides a low-code interface for browsing and querying graph data without writing Gremlin. Both tools help validate traversal logic and spot modeling errors before deploying to production.
- Understand Gremlin’s processing pipeline for performance tuning. Gremlin queries go through three phases: parsing (TinkerPop steps), conversion (Neptune native steps), and optimization. Rewrite queries to eliminate steps that cannot be converted to native steps and move filter steps to the end of traversals for better conversion. The Neptune Gremlin results cache further reduces latency for repeated queries with no I/O costs and can be used if pagination is required.
- Plan for extensibility from the start. By using distinct edge labels for each hierarchy type, you build a model that supports multiple coexisting hierarchies in a single graph. We added legal entity hierarchies and bank-to-bank relationships, and existing treasury center queries continued to work unchanged.
Financial industry applications
The hierarchy challenges described here are common across the financial industry. Organizations managing complex entity relationships, whether routing payments, aggregating exposures, or tracing ownership, often face a similar underlying graph problem: multi-hop, directional, rule-filtered traversal over structures that change over time. The patterns in this post apply directly.
- Corporate treasury. Fortune 500 companies manage hundreds of legal entities across dozens of jurisdictions. Their treasury teams face the same POBO, cash pooling, and bank account eligibility challenges. Managing these hierarchies at scale requires a data model that supports multi-hop traversals, directional relationships, and real-time path resolution. A graph-based approach standardizes payment routing and intercompany accounting path resolution, reducing manual effort and providing real-time visibility into cash positions across the entity structure.
- Regulatory reporting and stress testing. US banking regulators require institutions to aggregate exposures across legal entity hierarchies for stress testing (CCAR, DFAST) and resolution planning. Tracing exposures through complex ownership structures spanning hundreds of entities is fundamentally a graph traversal problem. The same repeat().until() patterns used for POBO path resolution apply directly. The Primary/State versioning pattern is particularly relevant here because regulators can reconstruct point-in-time views of entity structures without maintaining separate snapshot tables.
- Exposure aggregation and entity relationship mapping. The Legal Entity Identifier (LEI) system maps ownership relationships between over 2.7 million registered entities globally. Today, this data lives in flat files and relational tables. Modeling it as a property graph would support real-time queries such as identifying which institutions have direct or indirect exposure to a specific entity, or tracing potential impact paths across interconnected financial networks.
- Payment networks and correspondent banking. Payment routing through correspondent banking networks is a graph problem. Each payment may traverse multiple intermediary banks with different fee structures, currency capabilities, and processing windows. The labeled edge pattern used in this post to distinguish POBO from SWEEP applies directly: edges represent nostro/vostro relationships or fee corridors, while node properties determine eligibility by currency, payment type, or jurisdiction.
- AML and beneficial ownership. Tracing payment flows through complex entity structures is central to anti-money laundering compliance. The same traversal patterns that trace an accounting path can trace transactions through chains of related entities. The eligibility filtering pattern maps to compliance-based screening, and the Primary/State versioning pattern delivers the historical audit trail that regulators require.
In each of these cases, the core technology patterns are the same. Use iterative graph modeling with labeled directed edges, node properties for eligibility filtering, temporal versioning for auditability, and a minimal graph paired with a key-value store for reference data enrichment. The financial hierarchy problem is universal, and the graph solution scales across it.
We built a graph resolution service, an internal microservice that resolves payment routing and accounting paths in real time, using Neptune to model these financial hierarchies as a property graph. In this post, we walk through our iterative graph modeling process, key design decisions including a Primary/State node pattern for versioning, and the Gremlin query patterns that power our treasury operations. If you manage financial hierarchies, organizational structures, or other systems with complex multi-hop relationships, these patterns can help you design an effective graph solution. With this approach, we accomplished the following:
- Modeled financial hierarchies as a property graph in Neptune.
- Wrote Gremlin queries that resolve multi-hop payment routing and cash pooling paths in a single query.
- Implemented a Primary/State node pattern that preserves version history and supports audit trails.
- Added new hierarchy types (legal entity structures, bank-to-bank relationships) without refactoring existing queries.
Conclusion
Financial hierarchies are well-suited to graph modeling. The relationships between legal entities, bank accounts, and intercompany agreements are directional, multi-hop, rule-filtered, and change over time. As these hierarchies grow, traversing them requires increasingly complex application logic that becomes brittle with each additional level of depth.
This post shared a working pattern for modeling complex treasury center financial hierarchies as a property graph in Neptune. Our iterative approach started with simple directed edges and progressively added bank account vertices, labeled edges, bidirectional relationships, and node-level eligibility properties. The result is a flexible model that supports POBO payment routing, cash pooling, bank account eligibility, and accounting path resolution, with proof-of-concept latencies that met the target access pattern requirements. A key design decision shaped the outcome: separating relationship semantics (edge labels) from eligibility semantics (node properties) kept the model clean and avoided duplicating edges for different eligibility states.
To get started, model your simplest hierarchy as a directed graph in a Neptune notebook, validate it against your real access patterns, and iterate. The Gremlin patterns and Primary/State versioning approach in this post apply to any domain with complex, multi-hop entity relationships. To discuss how Neptune can support your financial hierarchy workloads, contact your AWS account team or request a consultation with an AWS Solutions Architect. If you have questions about the patterns in this post, leave a comment below.