Amazon SageMaker Inference
Easily deploy and manage machine learning (ML) models for inference
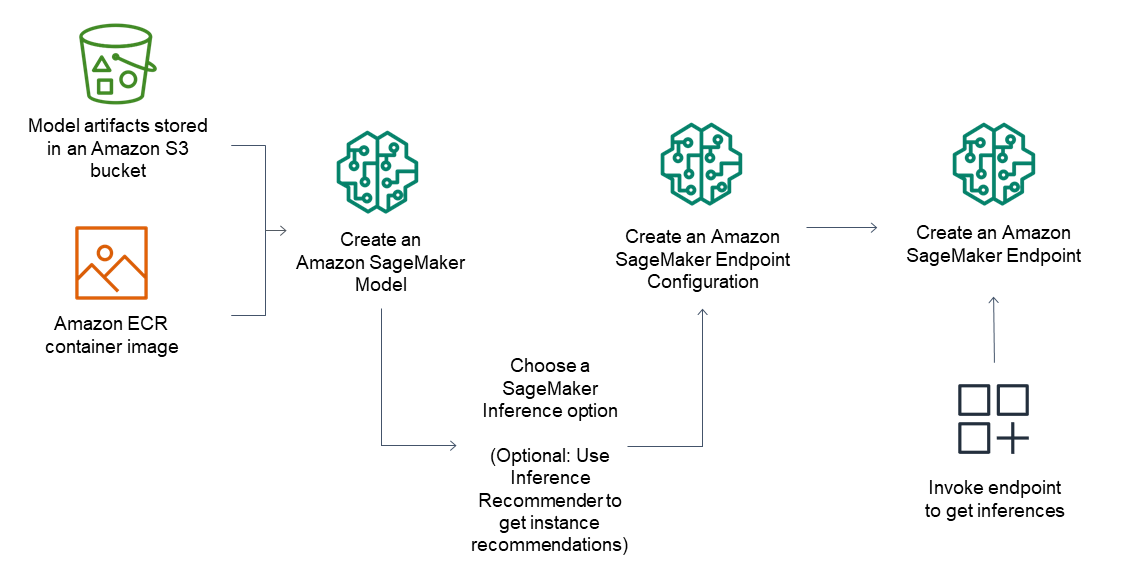
What is Amazon SageMaker Inference?
Amazon SageMaker AI simplifies deploying foundation and machine learning models to deliver optimal price performance for any use case. SageMaker inference auto-provisions from a prioritized instance pool when capacity is constrained. Additionally, it recommends optimal inference configurations — shrinking manual optimization and benchmarking cycles from weeks to hours. You define your cost, throughput, and latency requirements — let SageMaker AI do the rest, so your team can focus on building better models instead of managing infrastructure and performance.

Easily deploy and manage machine learning (ML) models for inference
Deploy models in production for inference for any use case
SageMaker AI caters to a wide range of inference requirements, from low latency (a few milliseconds) and high throughput (millions of transactions per second) scenarios to long-running inference for use cases such as multilingual text processing, text-image processing, multi-modal understanding, natural language processing, and computer vision. SageMaker AI provides a robust and scalable solution for all your inference needs.
Achieve optimal inference performance and cost
Amazon SageMaker AI offers more than 100 instance types with varying levels of compute and memory to suit different performance needs. To better utilize the underlying accelerators and reduce deployment cost, you can deploy multiple models to the same instance.
To better utilize the underlying accelerators and reduce deployment costs, inference recommendations apply goal-aligned optimizations, you can deploy multiple models to the same instance. For further cost optimization, autoscaling automatically adjusts the number of instances based on traffic, shutting down instances when there is no usage to minimize inference costs.
Reduce operational burden using SageMaker MLOps capabilities
As a fully managed service, Amazon SageMaker AI takes care of setting up and managing instances, software version compatibilities, and patching versions. With built-in integration with MLOps features, it helps off-load the operational overhead of deploying, scaling, and managing ML models while getting them to production faster.
Scalable and cost-effective inference options
Single-model endpoints
One model on a container hosted on dedicated instances or serverless for low latency and high throughput.
Multiple models on a single endpoint
Host multiple models to the same instance to better utilize the underlying accelerators, reducing deployment costs by up to 50%. You can control scaling policies for each FM separately, making it easier to adapt to model usage patterns while optimizing infrastructure costs.
Serial inference pipelines
Multiple containers sharing dedicated instances and executing in a sequence. You can use an inference pipeline to combine preprocessing, predictions, and post-processing data science tasks.
Serverless Inference
Deploy SageMaker models to Amazon Bedrock for serverless inference and eliminate infrastructure management completely. Bedrock's next-generation inference engine automatically optimizes for cost and latency and enforces Zero Operator Access security so no one—not even AWS operators—can access your data in transit. All without requiring you to manage a single GPU.

Support for most machine learning frameworks and model servers
Amazon SageMaker inference supports built-in algorithms and prebuilt Docker images for some of the most common machine learning frameworks such as TensorFlow, PyTorch, ONNX, and XGBoost. If none of the pre-built Docker images serve your needs, you can build your own container for use with CPU backed multi-model endpoints. SageMaker inference supports most popular model servers such as TensorFlow Serving, TorchServe, NVIDIA Triton, AWS multi-model server.
Amazon SageMaker AI offers specialized deep learning containers (DLCs), libraries, and tooling for model parallelism and large model inference (LMI), to help you improve performance of foundational models. With these options, you can deploy models including foundation models (FMs) quickly for virtually any use case.
Achieve high inference performance at low cost
Achieve high inference performance at low cost
SageMaker inference recommendations eliminate manual benchmarking and optimization to deliver optimal inference performance. Inference recommendations analyze your model architecture, apply goal-aligned optimizations like speculative decoding and kernel tuning, and benchmark on real GPU infrastructure using NVIDIA AIPerf to deliver deployment-ready configurations with validated performance metrics, which can reduce time to deploy models in production from weeks to hours. For more information click here.

Deploy models on the most high-performing infrastructure or go serverless
Amazon SageMaker AI offers more than 70 instance types with varying levels of compute and memory, including Amazon EC2 Inf1 instances based on AWS Inferentia, high-performance ML inference chips designed and built by AWS, and GPU instances such as Amazon EC2 G4dn. Or, choose Amazon SageMaker Serverless Inference to easily scale to thousands of models per endpoint, millions of transactions per second (TPS) throughput, and sub10 millisecond overhead latencies.

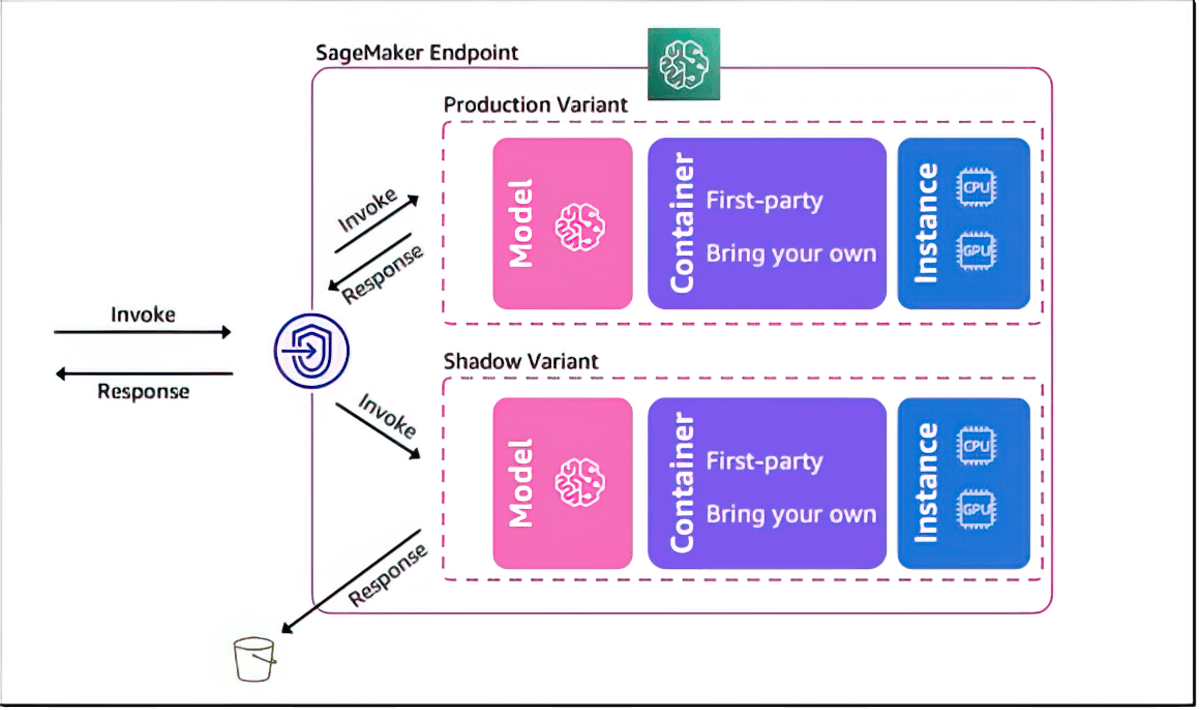
Shadow test to validate performance of ML models
Amazon SageMaker AI helps you evaluate a new model by shadow testing its performance against the currently SageMaker-deployed model using live inference requests. Shadow testing can help you catch potential configuration errors and performance issues before they impact end users. With SageMaker AI, you don’t need to invest weeks of time building your own shadow testing infrastructure. Just select a production model that you want to test against, and SageMaker AI automatically deploys the new model in shadow mode and routes a copy of the inference requests received by the production model to the new model in real time.
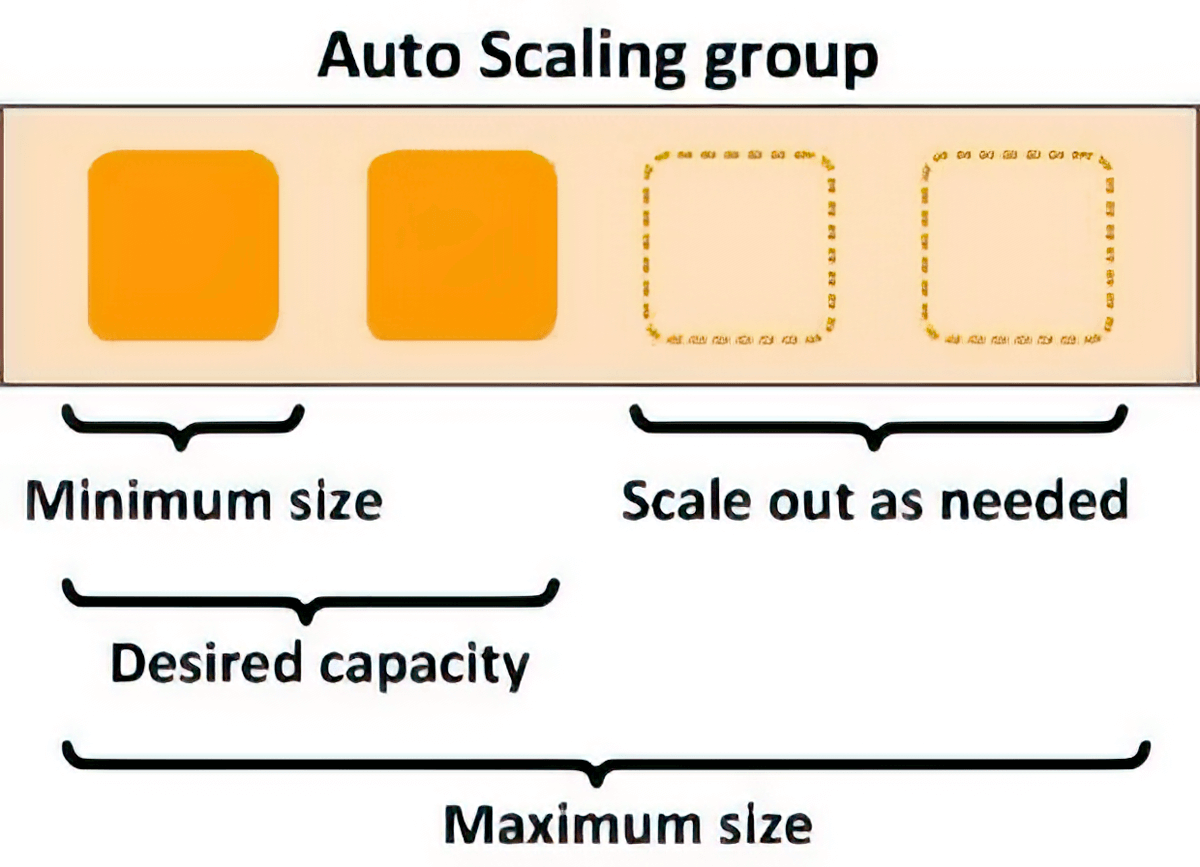
Autoscaling for elasticity
You can use scaling policies to automatically scale the underlying compute resources to accommodate fluctuations in inference requests. You can control scaling policies for each ML model separately to handle the changes in model usage easily, while also optimizing infrastructure costs.
Latency improvement and Intelligent routing
You can reduce inference latency for ML models by intelligently routing new inference requests to instances that are available instead of randomly routing requests to instances that are already busy serving inference requests, allowing you to achieve 20% lower inference latency on average.
Reduce operational burden and accelerate time to value
Fully managed model hosting and management
As a fully managed service, Amazon SageMaker AI takes care of setting up and managing instances, software version compatibilities, and patching versions. It also provides built-in metrics and logs for endpoints that you can use to monitor and receive alerts.
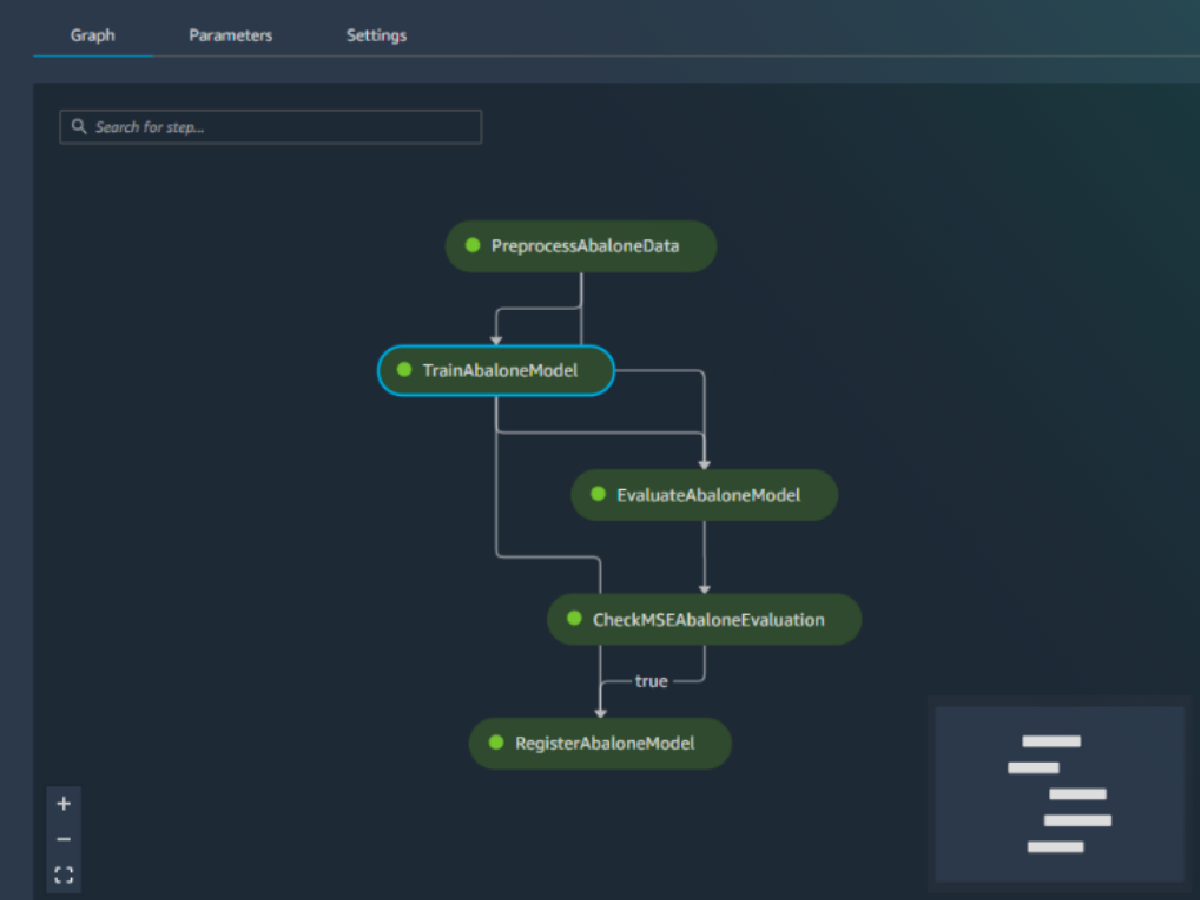
Built-in integration with MLOps features
Amazon SageMaker AI model deployment features are natively integrated with MLOps capabilities, including SageMaker Pipelines (workflow automation and orchestration), SageMaker Projects (CI/CD for ML), SageMaker Feature Store (feature management), SageMaker Model Registry (model and artifact catalog to track lineage and support automated approval workflows), SageMaker Clarify (bias detection), and SageMaker Model Monitor (model and concept drift detection). As a result, whether you deploy one model or tens of thousands, SageMaker AI helps off-load the operational overhead of deploying, scaling, and managing ML models while getting them to production faster.
Capacity-Aware Inference
SageMaker AI eliminates manual retries when instance capacity is unavailable to accelerate your time to deploy models in production. It automatically falls back to your next preferred instance and delivers endpoints in minutes, for both new and existing ones. Priority is honored across scale-up and scale-down.