Artificial Intelligence
Category: Amazon SageMaker

AWS AI/ML Community attendee guides to AWS re:Invent 2021
The AWS AI/ML Community has compiled a series of session guides to AWS re:Invent 2021 to help you get the most out of re:Invent this year. They covered four distinct categories relevant to AI/ML. With a number of our guide authors attending re:Invent virtually, you will find a balance between virtually accessible sessions and sessions […]

Next Gen Stats Decision Guide: Predicting fourth-down conversion
It is fourth-and-one on the Texans’ 36-yard line with 3:21 remaining on the clock in a tie game. Should the Colts’ head coach Frank Reich send out kicker Rodrigo Blankenship to attempt a 54-yard field goal or rely on his offense to convert a first down? Frank chose to go for it, leading to a […]
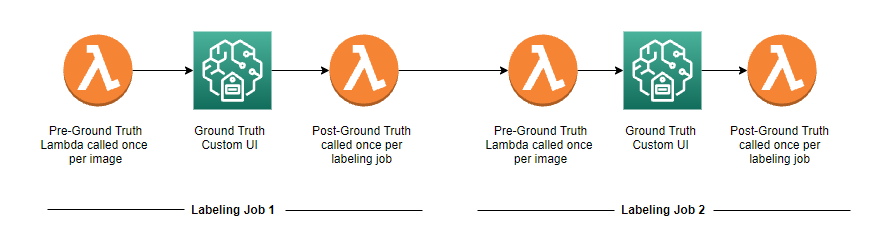
Chain custom Amazon SageMaker Ground Truth jobs for image processing
Amazon SageMaker Ground Truth supports many different types of labeling jobs, including several image-based labeling workflows like image-level labels, bounding box-specific labels, or pixel-level labeling. For situations not covered by these standard approaches, Ground Truth also supports custom image-based labeling, which allows you to create a labeling workflow with a completely unique UI and associated […]

Accelerate data preparation using Amazon SageMaker Data Wrangler for diabetic patient readmission prediction
Patient readmission to hospital after prior visits for the same disease results in an additional burden on healthcare providers, the health system, and patients. Machine learning (ML) models, if built and trained properly, can help understand reasons for readmission, and predict readmission accurately. ML could allow providers to create better treatment plans and care, which […]

Use Amazon SageMaker ACK Operators to train and deploy machine learning models
AWS recently released the new Amazon SageMaker Operators for Kubernetes using the AWS Controllers for Kubernetes (ACK). ACK is a framework for building Kubernetes custom controllers, where each controller communicates with an AWS service API. These controllers allow Kubernetes users to provision AWS resources like databases or message queues simply by using the Kubernetes API. […]

Design a compelling record filtering method with Amazon SageMaker Model Monitor
As artificial intelligence (AI) and machine learning (ML) technologies continue to proliferate, using ML models plays a crucial role in converting the insights from data into actual business impacts. Operational ML means streamlining every step of the ML lifecycle and deploying the best models within the existing production system. And within that production system, the […]
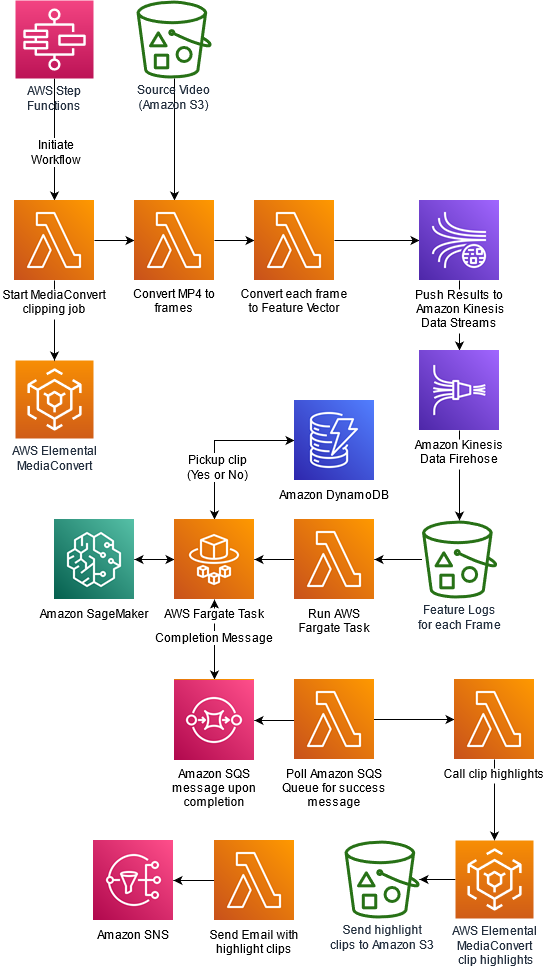
Automatically detect sports highlights in video with Amazon SageMaker
July 2023: Please refer to the Media Replay Engine (MRE) solution presented in this Github repo instead, for the latest and more efficient solution for this use case. MRE is a framework for building automated video clipping and replay (highlight) generation pipelines using AWS services for live and video-on-demand (VOD) content. Extracting highlights from a […]

AWS and NVIDIA launch “Hands-on Machine Learning with Amazon SageMaker and NVIDIA GPUs” on Coursera
Note to readers: Enrollment for this course has been temporarily paused until the start of 2022. Stay tuned for further announcements. AWS and NVIDIA are excited to announce the new Hands-on Machine Learning with Amazon SageMaker and NVIDIA GPUs course. The course has four parts, and is designed to help machine learning (ML) enthusiasts quickly learn […]

Use integrated explainability tools and improve model quality using Amazon SageMaker Autopilot
Whether you are developing a machine learning (ML) model for reducing operating cost, improving efficiency, or improving customer satisfaction, there are no perfect solutions when it comes to producing an effective model. From an ML development perspective, data scientists typically go through stages of data exploration, feature engineering, model development, and model training and tuning […]

Deploy fast and scalable AI with NVIDIA Triton Inference Server in Amazon SageMaker
Machine learning (ML) and deep learning (DL) are becoming effective tools for solving diverse computing problems, from image classification in medical diagnosis, conversational AI in chatbots, to recommender systems in ecommerce. However, ML models that have specific latency or high throughput requirements can become prohibitively expensive to run at scale on generic computing infrastructure. To […]