AWS for Industries
Improving the Utilization of Wearable Device Data using an AWS Data Lake
The key to meaningful progress in key global healthcare initiatives, like value-based care, reduction in costs, reduction of errors, and improving outcomes, lies within the vast quantity of data from sources ranging from medical imaging to electronic medical records. IDC projects the total universe of healthcare data to grow approximately 400% between 2020 and 2025, and with it the potential for better predictive diagnoses, individualized therapies, and new efficiencies that can increase access to care while controlling costs. To realize that potential, the data must be made actionable, which is where the storage and computing capacity of the cloud—and cloud-driven artificial intelligence and machine-learning solutions—come into play.
Healthcare and life science customers are looking to aggregate data from multiple sources, to make a determination of a patient’s condition. This aggregated data either leads to a improved insight of the patient’s condition, offering the ability to model the progression of the underlying condition, which eventually gives our customers the potential to predict the onset of conditions, leaving our healthcare providers armed with insights to be better prepared to provide the appropriate care. The data sources, which once used to be restricted to acute healthcare settings, now include data from wearable devices on the patients. The key drivers for this trend are 1) increasing trend in chronic diseases, which require continuous monitoring and disproportionately consume our resources, 2) migration of care away from acute to sub-acute or home settings, 3) advancement in sensor technologies, such as CGM (continuous glucose monitors), and 4) the impetus of contact-less care required by Covid-19 pandemic. In addition to the medical grade wearable devices, there has been an explosion in the availability of consumer grade wearable devices. The large collection of data from consumer grade devices, and relevant insights drawn from it, are directly applicable to the health and wellness market.
In this paradigm the critical aspects are: 1) data ingestion and processing and 2) data modeling, using AI/ML tools such as Amazon Sagemaker. Given the growing number of wearable devices, both medical and consumer, in this blog we explain the processing of data from wearables.
Technical Challenges
The market for smart wearable technology is booming, largely in part to the consumer health and fitness trend across consumers. In addition to the rapid growth in the consumer use of wearable devices, there has been a corresponding increase in interest in using wearable data for assessing patient health. This growth is predominantly driven by the fact that wearable devices can continuously monitor patients outside of a clinical setting. This provides clinicians with a more comprehensive, longitudinal view of patients’ overall health. This is particularly true, where data collected by wearables can be used to detect potential illness or disease, such as sleep apnea, cardiac disease, or mental illness. In addition, the capability of sensors that wearable devices employ for measuring health and wellness are continually expanding, with clinically validated sensors, such as EKGs, becoming more popular in consumer devices.
Wearable devices are used to record a variety of personal health and wellness measurements, such as heart rate (HR), sleep patterns and duration, and walking steps and physical activities. They can be worn either full or part time to provide useful insights into an individual’s health and behavior. The data recorded by these devices can be sampled multiple times a millisecond, or less frequently (e.g., every minute, hourly), depending on the type of data the device is collecting, the accuracy of the sensors that the device has, and the heuristics for balancing sample rate and battery usage. The data that wearables record is generally sent to a central location for storage and processing. The data can be sent continuously; however, it is likely cached on the device or the user’s phone and uploaded at certain times throughout the day, or under specific circumstances (e.g., when the user’s phone connects to Wi-Fi).
To support research involving wearable data across a broad population of study participants, researchers need to manage data with varying sample frequencies, upload frequencies, and data formats, as there are presently no standards across major wearables device manufacturers. Consequently, ingesting this data from multiple sources and converting it to a consistent format (to be analyzed or used for ML training and inferencing) can be very challenging. However, researchers can employ data lake patterns for extracting, transforming, and loading this data to be able to process and analyze without having to develop tools and techniques for each data source.
In this blog post, we share techniques for ingesting data from wearable devices into a data lake, then transform the data into a format that can easily queried, and used to build and train machine learning models. The models can be used to derive real-time or periodic insights from wearable data uploaded into Amazon S3.
The following use cases can be supported by the proposed solution deployed on AWS:
- Ingesting small/medium/large study data from different wearable biosensors devices from multiple vendors
- Ingesting on-boarding survey data, daily survey data, and terminating survey data to analyze trends along with other participant information
- Supporting customized transformation of various input formats
- Analyzing data using existing solutions or building new ML solutions
- Creating dashboards to share the analysis; publishing & sharing the dashboards with others
Solution Overview
 Data lake architecture diagram for ingesting and analyzing medical device data
Data lake architecture diagram for ingesting and analyzing medical device data
The following AWS services are used for ingesting and processing the data:
- Amazon Simple Storage Service (Amazon S3) is a scalable object storage service that hosts the raw data files and the processed files in the data lake for millisecond access.
- Amazon Simple Queue Service (SQS) is a message queuing service that enables you to decouple and scale data ingestion in this use case. We also have a retry logic applied in the queue.
- Amazon DynamoDB is a NoSql database that delivers single-digit millisecond performance at any scale and is used to avoid processing of duplicates files.
- Amazon Simple Notification Service (Amazon SNS) is a fully managed messaging service for both application-to-application (A2A) and application-to-person (A2P) communication that is used to send email alerts.
- AWS Lambda is a compute service that lets you run code without provisioning or managing servers and is used to trigger appropriate AWS Glue jobs.
- AWS Key Management Service (KMS) makes it easy for you to create and manage cryptographic keys and control their use across a wide range of AWS services and in your applications.
- AWS Systems Manager Parameter Store provides a centralized store to manage your configuration data. This allows you to separate your configuration data from your code.
- AWS Glue is a serverless data preparation service that makes it easy to Extract, Transform and Load (ETL) data. An AWS Glue job encapsulates a script that reads, processes, and then writes data to a new schema. This solution uses Python3.6 Glue Jobs for ETL processing.
- Amazon Athena is an interactive query service that can query data in S3 using standard SQL queries using tables in a Glue Data Catalog. The data can be accessed via JDBC for further processing such as displaying in BI dashboards.
- Amazon CloudWatch is a monitoring and observability service that provides you with data and actionable insights to monitor your applications, respond to system-wide performance changes, etc. The logs from AWS Glue Jobs and Lambda functions are saved in CloudWatch logs.
According to the security requirements to process the Protected Health Information (PHI) data, we need to take the following into consideration:
- Use of HIPAA quick start or AWS Control Tower network infrastructure
- Use of security keys for encryption at REST and in-transit
- Solution allowing audit of the data being ingested and consumed
- Access to resources based on least privilege principle
The following diagram illustrates the restricted VPC access to AWS services complying the security requirements:
 Security architecture based on VPC restricted access to AWS services
Security architecture based on VPC restricted access to AWS services
Prerequisites
To follow the deployment walkthrough, you need an AWS account.
A Python development environment is also required to enhance functionality in AWS Glue and Lambda.
Deployment Walkthrough
- Follow the Reference Architecture for HIPAA on AWS Quick Start instructions to create VPCs and subnets for your network. Or, set up the network baseline through AWS Control Tower. If you already have your existing VPC and subnets, you can skip this step.
- Create an S3 bucket “aws-glue-scripts-<ACCOUNT_ID>” via the console.
- Download the sample Python AWS Glue job heart_rate_job.py from https://medical-device-data-lake.s3.amazonaws.com/heart_rate_job.py and Save it to the S3 bucket created above. Record the S3 key of the uploaded file – it is needed in the next step. This is a sample AWS Glue job that is deployed in your solution. You can download a sample data file to test from https://medical-device-data-lake.s3.amazonaws.com/P1.20201012.heart_rate.csv.
- Deploy the CloudFormation (CFN) template for the data lake infrastructure using either of these two options:
Option 1: One-click deployment to create data lake infrastructure without VPC network isolation, where the data flow traffic will go through public internet. This CloudFormation stack creation may take up to 5 minutes.
![]()
Option 2: One-click deployment to create data lake infrastructure within VPC, where the data flow traffic will be restricted within VPC. The network isolation will ensure a more secure data lake environment. This CloudFormation stack creation may take up to 25 minutes.
![]()
In both of these options, you will receive an SNS topic subscription confirmation email during the stack creation process. Confirming your subscription will let you receive Lambda function processing statuses.
The following table provides a list of the CFN parameters used in the deployment. Please edit the values in the AWS console for your own deployment.

*Only available for Option 2 CFN deployment with VPC network isolation.
If the Option 2 deployment is selected, the Lambda functions will be created within the provided VPC subnets, and it will access other AWS Services via VPC endpoints. To allow AWS Glue jobs to be restricted to the VPC network isolation and access other AWS services via VPC endpoints, you will need to carry out some extra steps: create AWS Glue connections of type “Network” following the steps in Crawling an Amazon S3 Data Store using a VPC Endpoint; associate the AWS Glue connections with the sample AWS Glue job named “heart_rate_job”.
To ensure high availability, create two AWS Glue connections pointing to different subnets in the given VPC. The AWS Glue connections will ensure that all the traffic from the AWS Glue jobs flows through the VPC network. Since the AWS Glue connection will use the available IP addresses from the configured subnets to run the AWS Glue jobs, make sure that you have sufficient IP addresses for all the possible jobs to run in parallel.
- Test data ingestion by putting the sample file from #3 into the staging bucket inside the “StagingFolderPrefix” location. The default prefix value is “staging/input/”. This lets you put the input data files in a non-root folder. Out of box, this solution supports the following input data schema in these different formats:
a) Tabular format including CSV and Parquet
-
-
- The file name should be “patientId.date.metric.csv” or “patientId.date.metric.parquet”
- Each entry in the sample data represents a unique metric value for a given minute, as shown here:
-

-
-
- Additional metrics can be easily added as new columns, and the time interval unit can be changed as well. For instance, we can use millisecond for three different metrics in the following dataset:
-

b) JSON format
-
-
- The file name should be “patientId.date.metric.json”
- Each row in the file will be a separate JSON object, such as
{“patient”:“patient_id”,“survey_type”:“daily_survey”, “other_attributes”:{} }
-
The AWS Glue job can be tweaked to handle different data formats. To handle data deduplication, you can use either of the following options:
Option 1: In the AWS Glue job, iterate over DataFrame and use any combination of fields to filter out duplicate rows (i.e., using same time stamp or same id).
Option 2: Use AWS Glue machine learning transforms, as explained in Matching Records with AWS Lake Formation FindMatches, to automatically identify and filter out duplicate rows.
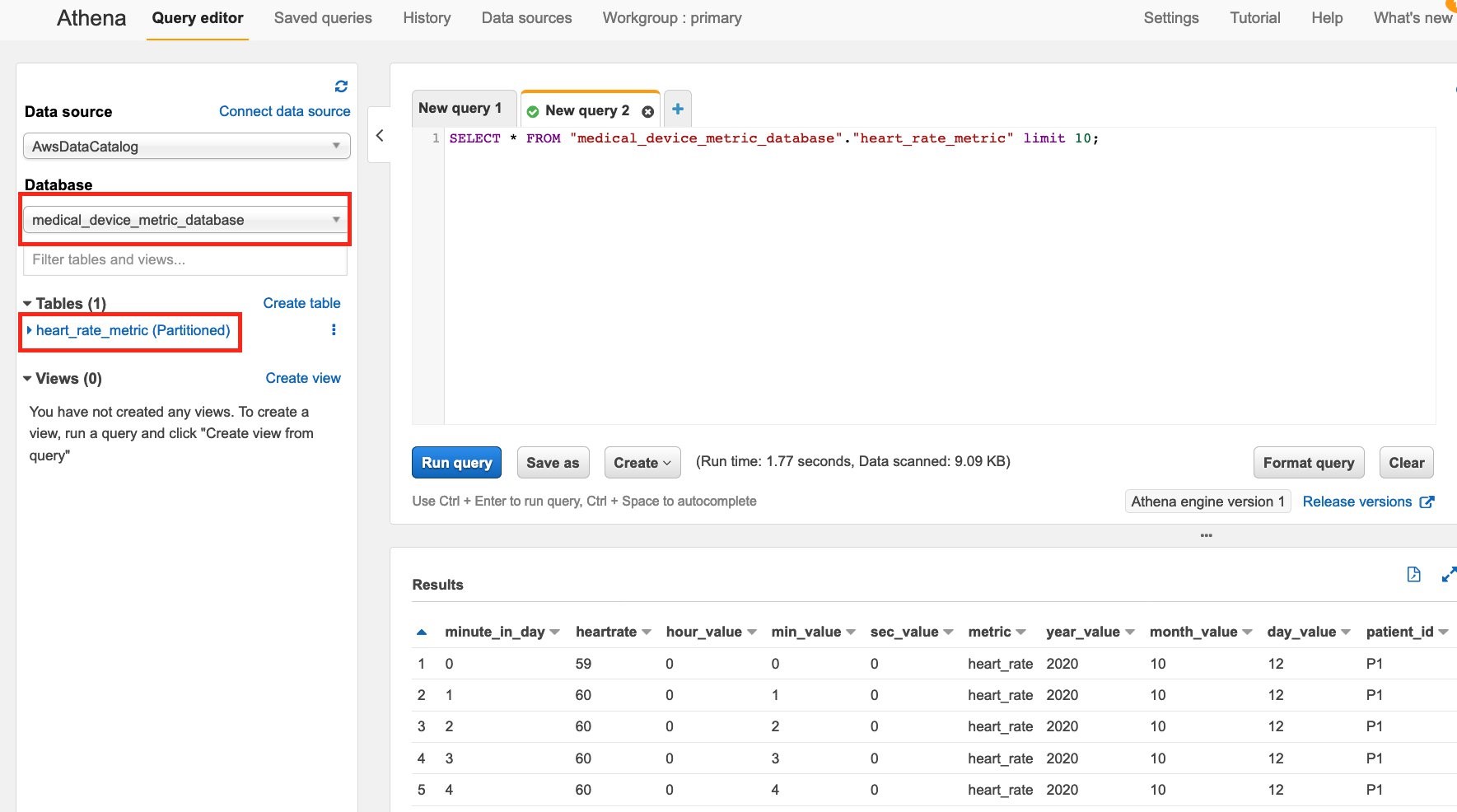
Once the data file is successfully processed, you should be able to see new logs for the Lambda function “SQSTriggerLambdaFunction” in the CloudWatch console. This shows the receipt of the input file, which triggered the AWS Glue job. You can check the success/error logs in CloudWatch log groups “/aws-glue/python-jobs/output” and “/aws-glue/python-jobs/error”. To confirm the data has been successfully ingested to the data lake, go to the AWS Athena console and check if the table has been created inside the metrics database.
- (Optional) To create another AWS Glue job that can handle different input data set, go to the AWS Glue console and click “Add job”.

Fill in the required parameters, including the name, IAM role, and script file name and location.
 Enter the Python library path, which can be copied from the existing “hear_rate_job”.
Enter the Python library path, which can be copied from the existing “hear_rate_job”.

From here, configure the “SQSTriggerLambdaFunction” Lambda function to add your new AWS Glue job name.

To learn more about using AWS Data Wrangler in Python ETL pipeline, see Optimize Python ETL by extending Pandas with AWS Data Wrangler. If you want to use Amazon QuickSight for data analytics and visualization in this data lake, see Organize and share your content with folders in Amazon QuickSight.
Cleaning Up
- Remove all files in “medical-device-datalake-bucket” and “medical-device-processed-bucket”.
- Delete all items from the DynamoDB table “file_metric_table_1”.
- Delete the CFN stack to avoid unexpected future charges.
Conclusion
We have demonstrated how to build a data lake on AWS to ingest, transform, aggregate, and analyze data from the wearable devices. We used code automation via AWS CFN deployment to create a robust data lake stack with options for network isolation. The VPC option may be required by regulation to restrict data flows within private network on AWS, rather than using public internet.
Building a data lake using CFN automation allows a range of possibilities, from potentially accelerating project timelines to implementing robust, scalable systems. For tight integration, reduced costs, and large-scale data applications, we encourage you to leverage CloudFormation. If you want to de-identify the input data set, you can setup a pre-process Lambda function in the ingestion step, and map from patient id values (or any other value that needs to be de-identified) to anonymize new values into a new file and send the file into the data processing step.
If you want to use this data lake with Fast Healthcare Interoperability Resources (FHIR), you can process and index the unstructured free text such as clinical notes, lab reports, insurance claims, and more in Amazon HealthLake. Then, the enriched, structured FHIR resources can be exported from HealthLake and integrated with medical device time series data in this data lake.
To find the latest development to this solution, check out the Analysis of Medical Device Data using Data Lake repository on GitHub.
More resources:
- HIPAA Compliance on AWS
- Whitepaper: Architecting for HIPAA Security and Compliance on Amazon Web Services
- Powering HIPAA-compliant workloads using AWS Serverless technologies
- Reference Architecture for HIPAA on the AWS Cloud: Quick Start Reference Deployment
If you are looking to learn more about AWS for Healthcare & Life Sciences, join us on the web at www.aws.amazon.com/health.