AWS HPC Blog
Automate scheduling of jobs on AWS Batch and AWS Fargate with Amazon EventBridge
Introduction
One of the simplest ways to help streamline your automation needs is to employ a job scheduler and remove the requirement to manually execute tasks. As businesses embrace automation to do more with less, job schedulers have established themselves as a critical part of any business’s IT operations. As such, the reliability, scalability, performance, and cost effectiveness of the scheduling platform becomes a bigger consideration. It’s no surprise that we are often engaged in conversations with customers asking us how they may leverage an AWS service to replace legacy on-premise job scheduler solutions.
In this blog post we will explain how you can use AWS Batch, AWS Fargate and Amazon Event Bridge to create a fully managed and serverless, cloud-native, job scheduling solution, with a specific focus on containerized jobs. We will provide a technical overview of the different components that make up this solution and cover some of the key considerations to help you determine if this solution is a good fit for your needs.
Overview
The following solution showcases an AWS Batch on AWS Fargate environment where jobs, which run on container images provided by the end user, can be configured to run on a schedule or in response to some event. In this blog post we will be configuring the jobs to run on a schedule using Amazon EventBridge Scheduler. It also covers how to pass secrets into these container jobs to connect to back-end systems like databases, and how to centralize the logs from these jobs. This solution also caters to jobs which require central storage for generated artifacts like reports.
Additionally, the architecture is designed with cost optimization and operational efficiency in mind—all services used take advantage of low cost AWS serverless technologies or managed services. This helps remove the undifferentiated heavy lifting of managing the underlying compute resources.
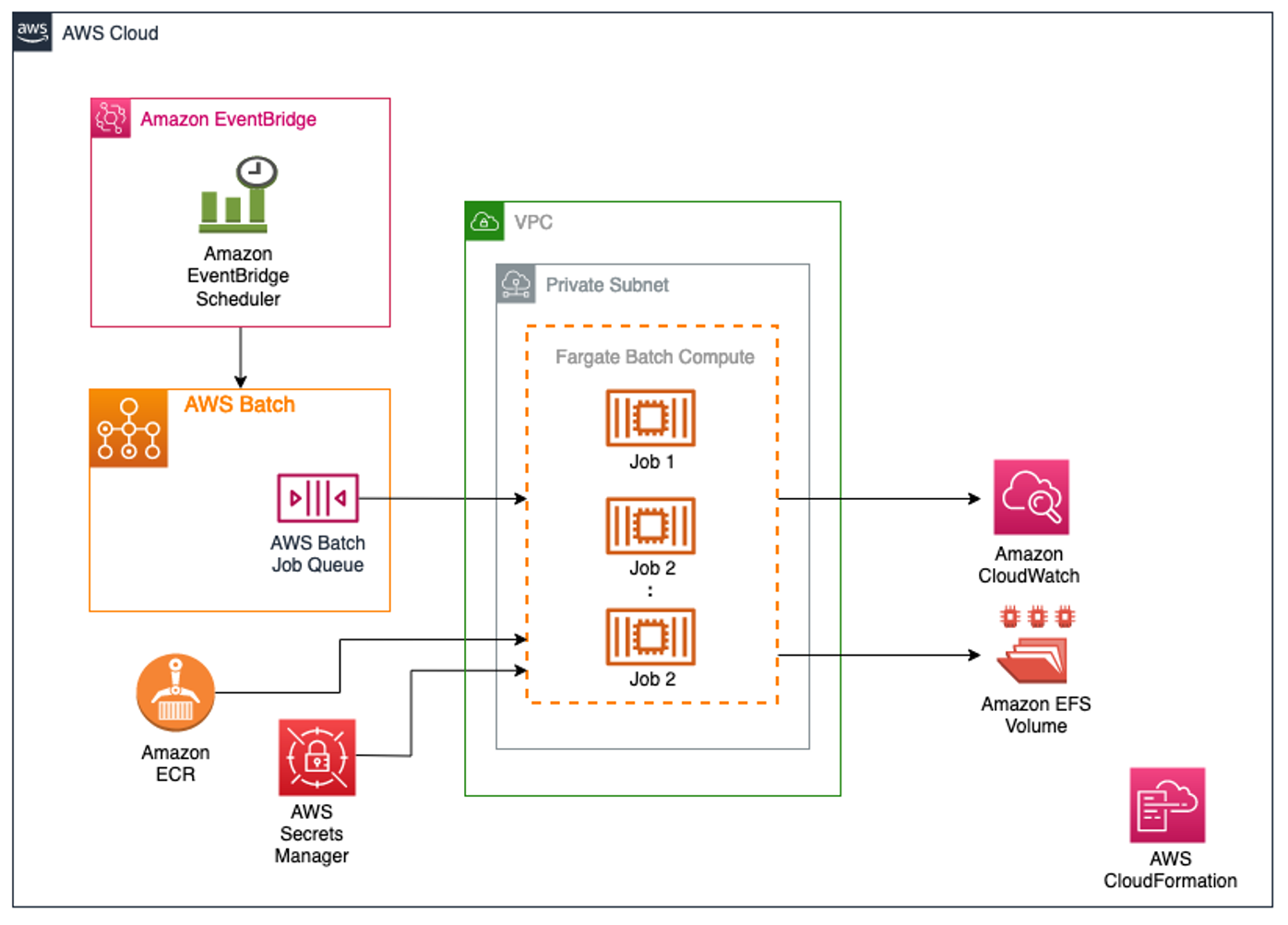
Figure 1: High-Level architecture of the solution showing how schedules defined in Amazon EventBridge initiate AWS Batch jobs, which in turn can pull container images from Amazon ECR or secrets from AWS Secrets Manger, and push data and logs to Amazon EFS and Amazon CloudWatch, respectively.
Before we jump into the implementation, lets quickly introduce each of the services called out in the architecture and its function:
- AWS Batch helps you to run batch computing workloads on the AWS Cloud. A job definition is created to specify how a job is to be run, and includes details such as the job container image, and any required parameters and secrets.
- AWS Fargate is a serverless, pay-as-you-go compute engine that can be used with AWS Batch to easily run and scale containerized data processing workloads without the need to own, run, or manage compute infrastructure.
- AWS Secrets Manager is used to securely store and manage secrets which can be passed securely to the jobs in AWS Batch.
- Amazon CloudWatch Logs enables you to centralize the logs from all of your systems, applications, and AWS services that you use including AWS Batch, in a single, highly scalable service.
- Amazon EventBridge Scheduler is a serverless scheduler that allows you to create, run, and manage tasks from one central, managed service. It can be used to schedule automated actions that are invoked at certain times using cron or rate expressions. By setting an AWS Batch job as a target, EventBridge can run the job on a schedule.
- Amazon Elastic Container Registry (Amazon ECR) is an AWS managed container image registry service where users can store their own job container images for selection in AWS Batch job definitions.
- Amazon Elastic File System (EFS) provides serverless, fully elastic file storage so that you can share file data without provisioning or managing storage capacity and performance, and is a useful option for storing and sharing job artifacts.
Implementation
For this solution, we are using AWS Fargate as the compute resource and AWS Batch to run various job definitions. As shown in Figure 2, we are using a public ECR image which is available from the Amazon Public ECR Gallery. Alternatively, you can upload your own image to a private ECR repository and pass the image URL in the AWS Batch job definition. If you use a private ECR repository, you will need to verify that the Batch execution IAM role is able to access it.
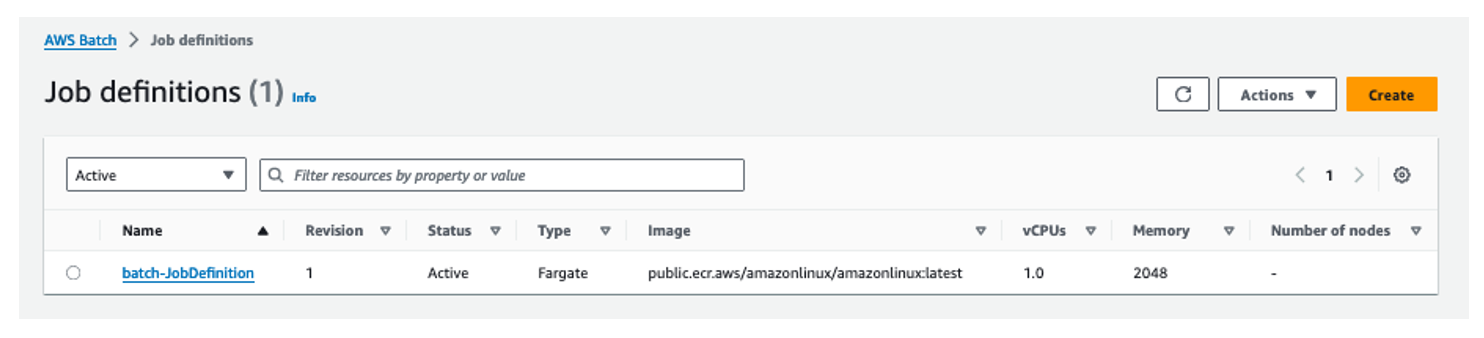
Figure 2: AWS Batch Job Definitions example depicting one active Fargate job.
We utilized Secrets Manager to store three secure variables that will be used later in this example. They represent a username, a password, and a connection string. Review the Create an AWS Secrets Manager secret documentation for more information on this process.
Shell scripts can be used as the entry point to the container to perform any desired task, such as start an ETL process, run SQL scripts against an AWS RDS database, or pull and analyze data from S3.s seen in Figure 3 below, we pass multiple variables to the shell script.
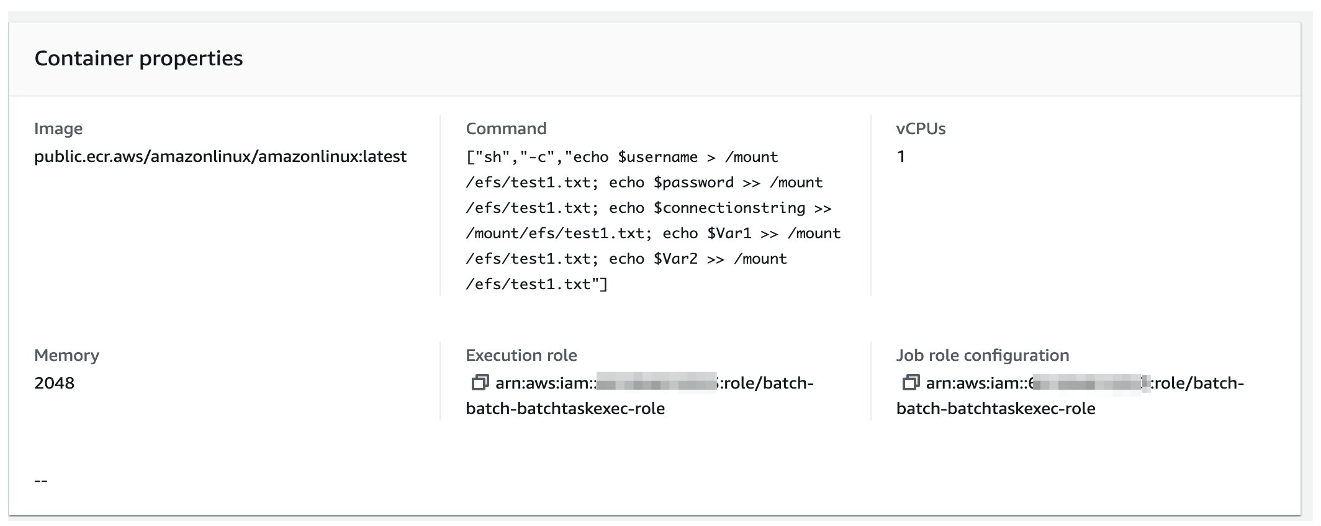
Figure 3: AWS Batch Job Definitions – Container properties details depicting bash commands.
As part of the AWS Batch job definition, we define two environment variables, $Var1 and $Var2, along with AWS Secrets username, password and connectionstring, as shown in Figure 4 below. For demonstration purpose, we are simply writing these parameters to an EFS file system that is mounted to the container. You can leverage these features to customize how you pass parameters to run application or database jobs through AWS Batch. You can create multiple job definitions and can pass variables and secrets based on specific job or application requirements.
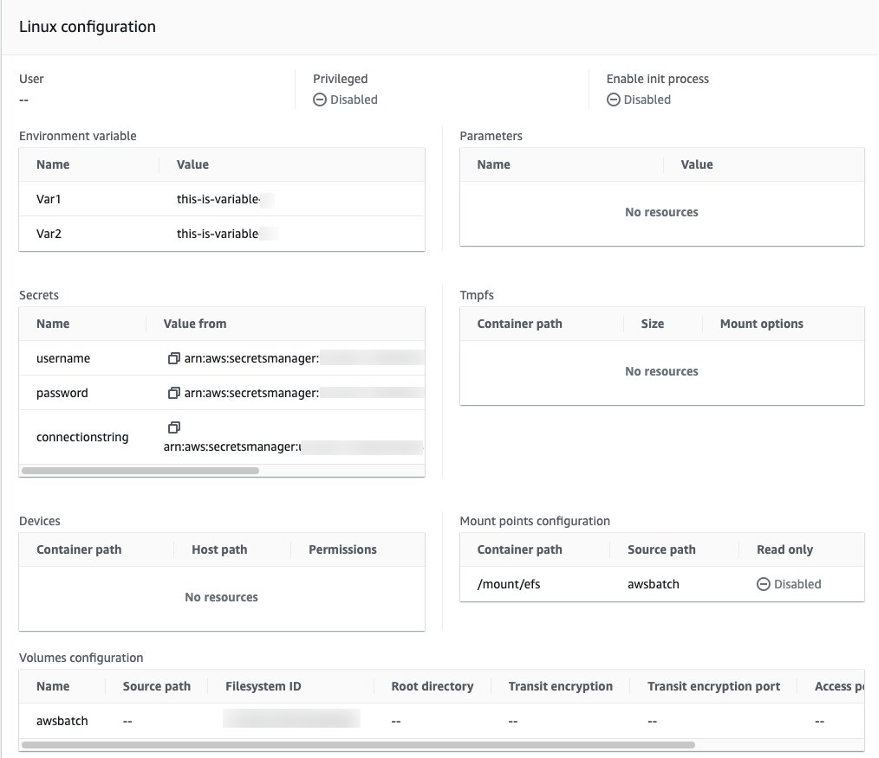
Figure 4: AWS Batch Job Definitions – Linux operating systems configuration depicting environment variables & EFS mount points
To run these Batch job definitions on a schedule, we are relying on Amazon EventBridge Scheduler. With Amazon EventBridge Scheduler, we can create complex schedules to run jobs. Figures 5 and 6 below shows how we create a schedule for our job. You can customize the EventBridge Scheduler schedule to meet your specific needs using a cron expression as highlighted in Figures 5 below, or you can specify regular intervals. This gives you the flexibility to schedule daily/weekly or monthly jobs to run and reduce maintenance cost.
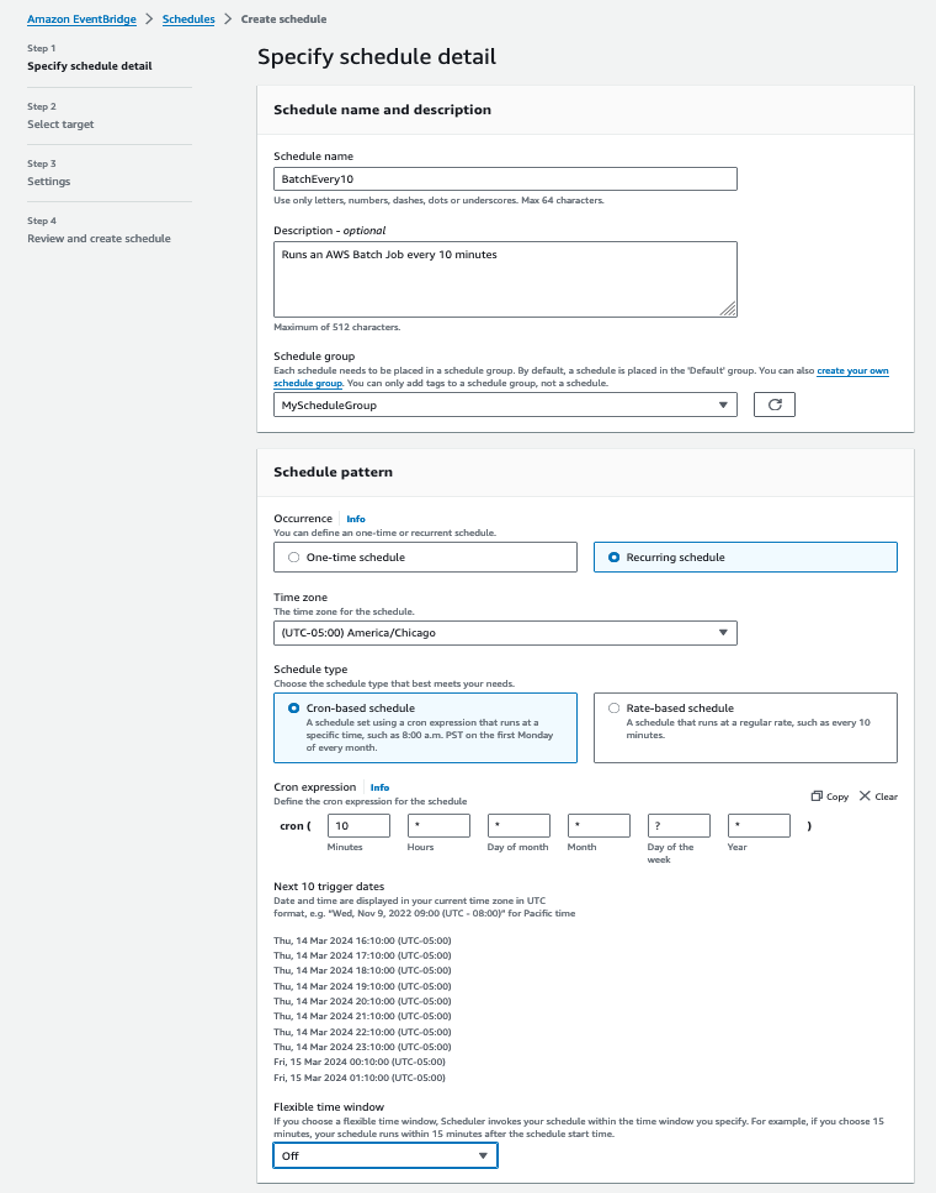
Figure 5: Amazon EventBridge Scheduler details screen highlighting the schedule pattern.
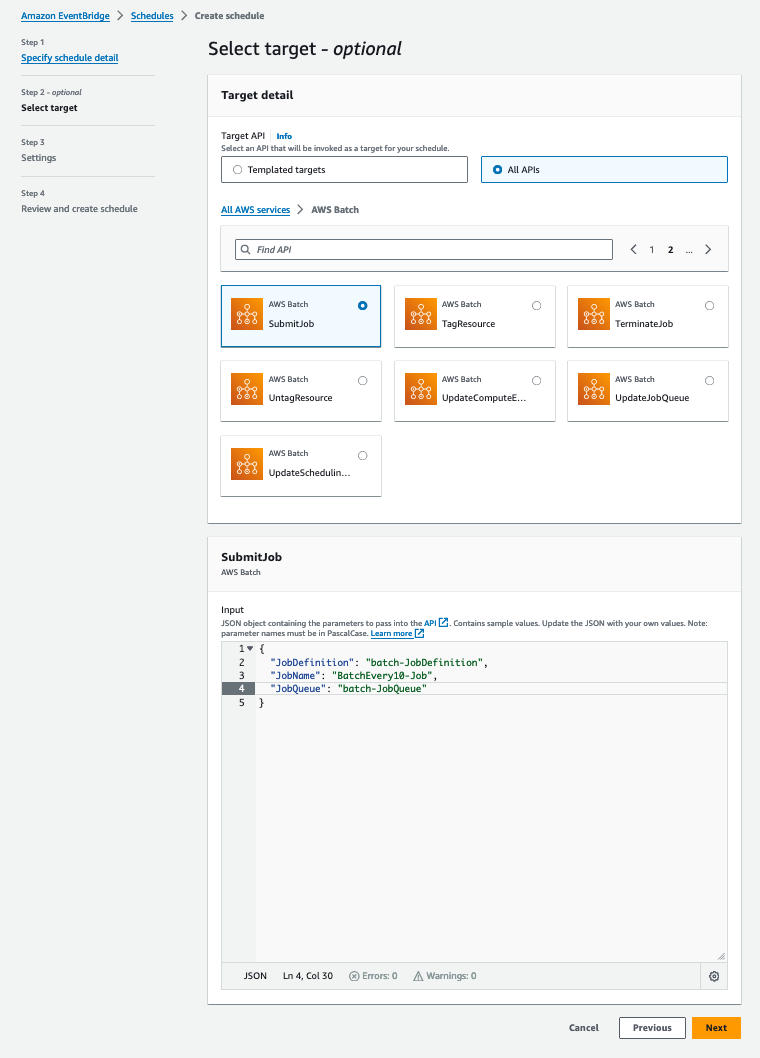
Figure 6: Amazon EventBridge Scheduler Select Target screen highlighting how to submit the Batch Job.
The AWS Batch management console has a built in dashboard where we can see how many jobs are ready to run and the number of successful and failed jobs. As we have shown in Figure 7, you can observe the status of previously executed jobs and take necessary action based on requirements. AWS Batch retains job information for a minimum of 7 days.
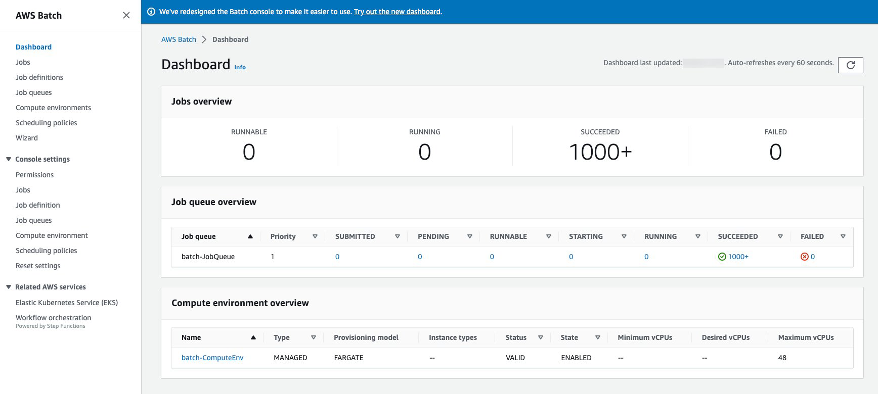
Figure 7: AWS Batch Success/Running Dashboard showing multiple successful job executions
If there are any failed jobs, you can use CloudWatch Logs to troubleshoot further. In our example, the job definition is using the awslogs Log driver to send logs to a CloudWatch log group called batch-loggroup, as shown in Figure 8.
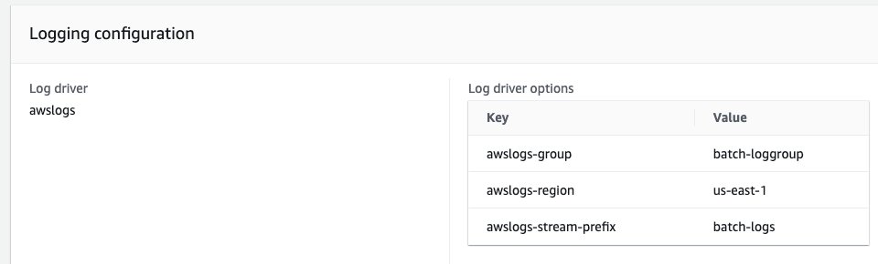
Figure 8: AWS Batch Job Definition – Logging configuration detail panel with awslogs driver options
Figure 9 shows the log files with date and time information of respective batch jobs. You can get a detailed analysis of those jobs and troubleshoot as necessary.
Figure 9: CloudWatch Batch Log Group log stream details
Considerations
AWS Batch runs jobs at scale and optimizes for throughput and cost, while giving you powerful queueing and scaling capabilities. However, not every workload is best run on Batch on Fargate. Here are some important things to consider when configuring AWS Batch jobs:
- Very short jobs. If your jobs run for only a handful of seconds, the overhead to schedule your jobs may be more than the runtime of the jobs themselves, resulting in less-than-desired utilization. In this case, AWS Lambda might be a better option. Or, staying with Batch, a workaround is to binpack your tasks together before submitting them in Batch, then having your Batch jobs iterate over your tasks. A general guidance is to binpack your jobs is to: 1) stage the individual tasks arguments into an Amazon DynamoDB table or as a file in an Amazon S3 bucket, ideally group the tasks in order to get your AWS Batch jobs to last of 3-5 minutes each 2) loop through your task groups within your AWS Batch job.
- Jobs required to run immediately. While Batch can process jobs rapidly, it optimizes for cost, priority, and throughput rather than instantaneous job execution. This implies that some queue time is desirable to allow Batch to make the right choice for compute. If you need a response time ranging from milliseconds to seconds between job submissions, you may want to use a service-based approach using Amazon Elastic Container Service (Amazon ECS) or Amazon Elastic Kubernetes Service (Amazon EKS) instead of using a delayed-start, batch-processing architecture.
- Batch Compute – Fargate vs Amazon Elastic Compute Cloud (Amazon EC2).AWS Fargate requires less initial setup and configuration than Amazon EC2 and you don’t need to manage servers, handle capacity planning, or isolate container workloads for security. So, if your jobs must start quickly, specifically less than 30 seconds, or the requirements of your jobs are 16 vCPUs or less, no GPUs, and 120 GiB of memory or less, then Fargate is the recommended choice. However, if you require specific control over instance types, a high level of throughput or concurrency, custom Amazon Machine Images (AMI’s), or have requirements for resources Fargate does not provide, such as GPU or more memory for example, we recommend Amazon EC2.
- Spot Instance usage.Most AWS Batch customers use Amazon EC2 Spot Instances because of the savings over EC2 On-Demand instances. However, if your workload runs for multiple hours and can’t be interrupted, On-Demand instances might be more suitable for you. You can always try Spot Instances first and switch to On-Demand if necessary.
For more information, please review the Best Practices for AWS Batch documentations.
Conclusion
AWS Batch on AWS Fargate is an excellent option when looking for a low cost, scalable solution for running batch jobs, with low operational overhead. In this blog we hoped to cover some of the common use cases when configuring batch jobs, as well as considerations when identifying when Amazon Batch may or may not be a good fit. To get started, out the Getting Started with AWS Batch documentation.