AWS Database Blog
How to build unified JSON search solutions in AWS
Modern applications rely on JSON for data interchange and storage flexibility. JSON’s schema-less nature allows developers to iterate quickly without costly migrations, but this flexibility introduces architectural complexity. No single database can efficiently handle the conflicting demands of ACID transactions for financial operations, global low latency for user interactions, petabyte-scale analytics for business intelligence, and complex search for content discovery simultaneously. These workloads have fundamentally different performance characteristics and operational requirements. Forcing them into a single engine often results in performance bottlenecks, inflated costs, and operational constraints. Fortunately, you can address these challenges by combining purpose-built AWS services, each optimized for specific workload patterns, while keeping your data synchronized across these systems.
Using a movie streaming reference architecture, this post shows how to implement and sync operational, analytical, and search JSON workloads across AWS services. This pattern provides a scalable blueprint for any use case requiring multi-modal JSON data capabilities.
Why JSON workloads require specialized services
JSON’s defining characteristics, schema-less structure, hierarchical nesting, and variable attribute sets, make it uniquely flexible for application development, but that same flexibility creates architectural complexity that no single database can efficiently resolve.
Unlike fixed-schema formats, JSON documents can evolve freely: a movie catalog entry might carry a handful of attributes today and dozens tomorrow, with entirely different fields across content types. This schema variability means JSON data resists the rigid column definitions of relational databases, the flat structure of key-value stores, and the fixed record structure of columnar warehouses, all at once. At the same time, JSON is the native interchange format for web APIs, event streams, and user-generated content, which means the same JSON data must serve fundamentally different consumers: applications that need individual records instantly, analysts who need to aggregate millions of records, and users who need to search and discover content through natural language queries.
These patterns require specialized optimizations that a single engine cannot provide:
- Operational access requires low latency reads and writes with ACID guarantees for individual JSON documents (for example, retrieving a user’s playback position or updating a subscription record)
- Analytical processing requires scanning and aggregating billions of JSON events with columnar storage and parallel processing (for example, identifying trending content across billions of viewing events)
- Discovery operations require tokenization, inverted indices, and relevance scoring across JSON fields (for example, returning ranked results for a fuzzy search query like “
space movies with Chris“)
No single engine handles all three patterns efficiently. The solution is a purpose-built service for each pattern, synchronized to ensure data consistency across all layers.
Selecting AWS services for JSON workloads
AWS provides purpose-built services for distinct access patterns and data structures. By synchronizing them, each layer excels: the operational store handles transactions, the analytical warehouse performs deep historical analysis, and the discovery layer powers sub-second searches, all while maintaining a unified JSON view.
The following decision tree (select to enlarge) illustrates one approach to selecting AWS services based on your data access patterns and workload requirements. For operational applications, choose between Amazon relational databases (Amazon Aurora or Amazon RDS), document stores (Amazon DocumentDB with MongoDB compatibility), or key-value stores (Amazon DynamoDB) depending on data structure, scaling requirements, query complexity, and latency needs. You feed all primary data stores into the semantic and discovery layer, Amazon OpenSearch Service for full-text and semantic search, and Amazon Simple Storage Service (Amazon S3) Vectors for cost-effective vector embedding storage. Meanwhile Amazon S3 serves as the foundational data lake layer feeding analytical tools like Amazon Redshift and Amazon Athena.
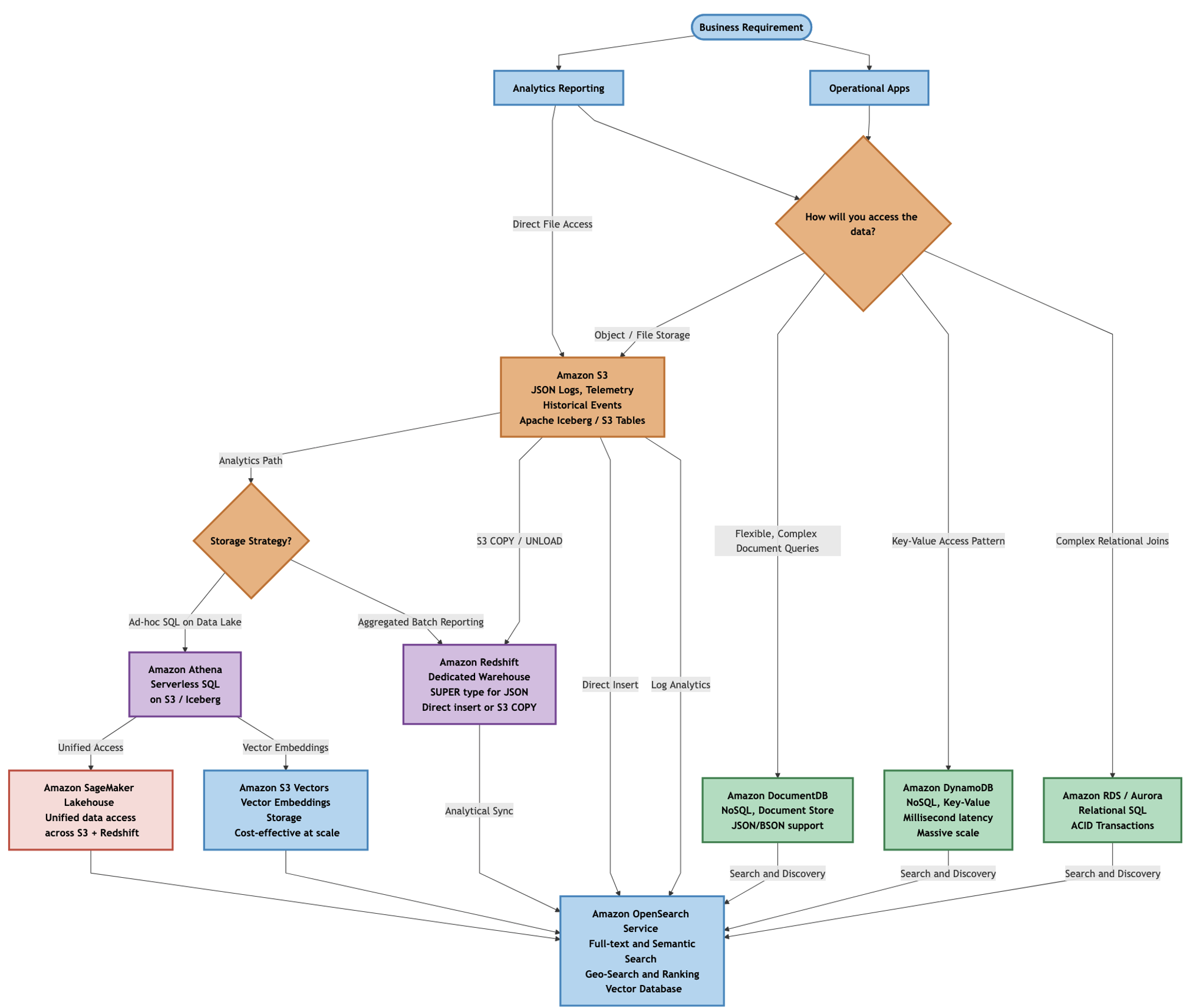
Note that while graph databases such as Amazon Neptune could provide an alternative architecture for certain personalization and recommendation use cases (modeling relationships between viewers, content, and reviews), this post focuses on document-oriented patterns that align with JSON’s hierarchical structure and are more commonly implemented in streaming platforms.
For a movie streaming platform, these design choices manifest across multiple architectural requirements. While JSON serves as the data format throughout, each service addresses a distinct operational need:
- Amazon DynamoDB – High-volume event writes for user activity tracking and real-time state tracking, maintaining current playback positions, session tokens, and user preferences across devices.
- Amazon DocumentDB – Managing movie catalogs with nested, variable attributes.
- Amazon Aurora PostgreSQL and Amazon RDS for PostgreSQL – guaranteeing transactional integrity for billing and subscriptions, using JSONB columns where JSON storage is appropriate while maintaining ACID guarantees.
- Amazon S3 – Durable, low-cost storage for petabyte-scale JSON logs and telemetry.
- Amazon Redshift – Analyzing viewing history using the
SUPERdata type for BI. - Amazon OpenSearch Service – Powering content discovery with fuzzy matching and ranking.
We begin with Amazon OpenSearch Service because search and discovery represent the primary integration objective of this architecture. Understanding what OpenSearch requires in terms of document structure, field indexing, and synchronization frequency establishes the foundation for how each upstream data store must be configured to feed it effectively. Each subsequent section then walks through the implementation details for DynamoDB, DocumentDB, Aurora PostgreSQL, S3, and Redshift, covering storage strategies, CDC enablement, and the synchronization processes that keep OpenSearch aligned with each source system.
Amazon OpenSearch Service
For the movie streaming use case, you need a discovery layer that can serve user-facing search across all your primary stores. Amazon OpenSearch Service functions as this high-performance discovery layer, built on top of, rather than replacing, your operational and analytical data stores. While databases handle transactional writes and warehouses manage heavy aggregations, OpenSearch Service excels at discovery workloads where users explore content through partial matches, multi-dimensional filters, and ranked results on JSON documents.
Its core strengths include full-text, semantic, and geo-search on JSON data, log analytics, and vector search, enabling billions of high-dimensional vector searches with low latency to support generative AI and recommendation systems. For a movie streaming platform, these capabilities power the search bar, recommendation carousels, and personalized homepages.
OpenSearch Service is essential for JSON workloads when your application requires user-facing search capabilities that operational databases cannot efficiently provide. While DynamoDB excels at retrieving a specific user’s bookmarks by user ID, and DocumentDB efficiently returns a complete movie document by title ID, neither can efficiently answer queries like “find all movies with 'space' in the title or description, starring actors whose names contain 'Chris', filtered to sci-fi genre, ranked by ‘user ratings‘ and ‘recent popularity‘“.
These multi-field, fuzzy-match, relevance-ranked queries require inverted indices and scoring algorithms purpose-built for discovery workloads, exactly what OpenSearch Service provides for JSON documents at scale.
Integration patterns with OpenSearch Ingestion
Because your JSON data is now distributed across five specialized stores, OpenSearch Service needs to maintain its own synchronized copy of the search-relevant fields from each source. OpenSearch Ingestion (OSI) keeps OpenSearch Service synchronized with the search-relevant fields from your primary data stores.
Note that while OSI solves synchronization into OpenSearch Service for search and discovery use cases, it does not address synchronization requirements for analytics and reporting workloads, which require separate strategies.
OSI implements synchronization through a dual-phase approach:
Phase 1: Initial snapshot (baseline) – The integration begins by exporting full snapshots from source databases to Amazon S3. OSI ingests these snapshots to establish a comprehensive data baseline within OpenSearch Service.
Phase 2: Continuous synchronization (delta) – After the baseline is established, the system transitions to near real-time updates using Change Data Capture (CDC). OSI monitors incremental changes from source logs, such as Amazon DynamoDB Streams, DocumentDB Change Streams, or PostgreSQL Write-Ahead Logs (WAL), to keep indices current.
To optimize storage and performance, configure OSI to flatten nested JSON structures. This allows for selective indexing of specific fields rather than duplicating entire source documents, reducing overhead in the discovery layer.
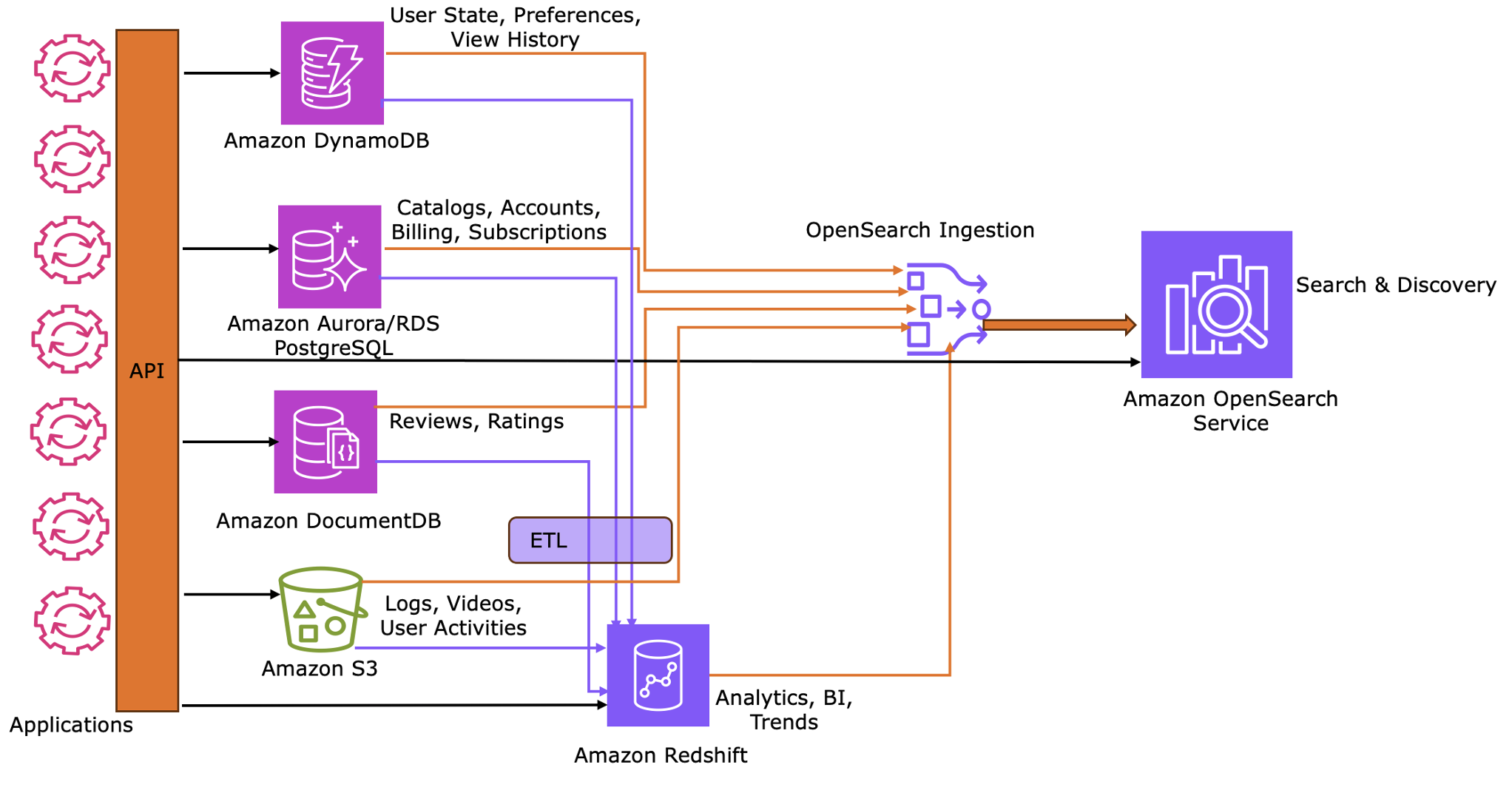
The following sections detail integration patterns for each service, explaining storage logic, CDC enablement, snapshot mechanics, and the specific synchronization processes that keep OpenSearch aligned with source systems.
Amazon DynamoDB
Amazon DynamoDB is a NoSQL database providing consistent performance and predictable scaling for key-value lookups. It natively supports JSON documents (respecting the item-size limit of 400 KB), allowing direct operations on nested attributes without a fixed schema. Its massive write throughput and low latency are essential for high-volume JSON event streams.
The schema-less design is ideal for user activity tracking: it handles varying event structures, such as “play” events with resume points or “search” events with query rankings, without requiring migrations.
For a movie streaming platform, use DynamoDB to manage real-time user state, session management, and high-throughput operational workloads where performance at scale is the priority. In this architecture, DynamoDB stores the “current” status of a user’s interaction as JSON documents: playback resume points (timestamps), active session tokens, and personal bookmarks (“My List“). This lean operational layer enables a seamless, cross-device “continue watching” experience, with historical events archived to Amazon S3.
Integrate Amazon DynamoDB with Amazon OpenSearch Service when changes in user state, such as a newly added bookmark or a completed movie, directly influence content discovery to make sure that search results reflect recent preferences rather than generic content.
Implementation for a movie streaming platform
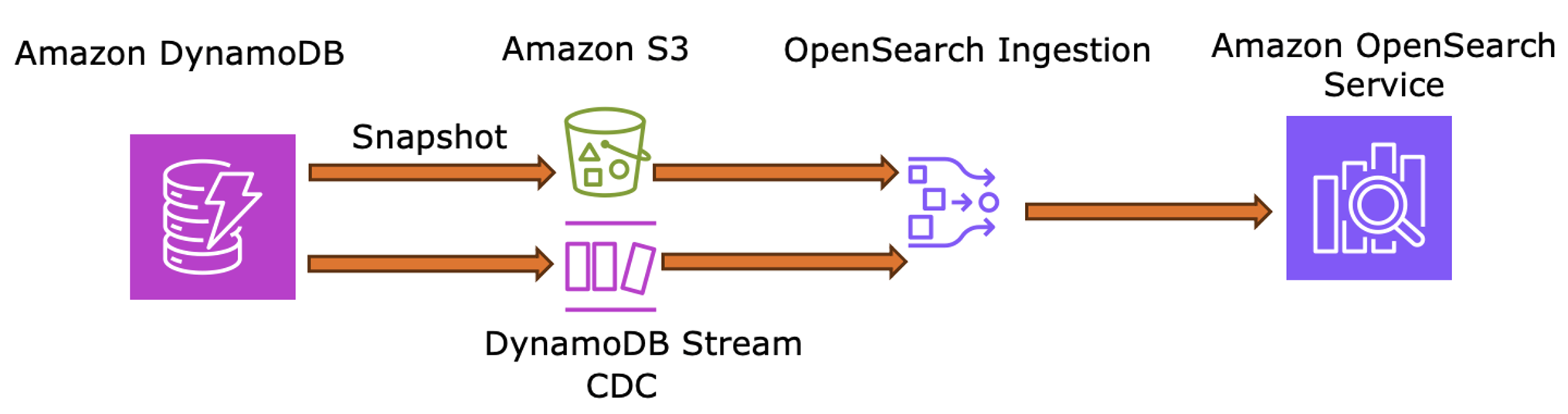
- Storage – Use DynamoDB with
useridas the partition key andtitleidas the sort key to track playback and bookmarks. - Initial load – Export a table snapshot to S3 via Point-in-Time Recovery (
PITR) for the OSI baseline. - Real-time sync – Enable DynamoDB Streams for OSI to capture state changes (
resume points, watch history) and instantly update personalized rankings in OpenSearch.
The following diagram illustrates how DynamoDB Streams and OSI keep OpenSearch Service synchronized with the latest user activity.
Amazon DocumentDB
Amazon DocumentDB is purpose-built for managing JSON at scale, supporting complex, nested structures without a predefined schema. It enables direct interaction via dot notation, array operators, and comprehensive aggregation pipelines for deep data transformation.
For a movie streaming platform, use DocumentDB as the Movie Catalog repository. While items share a common core, modern catalogs include diverse content, TV series, documentaries, sports, and international titles, each with distinct, sparse metadata. Document-oriented storage is ideal for this variability:
- Feature films include attributes like director, cast, runtime, theatrical release date, and production studio
- TV series require seasons, episode counts, series premiere dates, and per-episode metadata
- Documentaries often include subject matter tags, interview subjects, and archival footage credits
- International content carries localized titles, regional ratings systems, dubbed audio tracks, and subtitle availability in multiple languages
- Children’s content includes age-appropriateness ratings, educational content flags, and parental control metadata
Storing this as JSON eliminates complex relational schemas, nullable columns, and frequent migrations. DocumentDB’s aggregation pipelines further streamline in-database processing, such as filtering by genre or computing average ratings across catalog subsets.
Integrate Amazon DocumentDB with Amazon OpenSearch Service when catalog metadata must drive content discovery through full-text search, faceted filtering, and relevance ranking. DocumentDB natively handles the nested JSON structures common in product catalogs, including localized descriptions, genre arrays, and cast lists.
Implementation for a movie streaming platform
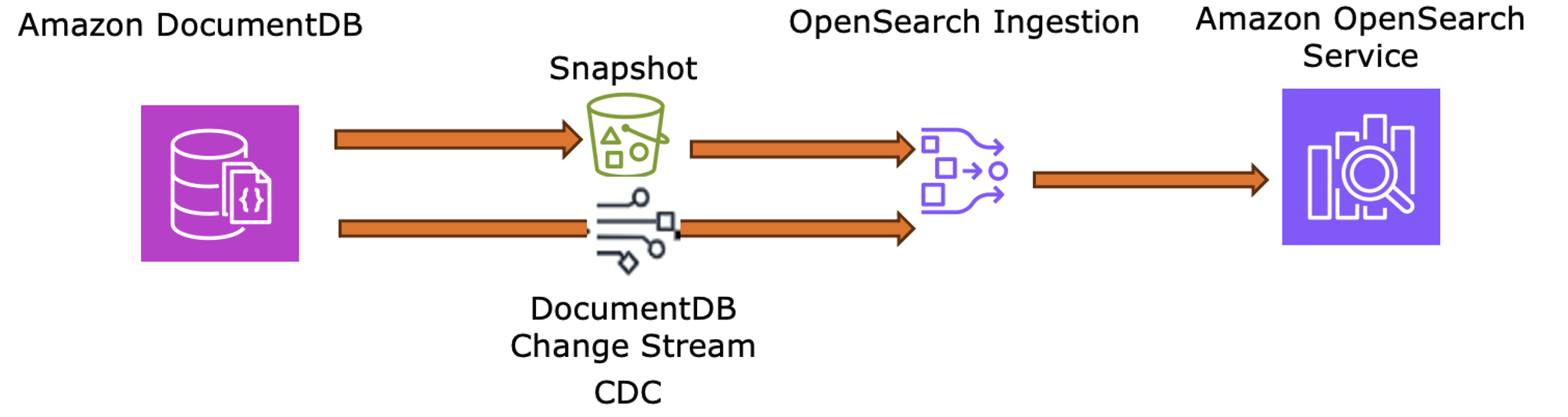
- Storage – Store movie catalog documents as JSON in DocumentDB collections, structured to accommodate variable attributes without schema migrations.
- Initial load – Export the current collection to S3 for OSI to perform a full baseline sync.
- Real-time sync – Enable Change Streams on DocumentDB for OSI to capture and push incremental updates (new releases, metadata changes) directly to OpenSearch.
The following diagram illustrates how DocumentDB Change Streams and OSI keep OpenSearch Service synchronized with the latest content.
Amazon Aurora PostgreSQL
This service combines strict ACID guarantees with robust JSON support via the JSONB data type. This dual capability allows you to perform complex relational joins while using GIN indexing and specialized functions to query semi-structured data efficiently. Amazon Aurora PostgreSQL is the recommended choice for relational workloads requiring JSON support due to its superior performance, scalability, and managed infrastructure compared to self-managed alternatives.
For a movie streaming platform, choose Aurora PostgreSQL as your primary source for Billing, Accounts, and Subscriptions. While large-scale streaming platforms often relax referential integrity constraints for performance reasons, billing and subscription workflows benefit from the transactional consistency that PostgreSQL provides for critical financial operations. JSONB is used for representing semi-structured data like metadata.
Audit records are streamed downstream via CDC to dedicated audit and compliance systems rather than retained in the primary operational store, keeping Aurora focused on transactional operations.
Integrate Aurora PostgreSQL with Amazon OpenSearch Service when your architecture requires the primary source of record for metadata and detailed records for regulated data. With this approach the discovery layer reflects the most current version of operational data while providing advanced full text searchability.
Implementation for a movie streaming platform
- Storage – Store core billing and account records in relational tables, using
JSONBonly for semi-structured data like subscription flags and tags. - Initial load – Export an Aurora snapshot to S3 in Parquet format to establish the baseline of subscriber account data.
- Real-time sync – Enable logical replication on the Aurora cluster for OSI to consume PostgreSQL
WALevents, ensuring subscription and status changes reflect in OpenSearch in near real-time.
The following diagram illustrates how PostgreSQL WAL events and OSI synchronize account metadata into OpenSearch Service for discovery.

Amazon S3
Amazon S3 is the foundational data lake for all JSON analytical data, providing scalable, cost-effective storage for logs, telemetry, and historical events. For workloads needing schema evolution or transactional consistency, open table formats like Apache Iceberg (via Amazon S3 Tables) add structure to raw JSON. Beyond supporting OSI exports, S3 powers petabyte-scale datasets for tools like Amazon Redshift, Amazon Athena, and OpenSearch Service.
For user activity use S3 to capture the massive, immutable history of every playback event (plays, pauses, and skips) as JSON log files. This offloads high-volume historical records from Amazon DynamoDB, allowing the operational layer to focus on current user state (resume points, bookmarks, active sessions) while preserving a complete historical record for deep analysis in Amazon Redshift.
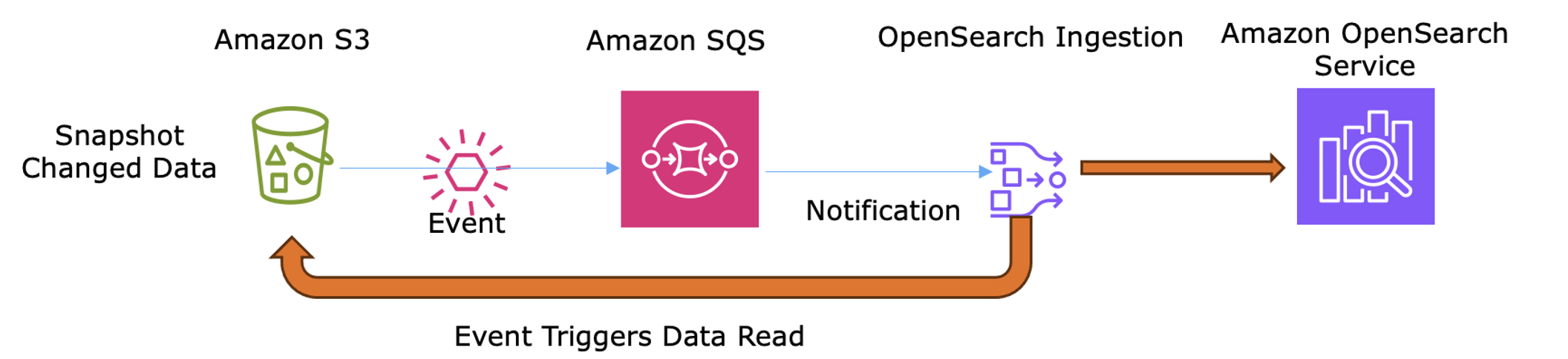
Integrate Amazon S3 with Amazon OpenSearch Service when you need to enable discovery capabilities on top of massive volumes of JSON data stored in your data lake. Note that Amazon Athena serves as the primary entry point for analytics on large S3 datasets, while OpenSearch Service can function as a semantic layer to enable interactive discovery and exploration of data.
Implementation for a movie streaming platform
- Ingestion logic – Stream raw User Activity and Quality-of-Service (QoS) logs to S3 as JSON, capturing buffering events and bitrate switches.
- OSI configuration – Use the S3 source plugin and Amazon SQS notifications to trigger automatic ingestion as new log batches arrive.
- Sync process – OSI transforms the JSON by anonymizing identifiers and extracting behavioral signals (for example, “
most-watched genre“) before indexing them in OpenSearch Service for discovery.
The following diagram shows how S3 Event Notifications trigger OSI via SQS to ingest and transform log files for OpenSearch Service discovery.
Amazon Redshift
Amazon Redshift delivers high-performance online analytical processing (OLAP) capabilities for large JSON datasets. Through the SUPER data type, it provides native support for complex, hierarchical JSON, enabling SQL-compatible querying via PartiQL without the need to flatten or transform data before loading.
Amazon Redshift’s columnar storage and massively parallel processing (MPP) are ideal for petabyte-scale business intelligence and historical reporting. This architecture is especially efficient for JSON because it allows analysts to read only the required nested fields rather than scanning entire objects.
For a movie streaming platform, use Amazon Redshift as the primary engine for analyzing the long-term User Activity logs stored as JSON in Amazon S3. By processing billions of play, pause, and skip events captured as JSON documents, Amazon Redshift identifies high-level patterns, such as regional viewership surges or seasonal genre popularity. The SUPER data type allows queries to extract nested fields from JSON event payloads without requiring rigid schema definitions, accommodating evolving event structures as the platform adds new tracking capabilities.
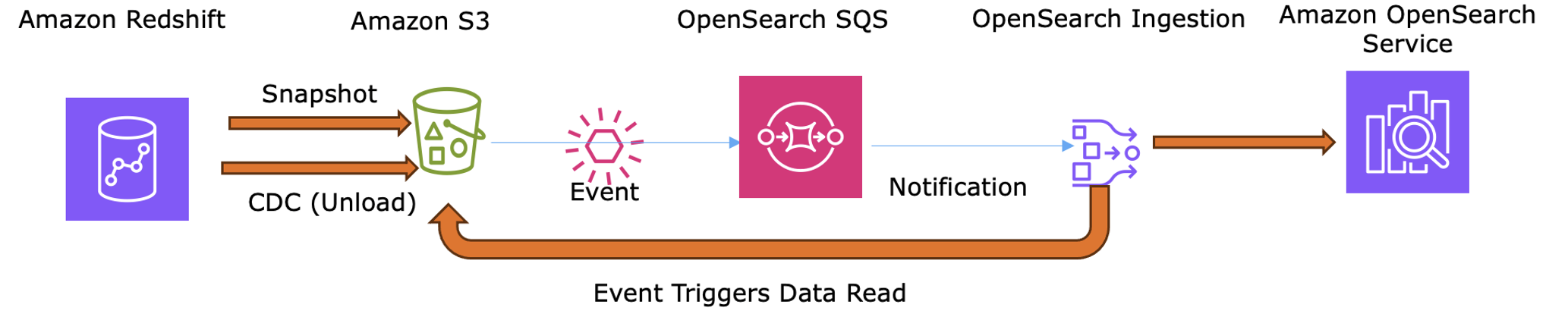
Integrate Amazon Redshift with Amazon OpenSearch Service when insights from complex historical analysis of JSON data must influence the real-time customer experience. This strategy handles the massive computational load of pattern analysis across millions of subscribers, exporting only high-level “trending scores” to OpenSearch Service for surfacing “Trending Now” content and personalized rankings, without storing or processing petabyte-scale historical logs.
Implementation for a movie streaming platform
- Analysis – Amazon Redshift processes billions of
User Activityevents from the S3 data lake to compute trending scores, identifying movies gaining regional momentum or genres experiencing seasonal surges. - Snapshot – Use the
UNLOADcommand to export pre-computed trending scores (movie_id,trend_rank) to S3, sending only aggregated results rather than raw viewing data. - Scheduled sync – Since Redshift lacks native CDC, OSI uses the S3 source plugin to ingest these exported files on a scheduled basis (
hourly or daily). - Indexing – OSI extracts the identifiers and scores for OpenSearch Service to boost search rankings and populate trending carousels.
The following diagram shows how trending scores are exported via UNLOAD and ingested by OSI to keep OpenSearch Service rankings and tending carousels current.
Integration optimization strategies
While OSI automates the synchronization process, you can optimize your implementation by balancing data completeness with operational efficiency. JSON datasets are particularly well-suited for optimization because they can be easily segmented, partially synchronized, batched, or deduplicated using document identifiers. Minimize data movement while preserving functionality with the following strategies:
Selective field synchronization – Index only the fields required for searching, filtering, or aggregating, maintaining source databases as the systems of record. For example, in movie metadata, OpenSearch Service should store titles, descriptions, cast names, and genres, but omit production budgets, internal identifiers, and complete episode transcripts.
Batch operations – Use OSI buffers to group documents into bulk requests to OpenSearch Service before indexing. Use larger buffers (for example, 10MB with a 60-second timeout) to improve throughput for high-volume, non-urgent data like historical logs. Use smaller buffers (for example, 1MB with a 5-second timeout) to reduce latency for time-sensitive data like user activity.
Source deduplication – Use deterministic document IDs or composite keys (like movie_id, user_id + timestamp) generated at the source so that duplicate JSON events update the same OpenSearch Service record rather than creating multiple entries.
Incremental updates – Rely on CDC streams for partial document updates to reduce network load and indexing overhead. OSI automatically performs partial updates when CDC streams provide incremental changes. For example, if a movie’s rating changes, OSI updates only the rating field in OpenSearch Service rather than re-indexing the entire JSON document.
Designing for eventual consistency
In a distributed JSON platform, eventual consistency is not a compromise but a deliberate design choice that enables each specialized service to operate at its optimal performance characteristics. Because JSON documents are self-contained and schema-flexible, they can be partially synchronized and selectively indexed across services, reducing the risk of disrupting downstream consumers and making them well-suited to this model. By designing for eventual consistency, you acknowledge that the discovery layer intentionally lags the operational truth within bounded, predictable windows, which is acceptable because JSON workload characteristics allow flexibility in synchronization timing. Throughout this process, CDC mechanisms preserve the order of changes, ensuring data integrity even with slight delays.
For a movie streaming platform, acceptable synchronization windows are determined by workload requirements and user expectations rather than database limitations. These example service-level objectives reflect what users perceive as acceptable lag based on the nature of each operation:
Catalog updates (Amazon DocumentDB) – Target synchronization within tens of seconds after a movie is added to the operational catalog before appearing in search results. When a streaming service adds new content, users don’t have exact awareness of when it appears down to the second. Even for highly anticipated releases where users are waiting for midnight drops, they typically navigate directly to the show’s detail page rather than discovering it through search, making search index lag imperceptible.
User activity (Amazon DynamoDB) – Target synchronization within a few seconds to support “Just Watched” or personalized recommendations. Slight delays in personalization have minimal user impact since recommendation algorithms already operate on historical patterns rather than instant state. Users expect recommendations to evolve over time, not instantaneously after every interaction.
Billing/tier changes (Amazon Aurora) – Target synchronization under 30 seconds for downstream audit and analytics systems. The critical path for subscription changes, validating payment and granting content access, is served directly by the operational data store, not the search index. Downstream CDC synchronization affects only audit logs and analytics, which operate on hourly or daily aggregates where synchronization lag is operationally invisible.
Analytical exports (Amazon Redshift) – Target synchronization on hourly or daily schedules to reflect trending scores. Business intelligence workloads inherently operate on scheduled reporting cycles where “current” data typically means “as of the last ETL run” rather than real-time.
OSI helps enforce these service-level objectives by providing monitoring, backpressure handling, and dead-letter queues. This maintains the synchronization layer as a managed, observable bridge between your primary storage and your advanced search capabilities.
Conclusion
In this post, we showed you how to build a unified JSON database architecture by distributing workloads across specialized AWS services. You learned that you can use Amazon DynamoDB for operational data, Amazon DocumentDB for flexible catalogs, Amazon Aurora PostgreSQL for transactional integrity, Amazon S3 for data lake storage, Amazon Redshift for analytics, and Amazon OpenSearch Service for discovery, all synchronized through OSI.
Evaluate your current JSON workloads and identify which access patterns, operational, analytical, or discovery, each workload serves. Follow the recommendations in this post to implement a distributed system where specialized AWS services handle JSON workloads according to their strengths. Once you implement your target JSON architecture in AWS, share your experiences, challenges, and optimization strategies in the comments below.