Artificial Intelligence
Use a SageMaker Pipeline Lambda step for lightweight model deployments
With Amazon SageMaker Pipelines, you can create, automate, and manage end-to-end machine learning (ML) workflows at scale. SageMaker Projects build on SageMaker Pipelines by providing several MLOps templates that automate model building and deployment pipelines using continuous integration and continuous delivery (CI/CD). To help you get started, SageMaker Pipelines provides many predefined step types, such as steps for data processing, model training, model tuning, and batch scoring. You can use a callback step to add functionality to your pipelines using other AWS services. With the new Lambda step that enables you to add an AWS Lambda function to your pipelines, you now have even more flexibility to create custom pipeline functionality.
You can use the Lambda step to run serverless tasks or jobs on Lambda such as splitting datasets or sending custom notifications. There are many other possibilities. For example, although you generally should use SageMaker Projects for robust model deployments with CI/CD best practices, there may be circumstances where it makes sense to use a Lambda step for lightweight model deployments to SageMaker hosting services. By “lightweight,” we mean deployments to development or test endpoints, or to internal endpoints that aren’t customer-facing or serving high volumes of traffic.
In this post, we examine the details of the Lambda step and how you can use it to add custom functionality to your pipelines. Next, we go into the specifics of using the Lambda step for lightweight model deployments. Our example use case involves using SageMaker Pipelines to orchestrate training a Hugging Face natural language processing (NLP) model on the IMDb movie reviews dataset, and deploying it to SageMaker Asynchronous Inference. You can follow along with sample code on GitHub.
Create a Lambda step
Lambda is a serverless compute service that lets you run code without provisioning or managing servers. With Lambda, you can run code in your preferred language for virtually any type of application or backend service—all with minimal administration. In the context of SageMaker Pipelines, a Lambda step enables you to add a Lambda function to your pipelines to support arbitrary compute operations, especially lightweight operations that have short duration. Keep in mind that in a SageMaker Pipelines Lambda step, a Lambda function is limited to 10 minutes maximum runtime, with a modifiable default timeout of 2 minutes.
You have two ways to add a Lambda step to your pipelines. First, you can supply the ARN of an existing Lambda function that you created with the AWS Cloud Development Kit (AWS CDK), AWS Management Console, or otherwise. Second, the high-level SageMaker Python SDK has a Lambda helper convenience class that allows you to create a new Lambda function along with your other code defining your pipeline. Just provide three parameters: a script with your function code, a function name, and an AWS Identity and Access Management (IAM) role for the Lambda function. The role specifies permissions for the Lambda function, such as permissions to access the SageMaker Model Registry or other features and services. As always, follow the principle of least privilege. Given these parameters, SageMaker automatically creates a new Lambda function and runs it as part of the Lambda step. For more information, see the Lambda step documentation.
The Lambda function script for a Lambda step is written the same way as for any other Lambda function. Like all Lambda functions, it must implement a handler method to respond to events, in this case events from the pipeline. To create the actual Lambda function, use the Lambda helper convenience as shown in the following code snippet. You can change the default timeout and specify the Lambda function size.
To create a Lambda step, supply the Lambda function created with the helper, and specify the inputs and outputs.
A lightweight deployment pipeline
Sometimes you need to deploy models to development or test endpoints, or to internal endpoints that aren’t customer-facing or serving high volumes of traffic. These kinds of endpoints may be suitable for lightweight deployment with a Lambda step. The Lambda step can perform tasks such as looking up the latest approved model registered in the SageMaker Model Registry after model building is complete, and then updating an endpoint with that model (or creating a new endpoint if one doesn’t already exist). The overall architecture is shown in the following diagram.
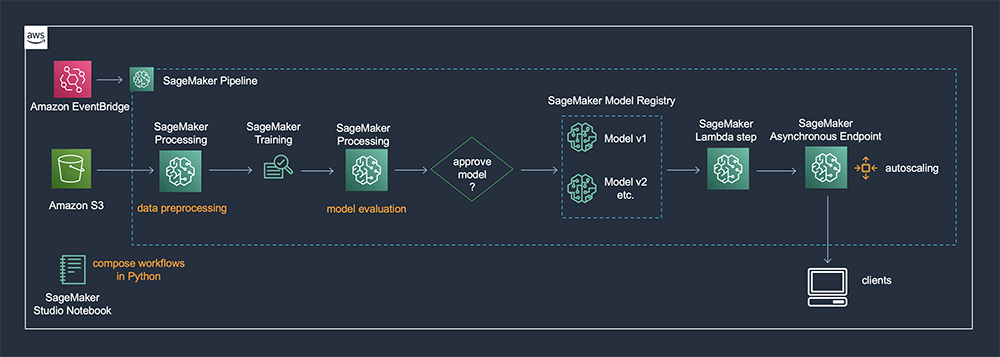
In the sample code for this post, we use SageMaker Pipelines to orchestrate training a Hugging Face NLP model on the IMDb movie reviews dataset and deploying it. Libraries such as the transformers library published by Hugging Face make it easy to add state-of-the-art NLP models to your applications. SageMaker offers a direct integration for Hugging Face models: the HuggingFace estimator in the high-level SageMaker Python SDK enables training, fine-tuning, and optimizing Hugging Face models built with PyTorch and TensorFlow, all with minimal setup. There also is a Hugging Face Inference Toolkit for SageMaker, as described in Announcing managed inference for Hugging Face models in Amazon SageMaker.
Besides a Lambda step, SageMaker Asynchronous Inference is another helpful feature for lightweight deployments. Asynchronous inference is suitable for handling large inference payloads that require a substantial amount of processing time, and where latency requirements are flexible. This may be the case for complex models such as some of the larger Hugging Face NLP models. Asynchronous inference creates a persistent endpoint where the number of instances behind the endpoint can be scaled down to zero. This helps with cost-optimizing workloads where data arrives at the endpoint intermittently, such as our example use case where new movie reviews may occasionally trickle in for predictions.
To create an Asynchronous Inference endpoint, we define an AsyncInferenceConfig object that configures the endpoint to receive asynchronous invocations. This is part of the overall EndpointConfiguration that defines the endpoint’s parameters, such as the model to be deployed and the initial instance count and type. In the AsyncInferenceConfig object, we provide an output Amazon Simple Storage Service (Amazon S3) location for predictions. You also can optionally specify an Amazon Simple Notification Service (Amazon SNS) topic on which to send notifications about predictions. This is shown in the following code snippet.
The complete pipeline includes a processing step, training step, evaluation step and model quality condition. If the model quality condition threshold is met, then additional pipeline steps are run: a model registration step, and deployment using the Lambda step we defined. To begin a pipeline execution, simply call the start method of the pipeline.
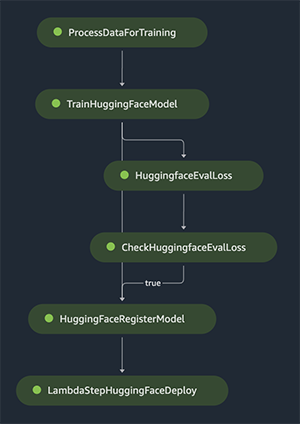
After the endpoint is deployed, you can use the endpoint name to create a SageMaker Predictor object to wrap the endpoint so you can get predictions from it. In the pipeline details page in SageMaker Studio, the pipeline graph will appear as follows after a successful pipeline execution.
Conclusion
SageMaker Pipelines offers extensive flexibility to customize your pipelines to orchestrate virtually any ML workflow. A convenient way to customize a pipeline is to add a Lambda step, which enables you to add serverless compute operations to your pipelines for many different kinds of tasks such as lightweight deployments. To get started with the Lambda step, see the Lambda step documentation and the sample code for this post on GitHub.
About the Authors
 Brent Rabowsky focuses on data science at AWS, and leverages his expertise to help AWS customers with their own data science projects.
Brent Rabowsky focuses on data science at AWS, and leverages his expertise to help AWS customers with their own data science projects.
 Kirit Thadaka is an ML Solutions Architect working in the SageMaker Service SA team. Prior to joining AWS, Kirit spent time working in early stage AI startups followed by some time in consulting in various roles in AI research, MLOps, and technical leadership.
Kirit Thadaka is an ML Solutions Architect working in the SageMaker Service SA team. Prior to joining AWS, Kirit spent time working in early stage AI startups followed by some time in consulting in various roles in AI research, MLOps, and technical leadership.
 Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.