AWS for Industries
Navigating the EU Data Act for IoT Solutions: Part 2- Data Discovery and Classification, Management, Accessibility, and Governance
In part 1- Healthcare Industry lens, we shared an overview of the impact of the European Union (EU) Data Act on Healthcare IoT, Act core requirements, and demonstrated how Amazon Web Services (AWS) services can be used to create data workflows to support efforts to meet requirements.
Technical implementation guide
Now that you’ve learned about the EU Data Act and example use case in the last blog post, over the next few sections, we will show you examples of solution architectures that can meet your data governance requirements for data discovery, classification, privacy, and access management. These generic requirements will help you on your journey to EU Data Act compliance.
Data Discovery and Classification for Data Privacy
The EU Data Act interlinks with requirements from other EU regulations such as the General Data Protection Regulation (GDPR). Data classification is a foundational step in cybersecurity risk management. AWS has tools that can help you meet the GDPR requirements by correctly identifying and classifying data. AWS provides prescriptive guidance on this topic in our Data classification overview white papers. For the purposes of this use case, we are interested in identifying and labeling Personally Identifiable Information (PII) or Protected Health Information (PHI) data in DICOM metadata, patient demographics, patient measurement data, timestamps, location data, log data, and clinical annotations. This activity is an essential process for managing your compliance position regarding many data privacy frameworks. Amazon Macie is a tool that can be used to automate this activity for both PHI and PII, as well as other types of sensitive information stored in Amazon S3. Visit the Macie documentation for a full list of supported data types.
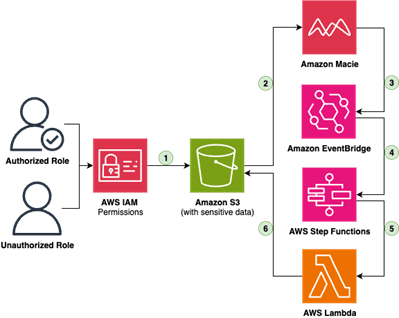
Figure 1 – Data discovery and classification architecture
- Data is ingested into the Amazon S3 bucket
- Amazon Macie scans the S3 bucket on a regular basis
- Amazon Macie discovers an object containing PII or PHI
- Amazon EventBridge rule is triggered
- The target for the EventBridge rule is an AWS Step Function which will trigger a remediation workflow.
- The workflow is an AWS Lambda function that creates a new tag for the object, “ClassificationLevel:PII
Now that your example data has been discovered and tagged, we can use that label in a conditional AWS Identity and Access Management (IAM) policy to control access to the object. Alternatively, you could enable other automated processing activities such as anonymization, pseudo anonymization or encryption with tools such as AWS Glue. The policy below is applied to the Amazon S3 bucket, and only allows an IAM role or user with the tag “AccessLevel:PII” from accessing any file labeled with the tag “ClassificationLevel:PII”.
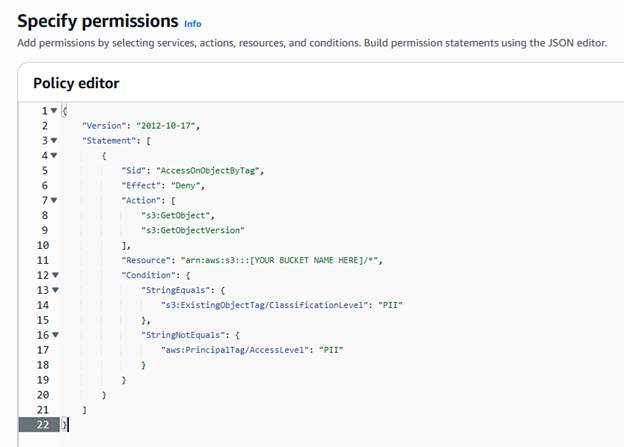
In this section, we have shown you how to use Macie to discover PII, Lambda to tag the data, and IAM to enable ABAC access control.
However, Amazon Macie is not your only option. Depending on the data types you want to redact, you can use other services as shown in the table below. You should also consider the volume of data, the usage pattern and the pricing for each of these service options. If you have volume data available, then you can use the AWS Pricing Calculator to help you estimate the costs.
As an alternative to Amazon Macie, you can also use AWS Glue to detect and redact PII data in an object that contains structured data. You can create a visual extract, transform, and load (ETL) job that will take your source S3 bucket, apply a custom transformation to the data, before writing the data back to a bucket. For example, you can write a custom transformation that would read a JSON file, encrypt the value of any PII fields in that file, and write the file to at S3 bucket.
Finally, you can also look at Amazon Comprehend which can also detect and redact PII but only in text documents.
All of these are managed services for doing the same job, but two key differences you should note are pricing, the ability to opt-out of cross-region transfers for Comprehend and Glue, and supported languages for Amazon Comprehend, Amazon Comprehend Medical (US-English only), AWS Glue, and Amazon Macie.
| Service | Purpose | Pricing Model | Opt-Out | Data Type |
| Amazon Comprehend | General text analysis | Price is per unit where a unit = 100 characters | Supported | -Documents
-Images with text |
| Amazon Comprehend Medical | Healthcare-specific text analysis | Price is per unit where a unit = 100 characters | Supported | -Plain text (.txt) files
-UTF-8 encoded text |
| AWS Glue | Data integration and transformation | Price is per unit of cpu and memory utilization as DPUs, charged per second | Supported | -Structured data: CSV, JSON, Parquet, ORC, Avro
-Semi-structured data: XML, logs -Database tables: MySQL, PostgreSQL, Oracle, SQL Server -Data lake formats: Parquet, ORC, Avro -Streaming data sources -Custom data formats through custom connectors |
| Amazon Macie | Data security and privacy protection | Pricing is based in volume of data in the buckets being scanned | Not supported | -Structured data formats: CSV, TSV, JSON
-Storage formats: Parquet, Avro, ORC -Document formats: PDF, DOC/DOCX, XLS/XLSX, PPT/PPTX -Text files and logs -Compressed archives: ZIP, TAR, GZIP |
Data management architecture
With our data now labeled and access controls established, we can implement secure data sharing where only authorized identities can access only PII, only PHI, or PII and PHI. This ensures sensitive information is available exclusively to processes with legitimate business needs while maintaining regulatory compliance and preventing unauthorized access.
However, we want to be able to serve the same files to all users from a S3 bucket, without having to have a redacted version of the file in a separate bucket which would result in unnecessary duplication and cost. This is where S3 Object Lambda access points can help by implementing just-in-time data redaction. The simplified architecture below shows us how we can have two endpoints pointing to the same bucket. One is your standard endpoint that is exposed via API gateway, where you issue a GET request and the S3 service returns you a copy of the original file, decrypted and ready to use with all the PII intact. The other endpoint uses a Lambda function, which anonymizes the file when a GET request is issued. You can then manage access to the API endpoints using role-based access control (RBAC) with IAM tags, resource policies, Amazon Cognito user pools and other tools to achieve your privacy objectives.
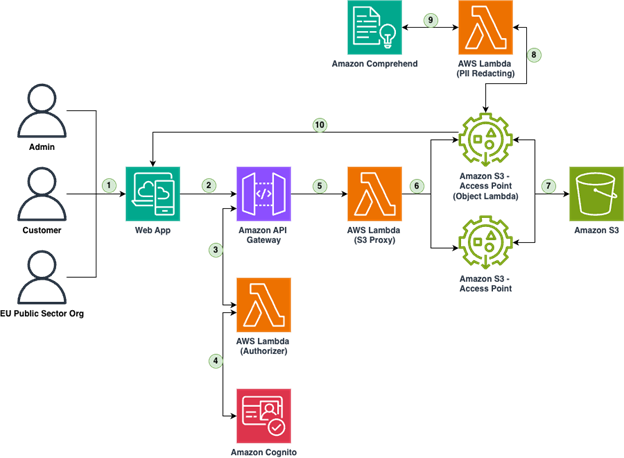
Figure 2 – Data management architecture
- Users connect to the web app
- The web app sends POST requests to an AWS API Gateway
- The API Gateway routes requests to the AWS Lambda Authorizer for authentication
- Once authenticated, connects to Amazon Cognito to store information
- The API Gateway routes requests to the S3 Proxy Lambda
- For object access and PII Redacting Lambda (for sensitive data handling)
- POSTS requests to Amazon S3
- The AWS Lamba redacts PII
- Using an S3 Object Lambda Access point allows us to filter PII or other data using Comprehend
- S3 object Access lambda returns the redacted data
See this blog post for examples of how to perform just-in-time data redaction and enrich data using S3 Object Access Lambda Endpoints https://aws.amazon.com/blogs/aws/introducing-amazon-s3-object-lambda-use-your-code-to-process-data-as-it-is-being-retrieved-from-s3/
Metadata for our S3 objects can be anonymized using several different patterns. Patterns we will discuss here include:
- Copy and replace metadata with S3 copy object
- Lambda function to remove PII on object access or modification
- Tag replacement with S3 Batch Operation
You could copy an S3 object to create a new version of it, replacing the metadata using the –metadata option. The code below shows you an example using the CLI
aws s3api copy-object –bucket <destination_bucket> –key <destination_key> –copy-source <source_bucket>/<source_key> –metadata ‘{“key1”: “value1”, “key2”: “value2”}’
You could trigger a Lambda function that removes PII from metadata when the S3 object creation or modification events occur. You could choose to use the S3 Batch Operations tools that allow you to replace all the tags with new anonymized tags. Finally, you can use AWS Glue to crawl the S3 bucket and create a table of metadata in Amazon Athena, query that table for PII, and finally trigger a Lambda function to update the sensitive tags using S3 APIs.
To support you in making the decision about what approach to take, consider your requirements.
- Do you need real time redaction, or can you perform redaction in batch mode?
- What file types do you need to redact?
- Are you scanning many objects in an S3 bucket or are they zipped up?
All these factors, as discussed in the table above, will inform your decision to get the best solution for your scenario. Also, keep in mind that most of these solutions will require S3 object versioning to be enabled because tags are immutable i.e. changing the tag creates a copy or new version of the object. Keep in mind that implementing versioning will increase storage costs, because each new version of an object incurs additional, separate storage charges. You should also add Amazon CloudWatch logging to your lambda function so you can audit tag updates to objects.
Data Accessibility and Governance
One of the key requirements for any system that you build is to be able to support the bulk log access for both customers and authorized government agencies. Under the EU Data Act, users have the right to access their IoT data easily, securely, free of charge, in a comprehensive, structured, commonly used and machine-readable format. This is an important principle of the EU Data Act that regulates the freedom of customers to have complete agency over their data: sell it, move it or delete it as they wish.
Such a system would need features including a contact center flow to request data, human-in-the-loop validation of the 3rd party request, authentication of the 3rd party using temporary credentials, and finally a bulk download mechanism. Amazon Connect can be set up to deal with email contact requests from users or government agencies, as well as creating the necessary human authorization step to validate the request. You can then configure temporary credentials and use Amazon S3 Access Grants to allow granular, temporary access to the files in the S3 bucket using a AWS Transfer Family web app.
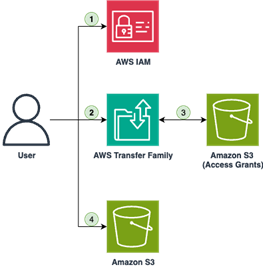
Figure 3 – Data Accessibility and Governance architecture with AWS Transfer family web app
- User is authenticated via IAM
- User loads AWS Transfer Family web app
- User gains access to their S3 bucket
- User lists objects and transfers files
Another pattern may involve the use of the Secure Shell (SSH) File Transfer Protocol (SFTP) Transfer Family service. You can leverage existing recipes for enabling an STFP server with granular access to the bucket and set up temporary credentials in Amazon Cognito. See this link for an example.
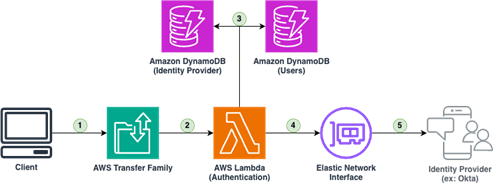
Figure 4 – Data Accessibility and Governance architecture with SFTP Transfer Family service
- Client initiates a connection to the SFTP service provided by AWS Transfer Family
- AWS Transfer Family forwards authentication requests to AWS Lambda for processing
- AWS Lambda connects to both Amazon DynamoDB instances (Identity Provider and Users) to verify credentials and user information
- After authentication, the connection moves to the Elastic Network Interface
- Connection to external Identity Provider (such as Okta) for additional authentication verification
As discussed above there are multiple options you can use to build a solution using these AWS Services to make the process of request and retrieval easier, while maintaining control over your data. Your decision is to look at your usage patterns and determine the best approach. Your AWS account team can help you if you need additional guidance and design review.
Call to action
The EU Data Act represents a fundamental shift in data governance for IoT manufacturers that will impact all healthcare organizations operating in the EU. Given that most of the requirements for IoT devices started to apply as of September 2025, the time to prepare and deploy now.
Key Steps to Take Today
1. Conduct a Data Audit
- Identify all IoT devices in your organization
- Map data flows and classify data types (personal, medical, telemetry)
2. Review Your AWS Architecture
- Evaluate your current AWS region selection, choose appropriate regions for your data residency needs
- Implement encryption for all data transfers using AWS KMS
3. Implement Data Classification
- Identify sensitive IoT data via AWS
- Establish tagging policies for PII and PHI
- Create access control policies based on data classification
4. Develop Data Sharing Capabilities
- Build secure data portals for patient and provider access
- Implement APIs that support that help enabling users access to their usage data
- Establish protocols for handling government data requests
Get Expert Support
Don’t navigate these complex requirements alone. AWS offers comprehensive resources to help healthcare organizations prepare for the EU Data Act’s requirements for IoT devices:
- Schedule a Compliance Workshop with our security specialists
- Request an Architecture Review to identify potential compliance gaps
- Explore Our Reference Architectures for IoT compliance
Official EU Data Act Resource: EU Data Act gives users control over data from connected devices
Start Your Compliance Journey Today
Ready to build your EU Data Act IoT compliance strategy? Reach out to your AWS account team.
This blog post does not constitute legal advice and should not be relied on as legal advice. AWS encourages its customers to obtain appropriate advice on their implementation of privacy and data protection environments, and more generally, applicable laws relevant to their business. Customers are responsible for making their own independent assessment of the information in this blog post. This blog post: (a) is for informational purposes only, (b) represents current AWS product offerings and practices, which may be subject to change, and (c) does not create any commitments or assurances from AWS and its affiliates, suppliers or licensors. AWS products or services are provided “as is” without warranties, representations, or conditions of any kind, whether express or implied. The responsibilities and liabilities of AWS to its customers are controlled by AWS agreements, and this document is not part of, nor does it modify, any agreement between AWS and its customers.