Amazon SageMaker Model Training
Train and fine-tune ML and generative AI models
What is SageMaker Model Training?

Benefits of cost effective training
-
SageMaker AI offers a broad choice of GPUs and CPUs, as well as AWS accelerators such as AWS Trainium and AWS Inferentia, to enable large-scale model training. You automatically scale infrastructure up or down, from one to thousands of GPUs.
-
SageMaker AI allows you to automatically split your models and training datasets across AWS cluster instances to help you efficiently scale training workloads. It helps you to optimize your training job for AWS network infrastructure and cluster topology. You can also use optimized recipes to benefit from state-of-the-art performance and quickly get started training and fine-tuning publicly available generative AI models in minutes. It also streamlines model checkpointing through the recipes by optimizing the frequency of saving checkpoints, ensuring minimum overhead during training.
-
SageMaker AI can automatically tune your model by adjusting thousands of algorithm parameter combinations to arrive at the most accurate predictions. Use debugging and profiling tools to quickly correct performance issues and optimize training performance.
-
SageMaker AI enables efficient ML experiments to help you more easily track ML model iterations. Improve model training performance by visualizing the model architecture to identify and remediate convergence issues.
Train models at scale
Fully managed training jobs
SageMaker training jobs offer a fully managed user experience for large distributed FM training, removing the undifferentiated heavy lifting around infrastructure management. SageMaker training jobs automatically spins up a resilient distributed training cluster, monitors the infrastructure, and auto-recovers from faults to ensure a smooth training experience. Once the training is complete, SageMaker spins down the cluster and you are billed for the net training time. In addition, with SageMaker training jobs, you have the flexibility to choose the right instance type to best fits an individual workload (for example, pretrain a large language model (LLM) on a P5 cluster or fine tune an open source LLM on p4d instances) to further optimize your training budget. In addition, SagerMaker training jobs offers a consistent user experience across ML teams with varying levels of technical expertise and different workload types.
SageMaker HyperPod
Amazon SageMaker HyperPod is a purpose-built infrastructure to efficiently manage compute clusters to scale foundation model (FM) development. It enables advanced model training techniques, infrastructure control, performance optimization, and enhanced model observability. SageMaker HyperPod is preconfigured with SageMaker distributed training libraries, allowing you to automatically split models and training datasets across AWS cluster instances to help efficiently utilize the cluster’s compute and network infrastructure. It enables a more resilient environment by automatically detecting, diagnosing, and recovering from hardware faults, allowing you to continually train FMs for months without disruption, reducing training time by up to 40%.
High-performance distributed training
SageMaker AI makes it faster to perform distributed training by automatically splitting your models and training datasets across AWS accelerators. It helps you optimize your training job for AWS network infrastructure and cluster topology. It also streamlines model checkpointing through the recipes by optimizing the frequency of saving checkpoints, ensuring minimum overhead during training.
Customize generative AI and ML models efficiently
Amazon SageMaker AI enables customization of both Amazon proprietary and publicly available foundation models using custom datasets eliminating the need to train them from scratch. Data scientists and developers of all skill sets can quickly get started with training and fine-tuning of public as well as proprietary generative AI models using optimized recipes. Each recipe is tested by AWS, removing weeks of tedious work testing different model configurations to achieve state-of-the-art performance. With recipes, you can fine-tune popular publicly available model families including Llama, Mixtral, and Mistral. In addition, you can customize Amazon Nova foundation models, including Nova Micro, Nova Lite, and Nova Pro for your business-specific use cases on Amazon SageMaker AI using a suite of techniques across all stages of model training. Available as ready-to-use SageMaker recipes, these capabilities allow customers to adapt Nova models across the entire model lifecycle, including supervised fine-tuning, alignment, and pre-training.
Built-in tools for the highest accuracy and lowest cost
Automatic model tuning
SageMaker AI can automatically tune your model by adjusting thousands of algorithm parameter combinations to arrive at the most accurate predictions, saving weeks of effort. It helps you to find the best version of a model by running many training jobs on your dataset.
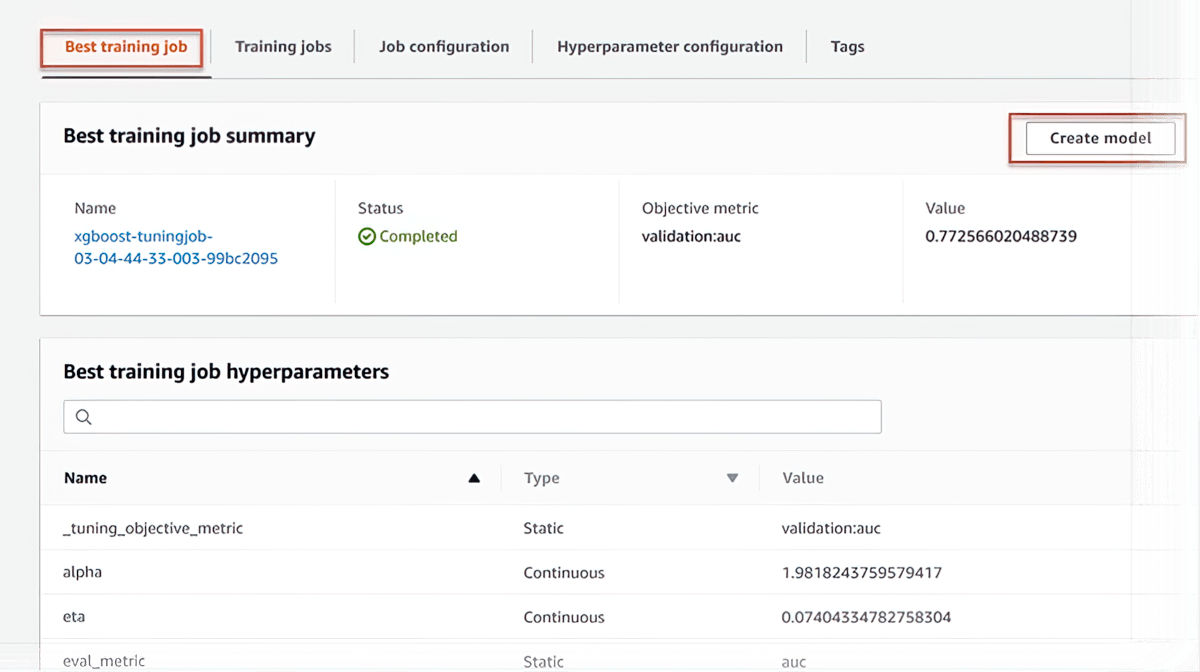
Managed Spot training
SageMaker AI helps reduce training costs by up to 90 percent by automatically running training jobs when compute capacity becomes available. These training jobs are also resilient to interruptions caused by changes in capacity.
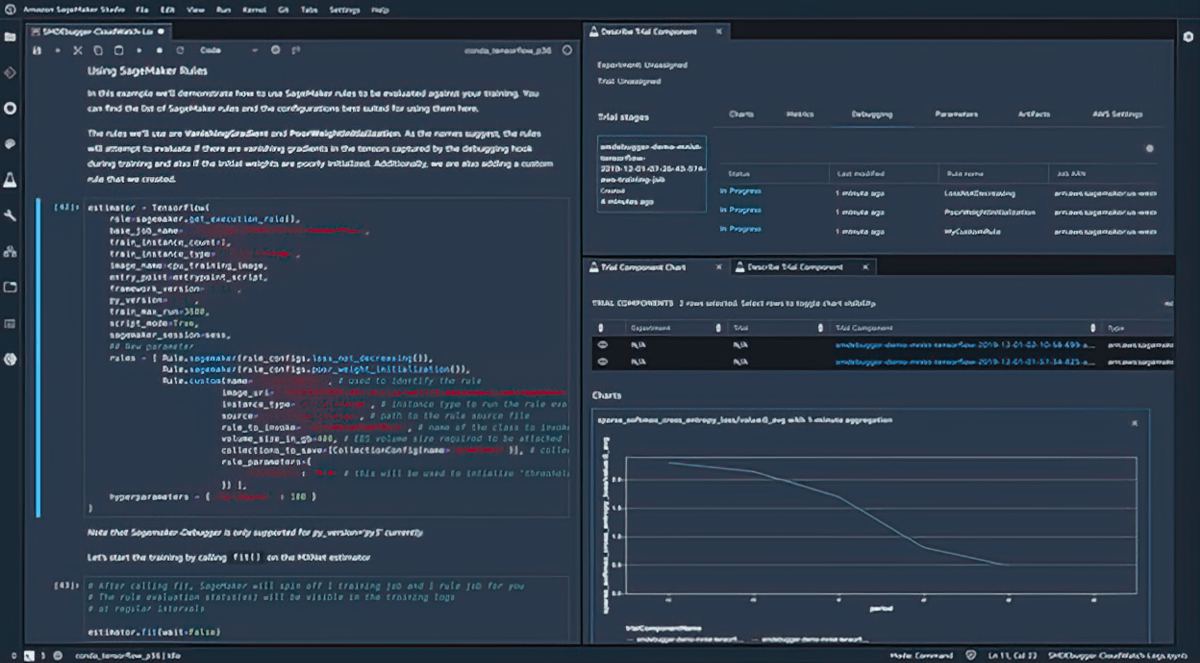
Debugging
Amazon SageMaker Debugger captures metrics and profiles training jobs in real time, so you can quickly correct performance issues before deploying the model to production. You can also remotely connect to the model training environment in SageMaker for debugging with access to the underlying training container.
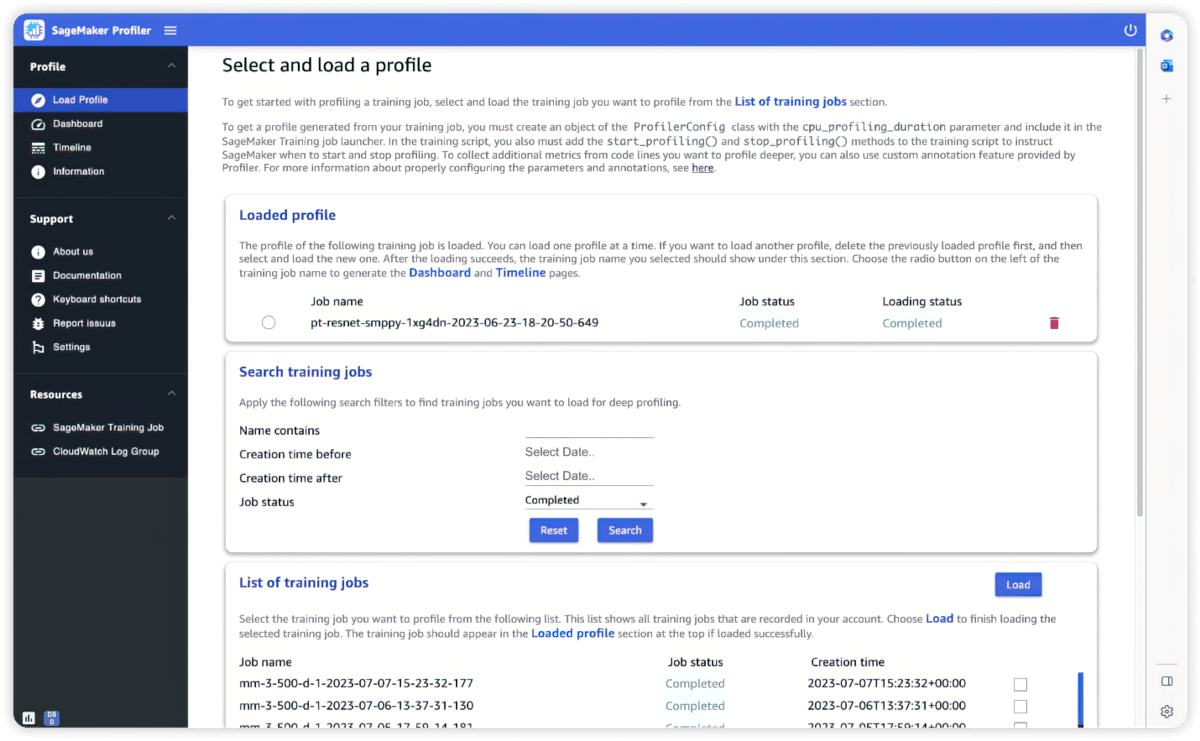
Profiler
Amazon SageMaker Profiler helps you optimize training performance with granular hardware profiling insights including aggregated GPU and CPU utilization metrics, high resolution GPU/CPU trace plots, custom annotations, and visibility into mixed precision utilization.
Built-in tools for interactivity and monitoring
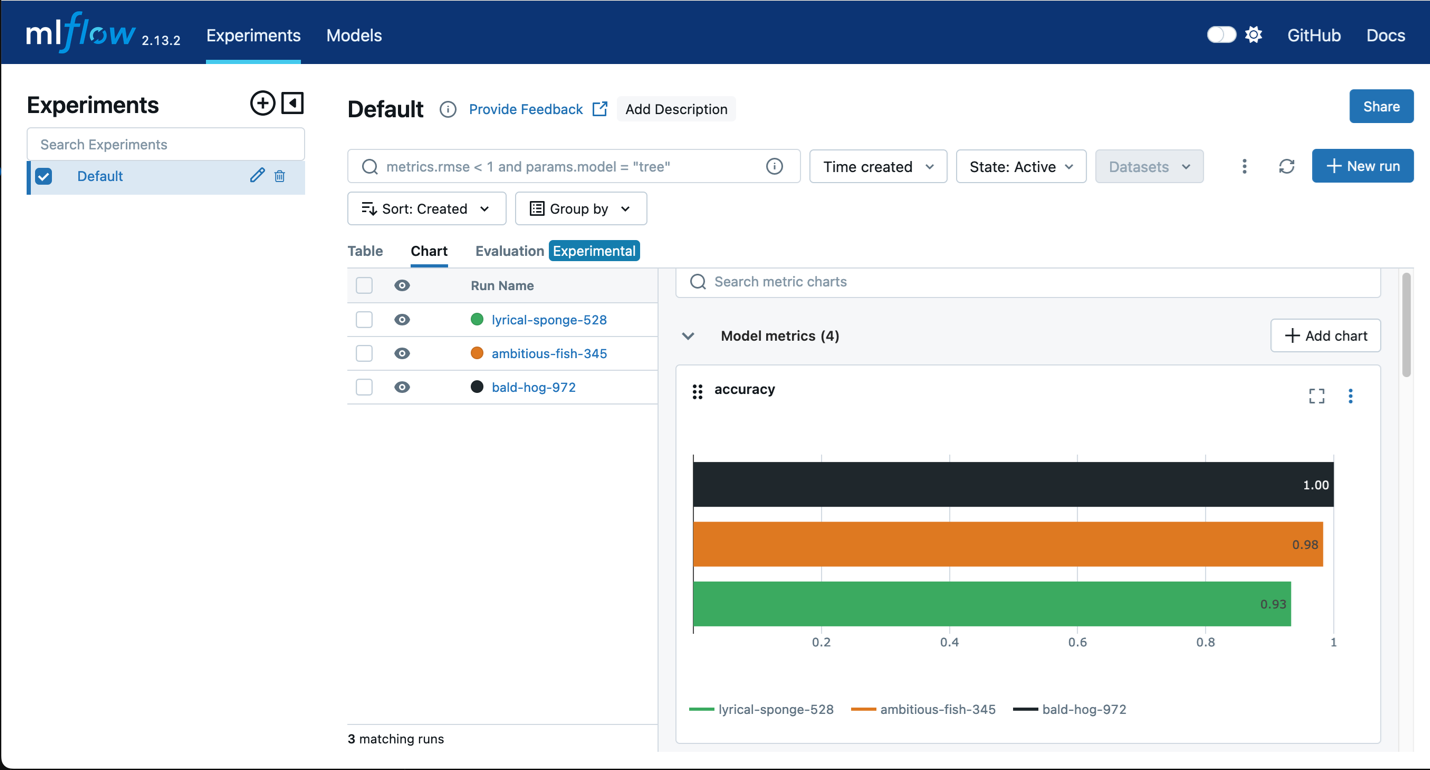
Amazon SageMaker with MLflow
Use MLflow with SageMaker training to capture input parameters, configurations, and results, helping you quickly identify the best-performing models for your use case. The MLflow UI allows you to analyze model training attempts and effortlessly register candidate models for production in one quick step.
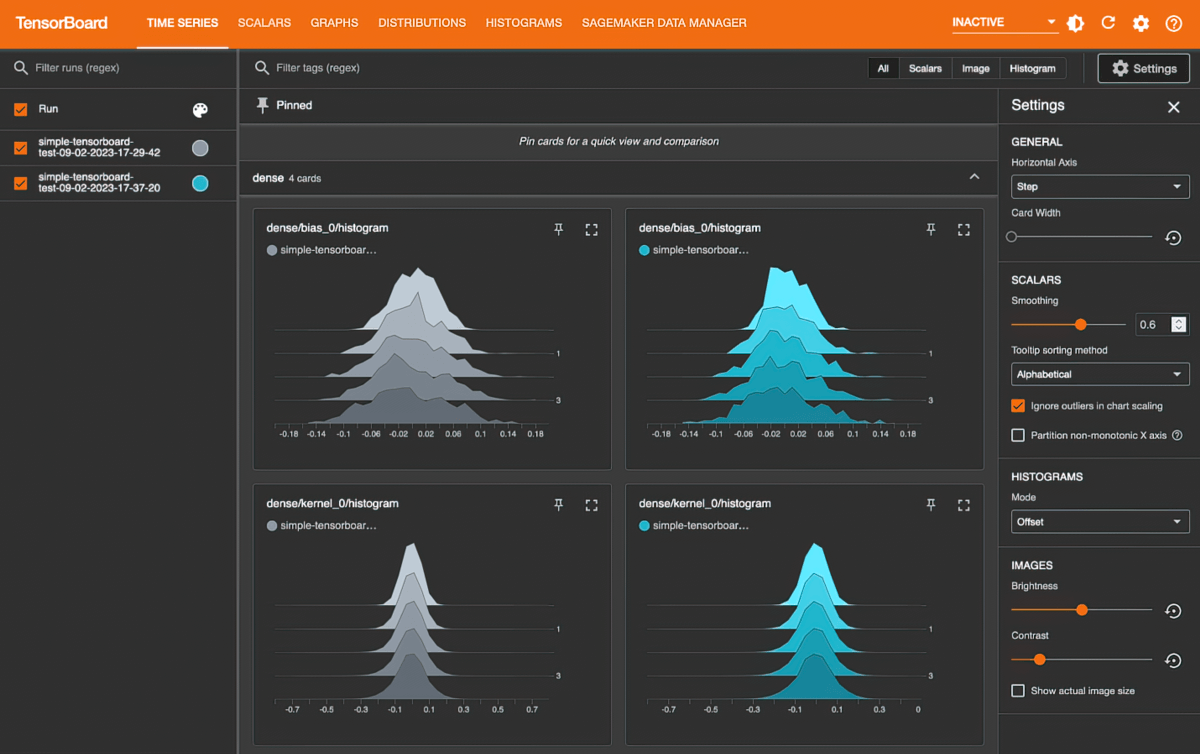
Amazon SageMaker with TensorBoard
Amazon SageMaker with TensorBoard helps you to save development time by visualizing the model architecture to identify and remediate convergence issues, such as validation loss not converging or vanishing gradients.
Flexible and faster training
Full customization
SageMaker AI comes with built-in libraries and tools to make model training easier and faster. SageMaker AI works with popular open source ML models such as GPT, BERT, and DALL·E; ML frameworks, such as PyTorch and TensorFlow; and transformers, such as Hugging Face. With SageMaker AI, you can use popular open source libraries and tools, such as DeepSpeed, Megatron, Horovod, Ray Tune, and TensorBoard, based on your needs.
Local code conversion
Amazon SageMaker Python SDK helps you run ML code authored in your preferred integrated development environment (IDE) and local notebooks along with the associated runtime dependencies as large-scale ML model training jobs with minimal code changes. You only need to add a line of code (Python decorator) to your local ML code. SageMaker Python SDK takes the code along with the datasets and workspace environment setup and runs it as a SageMaker training job.
Automated ML training workflows
Automating training workflows using Amazon SageMaker Pipelines helps you create a repeatable process to orchestrate model development steps for rapid experimentation and model retraining. You can automatically run steps at regular intervals or when certain events are initiated, or you can run them manually as needed.
Flexible training plans
To meet your training timelines and budgets, SageMaker AI helps you create the most cost-efficient training plans that use compute resources from multiple blocks of compute capacity. Once you approve the training plans, SageMaker AI automatically provisions the infrastructure and runs the training jobs on these compute resources without requiring any manual intervention, saving weeks of effort managing the training process to align jobs with compute availability.
Resources
Get started with SageMaker Model Training
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages