Artificial Intelligence
Increasing performance and reducing the cost of MXNet inference using Amazon SageMaker Neo and Amazon Elastic Inference
Note: Amazon Elastic Inference is no longer available. Please see Amazon SageMaker for similar capabilities.
When running deep learning models in production, balancing infrastructure cost versus model latency is always an important consideration. At re:Invent 2018, AWS introduced Amazon SageMaker Neo and Amazon Elastic Inference, two services that can make models more efficient for deep learning.
In most deep learning applications, making predictions using a trained model—a process called inference—can drive as much as 90% of the compute costs of the application due to two factors. First, standalone GPU instances are designed for model training and are typically oversized for inference. While training jobs batch process hundreds of data samples in parallel, most inference happens on a single input in real time that consumes only a small amount of GPU compute. Even at peak load, a GPU’s compute capacity may not be fully utilized, which is wasteful and costly. Second, different models need different amounts of GPU, CPU, and memory resources. Selecting a GPU instance type that is big enough to satisfy the requirements of the most demanding resource often results in under-utilization of the other resources and high costs.
Elastic Inference is a service that provides the optimal amount of GPU compute to perform inference. SageMaker Neo is a service that optimizes deep learning models for specific infrastructure deployments by reducing the memory imprint which can result in upto double the execution speed.
This post deploys an MXNet hot dog / not hot dog image classification model in Amazon SageMaker and measures model latency and costs in a variety of deployment scenarios. This post evaluates deployment options using Amazon SageMaker and Amazon Elastic Inference and the different results you may see if you choose different Amazon EC2 instances.
| About this blog post | |
| Time to complete | 2 hours
|
| Cost to complete | ~ $10 (at publication time, depending on terms used)
|
| Learning level | Intermediate (200) |
| AWS services | Amazon SageMaker
Amazon SageMaker Neo Amazon Elastic Inference |
The benefits of Amazon Elastic Inference
Amazon Elastic Inference allows developers to dramatically decrease inference costs with up to 75% savings when compared to the cost of using a dedicated GPU instance. Amazon Elastic Inference also provides three separate sizes of GPU acceleration (eia2.medium, eia2.large, and eia2.xlarge) which creates flexibility to optimize cost and performance for different use cases such as natural language processing or computer vision. You can easily scale Elastic Inference accelerators (EIA) by using Amazon EC2 Auto Scaling groups.
The benefits of Amazon SageMaker Neo
SageMaker Neo uses deep learning to find code optimizations for specific hardware and deep learning frameworks that allow models to perform at up to twice the speed with no loss in accuracy. Furthermore, by reducing the code base for deep learning networks to only the code required to make predictions, SageMaker Neo reduces the memory footprint for models by up to 10 times. SageMaker Neo can optimize models for a variety of platforms, which makes tuning a model for multiple deployments simple.
Running the notebook
In this post, we will explore an image classification task using a pre-trained ResNet model that is fine-tuned for the food images within the hot dog / not hot dog dataset. The notebook shows how to use Amazon SageMaker to fine-tune a pre-trained convolutional neural network model, optimize the model using SageMaker Neo, and deploy the model and evaluate its latency in a variety of methods using SageMaker Neo and EIA.
Complete the following steps:
- Launch an Amazon SageMaker notebook with at least 10 GB of EBS space.
- Clone the repository for this post from the GitHub repo.
- Launch the
hot dog / not hot dognotebook. - Download and unzip the Food101 dataset in a terminal into the repository folder. See the following code:
- Create the
hot dog / not hot dogdatasets with the following code: - Create an Amazon SageMaker session and role, upload to Amazon S3, and train the model. See the following code:
- Instantiate the Amazon SageMaker MXNet estimator with the role, instance type, number of instances, and hyperparameters and fit the model. See the following code:
- Optimize the models through SageMaker Neo. See the following code:
- Prepare model deployment. The following example code is for P2:
- Prepare the model inference code:
- Deploy and time the inference. The following example code is for P2:
Evaluating multiple deployments
Approach
This post focused on testing GPU and CPU instances with AWS machine learning services, including SageMaker Neo and EIA, which are designed to enhance the performance of base instances. The size of ResNet models varied during the testing, with final results reported using a ResNet 101. The test used 50 test images from the public hot dog / not hot dog dataset for inference to compare the latency and cost implication of the various deployment types. This post reshaped the test images to a dimension of 512 by 512 for standardization when performing inference.
Results
The following table shows latency and real-time cost after performing inference on the 50 test images with seven runs and one loop per run using a ResNet 101 model. EIA was an eia2.mediumwhich helped to use a precise amount of GPU for inference while staying on a CPU instance. Because the intention was to run model inference non-stop, the yearly operating cost for reference was calculated based on running an Amazon SageMaker endpoint for 24 hours a day, 365 days a year.
| Endpoint | Average time (seconds) | Standard deviation (per loop in milliseconds) | Real-time on-demand cost / hour | Cost / 100,000 images | Yearly operating cost |
| p2.xlarge | 19.6 | 356 | $1.26 | $13.68 | $11,037.60 |
| Neo on p2.xlarge | 5.3 | 133 | $1.26 | $3.72 | $11,037.60 |
| g4dn.xlarge | 15.7 | 193 | $0.74 | $6.38 | $6,447.36 |
| Neo on g4dn.xlarge | 2.7 | 177 | $0.74 | $1.11 | $6,447.36 |
| c5.large with eia2.medium | 20.8 | 246 | $0.29 | $3.23 | $2,514.12 |
| c5.xlarge | 53.9 | 345 | $0.24 | $7.13 | $2,084.88 |
| Neo on c5.xlarge | 21.6 | 665 | $0.24 | $2.84 | $2,084.88 |
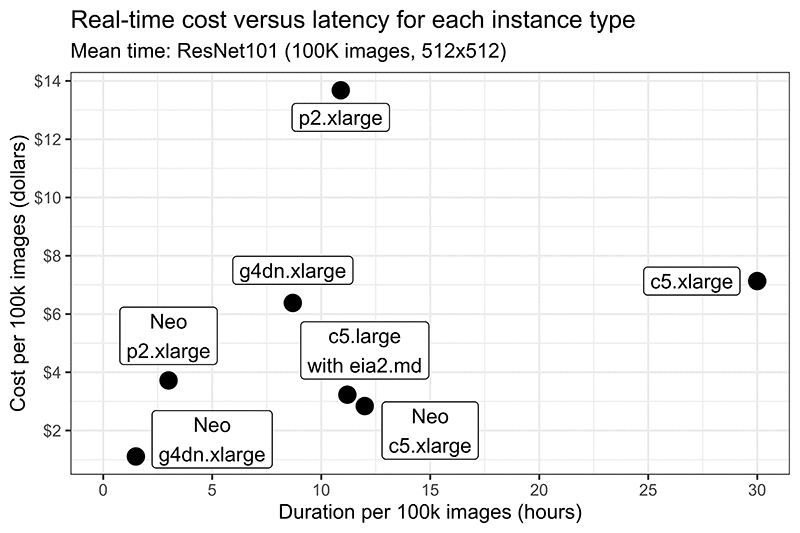
The following graph shows the real-time cost (in dollars) versus duration (in hours) for 100,000 images. Ideally, the deployment type should be close to the origin (0,0). For use cases that maximize throughput in batch processing, the option with the lowest latency has the lowest cost (SageMaker Neo G4). In cases where SageMaker Neo is not an option for model deployment, other deployment configurations have a good balance between latency and cost.
The following graph compares cost versus latency with yearly operating cost (in dollars) versus average time (in seconds) over the 50 test images. The GPU deployment options are more costly than the CPU options, but they have a benefit of low latency. Using SageMaker Neo helps to decrease latency while maintaining the same cost for a given instance type.

Interpretation and recommendation
Based on latency alone, SageMaker Neo on G4 was the clear winner, with the lowest average latency at 2.7 seconds. SageMaker Neo on P2 was slightly behind, with the second-lowest average latency at 5.3 seconds. However, when also evaluating cost, the preferred option depends on how you use the endpoint. For example, assuming an endpoint is deployed continually, the annual operating cost for both the base P2 and the P2 with SageMaker Neo options were the highest of all deployment methods in this test. However, if you use it to process throughput in periodic occurrences, such as performing inference on 100,000 images, the cost for P2 with SageMaker Neo is near the lower end of the cost range due to the speed at which the inferences occur for the experiment. You can evaluate several endpoint configurations to provide optimal latency at the lowest cost by accounting for cost, latency, and frequency of endpoint use.
For a continual deployment, the lowest annual cost options are the C5 endpoint and the corresponding SageMaker Neo on C5 endpoint. These had average latency times of 53.9 and 21.6 seconds, respectively. For the throughput processing case of 100,000 images, SageMaker Neo-compiled G4 instances were the most cost-effective despite the higher hourly price due to the significant decrease in associated latency. The other cost-effective options are the SageMaker Neo on C5 and C5 with EIA due to their associated decreases in latency. The C5 with EIA possesses the additional advantage of using a CPU context to exclusively handle data preprocessing, whereas the SageMaker Neo c5.xlarge uses CPU capacity to handle both inference and data preprocessing.
This shows the advantage of using SageMaker Neo or an EIA to optimize endpoint latency for this instance type. Using SageMaker Neo, there was a latency decrease of 60% with the same cost on an annual basis and a 60% reduction in cost to process 100,000 images. Using the EIA to process 100,000 images provided a 61% decrease in average latency and a 55% reduction in cost, but with an additional 21% cost increase on an annual basis. Relative to the other options tested, SageMaker Neo and the EIA provided excellent efficiency gains at minor to negligible extra cost.
The G4 instance deployment provided a balance of latency and cost, and when combined with SageMaker Neo, provided the most cost-effective option for throughput processing. SageMaker Neo on G4 had the lowest average latency at 2.7 seconds, while a base G4 instance had the third-lowest average latency at 15.7 seconds (behind SageMaker Neo on a P2). Both the SageMaker Neo on G4 and the base G4 were in the midpoint of annual operating costs, but SageMaker Neo on G4 had the lowest throughput operating cost of all endpoints evaluated. Using SageMaker Neo on G4 provided a decrease in latency nearly six times greater than a base G4 instance. With a model compiled using SageMaker Neo, a G4 was about two times faster than a P2 and eight times faster than a C5. Comparing the costs of the instances on an annual basis, a G4 costs 42% less than a P2, and a C5 costs 68% less than a G4. While sacrificing cost, SageMaker Neo on a G4 provides a much higher inference speed than a C5.
Overall, the test showed that SageMaker Neo helps reduce latency while maintaining the same cost as a base instance when examined on an annual operating basis. However, the benefits of SageMaker Neo from a cost perspective are clear when measuring throughput performance. While the cost of using SageMaker Neo with a P2 instance was the highest of all options evaluated for continual annual deployment, the cost for throughput processing decreased by 73% relative to the base P2.
Using SageMaker Neo with the P2 instance also reduced latency by approximately 3.7 times, from 19.6 to 5.3 seconds. There was a smaller reduction of 2.5 times in latency when tested on C5 with SageMaker Neo. Nonetheless, attaching SageMaker Neo whenever feasible is a sensible choice to reduce latency with a more significant benefit for GPU than CPU instances.
The EIA attached to a C5 instance helped to improve latency with only a slight increase in annual cost and a significant decrease in throughput processing cost. Similar to SageMaker Neo, EIA reduced latency by about 2.6 times, from 53.9 to 20.8 seconds, with a small cost increase of $0.05 per on-demand hour. In scenarios when SageMaker Neo is not feasible, attaching an EIA is cost-effective because it only uses the necessary GPU acceleration while paying for a CPU instance.
Conclusion
The results of this inference study show that there are several possible solutions that you can use depending on latency, cost requirements, and the type of inference task. If cost is not an issue and latency is paramount, the SageMaker Neo on G4 deployment is the best choice. If cost is a considerable concern, you can sacrifice some latency and the endpoint remains in continual use, using either SageMaker Neo or an EIA with a C5 instance is a good choice. For throughput processing jobs, both the P2 with SageMaker Neo and G4 with SageMaker Neo are effective lower-cost options and only slightly more expensive than the C5 instances with SageMaker Neo or EIA. Finally, if you require a GPU and can’t use either SageMaker Neo or EIA, the G4 instance is a good option for balancing cost and latency.
Overall, this evaluation showed that using SageMaker Neo or an EIA can provide substantial performance improvements with minimal to no increase in the cost of the endpoint and potentially significant decrease spend when used for throughput processing. When these options are not feasible, but latency is still a crucial factor, the G4 instance is preferred over a standalone P2 instance for faster inference speed while also yielding a reduction in cost.
Open the Amazon SageMaker console to get started.
About the author
 Dheepan Ramanan is a Data Scientist in AWS Professional Services AI/ML Global Specialty practice. Dheepan works with AWS customers to build machine learning models for natural language processing, computer vision, and product recommendation. In his spare time, Dheepan enjoys analog activites like creating elaborate pen and ink drawings, sous viding steaks, and walking his poodle.
Dheepan Ramanan is a Data Scientist in AWS Professional Services AI/ML Global Specialty practice. Dheepan works with AWS customers to build machine learning models for natural language processing, computer vision, and product recommendation. In his spare time, Dheepan enjoys analog activites like creating elaborate pen and ink drawings, sous viding steaks, and walking his poodle.
 Ryan Gillespie is a Data Scientist with AWS Professional Services. He has a MSc from Northwestern University and a MBA from the University of Toronto. He has previous experience in the retail and mining industries.
Ryan Gillespie is a Data Scientist with AWS Professional Services. He has a MSc from Northwestern University and a MBA from the University of Toronto. He has previous experience in the retail and mining industries.
 Jimmy Wong is an Associate Data Scientist within AWS Professional Services AI/ML Global Specialty Practice. He focuses on developing machine learning solutions related to natural language processing and computer vision for customers. In his spare time, Jimmy enjoys his Nintendo Switch, catching up on shows, and exercising.
Jimmy Wong is an Associate Data Scientist within AWS Professional Services AI/ML Global Specialty Practice. He focuses on developing machine learning solutions related to natural language processing and computer vision for customers. In his spare time, Jimmy enjoys his Nintendo Switch, catching up on shows, and exercising.