Artificial Intelligence
Running Java-based deep learning with MXNet and Amazon Elastic Inference
Note: Amazon Elastic Inference is no longer available. Please see Amazon SageMaker for similar capabilities.
The new release of MXNet 1.4 for Amazon Elastic Inference now includes Java and Scala support. Apache MXNet is an open source deep learning framework used to build, train, and deploy deep neural networks. Amazon Elastic Inference (EI) is a service that allows you to attach low-cost GPU-powered acceleration to Amazon EC2 and Amazon SageMaker instances. Amazon EI reduces the cost of running deep learning inference by up to 75%. In this post, we will show you how to run inference in Java using MXNet and an Elastic Inference Accelerator (EIA).
Setting up Amazon Elastic Inference with Amazon EC2
Starting up an EC2 instance with an attached Amazon EI accelerator requires some pre-configuration steps when you set up your AWS account. You can use the setup tool to easily start up everything you need. Or, you can launch an instance with an accelerator by following the instructions in the Amazon Elastic Inference documentation. Here, we start with a basic Ubuntu Amazon Machine Image (AMI), and configure it for our needs. Start by connecting to your instance via SSH and installing the following dependencies:
Setting up a Java project
Start by downloading and unzipping the demo project.
Inside the archive is a pom.xml file that will build the project with the Amazon EI MXNet dependency. It uses an additional Maven repository located on Amazon S3 that contains the Amazon EI MXNet package:
Then, there is a dependency on the Amazon EI build of Apache MXNet in the project’s pom.xml:
With these changes, Maven can access the appropriate repository and will automatically download the Amazon EI MXNet jar to make it accessible from the project.
Creating a ResNet-152 application
In this section we will walk through the demo code in the archive at:
Let’s write some code to perform a simple image classification using the ResNet-152 model. First, we need to download the model, names of the different image classification labels, and a test image.
Then, we create a Predictor object to run the model. It takes in an image as a 1 element batch of images where each image is a 3 x 224 x 224 NDArray of Floats. Since the image is the only input to the model, we make a list with that inputDescriptor as the only element. We also provide the path to the model on the local file system. In order to run this predictor with Amazon EI we pass in Context.eia(). You could also use Context.cpu() to run inference locally on the CPU only (this could be useful for debugging).
Now that we have the predictor, we need to get the image to run the prediction on. There are some utilities within the ObjectDetector class to help simplify this process. Let’s load the image from the file, reshape it to 224 x 224, and convert it into an NDArray.
Finally, let’s use our predictor to run inference on the image.
Let’s print out the top 5 predicted classes of the image. After we execute the prediction, we need to find the results with largest confidence values. Then, we need to find the corresponding names for each element in the results from the synset.txt file.
Building and running the ResNet-152 application
To build the project, simply navigate to the main directory containing the README and pom.xml and run mvn package. After it’s built, we can run the example by using mvn exec:java -Dexec.mainClass=mxnet.ImageClassificationDemo -Dexec.cleanupDaemonThreads=false.
Running the test produces the following results:
You can learn more by reading the Elastic Inference with MXNet Java API Documentation.
Cost and performance gains
Lets analyze the performance of the various configurations using the latency or time required to complete one inference call. Amazon EI accelerators are currently available in three sizes: eia1.medium, eia1.large, and eia1.xlarge. Each has from 1 to 4 GB of memory and from 8 to 32 TFLOPS of compute. For this example, we’ll run the resnet-152 model on P2, P3, C5.4xlarge, and C5.large EC2 instance types plus all EIA options.
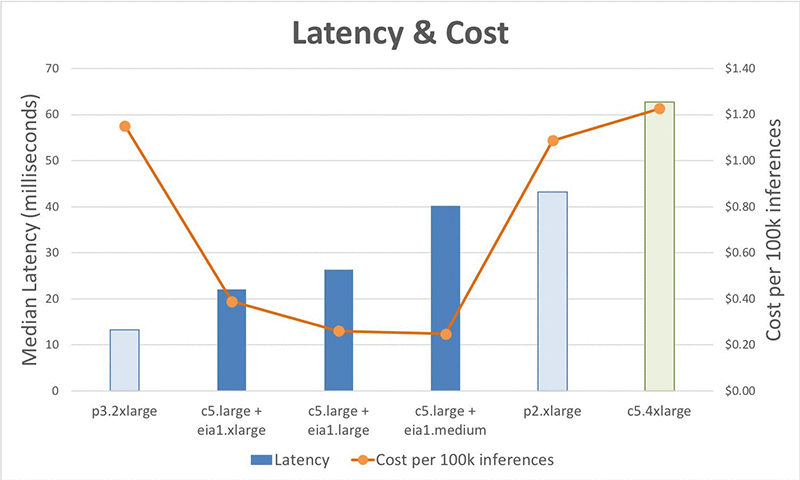
Looking at the results, we can see the latencies of the standard instances are, from best to worst, 13.26ms for P3, 43.52ms for P2, and 64.91ms for C5.4xlarge. The latencies for the EIA instances fall between the best, P3, and the middle, P2, with 22.11ms for c5.large + eia1.xlarge, 26.28 for c5.large + eia1.large, and 41.7ms for c5.large + eia1.medium. However, the cost efficiencies of the standard EC2 instances range from $1.08 to $1.19 per 100,000 inferences while the Amazon EI accelerator instances have cost efficiencies from $.24 to $.37, up to a 78% savings.
Compared to running inferences on CPU instances such as the c5.4xlarge, the Amazon EI options are up to 56% faster, while being cheaper as well. They have better performance than the P2 while being up to 76% cheaper. Although the P3 instances have better latency, you can get up to 13 Amazon EI instances for the same price, which is 93% cheaper.
In summary, if your application requires the lowest latency available, you probably need to stick to the P3 instance type. But if your application allows for just slightly higher latencies, you can take advantage of Amazon EI and save up to 78% compared to the cost of P2 and P3 instances. The results for the EIA instances show that EIA provides another option in terms of raw performance between P2 and P3 instances, but with the best cost efficiency of any instance type. Refer to Appendix 1 for a detailed performance comparison between different CPU, GPU, and EIA flavors.
Conclusion
The Java/Scala support for MXNet on Amazon EI enables Java applications to add cost-effective deep learning acceleration to existing production systems. Using Amazon EI accelerators can reduce latencies by 56% compared to using just CPU while reducing the inference cost by up to 78%.
Get Started with Amazon EI and the Java API
You can learn more on how to start with Amazon EI, set up your necessary infrastructure, and deploy your models into production from the posts on Model serving with Amazon Elastic inference and Amazon Elastic Inference – GPU powered deep learning inference acceleration. You can read more about MXNet from the Java MXNet API Reference and the Apache MXNet website.
Appendix 1 – Raw performance and cost results for ResNet-152
This table provides the data collected across a number of instance types both with and without Amazon Elastic Inference. We show the times to do a single prediction (latency), the number of predictions per second (throughput), the cost of the instances, and the cost effectiveness ($/100k inferences). For example, if your main goal is to get minimal latency while keeping costs under control (e.g., you don’t want expensive GPU hosts), one of the best choices for you is to use a c5.2xlarge instance with an eia1.xlarge accelerator. If your primary goal is to minimize costs, and your latency requirements are more lenient, you can use a c5.large instance with an eia1.large accelerator. Compared to the latency-optimized case inference time would increase by ~28%, but the corresponding cost reduction would be ~50%.
Remember that these metrics are only for the Resnet-152 model. You would need to collect data on your application’s model in order to find the best options for you.
| Instance Type | p50 Latency | p90 Latency | Throughput per sec | Instance Cost per hour | $/100k inferences | Notes |
| c5.4xlarge | 62.73 | 64.91 | 15.94 | $0.68 | $1.19 | |
| c5.9xlarge | 39.61 | 39.81 | 25.25 | $1.53 | $1.68 | |
| c5.large + eia1.medium | 40.19 | 41.37 | 24.88 | $0.22 | $0.24 | |
| c5.large + eia1.large | 26.28 | 27.15 | 38.05 | $0.35 | $0.25 | Best for cost effectiveness with EI |
| c5.large + eia1.xlarge | 22.11 | 23.13 | 45.23 | $0.61 | $0.37 | |
| c5.xlarge + eia1.medium | 39.62 | 41.35 | 25.24 | $0.30 | $0.33 | |
| c5.xlarge + eia1.large | 26.24 | 26.92 | 38.11 | $0.43 | $0.31 | |
| c5.xlarge + eia1.xlarge | 21.04 | 21.61 | 47.52 | $0.69 | $0.40 | |
| c5.2xlarge + eia1.medium | 38.8 | 43.24 | 25.78 | $0.47 | $0.50 | |
| c5.2xlarge + eia1.large | 26.27 | 27.03 | 38.07 | $0.60 | $0.44 | |
| c5.2xlarge + eia1.xlarge | 20.89 | 21.26 | 47.88 | $0.86 | $0.50 | Best for latency with EI |
| p2.xlarge | 43.23 | 43.52 | 23.13 | $0.90 | $1.08 | |
| p3.2xlarge | 13.26 | 13.54 | 75.44 | $3.06 | $1.13 |
About the authors
 Zach Kimberg is a Software Engineer with AWS Deep Learning working mainly on Apache MXNet for Java and Scala. Outside of work he enjoys reading, especially Fantasy.
Zach Kimberg is a Software Engineer with AWS Deep Learning working mainly on Apache MXNet for Java and Scala. Outside of work he enjoys reading, especially Fantasy.
 Sam Skalicky is a Software Engineer with AWS Deep Learning and enjoys building heterogeneous high performance computing systems. He is an avid coffee enthusiast and avoids hiking at all costs.
Sam Skalicky is a Software Engineer with AWS Deep Learning and enjoys building heterogeneous high performance computing systems. He is an avid coffee enthusiast and avoids hiking at all costs.
 Denis Davydenko is an Engineering Manager with AWS Deep Learning. He focuses on building Deep Learning tools that enable developers and scientists to build intelligent applications. In his spare time he enjoys spending time with his family, playing poker and video games.
Denis Davydenko is an Engineering Manager with AWS Deep Learning. He focuses on building Deep Learning tools that enable developers and scientists to build intelligent applications. In his spare time he enjoys spending time with his family, playing poker and video games.