AWS for Industries
The Art of the Possible: Building an Intelligent Wealth Management Platform – Part 1

Wealth management firms face a defining inflection point. A generational wealth transfer is reshaping who they must serve, digital-native clients are raising the bar on personalisation and accessibility, and cost pressures are squeezing the traditional high-touch model. Firms that want to grow, particularly into the underserved affluent segment, cannot simply add headcount. Yet relationship managers still spend nearly two-thirds of their time on non-core tasks, leaving insufficient capacity for the conversations that drive growth and loyalty. With an overwhelming majority of executives ranking client experience as their top strategic priority, the need to deliver premium service at scale has never been more urgent.
The answer isn’t incremental improvement; it’s a fundamental architectural shift toward agentic AI: autonomous, multi-agent systems that reason across data, take action, and continuously learn. When combined with graph database technology such as Amazon Neptune, these systems can surface hidden client relationships, identify cross-sell and upsell opportunities invisible to traditional SQL queries, and deliver hyper-personalized intelligence at scale while helping maintain the compliance and auditability that financial services demand.
This is the first post in a two-part series exploring how AWS-native services, including Amazon Bedrock AgentCore, Amazon Neptune Analytics, Strands Agents, and a serverless data pipeline, power three transformative advisor capabilities:
- Deep Client Graph Intelligence: Natural language queries over a connected knowledge graph of clients, advisors, products, and relationships
- Automated Client Report Pipeline: Serverless, hybrid AI/deterministic briefing reports generated daily at scale
- Agentic Market Monitoring: An autonomous agent that crawls over 20 financial news sources, scores emerging themes, and delivers portfolio-specific intelligence to advisors
Together, these capabilities directly address the priorities on which wealth management leaders focus advisor productivity, client experience, personalization at scale, and sustainable Assets Under Management (AUM) growth.
In Part 2, we cover the data foundation that powers this platform; building a governed data lake with data mesh architecture along with a smart chat interface that enables advisors to interact using both text and voice inputs.
Deep Client Search and Intelligence Powered by Graph and Generative AI
Most advisor portals rely on keyword-based searches to locate clients. Natural language search using TEXT2SQL (converting natural language to SQL queries) and generative AI technologies is becoming more common, but these approaches have limitations. They struggle when advisors need to explore complex relationships between entities such as advisors, clients, locations, investment products, risk profiles, and employment histories. Traditional search lacks the ability to surface hidden insights, segment clients effectively, and identify actionable cross-sell and upsell opportunities.
Graph technology fundamentally changes this by modeling the relationships between entities, enabling deeper analysis and the discovery of complex connections that traditional search cannot provide. The architecture in Figure 1 illustrates how financial advisors can use graph technology and generative AI together to enable natural language queries, produce richer client insights, and discover new or hidden connections and opportunities.
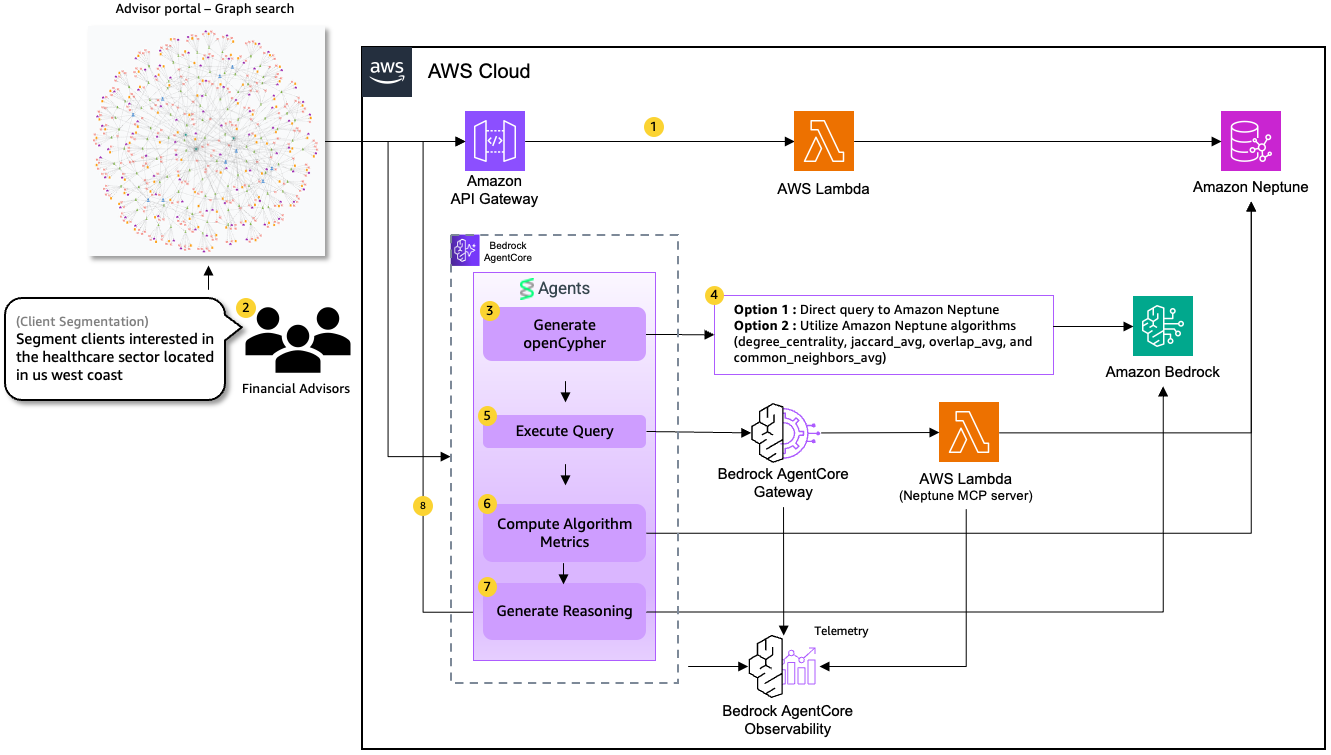
Figure 1 – Architecture for graph and generative AI-powered advisor and client intelligence solution
The following steps describe how the architecture works:
- Initial data visualization. The front-end application loads graph data from Amazon Neptune Analytics through AWS Lambda and Amazon API Gateway. This provides advisors with an interactive visualization of client relationships and network structures. This transactional microservice architecture delivers faster data loading compared to agent-based workflows. This is a critical advantage for initial page loads, designed to provide advisors with minimal wait times and immediate access to client insights.
- Natural language query interface. Advisors ask client segmentation questions in plain English directly within the application interface, eliminating the need to learn complex query languages or understand the underlying graph structure.
- Example query: “Which clients cluster together by investment style based on shared stock holdings?”
- Additional use cases include cross-sell and upsell opportunities, what-if simulations, and advisor optimization. All detailed examples and implementations are available in the Git repository.
- Intelligent query translation and multi-agent workflow with Strands Agents. The request routes to a specialized graph agent that converts natural language into openCypher queries.
- Smart query optimization. Based on the advisor’s input, Amazon Bedrock intelligently determines the optimal query strategy:
- Direct query execution: For straightforward segmentation questions, the agent runs targeted queries directly against Amazon Neptune Analytics to retrieve specific client data and relationships.
- Algorithm-enhanced queries: For complex network analysis, the graph agent automatically incorporates built-in graph algorithms in Neptune Analytics, such as Centrality, Similarity, and Clustering, directly into openCypher queries. Amazon Neptune Analytics provides these capabilities by integrating advanced graph algorithms into the query layer.
- Automated query validation: The graph agent validates the generated query syntax, checks for logical errors, and automatically corrects issues before execution, enabling accuracy, optimal performance, and protection against malformed queries.
- Query execution. The Neptune Model Context Protocol (MCP) server registers with the Amazon Bedrock AgentCore Gateway, enabling the agent to retrieve relevant graph data from Amazon Neptune Analytics. The architecture provides a clean separation of concerns: the MCP server owns the Neptune connection and query execution, while the graph search agent owns the AI logic (Cypher generation, reasoning). This design means other agents in the system can reuse the Neptune MCP server without duplicating Neptune connection logic.
- Advanced metrics analysis (optional). When advisors need deeper insights, the system can calculate and visualize key network metrics such as Degree Centrality, Similarity Metrics, and others to quantify the relationship strength and network influence.
- Interpreting graph data. Raw graph data can be difficult to interpret on its own. Amazon Bedrock analyzes the user query, Neptune query results, and algorithm metrics to generate clear, actionable explanations that help advisors make informed decisions. The reasoning agent produces a structured markdown response following a strict three-section format: overview, key findings, and recommended actions.
- Dynamic visualization updates. The front-end graph visualization updates in real-time alongside the AI-generated explanations, providing both visual and textual insights simultaneously.
Amazon Bedrock AgentCore powers this multi-agent architecture by simplifying agent deployment and management, integrating MCP servers, providing full-stack observability, delivering reliable performance at scale, and maintaining enterprise security standards.
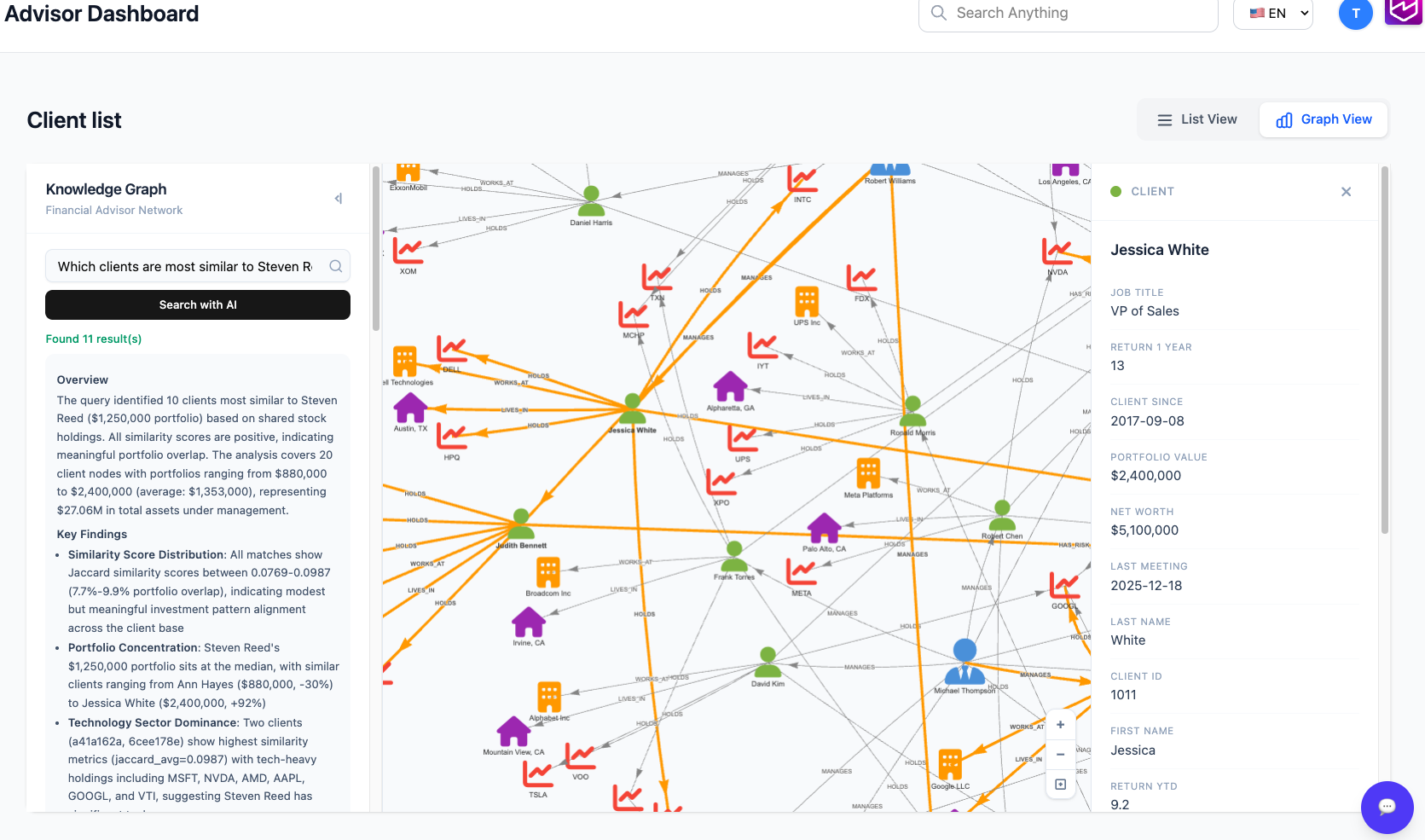
Figure 2 – Demo image: Graph and generative AI-powered advisor and client intelligence
Building an Automated Client Report Pipeline via Workflow Automation with Generative AI
Wealth management advisors require timely, comprehensive client briefing reports before every meeting covering portfolio performance, market context, risk analysis, and actionable recommendations. Manual report generation is time-consuming and prone to inconsistencies. This section shows how to automate this process at scale using AWS serverless services, handling hundreds of clients daily with fault-tolerant orchestration.
This demo solution implements a fully serverless report generation system built on three core design principles:
- Separation of orchestration from generation, enabling independent scaling of each component.
- Canary-then-full-batch pattern. The system generates reports progressively, starting with a canary subset for validation before processing the full batch, reducing risk and enabling early error detection.
- Hybrid deterministic plus generative AI report generation. The system combines rule-based logic for structured data processing with generative AI for narrative synthesis, balancing accuracy with intelligent content generation. Python templates render deterministic sections, which are never sent to the model, eliminating hallucination risk on structured content. A forced Bedrock tool call generates narrative sections (namely
submit_narratives) that returns the seven narrative fields as structured arguments. No JSON text to parse, no malformed-output failure mode. Python assembles the final report by combining the two:
tool_config = {
"tools": [{"toolSpec": {
"name": "submit_narratives",
"description": "Submit the seven narrative sections for the client report.",
"inputSchema": {"json": {
"type": "object",
"required": list(NARRATIVE_KEYS),
"properties": {k: {"type": "string"} for k in NARRATIVE_KEYS},
}},
}}],
"toolChoice": {"tool": {"name": "submit_narratives"}},
}
response = bedrock.converse(
modelId="us.anthropic.claude-sonnet-4-5-20250929-v1:0",
system=[{"text": system_prompt}], # synthesis prompts only — no tables, no numbers
messages=[{"role": "user", "content": [{"text": "Submit the narrative sections."}]}],
toolConfig=tool_config,
inferenceConfig={"maxTokens": 8192},
)
narratives = next(
block["toolUse"]["input"]
for block in response["output"]["message"]["content"]
if "toolUse" in block
)While multi-agent orchestration can pull data from distributed sources in real-time, this implementation uses a unified data platform as a single source of truth. Pre-processed data stored in a centralized repository in Amazon Redshift Serverless helps agents query standardized datasets rather than reconciling multiple sources. This approach improves accuracy, helps reduce costs by eliminating redundant data fetching, and separates data engineering from agentic workflows. Since client reports are tolerant of scheduled data refreshes, batch aggregation is viable without real-time complexity, allowing the system to focus on intelligent report assembly rather than multi-source integration. However, if a specific client report requires real-time data refresh, you can trigger the process on demand.
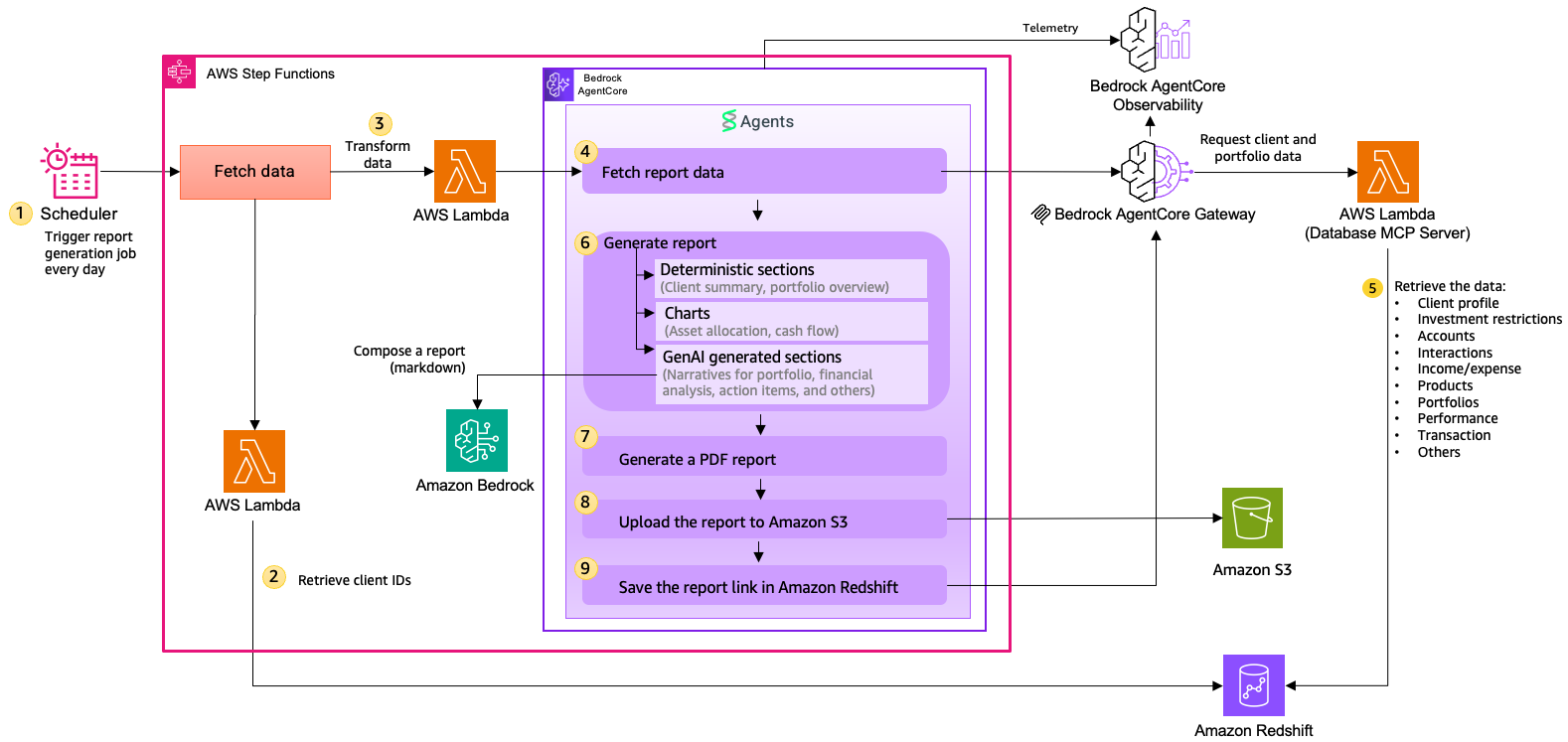
Figure 3 – Architecture for Client Report Automation
Figure 3 illustrates the architecture for client report automation. The steps below describe the end-to-end workflow:
- Scheduler using Amazon EventBridge. Amazon EventBridge Scheduler triggers the AWS Step Functions workflow daily. The scheduler invokes the state machine with an AWS Identity and Access Management (IAM) role scoped to grantStartExecution permissions.
- Retrieve client IDs from Amazon Redshift Serverless. The GetClientList AWS Lambda function queries Amazon Redshift to retrieve all active client IDs requiring reports.
- Iterate over clients with AWS Step Functions. A Map state iterates over the client list and invokes the report pipeline for each client in parallel, starting with a canary batch before scaling to full concurrency. The state machine handles retries, failures, and throughput rather than application code.
- Fetch and transform data. The system fetches raw Amazon Redshift rows and transforms them into rich Pydantic domain models. This transformation layer normalizes data formats, calculates derived fields, and structures everything for report rendering.
- Fetch report data via an MCP client using Amazon Bedrock AgentCore Gateway. The client connects to the Portfolio Data MCP server via Amazon Bedrock AgentCore Gateway, retrieving all necessary data for client report generation.
- Report generation in three stages:
- Deterministic sections: client summary and portfolio overview with real data. The system processes tables, charts, and numerical data deterministically, dramatically reducing hallucination risk on structured content.
- Chart generation: The system generates portfolio allocation pie charts and cash flow bar charts as SVG via matplotlib.
- AI-generated narratives: The converse API in Amazon Bedrock uses a forced tool call. The model receives only seven synthesis prompts (last interaction summary, recent highlights, portfolio narrative, financial position analysis, opportunities, relationship context, and action items) and must return the narratives as structured tool arguments. Schema enforcement at the API layer guarantees the response shape; Python assembles the final report by combining the pre-rendered deterministic sections with the model’s narrative output. This hybrid report generation approach means approximately 35% of report content is AI-generated, reducing Amazon Bedrock token usage by roughly half compared to a fully generative approach.
- PDF rendering. The system converts Markdown output to HTML (with SVG charts inlined), then renders it to PDF using WeasyPrint, producing a polished document with deterministic sections, AI narratives, and embedded visualizations.
- Storage in Amazon Simple Storage Service (S3). The system uploads the PDF to Amazon S3 with versioning enabled, SSL enforcement, and access logging for compliance and audit requirements.
- Metadata persistence. The MCP Gateway’s save_report tool saves a report record back to Amazon Redshift Serverless, storing metadata including client_id, report_id, S3 path, generation timestamp, and report status.
This architecture demonstrates how teams can embed multi-agent workflows into traditional serverless workflows combining Amazon EventBridge, AWS Step Functions, Amazon Bedrock, Amazon Bedrock AgentCore, and Strands Agents for production-grade, fault-tolerant report automation.
Market Monitoring and Intelligence Agent Development
Financial news volume creates a significant challenge for wealth management advisors. Dozens of sources publish hundreds of articles every hour. Advisors preparing for client meetings must scan this information, identify what is relevant to their client’s specific holdings, and synthesize it into a coherent narrative. It is time-consuming, inconsistent across advisors, and does not scale as portfolios grow in complexity.
This section presents an AI-powered market intelligence system that automatically crawls financial news, identifies emerging themes using intelligent pattern recognition on Amazon Bedrock, and delivers personalized, portfolio-specific insights. Advisors receive both general market intelligence and themes tailored to each client’s top holdings, enabling more informed and confident client conversations.
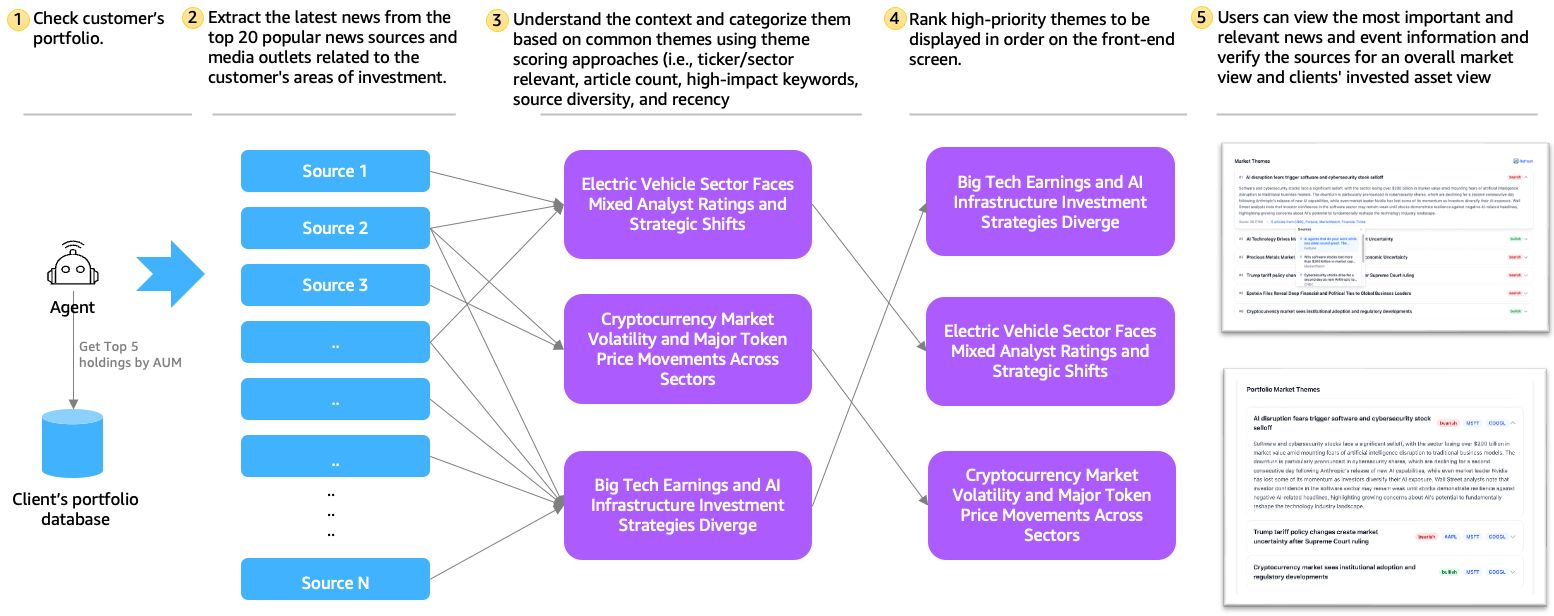
Figure 4 – Market Monitoring and Intelligence Process
The following steps describe how the system works:
- Portfolio context retrieval. The system queries Amazon Redshift Serverless through the Portfolio Data MCP Server on Amazon Bedrock AgentCore, identifying each client’s top five holdings by AUM. This establishes the personalized context for portfolio-specific intelligence. For general market insights, the system skips this step.
- Financial news extraction. A custom Web Crawler MCP Server deployed on Amazon Bedrock AgentCore orchestrates Really Simple Syndication (RSS) feed crawling from over 20 major financial news sources, extracting full-text content and persisting articles from the last 48 hours into Amazon Redshift Serverless with complete metadata (source, date, URL, content, extraction timestamps) creating an auditable news repository.
- Theme identification and scoring. Amazon Bedrock analyzes all recent articles in a single prompt to identify 5 to 6 major market themes, each backed by at least three articles. A multi-factor scoring model then computes an importance score (0 to 100) by weighting four factors:
- Article count (30%): breadth of coverage across sources
- Source diversity (25%): cross-source validation
- Recency (25%): freshness of the signal
- Impact keywords (20%): severity and market significance
This scoring approach provides transparent, deterministic ranking on top of AI-generated insights. The scoring logic is fully customizable to align with an organization’s specific priorities and risk appetite.
- Theme ranking and persistence. Themes sorted by importance score, capped at six for general market themes and three for each stock for portfolio themes. The system persists results in Amazon Redshift with full metadata — theme titles, sentiment labels (bullish/bearish/neutral), scores, summaries, timestamps, and client identifiers. The system stores article-to-theme associations separately and exposes deduplicated access through database views.
- Theme generation Workflow: Market themes refresh daily through an AWS Step Functions state machine triggered by Amazon EventBridge. The workflow crawls financial news feeds, then uses Amazon Bedrock to identify, rank, and summarize major themes from the collected articles. A canary pattern runs a small test batch of clients first before processing the full client list with up to 10 concurrent Lambda invocations, generating portfolio-specific themes tailored to each client’s top holdings. At query time, advisors receive pre-computed themes directly from Amazon Redshift Serverless, delivering sub-second responses without LLM latency.
- Advisor-facing display with source verification. An application deployed as a Lambda function behind Amazon API Gateway serves three REST endpoints: general market themes, portfolio-specific themes, and source article verification. Full source transparency enables advisors to verify AI-generated summaries against original articles, building trust in the system’s recommendations and supporting compliance requirements.
Conclusion
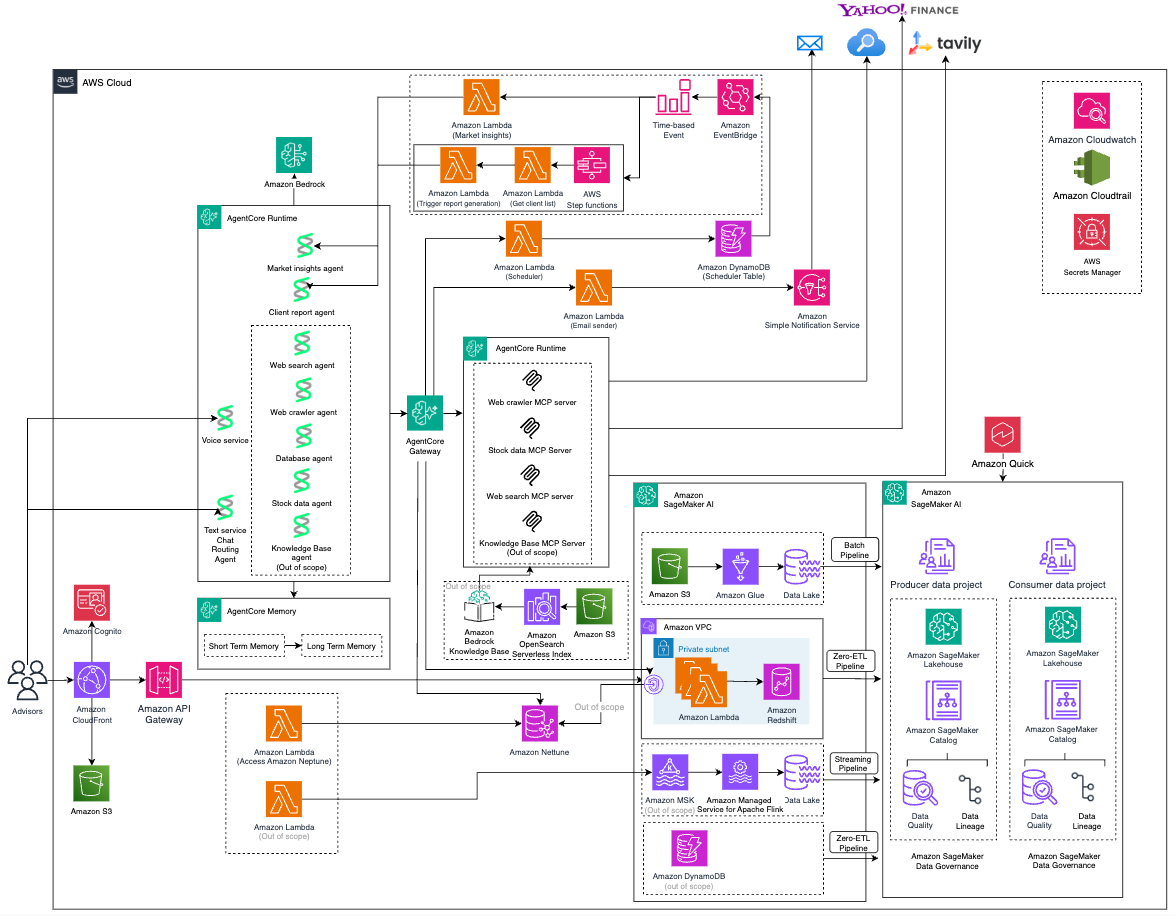
Figure 5 — End-to-end Intelligent Wealth Management Platform Architecture
In this post, we showed how to combine generative AI, graph technology, and microservice and serverless architectures to address core advisor challenges in wealth management. From uncovering hidden client relationships, to automating personalized report generation at scale, to transforming market noise into portfolio-specific intelligence.
A key design principle throughout this architecture is that you do not have to choose between deterministic reliability and AI intelligence. By combining rule-based processing for structured data with generative AI for narrative synthesis, and by separating data engineering from agentic workflows, financial institutions can build platforms that are accurate, auditable, and operationally resilient.
In Part 2 of this series, we cover the data foundation that powers this platform; building a governed data lake with data mesh and data sharing capabilities for the wealth and advisory business along with a smart chat interface that enables advisors to interact using both text and voice inputs.
To explore the source code and start building, visit the GitHub repository: AWS Samples — sample-wealth-advisor-demo-platform