Artificial Intelligence
Category: Amazon Elastic Inference

Reduce inference costs on Amazon EC2 for PyTorch models with Amazon Elastic Inference
Note: Amazon Elastic Inference is no longer available. Please see Amazon SageMaker for similar capabilities. You can now use Amazon Elastic Inference to accelerate inference and reduce inference costs for PyTorch models in both Amazon SageMaker and Amazon EC2. PyTorch is a popular deep learning framework that uses dynamic computational graphs. This allows you to […]
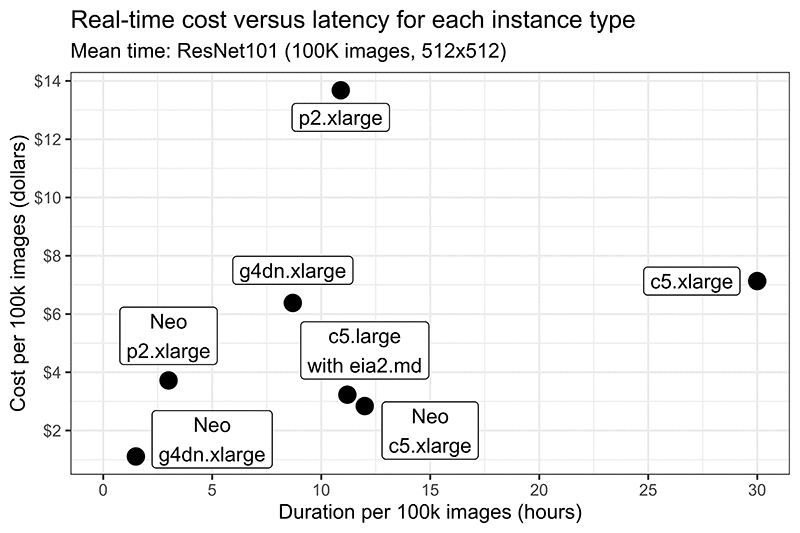
Increasing performance and reducing the cost of MXNet inference using Amazon SageMaker Neo and Amazon Elastic Inference
Note: Amazon Elastic Inference is no longer available. Please see Amazon SageMaker for similar capabilities. When running deep learning models in production, balancing infrastructure cost versus model latency is always an important consideration. At re:Invent 2018, AWS introduced Amazon SageMaker Neo and Amazon Elastic Inference, two services that can make models more efficient for deep […]

Reduce ML inference costs on Amazon SageMaker for PyTorch models using Amazon Elastic Inference
Note: Amazon Elastic Inference is no longer available. Please see Amazon SageMaker for similar capabilities. Today, we are excited to announce that you can now use Amazon Elastic Inference to accelerate inference and reduce inference costs for PyTorch models in both Amazon SageMaker and Amazon EC2. PyTorch is a popular deep learning framework that uses […]

Optimizing TensorFlow model serving with Kubernetes and Amazon Elastic Inference
Note: Amazon Elastic Inference is no longer available. Please see Amazon SageMaker for similar capabilities. This post offers a dive deep into how to use Amazon Elastic Inference with Amazon Elastic Kubernetes Service. When you combine Elastic Inference with EKS, you can run low-cost, scalable inference workloads with your preferred container orchestration system. Elastic Inference […]

Serving deep learning at Curalate with Apache MXNet, AWS Lambda, and Amazon Elastic Inference
Note: Amazon Elastic Inference is no longer available. Please see Amazon SageMaker for similar capabilities. This is a guest blog post by Jesse Brizzi, a computer vision research engineer at Curalate. At Curalate, we’re always coming up with new ways to use deep learning and computer vision to find and leverage user-generated content (UGC) and […]

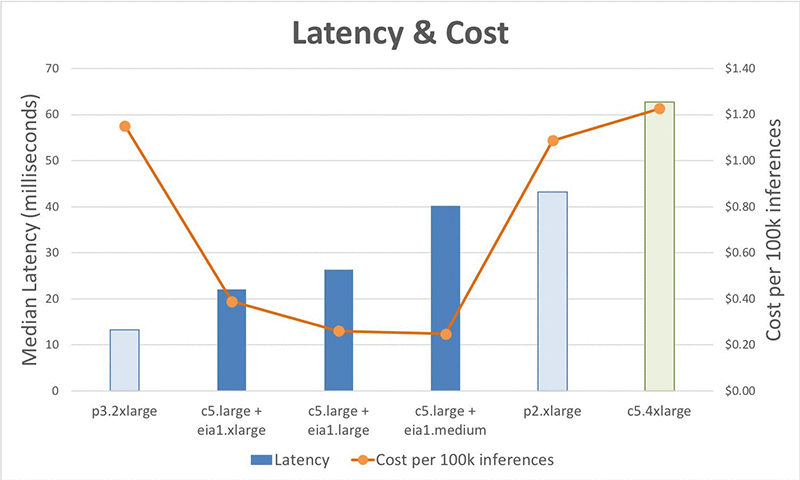
Optimizing costs in Amazon Elastic Inference with TensorFlow
Note: Amazon Elastic Inference is no longer available. Please see Amazon SageMaker for similar capabilities. Amazon Elastic Inference allows you to attach low-cost GPU-powered acceleration to Amazon EC2 and Amazon SageMaker instances, and reduce the cost of running deep learning inference by up to 75 percent. The EIPredictorAPI makes it easy to use Elastic Inference. In this post, […]
Running Java-based deep learning with MXNet and Amazon Elastic Inference
Note: Amazon Elastic Inference is no longer available. Please see Amazon SageMaker for similar capabilities. The new release of MXNet 1.4 for Amazon Elastic Inference now includes Java and Scala support. Apache MXNet is an open source deep learning framework used to build, train, and deploy deep neural networks. Amazon Elastic Inference (EI) is a […]

Launch EI accelerators in minutes with the Amazon Elastic Inference setup tool for EC2
Note: Amazon Elastic Inference is no longer available. Please see Amazon SageMaker for similar capabilities. The Amazon Elastic Inference (EI) setup tool is a Python script that enables you to quickly get started with EI. Elastic Inference allows you to attach low-cost GPU-powered acceleration to Amazon EC2 and Amazon SageMaker instances to reduce the cost of running […]

Reducing deep learning inference cost with MXNet and Amazon Elastic Inference
Note: Amazon Elastic Inference is no longer available. Please see Amazon SageMaker for similar capabilities. Amazon Elastic Inference (Amazon EI) is a service that allows you to attach low-cost GPU-powered acceleration to Amazon EC2 and Amazon SageMaker instances. MXNet has supported Amazon EI since its initial release at AWS re:Invent 2018. In this blog post, […]
Model serving with Amazon Elastic Inference
Note: Amazon Elastic Inference is no longer available. Please see Amazon SageMaker for similar capabilities. Amazon Elastic Inference (EI) is a service that allows you to attach low-cost GPU-powered acceleration to Amazon EC2 and Amazon SageMaker instances. EI reduces the cost of running deep learning inference by up to 75%. Model Server for Apache MXNet […]