AWS Database Blog
Part 2 – Role of the DBA When Moving to Amazon RDS: Automation
July 2023: This post was reviewed for accuracy.
In Part 1 of this blog series, I talked about how Amazon Relational Database Service (Amazon RDS) can help change the focus of your role as a database administrator (DBA) from routine, time-consuming tasks to project work that helps the business move faster. Spending more time focused on controlling access to the database, helping application teams draft and apply changes to database structures, and performing reactive and proactive performance tuning are important tasks that more directly contribute to the business bottom line.
Automation tips
In this post, I discuss how you can push that advantage one step further and use AWS tools to do more through automation. An important aspect of being an effective DBA when your business is running at top speed is using code and automation whenever you can. AWS provides tools for you to make this easier.
Many of the examples in this post use the AWS Command Line Interface (AWS CLI) to work with Amazon RDS. The AWS CLI is a unified tool to manage your AWS services. With just one tool to download and configure, you can control multiple AWS services from the command line and automate them through scripts. All the code examples used in this post are available to download from this GitHub repository.
If you’d like to skip ahead and see the code in action, go to Case Study: Amazon RDS accelerates unit testing.
Database creation
The basic building block of Amazon RDS is the DB instance. Your Amazon RDS DB instance is similar to your on-premises Microsoft SQL Server. After you create your SQL Server DB instance, you can add one or more custom databases to it. For a guided walkthrough on creating and connecting to a SQL Server database, you can follow the example in the Amazon RDS documentation.
In the following example command, you create a DB instance running the SQL Server database engine SE named sqltest with a db.m4.large instance class, 500 GB of storage, a standby database in another Availability Zone, and automated backups enabled with a retention period of seven days.
Stopping and starting your database
If you use a DB instance intermittently, and you want to resume where you last left your data, you can stop your Amazon RDS instance temporarily to save money. If you have development or test instances that are used only during working hours, you can shut them down overnight and then start them up when you return to the office. You can automate this process with a little bit of orchestration and a few calls to the API. For additional details, review the Stop Instance documentation.
Parameter groups
You manage your DB engine configuration through the use of parameters in a DB parameter group. DB parameter groups act as a container for engine configuration values that are applied to one or more DB instances. When you have a custom parameter group, it is easy to associate it with an instance by specifying it when you create your instance. A default DB parameter group is created if you create a DB instance without specifying a customer-created DB parameter group.
Option groups
Some DB engines offer additional features that make it easier to manage data and databases, and to provide additional security for your database. Amazon RDS uses option groups to enable and configure these features. An option group can specify features, called options, that are available for a particular Amazon RDS DB instance. Options can have settings that specify how the option works. When you associate a DB instance with an option group, the specified options and option settings are enabled for that DB instance.
The following command example uses the AWS CLI to modify an existing database sqltest to use a new option group sqlserver-se-12-native-backup and applies the change immediately. The option group I used in the example is one that uses native backup and restore to Amazon S3 within Amazon RDS for SQL Server. You can read more about the option in the blog post Amazon RDS for SQL Server Support for Native Backup/Restore to Amazon S3.
Monitoring
Monitoring is an important part of maintaining the reliability, availability, and performance of Amazon RDS and your AWS solutions. Amazon RDS provides metrics in real time to Amazon CloudWatch. Amazon CloudWatch is a monitoring service for AWS Cloud resources and the applications you run on AWS. Standard CloudWatch monitoring includes built-in metrics for your DB instance that are visible using the console, AWS CLI, or API for no additional charge.
AWS also gives you the option to enable Enhanced Monitoring for your Amazon RDS instance. Enhanced Monitoring provides additional metrics, increased granularity, and per-process information. The option is available when you create or modify your instance, and it does not require a restart. When you enable Enhanced Monitoring for your instance, you can choose the granularity, and you specify an IAM role that is authorized to collect the information. The enhanced metrics are published to CloudWatch Logs under a log group named RDSOSMetrics, and they are also available in the Amazon RDS monitoring section of the AWS Management Console. The enhanced monitoring data contains numerous metrics that you can use to review data that is valuable for performance monitoring.
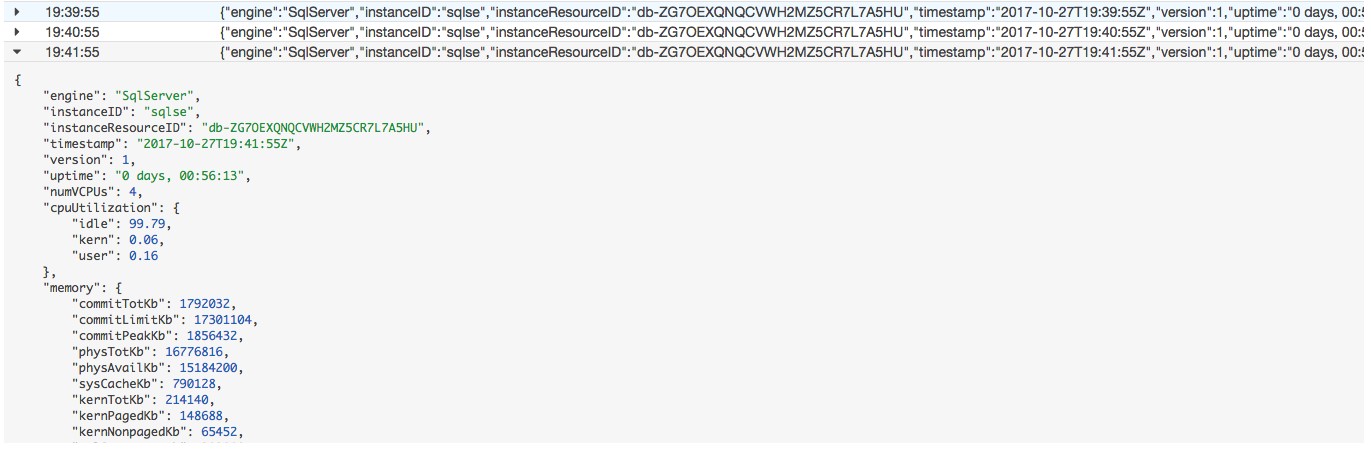
For the metrics and alerts that follow in this post, I focus on standard monitoring in Amazon CloudWatch.
Metrics
Amazon RDS sends CloudWatch data on hundreds of metrics. For the purposes of this blog, I mention just a few of them (WriteThroughput, WriteLatency, and ReadLatency). For a complete list of metrics available for monitoring, open the CloudWatch console and choose Metrics, RDS.

You can also watch the performance of your database over time through the CloudWatch console. It can help you spot trends and understand the performance baseline of your database.

Alarms: preparation
You can create a CloudWatch alarm that sends an Amazon Simple Notification Service (SNS) message when the alarm changes state. An alarm watches a single metric over a time period that you specify. It performs one or more actions based on the value of the metric relative to a given threshold over a number of time periods. The action is a notification sent to an Amazon SNS topic or Auto Scaling policy.
This means that before you create an alarm, you should create a topic and subscribe to it using your email address. The following command example creates an SNS topic.
The topic Amazon Resource Name (ARN) is returned as the output of the command.

You can use the output ARN and any valid email address to subscribe to your new SNS topic.
The subscription must be confirmed before messages can be sent to your email address. In your email application, open the message from AWS Notifications and confirm your subscription. Your web browser displays a confirmation response from Amazon Simple Notification Service.

Alarms: creating
Alarms invoke actions for sustained state changes only. CloudWatch alarms do not invoke actions simply because they are in a particular state. The state must have changed and been maintained for a specified number of periods. You can use the AWS CLI to create an alarm for the metric WriteThroughput measuring over a period of five minutes (300 seconds) for two periods when the value meets or exceeds 48,000.
Now when your database write throughput exceeds your threshold value for a period of 10 minutes, CloudWatch sends a message to your SNS topic, and you receive an email. When you navigate to the console via the link in the email, you can clearly see which alarms need attention.

Your alert is also clearly visible on your instance in the Amazon RDS console.

To read more about monitoring options and best practices for monitoring Amazon RDS, see Monitoring Amazon RDS.
Backup and restore
You can back up and restore DB instances using automated or manual snapshots in Amazon RDS. You can restore to any point in time during your backup retention period, or share a copy of your database with another AWS Region or another account.
Backing up a database
Amazon RDS creates automated backups of your DB instance during the backup window of your DB instance. Amazon RDS saves the automated backups of your DB instance according to the backup retention period that you specify. If necessary, you can recover your database to any point in time during the backup retention period.
You can also back up your DB instance manually by creating a DB snapshot. In this example, I use the snapshot to restore the database to the same AWS Region and account. Amazon RDS also allows you to copy snapshots to other Regions and share with other accounts. The flexibility to copy and share snapshots from one AWS Region to another, or with another account, makes it easy to deploy new database copies.
When you create a DB snapshot, you need to identify which DB instance you are going to back up. Then give your DB snapshot a name so that you can restore from it later.
Restoring a database
Amazon RDS creates a storage volume snapshot of your DB instance, backing up the entire DB instance and not just individual databases. You can create a DB instance by restoring from this DB snapshot. When you restore the DB instance, you provide the name of the DB snapshot to restore from. Then provide a name for the new DB instance that is created from the restore. You can use one of the automated snapshots to restore your database, or you can use a manual snapshot that you have taken.
Restoring a database to a point in time
Using the automated snapshots, you can restore to any point in time during your backup retention period. To determine the latest restorable time for a DB instance, use the AWS CLI describe-db-instances command and look at the value returned in the LatestRestorableTime field for the DB instance.
The latest restorable time for a DB instance is typically within five minutes of the current time.
The example command restores the database sqltest to a new database sqltest-copy at the restore time of October 4, 2017, midnight UTC. I can then point my application at the new database. For more information about point-in-time recovery of an RDS database, see Restoring a DB Instance to a Specified Time.
You can also read more about Backing Up and Restoring Amazon RDS DB Instances in the Amazon RDS documentation.
Orchestration
The AWS CLI is a great way to quickly provision, change, or remove resources. You can use it to create collections of resources, but you have to manage the dependencies between the resources yourself. AWS CloudFormation is a service that gives developers and businesses an easy way to create a collection of related AWS resources and provision them in an orderly and predictable fashion.
AWS CloudFormation automates and simplifies the task of repeatedly and predictably creating groups of related resources that power your applications. An important advantage of AWS CloudFormation is that it allows you to automate service provisioning steps in a fairly simple way. There is no extra charge for AWS CloudFormation; you pay only for the AWS resources that you launch.
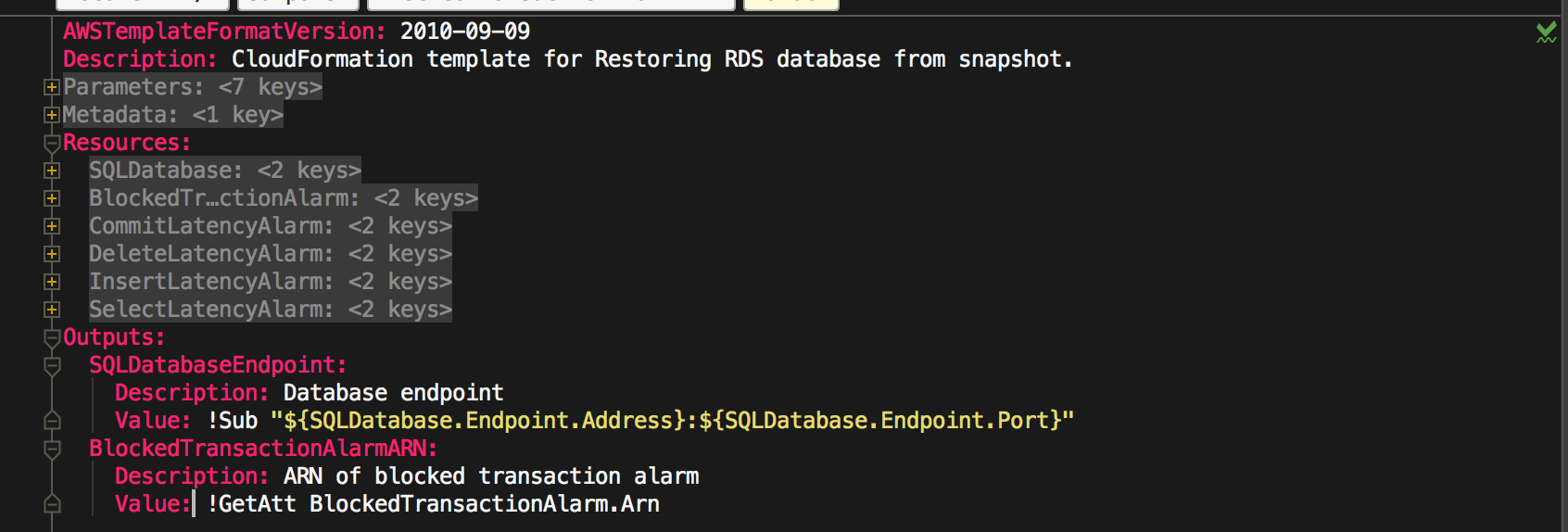
The following image shows an excerpt from an AWS CloudFormation template that is used for the case study in the next section. The template restores an Amazon RDS database from a snapshot and creates five alarms for that new instance. The expectation for this template is that all resources are successfully created, or they are all rolled back. The full template is available in the code repository for this blog post.
Case study: Amazon RDS accelerates unit testing
Now that we’ve reviewed all the ways that you can add automation to your administration tasks, let’s look at how you can put these concepts to use to solve a complex testing problem.
If you have products that run against customer databases, testing new application code changes against various database configurations in a timely fashion can be a challenge. The following matrix shows just two configurations of SQL Server against six machine types. One customer was doing this type of testing for multiple database engines, and multiple parameter configurations.

Before migrating to Amazon RDS, the customer used physical servers and performed configuration changes manually for each test. The customer further managed data consistency by using the engine native backup and restore.
As the size of the test data bloomed to just under 400 GB, the restore process was taking longer and longer, and the management time was increasing. With once-a-week testing, the DBA estimated that the time to install software, configure parameters, and manage the restorations for the SQL Server test fleet was conservatively taking an average of three to five hours a week.
When the customer moved to Amazon RDS, managing the testing process became a much simpler operation. The DBA did three things in preparation for automated testing:
- Created several parameter groups in Amazon RDS for the various SQL Server parameter configurations that they commonly test.
- Created a base Amazon RDS snapshot with a large set of pristine test data so that tests run on consistent data each time no matter the configuration.
- Drafted an AWS CloudFormation template that would restore the snapshot to a new database with three important CloudWatch alarms.

By setting up these few key pieces now, you can launch all tests whenever new code hits the test systems.
For each configuration in the text matrix, the following steps occur.
- The stack is launched.
- Application tests are run.
- Outcomes are recorded, data changes are captured, and any potential alerts are triggered.
- The stack is deleted.
For the SQL Server test matrix as defined, 12 stacks are created and destroyed each test cycle, and they are all managed by an automated code pipeline.
Now that the process is fully automated, the DBA spends less than five minutes a month adding or changing new parameter groups. Those three to five hours a week are now spent helping the application teams increase their SQL code efficiency. The more efficient code has helped them certify smaller CPU and memory footprints for their customers.
Note: For more information about SQL Server Audit or c2 audit mode Server Configuration, consult your SQL Server documentation. For more information about automation topics, a great place to start is the AWS DevOps Blog.
Summary
With Amazon RDS, DBAs can focus less on routine, time-consuming tasks, and spend more time on the tasks that directly contribute to the business bottom line. And you can take it a step further by using code to automate any remaining regular tasks. AWS tools like the AWS CLI make managing services and automating everyday tasks even easier, leaving you more time to help move the business forward.
About the Author
 Wendy Neu has worked as a Data Architect with Amazon since January 2015. Prior to joining Amazon, she worked as a consultant in Cincinnati, OH helping customers integrate and manage their data from different unrelated data sources.
Wendy Neu has worked as a Data Architect with Amazon since January 2015. Prior to joining Amazon, she worked as a consultant in Cincinnati, OH helping customers integrate and manage their data from different unrelated data sources.