Artificial Intelligence
Improve price performance of your model training using Amazon SageMaker heterogeneous clusters
This post is co-written with Chaim Rand from Mobileye.
Certain machine learning (ML) workloads, such as training computer vision models or reinforcement learning, often involve combining the GPU- or accelerator-intensive task of neural network model training with the CPU-intensive task of data preprocessing, like image augmentation. When both types of tasks run on the same instance type, the data preprocessing gets bottlenecked on CPU, leading to lower GPU utilization. This issue becomes worse with time as the throughput of newer generations of GPUs grows at a steeper pace than that of CPUs.
To address this issue, in July 2022, we launched heterogeneous clusters for Amazon SageMaker model training, which enables you to launch training jobs that use different instance types in a single job. This allows offloading parts of the data preprocessing pipeline to compute-optimized instance types, whereas the deep neural network (DNN) task continues to run on GPU or accelerated computing instance types. Our benchmarks show up to 46% price performance benefit after enabling heterogeneous clusters in a CPU-bound TensorFlow computer vision model training.
For a similar use case, Mobileye, an autonomous vehicle technologies development company, had this to share:
“By moving CPU-bound deep learning computer vision model training to run over multiple instance types (CPU and GPU/ML accelerators), using a tf.data.service based solution we’ve built, we managed to reduce time to train by 40% while reducing the cost to train by 30%. We’re excited about heterogeneous clusters allowing us to run this solution on Amazon SageMaker.”
— AI Engineering, Mobileye
In this post, we discuss the following topics:
- How heterogeneous clusters help remove CPU bottlenecks
- When to use heterogeneous clusters, and other alternatives
- Reference implementations in PyTorch and TensorFlow
- Performance benchmark results
- Heterogeneous clusters at Mobileye
AWS’s accelerated computing instance family includes accelerators from AWS custom chips (AWS Inferentia, AWS Trainium), NVIDIA (GPUs), and Gaudi accelerators from Habana Labs (an Intel company). Note that in this post, we use the terms GPU and accelerator interchangeably.
How heterogeneous clusters remove data processing bottlenecks
Data scientists who train deep learning models aim to maximize training cost-efficiency and minimize training time. To achieve this, one basic optimization goal is to have high GPU utilization, the most expensive and scarce resource within the Amazon Elastic Compute Cloud (Amazon EC2) instance. This can be more challenging with ML workloads that combine the classic GPU-intensive neural network model’s forward and backward propagation with CPU-intensive tasks, such as data processing and augmentation in computer vision or running an environment simulation in reinforcement learning. These workloads can end up being CPU bound, where having more CPU would result in higher throughput and faster and cheaper training as existing accelerators are partially idle. In some cases, CPU bottlenecks can be solved by switching to another instance type with a higher CPU:GPU ratio. However, there are situations where switching to another instance type may not be possible due to the instance family’s architecture, storage, or networking dependencies.
In such situations, you have to increase the amount of CPU power by mixing instance types: instances with GPUs together with CPU. Summed together, this results in an overall higher CPU:GPU ratio. Until recently, SageMaker training jobs were limited to having instances of a single chosen instance type. With SageMaker heterogeneous clusters, data scientists can easily run a training job with multiple instance types, which enables offloading some of the existing CPU tasks from the GPU instances to dedicated compute-optimized CPU instances, resulting in higher GPU utilization and faster and more cost-efficient training. Moreover, with the extra CPU power, you can have preprocessing tasks that were traditionally done offline as a preliminary step to training become part of your training job. This makes it faster to iterate and experiment over both data preprocessing and DNN training assumptions and hyperparameters.
For example, consider a powerful GPU instance type, ml.p4d.24xlarge (96 vCPU, 8 x NVIDIA A100 GPUs), with a CPU:GPU ratio of 12:1. Let’s assume your training job needs 20 vCPUs to preprocess enough data to keep one GPU 100% utilized. Therefore, to keep all 8 GPUs 100% utilized, you need a 160 vCPUs instance type. However, ml.p4d.24xlarge is short of 64 vCPUs, or 40%, limiting GPU utilization to 60%, as depicted on the left of the following diagram. Would adding another ml.p4d.24xlarge instance help? No, because the job’s CPU:GPU ratio would remain the same.
With heterogeneous clusters, we can add two ml.c5.18xlarge (72 vCPU), as shown on the right of the diagram. The net total vCPU in this cluster is 210 (96+2*72), leading to a CPU:GPU ratio to 30:1. Each of these compute-optimized instances will be offloaded with a data preprocessing CPU-intensive task, and will allow efficient GPU utilization. Despite the extra cost of the ml.c5.18xlarge, the higher GPU utilization allows faster processing, and therefore higher price performance benefits.

When to use heterogeneous clusters, and other alternatives
In this section, we explain how to identify a CPU bottleneck, and discuss solving it using instance type scale up vs. heterogeneous clusters.
The quick way to identify a CPU bottleneck is to monitor CPU and GPU utilization metrics for SageMaker training jobs in Amazon CloudWatch. You can access these views from the AWS Management Console within the training job page’s instance metrics hyperlink. Pick the relevant metrics and switch from 5-minute to 1-minute resolution. Note that the scale is 100% per vCPU or GPU, so the utilization rate for an instance with 4 vCPUs/GPUs could be as high as 400%. The following figure is one such example from CloudWatch metrics, where CPU is approximately 100% utilized, indicating a CPU bottleneck, whereas GPU is underutilized.

For detailed diagnosis, run the training jobs with Amazon SageMaker Debugger to profile resource utilization status, statistics, and framework operations, by adding a profiler configuration when you construct a SageMaker estimator using the SageMaker Python SDK. After you submit the training job, review the resulting profiler report for CPU bottlenecks.
If you conclude that your job could benefit from a higher CPU:GPU compute ratio, first consider scaling up to another instance type in the same instance family, if one is available. For example, if you’re training your model on ml.g5.8xlarge (32 vCPUs, 1 GPU), consider scaling up to ml.g5.16xlarge (64 vCPUs, 1 GPU). Or, if you’re training your model using multi-GPU instance ml.g5.12xlarge (48 vCPUs, 4 GPUs), consider scaling up to ml.g5.24xlarge (96 vCPUs, 4 GPUs). Refer to the G5 instance family specification for more details.
Sometimes, scaling up isn’t an option, because there is no instance type with a higher vCPU:GPU ratio in the same instance family. For example, if you’re training the model on ml.trn1.32xlarge, ml.p4d.24xlarge, or ml.g5.48xlarge, you should consider heterogeneous clusters for SageMaker model training.
Besides scaling up, we’d like to note that there are additional alternatives to a heterogeneous cluster, like NVIDIA DALI, which offloads image preprocessing to the GPU. For more information, refer to Overcoming Data Preprocessing Bottlenecks with TensorFlow Data Service, NVIDIA DALI, and Other Methods.
To simplify decision-making, refer to the following flowchart.
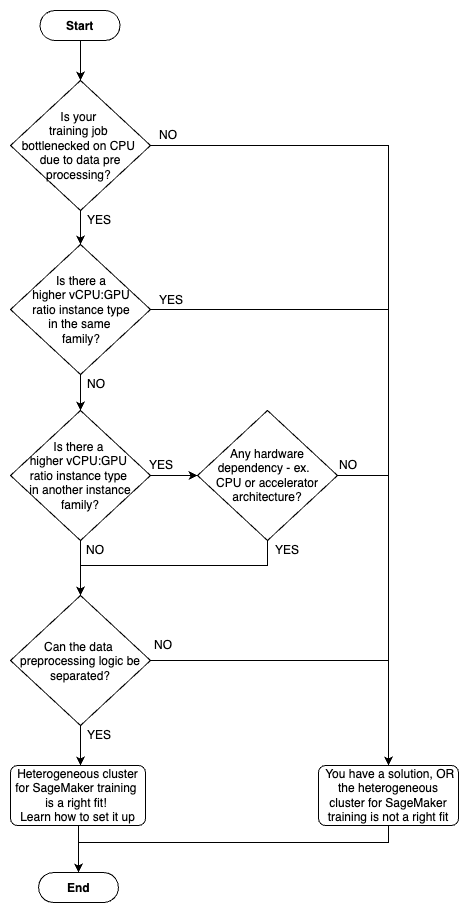
How to use SageMaker heterogeneous clusters
To get started quickly, you can directly jump to the TensorFlow or PyTorch examples provided as part of this post.
In this section, we walk you through how to use a SageMaker heterogeneous cluster with a simple example. We assume that you already know how to train a model with the SageMaker Python SDK and the Estimator class. If not, refer to Using the SageMaker Python SDK before continuing.
Prior to this feature, you initialized the training job’s Estimator class with the InstanceCount and InstanceType parameters, which implicitly assumes you only have a single instance type (a homogeneous cluster). With the release of heterogeneous clusters, we introduced the new sagemaker.instance_group.InstanceGroup class. This represents a group of one or more instances of a specific instance type, designed to carry a logical role (like data processing or neural network optimization. You can have two or more groups, and specify a custom name for each instance group, the instance type, and the number of instances for each instance group. For more information, refer to Using the SageMaker Python SDK and Using the Low-Level SageMaker APIs.
After you have defined the instance groups, you need to modify your training script to read the SageMaker training environment information that includes heterogeneous cluster configuration. The configuration contains information such as the current instance groups, the current hosts in each group, and in which group the current host resides with their ranking. You can build logic in your training script to assign the instance groups to certain training and data processing tasks. In addition, your training script needs to take care of inter-instance group communication or distributed data loading mechanisms (for example, tf.data.service in TensorFlow or generic gRPC client-server) or any other framework (for example, Apache Spark).
Let’s go through a simple example of launching a heterogeneous training job and reading the environment configuration at runtime.
- When defining and launching the training job, we configure two instance groups used as arguments to the SageMaker estimator:
from sagemaker.instance_group import InstanceGroup data_group = InstanceGroup("data_group", "ml.c5.18xlarge", 2) dnn_group = InstanceGroup("dnn_group", "ml.p4d.24xlarge", 1) from sagemaker.pytorch import PyTorch estimator = PyTorch(..., entry_point='launcher.py', instance_groups=[data_group, dnn_group] ) - On the entry point training script (named
launcher.py), we read the heterogeneous cluster configuration to whether the instance will run the preprocessing or DNN code:
With this, let’s summarize the tasks SageMaker does on your behalf, and the tasks that you are responsible for.
SageMaker performs the following tasks:
- Provision different instance types according to instance group definition.
- Provision input channels on all or specific instance groups.
- Distribute training scripts and dependencies to instances.
- Set up an MPI cluster on a specific instance group, if defined.
You are responsible for the following tasks:
- Modify your start training job script to specify instance groups.
- Implement a distributed data pipeline (for example,
tf.data.service). - Modify your entry point script (see
launcher.pyin the example notebook) to be a single entry point that will run on all the instances, detect which instance group it’s running in, and trigger the relevant behavior (such as data processing or DNN optimization). - When the training loop is over, you must make sure that your entry point process exits on all instances across all instance groups. This is important because SageMaker waits for all the instances to finish processing before it marks the job as complete and stops billing. The
launcher.pyscript in the TensorFlow and PyTorch example notebooks provides a reference implementation of signaling data group instances to exit when DNN group instances finish their work.
Example notebooks for SageMaker heterogeneous clusters
In this section, we provide a summary of the example notebooks for both TensorFlow and PyTorch ML frameworks. In the notebooks, you can find the implementation details, walkthroughs on how the code works, code snippets that you could reuse in your training scripts, flow diagrams, and cost-comparison analysis.
Note that in both examples, you shouldn’t expect the model to converge in a meaningful way. Our intent is only to measure the data pipeline and neural network optimization throughput expressed in epoch/step time. You must benchmark with your own model and dataset to produce price performance benefits that match your workload.
Heterogeneous cluster using a tf.data.service based distributed data loader (TensorFlow)
This notebook demonstrates how to implement a heterogeneous cluster for SageMaker training using TensorFlow’s tf.data.service based distributed data pipeline. We train a deep learning computer vision model Resnet50 that requires CPU-intensive data augmentation. It uses Horvod for multi-GPU distributed data parallelism.
We run the workload in two configurations: first as a homogeneous cluster, single ml.p4d.24xlarge instance, using a standard tf.data pipeline that showcases CPU bottlenecks leading to lower GPU utilization. In the second run, we switch from a single instance type to two instance groups using a SageMaker heterogeneous cluster. This run offloads some of the data processing to additional CPU instances (using tf.data.service).
We then compare the homogeneous and heterogeneous configurations and find key price performance benefits. As shown in the following table, the heterogeneous job (86ms/step) is 2.2 times faster to train than the homogeneous job (192ms/step), making it 46% cheaper to train a model.
| Example 1 (TF) | ml.p4d.24xl | ml.c5.18xl | Price per Hour* | Average Step Time | Cost per Step | Price Performance Improvement |
| Homogeneous | 1 | 0 | $37.688 | 192 ms | $0.201 | . |
| Heterogeneous | 1 | 2 | $45.032 | 86 ms | $0.108 | 46% |
* Price per hour is based on us-east-1 SageMaker on-demand pricing
This speedup is made possible by utilizing the extra vCPU, provided by the data group, and faster preprocessing. See the notebook for more details and graphs.
Heterogeneous cluster using a gRPC client-server based distributed data loader (PyTorch)
This notebook demonstrates a sample workload using a heterogeneous cluster for SageMaker training using a gRPC client-server based distributed data loader. This example uses a single GPU. We use the PyTorch model based on the following official MNIST example. The training code has been modified to be heavy on data preprocessing. We train this model in both homogeneous and heterogeneous cluster modes, and compare price performance.
In this example, we assumed the workload can’t benefit from multiple GPUs, and has dependency on a specific GPU architecture (NVIDIA V100). We ran both homogeneous and heterogeneous training jobs, and found key price performance benefits, as shown in the following table. The heterogeneous job (1.19s/step) is 6.5 times faster to train than the homogeneous job (0.18s/step), making it 77% cheaper to train a model.
| Example 2 (PT) | ml.p3.2xl | ml.c5.9xl | Price per Hour* | Average Step Time | Cost per Step | Price Performance Improvement |
| Homogeneous | 1 | 0 | $3.825 | 1193 ms | $0.127 | . |
| Heterogeneous | 1 | 1 | $5.661 | 184 ms | $0.029 | 77% |
* Price per hour is based on us-east-1 SageMaker on-demand pricing
This is possible because with a higher CPU count, we could use 32 data loader workers (compared to 8 with ml.p3.2xlarge) to preprocess the data and kept GPU close to 100% utilized at frequent intervals. See the notebook for more details and graphs.
Heterogeneous clusters at Mobileye
Mobileye, an Intel company, develops Advanced Driver Assistance Systems (ADAS) and autonomous vehicle technologies with the goal of revolutionizing the transportation industry, making roads safer, and saving lives. These technologies are enabled using sophisticated computer vision (CV) models that are trained using SageMaker on large amounts of data stored in Amazon Simple Storage Service (Amazon S3). These models use state-of-the-art deep learning neural network techniques.
We noticed that for one of our CV models, the CPU bottleneck was primarily caused by heavy data preprocessing leading to underutilized GPUs. For this specific workload, we started looking at alternative solutions, evaluated distributed data pipeline technologies with heterogeneous clusters based on EC2 instances, and came up with reference implementations for both TensorFlow and PyTorch. The release of the SageMaker heterogeneous cluster allows us to run this and similar workloads on SageMaker to achieve improved price performance benefits.
Considerations
With the launch of the heterogeneous cluster feature, SageMaker offers a lot more flexibility in mixing and matching instance types within your training job. However, consider the following when using this feature:
- The heterogeneous cluster feature is available through SageMaker PyTorch and TensorFlow framework estimator classes. Supported frameworks are PyTorch v1.10 or later and TensorFlow v2.6 or later.
- All instance groups share the same Docker image.
- All instance groups share the same training script. Therefore, your training script should be modified to detect which instance group it belongs to and fork runs accordingly.
- The training instances hostnames (for example, alog-1, algo-2, and so on) are randomly assigned, and don’t indicate which instance group they belong to. To get the instance’s role, we recommend getting its instance group membership during runtime. This is also relevant when reviewing logs in CloudWatch, because the log stream name
[training-job-name]/algo-[instance-number-in-cluster]-[epoch_timestamp]has the hostname. - A distributed training strategy (usually an MPI cluster) can be applied only to one instance group.
- SageMaker Managed Warm Pools and SageMaker Local Mode cannot currently be used with heterogeneous cluster training.
Conclusion
In this post, we discussed when and how to use the heterogeneous cluster feature of SageMaker training. We demonstrated a 46% price performance improvement on a real-world use case and helped you get started quickly with distributed data loader (tf.data.service and gRPC client-server) implementations. You can use these implementations with minimal code changes in your existing training scripts.
To get started, try out our example notebooks. To learn more about this feature, refer to Train Using a Heterogeneous Cluster.
About the authors
 Gili Nachum is a senior AI/ML Specialist Solutions Architect who works as part of the EMEA Amazon Machine Learning team. Gili is passionate about the challenges of training deep learning models, and how machine learning is changing the world as we know it. In his spare time, Gili enjoy playing table tennis.
Gili Nachum is a senior AI/ML Specialist Solutions Architect who works as part of the EMEA Amazon Machine Learning team. Gili is passionate about the challenges of training deep learning models, and how machine learning is changing the world as we know it. In his spare time, Gili enjoy playing table tennis.
 Hrushikesh Gangur is a principal solutions architect for AI/ML startups with expertise in both ML Training and AWS Networking. He helps startups in Autonomous Vehicle, Robotics, CV, NLP, MLOps, ML Platform, and Robotics Process Automation technologies to run their business efficiently and effectively on AWS. Prior to joining AWS, Hrushikesh acquired 20+ years of industry experience primarily around Cloud and Data platforms.
Hrushikesh Gangur is a principal solutions architect for AI/ML startups with expertise in both ML Training and AWS Networking. He helps startups in Autonomous Vehicle, Robotics, CV, NLP, MLOps, ML Platform, and Robotics Process Automation technologies to run their business efficiently and effectively on AWS. Prior to joining AWS, Hrushikesh acquired 20+ years of industry experience primarily around Cloud and Data platforms.
 Gal Oshri is a Senior Product Manager on the Amazon SageMaker team. He has 7 years of experience working on Machine Learning tools, frameworks, and services.
Gal Oshri is a Senior Product Manager on the Amazon SageMaker team. He has 7 years of experience working on Machine Learning tools, frameworks, and services.
 Chaim Rand is a machine learning algorithm developer working on deep learning and computer vision technologies for Autonomous Vehicle solutions at Mobileye, an Intel Company. Check out his blogs.
Chaim Rand is a machine learning algorithm developer working on deep learning and computer vision technologies for Autonomous Vehicle solutions at Mobileye, an Intel Company. Check out his blogs.