AWS for Games Blog
How Lore rethinks binary asset storage on AWS
![]()
Game development teams commit hundreds of large binary assets daily, and traditional version control systems were not designed to handle them. Lore, an open source version control system created by Epic Games, takes a different approach. When a binary file is modified and committed, traditional systems store the entire file as a new revision, whether Git-based or centralized, regardless of how few bytes actually changed. This creates redundant storage and significant monthly costs that scale with team size — a 50-person studio might accumulate petabytes over a production cycle. In this post, we explain how Lore rethinks binary asset storage and share the reference architecture we developed with Epic for deploying it on AWS.
What Lore does differently
Rather than treating binaries as opaque blobs, Lore makes their contents addressable. It splits every binary into content-addressed fragments: variable-size chunks identified by their cryptographic hash. Whether it’s a 200 MB texture or a 500 MB engine binary, only the fragments containing changed bytes are stored as new data. A small edit to a large file stores only the changed fragments, not a duplicate of the entire file.
The economics shift from linear to sub-linear. Early in a project, almost everything is new, so storage grows quickly. As the project matures, more pushes are variations on existing data and the fragment hit rate climbs. When the same fragment appears across 100 different textures, it’s stored once. A branch containing 50,000 unchanged assets requires zero additional storage, making branching effectively free. Multiple projects on the same infrastructure share fragments too, so studios with several titles benefit at the portfolio level.
The Lore client handles fragmentation and deduplication transparently, requiring no workflow changes. Artists, developers, and build engineers use the same process: Check Out, Edit, Commit. The client syncs only what each person needs, and efficiency gains happen automatically.
How Lore maps onto AWS
Data flows through these components:
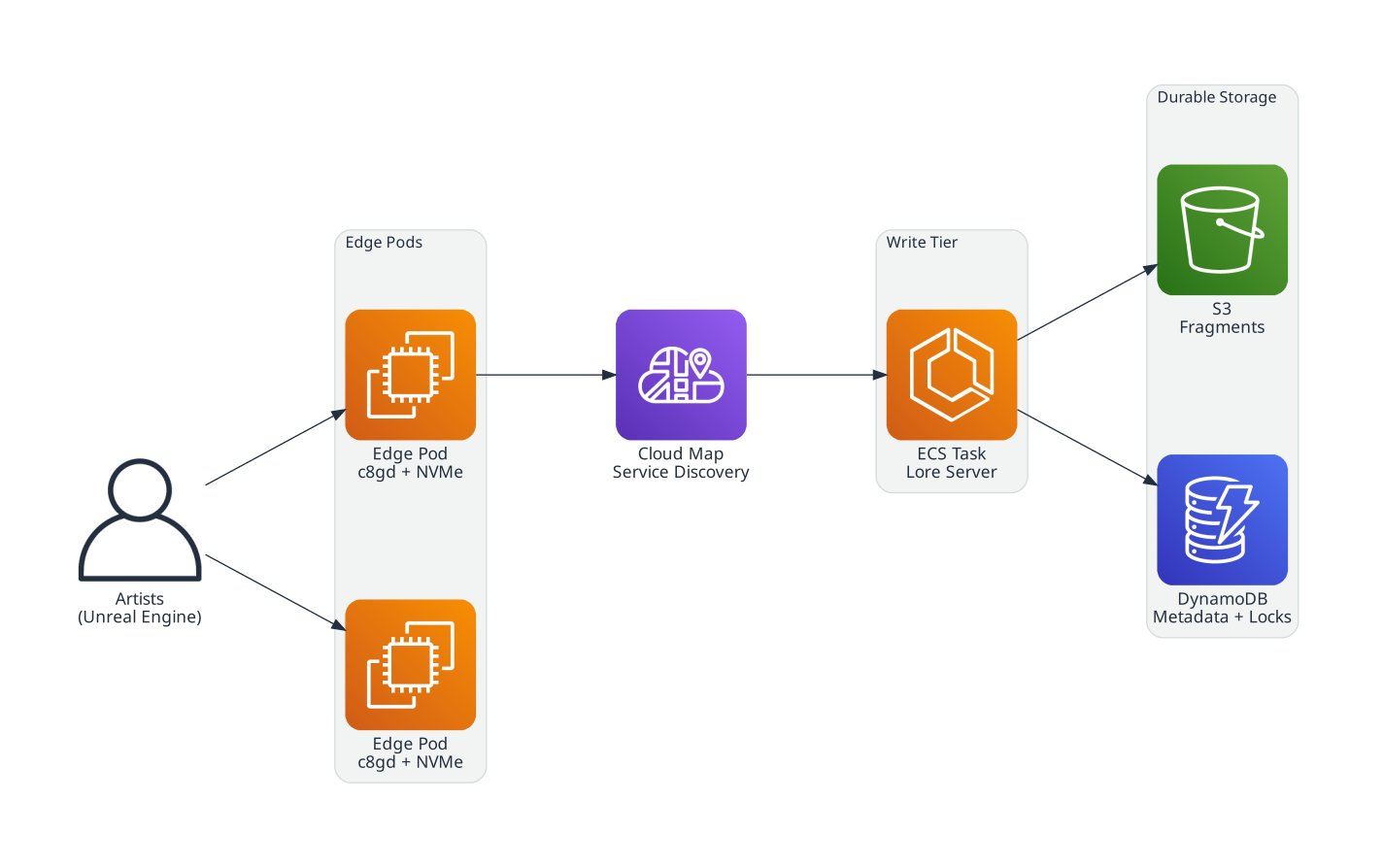
- Edge pods: C8gd instances on Amazon EC2. Clients connect to edge pods directly over QUIC, a multiplexed UDP protocol that saturates the link and recovers from packet loss without stalling. Each pod has terabytes of local NVMe for caching. On pull, fragments serve from NVMe. Cache misses hydrate from the write tier transparently.
- Write tier: Amazon ECS. The write tier owns durability. On push, edge pods forward new fragments to the write tier, which deduplicates and persists them to S3. On pull, it serves fragments to edge pods from memory, loading from S3 on first access.
- Durable storage: Amazon S3. Every unique fragment lives in S3. Fragments are immutable and content-addressed. Write once, read many.
- Metadata and locks: Amazon DynamoDB. Tables handle file metadata, fragment references, locks, and branch pointers. Single-digit millisecond reads for lock checks, which matters when 50 people are competing for exclusive locks. No database server to manage.
- Service discovery: AWS Cloud Map. Edge pods find the write tier via private DNS. When the write tier recycles, DNS updates in seconds, so teams are never impacted by infrastructure updates.
The result is a shift in how studios think about version control. When branching is free and storage growth is sub-linear, teams can experiment more aggressively. When fragments are shared across projects, studios can build reusable asset libraries at scale. Capabilities like these open new approaches to how studios organize and share work.
To get started, Lore’s source code is available on GitHub. To deploy Lore on AWS, we’ve published an open-source Terraform module: terraform-aws-lore. The module handles the full stack: networking, compute, storage, metadata, and auth. Defaults work for initial deployment, and studios can tune configuration to their specific needs. See the module README for prerequisites and deployment steps.
What’s next
This post introduced Lore’s approach to binary asset storage and its architecture on AWS. Running Lore in production means thinking about scale, integration with existing pipelines, and how the system fits into the broader Epic toolchain. Future posts in this series will explore:
- Scaling and resilience: Multi-region deployments, multi-tenant authorization for studios managing multiple projects, and automated failover for globally distributed teams.
- The Epic ecosystem: How Lore integrates with Unreal Engine’s broader toolchain.
- End-to-end pipeline: A Cloud Game Development Toolkit module pairing Lore with Horde for a complete build and asset pipeline.
To learn more about Lore, visit lore.org. For help evaluating it for your studio, contact your AWS account team.