AWS for Industries
Protecting Sensitive Data at Scale: Automated detection and remediation in a financial data lake
Introduction
Financial institutions face a critical challenge: protecting sensitive data at scale while enabling innovation. This post provides guidance for detecting and processing sensitive data within your financial data lake on AWS, helping you maintain compliance without sacrificing agility.
Data lakes have grown exponentially in the financial services industry, fueled by cloud computing. Cloud offers near-infinitely scalable and cost-effective storage, purpose-built databases, data warehousing, analytics, and ML platforms. Many AWS customers are tackling complex problems through financial data lake architectures, including customer analytics and personalization, anti-money laundering (AML) and fraud detection, and risk management and compliance.
As these data platforms grow in the cloud, teams require maintaining compliance with strict regulations while enabling effective data utilization. This challenge affects financial service institutions (FSIs) across multiple operational areas. Organizations managing customer analytics and personalization platforms must handle vast amounts of personal data while delivering customized experiences. Teams responsible for AML and fraud detection systems struggle to maintain security while processing high volumes of transaction data. Risk management and compliance operations face the additional burden of ensuring regulatory adherence while managing sensitive trading and client information.
Across all teams, there is a strict requirement to detect and remediate any sensitive Personally Identifiable Information (PII) and Payment Card Industry Data Security Standard (PCI DSS) data at scale within their expanding data lakes.
Why it matters: high stakes for FSIs and regulatory frameworks
Regulatory frameworks such as the General Data Protection Regulation (GDPR), the California Consumer Privacy Act (CCPA), and PCI DSS requirements mandate strict protection of sensitive data, with non-compliance resulting in severe penalties and reputational damage. The growing volume and complexity of sensitive data flowing through these systems amplify the challenge. The diverse nature of data sources and formats, from structured databases to unstructured documents and real-time streams, makes comprehensive protection challenging at scale.
Requirements: heterogeneous data stores and types and automation
The solution must support integration with a diverse ecosystem of data sources and formats within the financial data platform. It must cover the different components of the platform: data sources (enterprise, SaaS applications, edge devices, logs, streaming media, flat files, and social networks), feeding into a data ingestion layer (batch, near-real time and real-time), a scalable data lake (storage and governance), data movement/ETL processes and pipelines, and a consumption layer (purpose-built analytics, databases, warehousing, and querying tools).
A critical requirement of the solution is automation, essential for protecting sensitive data across this complex landscape. It must handle increasing data volumes without creating processing bottlenecks or introducing operational complexity. Adopting managed services offers advantages, providing native integration with data protection features that scale to match workload demands while maintaining consistent performance. This approach ensures robust security and frees up valuable engineering resources from building and maintaining custom solutions, allowing teams to focus on core business initiatives and innovation.
Solution: implementing automated PII and PCI DSS data protection in your financial data lake
To address the challenges of protecting sensitive data in financial data lakes at scale, we present an implementation guide that uses AWS services to automate PII and PCI DSS data detection and processing. As illustrated in the architecture diagram, our solution implements 11 key steps to safeguard sensitive information at various points in your data lake ecosystem (data ingestion, storage, data movement, data consumption)
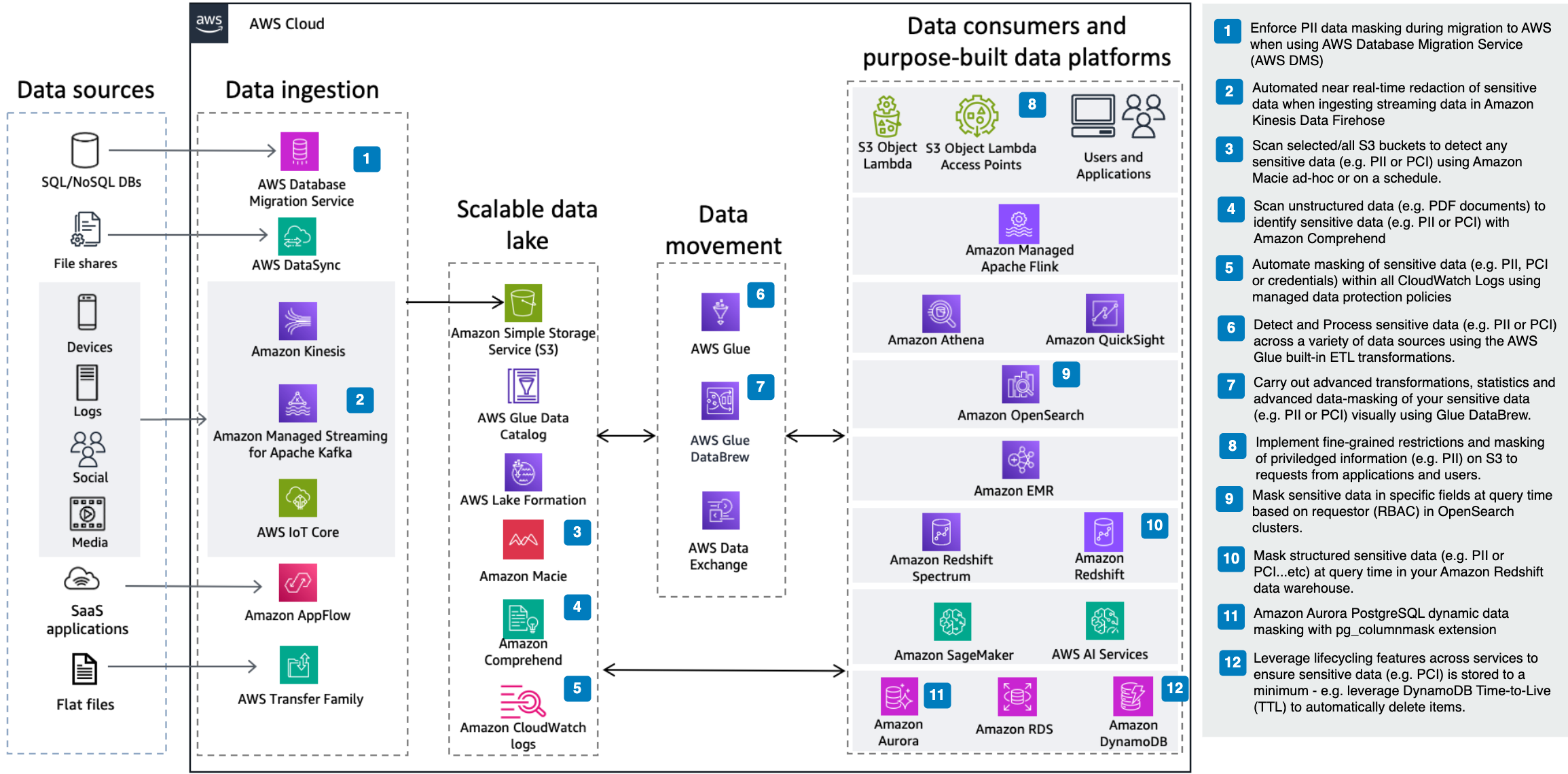
Data ingestion
You may have a stringent requirement to mask (redact) sensitive data from one or multiple data sources even before it lands in your data lake. For batch data migration of structured data sources (e.g., Oracle, SQL Server, MySQL, PostgreSQL databases), mask PII data using AWS Database Migration Service (DMS) and Amazon Macie. In this solution, AWS DMS replicates data from the source to the target database. During replication, AWS DMS events trigger the AWS Lambda function, which calls Amazon Macie to detect sensitive data in the replication batch. Then, DMS masks the detected sensitive data before writing it to the target database.
For streaming data feeds, implement Redact sensitive data from streaming data in near-real time using Amazon Comprehend and Amazon Kinesis Data Firehose to achieve near-real time redaction of sensitive data on ingestion. In this pattern, Amazon Kinesis Data Firehose delivers streams and performs transformations on records that are flagged by Amazon Comprehend through entity recognition.
Data storage and governance
Once data is ingested and stored in the data lake, scan specific/all Amazon Simple Storage Service (S3) buckets in your account for sensitive data. Amazon Macie offers this capability by using machine learning and pattern matching with managed data identifiers such as PCI DSS data (credit card numbers, expiry, and verification codes, and basic and international bank account numbers), as well as PII. Pick specific identifiers relevant to your specific geographical scope (global/country/region) and create your own custom data identifiers. Amazon Macie offers on-demand assessments or scheduled, automated evaluations to help achieve and maintain compliance.
For unstructured data in your data lake, such as PDF or text documents, you can use Amazon Comprehend for detection and redaction of sensitive data. You can do this in real-time for small documents or as a batch for larger documents, and both English and Spanish languages are supported. Leverage pre-trained managed models or customize your own model for entity recognition. Managed models include entity recognition of PCI DSS data (Swift code, account number and pin, credit/debit card details, etc.) and PII data.
Depending on your data lake use case, you will have one or more applications analyzing or processing the data. These applications generate a significant number of operational logs that may contain sensitive data. Implement automated data masking of these with Amazon CloudWatch Logs data protection policies. The logs will be available in the console or through the CLI/API, but sensitive data, as usual, will be masked.
ETL workflows and pipelines
Most data lakes require some ETL processing for ingesting and preparing data for storage and downstream consumption. To ensure no unwanted sensitive data is stored or retrieved by users and applications, implement managed detection and processing transformations in AWS Glue. Offer your staff a visual ETL interface to implement this job (AWS Glue Studio ETL Detect PII Transform), or implement through the Glue API.
Depending on your specific requirements, leverage AWS-managed sensitive data types such as PCI DSS data (e.g., BANK_ACCOUNT and CREDIT_CARD), PII data and country-specific entities. Depending on the criticality of your data, there are different detection sensitivity levels – full scan (cell-by-cell) or sampling (lower cost). The data can be processed in different ways (DETECT, REDACT, PARTIAL_REDACT, SHA-256_HASH), and override fine-grained actions are available).
If you require more advanced sensitive data treatment (statistics, detection, and processing), including advanced data-masking techniques, your teams can use the managed PII recipes in the data science environment AWS Glue DataBrew.

AWS Glue Managed Sensitive Data Types examples (Universal and US-specific).
Data consumption and purpose-built platforms
Many financial institutions adopt purpose-built platforms to store, query, and analyze data from their data lake. This can lead to better scale and performance and lower operational costs. For example, Nasdaq has adopted a lake house architecture with Amazon S3 and Amazon Redshift (data warehouse) to conduct data analysis and run complex queries.
If your data platform also leverages Amazon Redshift, automate sensitive data protection (PCI DSS and PII) through dynamic data masking (DDM). This feature applies fine-grained policies to hide, obfuscate, or pseudonymize data at query time based on the requesting user/role (RBAC). Amazon Aurora PostgreSQL (versions 16.10+ and 17.6+) also offers this DDM feature through the pg_columnmask extension.
For end users and applications retrieving data from shared datasets in your data lake, implement a similar pattern through Amazon S3 Object Lambda with Access Points. This pattern implements a ‘proxy’ layer between Amazon S3 and the end user/application to redact any sensitive data (PCI DSS and PII) before returning it to non-authorized requestors. Lambda does the detection and transformation, and Comprehend and Access Points provide different endpoints for different users based on their level of authorization.
If you are ingesting any data into Amazon OpenSearch, obfuscate sensitive fields by setting up native OpenSearch Service security controls. Field masking is a type of fine-grained access control that evaluates user credentials and per-index permissions and replaces sensitive field values with a cryptographic hash or with a custom replacement string (regex-based) at query time.
Data lifecycle and other general considerations
As a general best practice, sensitive data should be kept to a minimum. This is a specific compliance requirement under PCI DSS v4.0.1 under Requirement 3.2, which states that “Account data storage is kept to a minimum through implementation of data retention and disposal policies, procedures, and processes […]”. On AWS, you can leverage native data lifecycle features. DynamoDB Time to Live (TTL) lets you configure a per-item TTL, after which DynamoDB deletes the item from your table when the time expires without consuming write throughput. On Amazon S3, you can leverage the Amazon S3 Lifecycle configuration to automate sensitive data deletion on expiry.
Although not specific techniques to detect and process sensitive data, enforce fine-grained access control and auditing of your data lake resources, and ensure all data is encrypted at rest with proper management of encryption keys. This will help your AWS data lake comply with PCII DSSv4.0.1 and GPDR.
Conclusion
As financial institutions adopt cloud-based data lake architectures to drive innovation and leverage advanced analytics, protecting sensitive data such as PII and PCI DSS becomes a critical priority. By implementing the automated sensitive data protection techniques outlined in this post, ensure compliance with relevant data privacy regulations, mitigate the risks of data breaches, and build trust with your customers. AWS provides financial services solutions for the entire data lifecycle, from ingestion to storage, processing, and consumption. Start implementing these automated protection measures today to secure your financial data lake at scale.