Artificial Intelligence
Reducing deep learning inference cost with MXNet and Amazon Elastic Inference
Note: Amazon Elastic Inference is no longer available. Please see Amazon SageMaker for similar capabilities.
Amazon Elastic Inference (Amazon EI) is a service that allows you to attach low-cost GPU-powered acceleration to Amazon EC2 and Amazon SageMaker instances. MXNet has supported Amazon EI since its initial release at AWS re:Invent 2018.
In this blog post, we’ll explore the cost and performance benefits of using Amazon EI with MXNet. We’ll walk you through an example that shows you how we improved our initial inference latency of 43ms by 1.69x, and how we improved cost efficiency by 75 percent.
The benefits of Amazon Elastic Inference
Amazon Elastic Inference can reduce the cost of running deep learning inference by up to 75 percent. First let’s take a look at how Elastic Inference compares to other Amazon EC2 options in terms of performance and cost.
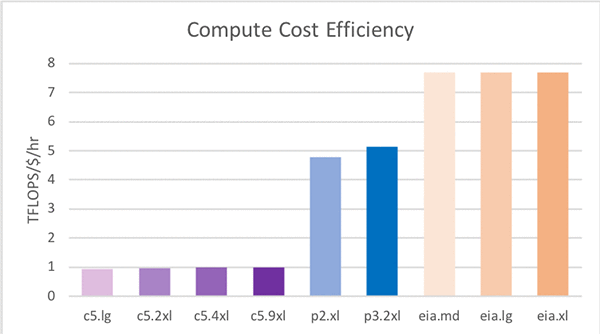
The table below lists the specific details for each EC2 option, in terms of resources, capacity and cost. Note that the c5.xlarge plus eia1.xlarge has a similar amount of compute capacity as a p2.xlarge (see the two highlighted rows in the table below).
| Instance Type | vCPUs | CPU Memory (GB) | GPU Memory (GB) | FP32 TFLOPS | $/hour | TFLOPS/$/hr |
| C5.Large | 2 | 4 | – | 0.08 | $0.09 | 0.94 |
| C5.XLarge | 4 | 8 | – | 0.17 | $0.17 | 1.00 |
| C5.2XLarge | 8 | 16 | – | 0.33 | $0.34 | 0.97 |
| C5.4XLarge | 16 | 32 | – | 0.67 | $0.68 | 0.99 |
| C5.9XLarge | 32 | 64 | – | 1.34 | $1.36 | 0.99 |
| P2.XLarge (K80) | 4 | 61 | 12 | 4.30 | $0.90 | 4.78 |
| P3.2XLarge (V100) | 8 | 61 | 16 | 15.70 | $3.06 | 5.13 |
| EIA1.Medium | – | – | 1 | 1.00 | $0.13 | 7.69 |
| EIA1.Large | – | – | 2 | 2.00 | $0.26 | 7.69 |
| EIA1.Xlarge | – | – | 4 | 4.00 | $0.52 | 7.69 |
| C5.XL + EIA.XL | 4 | 8 | 4 | 4.17 | $0.69 | 6.04 |
If we look at the compute capability (Tera-Floating-point-Operations-Per-Second, or TFLOPS) a C5.4XLarge provides 0.67 TFLOPS of performance for $0.68 an hour, whereas an EIA1.Medium with 1.00 TFLOPS costs just $0.13 per hour. If pure performance (ignoring costs) is the goal, clearly leveraging a P3.2XLarge instance will provide the most compute at 15.7 TFLOPS. But in the last column showing TFLOPS per dollar we see that the EI accelerators (EIA) provide the most value. Since EI accelerators (EIA) must be attached to an EC2 instance, the last row shows one possible combination. The C5.XLarge plus the EIA1.XLarge has a similar amount of vCPUs and TFLOPS as a P2.XLarge, but the cost per hour of the C5XLarge plus the EIA1.XLarge is $0.69 per hour compared with $0.90 per hour for the P2.XLarge. That’s a $0.21 per hour discount. This highlights the other benefit of using Amazon EI which is being able to configure the amount of vCPUs, memory, and GPU compute to match your needs.
Using Apache MXNet with Amazon EI
Apache MXNet is an open source deep learning framework used to build, train, and deploy deep neural networks. MXNet abstracts much of the complexity involved in implementing neural networks, is highly performant and scalable, and offers APIs across popular programming languages such as Python, C++, Java, R, Scala, and more. Amazon EI enabled Apache MXNet is available in the AWS Deep Learning AMI. A ‘pip’ package is also available on Amazon S3 so you can build it in to your own Amazon Linux or Ubuntu AMIs, or Docker containers.
Now we’ll analyze the performance (latency) and cost efficiency trade-offs for a ResNet-152 model for various instances. We’ll start with this example code from AWS and modify it for this blog post. The changes required to measure inference performance are in blue below:
You can see we added a loop around the inference call and timed the forward() and get_outputs() functions. MXNet uses lazy evaluation, so to force it to execute the forward call we need to use the outputs (by converting them to a numpy array). The first inference is abnormally slow due to initialization with the remote GPU on the EIA, so we stored the first inference time and summed the remaining inference latencies to compute an average.
Setting up an instance with an EI accelerator
We’ll launch an instance using the AWS Deep Learning AMI (DLAMI), which already provides support for Apache MXNet with Amazon EI. You can review Elastic Inference Prerequisites for the instructions related to Elastic Inference. You can review how to launch a DLAMI with an Elastic Inference Accelerator in the Elastic Inference documentation.
Testing on an instance with an EI accelerator
We launched a C5.4XLarge instance with the largest EI accelerator: EIA1.XLarge. This is probably more compute than we need but it will give us a good starting point from which to work backward from the best performance we can get with EI. Next, we activated the conda environment that was pre-installed for MXNet on EI with the following command:
Running our code on an instance with an EI accelerator produces this output:
Notice that the larger first inference time is 2763.00 ms. After the first inference, the average for the other 99 iterations is 20.34 ms.
Testing on a C5 instance
We can use the same script with just one change to run inference using only the CPU on the same instance. Here MXNet won’t use the EI accelerator when we set the context to CPU:
Running this code now produces this output:
Notice that the average inference is 44.61 ms. Compared to our initial run using the EI accelerator, the CPU takes 2.19x longer for each inference call on average when using a standard C5 instance.
Testing on GPU instances
Next, we launched a separate P2.XLarge instance to compare the performance to. We used the same DLAMI version. After the instance was launched we activated the regular MXNet conda environment:
Now we need to make two more tweaks to our script:
The first context that we change is the one used for binding, and the second context we change is the one that defines where our input data resides. For CPU and EIA instances, data must be allocated on a CPU context. It’s important to point out that typically you create your ndarrays on the same context that you bind the model to (CPU for CPU, and GPU for GPU). But for EIA you bind your model to the EIA context. You create your data with the CPU context. MXNet automatically copies the data over as needed for EIA.
Running this code on the P2.XLarge instance now produces this output:
Before we draw any conclusions, let’s launch a separate P3.2XLarge instance to compare the performance to. We can reuse the same script, DLAMI, and conda environment that we used earlier for the P2.XLarge instance. Running the code now produces this output on the P3.2XLarge instance:
Comparing C5, P2, P3, and EIA instances
Plotting the data we’ve collected thus far we can see that GPU performed better than CPU (as expected) and the V100 GPU in P3 instances is 3.34x faster than the K80 GPU in P2 instances. Where before you had to choose between P2 and P3, now EI gives you another choice in between with a 2.02x increase in speed over P2.

Based purely on instance cost per hour (in us-east-1 for EIA and EC2) we can see that the cost for the C5.4XL + EIA.XL is in between the costs for the P2 and P3 instances (see the following table). However, when factoring the cost to perform 100,000 inferences we can see that the P2 and P3 instances have similar costs, and the C5.4XL and the C5.4XL +EI instances are also within a penny of each other ($0.84 and $0.83). The big picture here is that by using EIA we get better than P2 performance at the cost of a C5 instance. What a deal!
| Instance Type | Cost per hour | Infer latency [ms] | Cost per 100k inferences |
| C5.4XLarge | $0.68 | 44.61 | $0.84 |
| C5.4XL + EIA.XL | $1.20 | 24.89 | $0.83 |
| P2.Xlarge | $0.90 | 41.10 | $1.03 |
| P3.2XLarge | $3.06 | 12.31 | $1.05 |
Exploring all possibilities
Now, let’s do more investigation and try out additional instance combinations for EI. After rerunning the initial script we started with on combinations of C5.Large, C5.XLarge, C5.2XLarge, and C5.4XLarge with EI accelerators EIA1.Medium, EIA1.Large, and EIA1.XLarge we produced the latest table:
| Host instance type | EI Accelerator type | Cost per hour | Infer latency [ms] | Cost per 100k inferences |
| C5.Large | EIA1.Medium | $0.22 | 39.00 | $0.23 |
| EIA1.Large | $0.35 | 25.68 | $0.25 | |
| EIA1.XLarge | $0.61 | 20.29 | $0.34 | |
| C5.XLarge | EIA1.Medium | $0.30 | 38.55 | $0.32 |
| EIA1.Large | $0.43 | 25.99 | $0.31 | |
| EIA1.XLarge | $0.69 | 21.12 | $0.40 | |
| C5.2XLarge | EIA1.Medium | $0.47 | 38.56 | $0.50 |
| EIA1.Large | $0.60 | 26.45 | $0.44 | |
| EIA1.XLarge | $0.86 | 20.76 | $0.50 | |
| C5.4XLarge | EIA1.Medium | $0.81 | 39.18 | $0.88 |
| EIA1.Large | $0.94 | 25.90 | $0.68 | |
| EIA1.XLarge | $1.20 | 20.34 | $0.68 |
In this table, when we look at the host instance types with the EIA1.Medium (yellow highlight) we see similar results. This means that there isn’t a lot of host-side processing, so going to a larger host instance doesn’t improve performance. This indicates to us that we can save on cost by choosing a smaller instance. Similarly, looking at host instances with all using the largest EIA1.XLarge accelerator (blue highlight) there isn’t a noticeable performance difference either. This confirms that EIA performance isn’t limited by the size of the host either. It also means that we can continue to use the C5.Large host instance type, achieve the same performance, and pay less.
Comparing inference latency
Now that we’ve decided on a C5.Large host instance type, we can look at the accelerator types. There is a progression from 39.18ms to 25.90ms and finally to 20.34ms in terms of inference latency. The following chart shows what we get if we add our new data points for the various accelerator sizes to our previous chart:
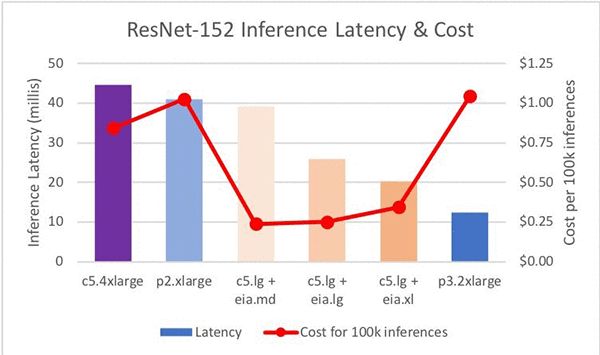
This chart shows that the EI accelerators provide a set of steps between P2 and P3 in terms of raw performance.
Comparing inference cost efficiency
The last column in the table shows the cost efficiency of the combination. Reviewing this column we see that the C5.Large + EIA1.Medium has the best cost efficiency. In a pure least-cost comparison, the C5.Large + EIA1.Medium combination provides the best cost efficiency when compared to the C5.4XL and the P2/P3 instances. Savings are 71 percent to 77 percent. And the C5.Large + EIA1.XLarge provides a 2.02x increase in speed over a P2 and a 2.19x speedup over the C5.4XL (CPU only). The savings are 66 percent and 59 percent, respectively.
Conclusions
Here’s what we’ve found so far:
- Combining EI accelerators with any host instance type enables users to choose the amount of host compute, memory, etc. with a configurable amount of GPU memory and compute.
- EI accelerators provide a range of memory and compute that is similar to P2 instances, but with a lower cost
- EI accelerators can bridge the gap in terms of raw performance (inference latency) between P2 and P3 instance types.
- EI accelerators can achieve a better cost efficiency than C5 and P2/P3 instances.
In our analysis we found that the ease of use in MXNet is as simple as changing the context for binding a model and ndarray creation. This allowed us to use largely the same test script on CPU, GPU, and EIA contexts in MXNet, and ease our testing and performance analysis.
We started with a Resnet-152 model running on a C5.4XLarge instance with a 44ms inference latency. We reduced it to 20ms by migrating to a C5.Large + EIA.XLarge. This resulted in a 2.19x increase in speed with a $0.07 hourly cost savings to top it off. We also found that we could achieve a 71 percent cost savings ($0.84versus $0.24 per 100k inferences) with a C5.Large + EIA.Medium and still get better performance (44ms versus 39ms).
Call to Action
Try out MXNet on EI and see how much you can save while still improving performance for inference on your model. Here are the steps we went through to analyze the design space for deep learning inference, and you can follow these steps for your model:
- Write a test script to analyze inference performance for CPU context.
- Create copies of the script with tweaks for GPU and EIA contexts.
- Run scripts on C5, P2, and P3 instance types to get a baseline for performance.
- Analyze the performance of EIA.
- Start with largest EI accelerator type and a large host instance type.
- Work backward until you find a combo that is too small.
- Introduce cost efficiency to the analysis by computing the cost to perform 100k inferences.
How much can you save while still improving the performance of inference for your model? How fast can you improve the inference latency of your model without spending a single cent more? Share your results in the comments section.
About the Authors
 Sam Skalicky is a Software Engineer with AWS Deep Learning and enjoys building heterogeneous high performance computing systems. He is an avid coffee enthusiast and avoids hiking at all costs.
Sam Skalicky is a Software Engineer with AWS Deep Learning and enjoys building heterogeneous high performance computing systems. He is an avid coffee enthusiast and avoids hiking at all costs.
 Hagay Lupesko is an Engineering Manager for AWS Deep Learning. He focuses on building Deep Learning tools that enable developers and scientists to build intelligent applications. In his spare time he enjoys reading, hiking and spending time with his family.
Hagay Lupesko is an Engineering Manager for AWS Deep Learning. He focuses on building Deep Learning tools that enable developers and scientists to build intelligent applications. In his spare time he enjoys reading, hiking and spending time with his family.