AWS Database Blog
Category: Amazon Neptune
Build fraud detection systems using AWS Entity Resolution and Amazon Neptune Analytics
In this post, we show how you can use graph algorithms to analyze the results of AWS Entity Resolution and related transactions for the CNP use case. We use several AWS services, including Neptune Analytics, AWS Entity Resolution, Amazon SageMaker notebooks, and Amazon S3.
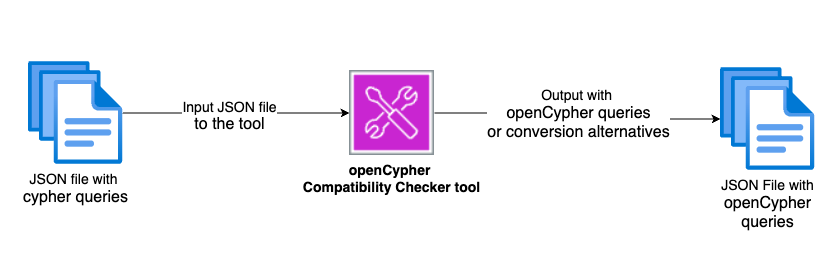
Validate Neo4j Cypher queries for Amazon Neptune migration
In this post, we show you how to validate Neo4j Cypher queries before migrating to Neptune using the openCypher Compatibility Checker tool. You can use this tool to identify compatibility issues early in your migration process, reducing migration time and effort.
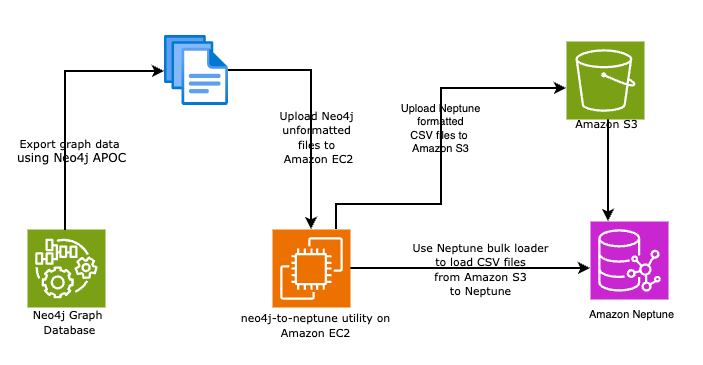
Automate your Neo4j to Amazon Neptune migration using the neo4j-to-neptune utility
In this post, we walk you through two methods to automate your Neo4j database to Neptune using the neo4j-to-neptune utility. This tool offers a fully automated end-to-end process in addition to a step-by-step manual process.

Build and explore Knowledge Graphs faster with Amazon Neptune using Graph.Build and G.V() – Part 2
This is a guest blog by Arthur Bigeard, Founder at gdotv, in partnership with Charles Ivie, Sr Graph Architect at AWS. G.V() is a graph database IDE available for Desktop or on AWS Marketplace, offering extensive graph visualization and querying capabilities for Amazon Neptune and Neptune Analytics. In Part 1 of this series, we demonstrated […]

Build and explore Knowledge Graphs faster with Amazon Neptune using Graph.Build and G.V() – Part 1
This is a guest blog post by Richard Loveday, Head of Product at Graph.Build, in partnership with Charles Ivie, Graph Architect at AWS. The Graph.Build platform is a dedicated, no-code graph model design studio and build factory, available on AWS Marketplace. Knowledge graphs have been widely adopted by organizations, powering use cases such as social […]

How Smartsheet enhances recommendations using Amazon Neptune and Knowledge Graphs
Smartsheet is a leading SaaS-based collaborative work management platform trusted by enterprises worldwide to manage projects, automate workflows, and drive collaboration at scale. In this post, we describe the Smartsheet Knowledge Graph, built in partnership between Smartsheet and AWS. The Smartsheet Knowledge Graph is a unified data model connecting people, content, and work in Smartsheet, representing how users interact with assets, content, and their collaborators.

Build graph applications faster with Amazon Neptune public endpoints
Developing applications on Amazon Neptune Database historically required users setup access into the VPC where it is hosted and use either 3rd party drivers or direct HTTP requests. In this post, we discuss how two key features, public endpoints and the Neptune Data API, solve these common challenges in Amazon Neptune application development. Public endpoints […]

4.7 times better write query price-performance with AWS Graviton4 R8g instances using Amazon Neptune v1.4.5
Amazon Neptune version 1.4.5 introduces engine improvements and support for AWS Graviton-based r8g instances. In this post, we show you how these updates can improve your graph database performance and reduce costs. We walk you through the benchmark results for Gremlin and openCypher comparing Neptune v1.4.5 on r8g instances against previous versions. You’ll see performance improvements of up to 4.7x for write throughput and 3.7x for read throughput, along with the cost implications.

Vibe code with AWS databases using Vercel v0
In this post, we explore how you can use Vercel’s v0 generative UI to build applications with a modern UI for AWS purpose-built databases such as Amazon Aurora, Amazon DynamoDB, Amazon Neptune, and Amazon ElastiCache.

Beyond Correlation: Finding Root-Causes using a network digital twin graph and agentic AI
When your network fails, finding the root cause usually takes hours of investigations, going through correlated alarms that often lead to symptoms rather than the actual problem. Root-cause analysis (RCA) systems are often built on hardcoded rules, static thresholds, and pre-defined patterns that work great until they don’t. Whether you’re troubleshooting network-level outages or service-level degradations, those rigid rule sets can’t adapt to cascading failures and complex interdependencies. In this post, we show you our AWS solution architecture that features a network digital twin using graphs and Agentic AI. We also share four runbook design patterns for Agentic AI-powered graph-based RCA on AWS. Finally, we show how DOCOMO provides real-world validation from their commercial networks of our first runbook design pattern, showing drastic MTTD improvement with 15s for failure isolation in transport and Radio Access Networks.