Artificial Intelligence
Category: Amazon SageMaker

Run PyTorch Lightning and native PyTorch DDP on Amazon SageMaker Training, featuring Amazon Search
So much data, so little time. Machine learning (ML) experts, data scientists, engineers and enthusiasts have encountered this problem the world over. From natural language processing to computer vision, tabular to time series, and everything in-between, the age-old problem of optimizing for speed when running data against as many GPUs as you can get has […]

Amazon SageMaker JumpStart solutions now support custom IAM role settings
Amazon SageMaker JumpStart solutions are a feature within Amazon SageMaker Studio that allow a simple-click experience to set up your own machine learning (ML) workflows. When you launch a solution, various of AWS resources are set up in your account to demonstrate how the business problem can be solved using the pre-built architecture. The solutions […]
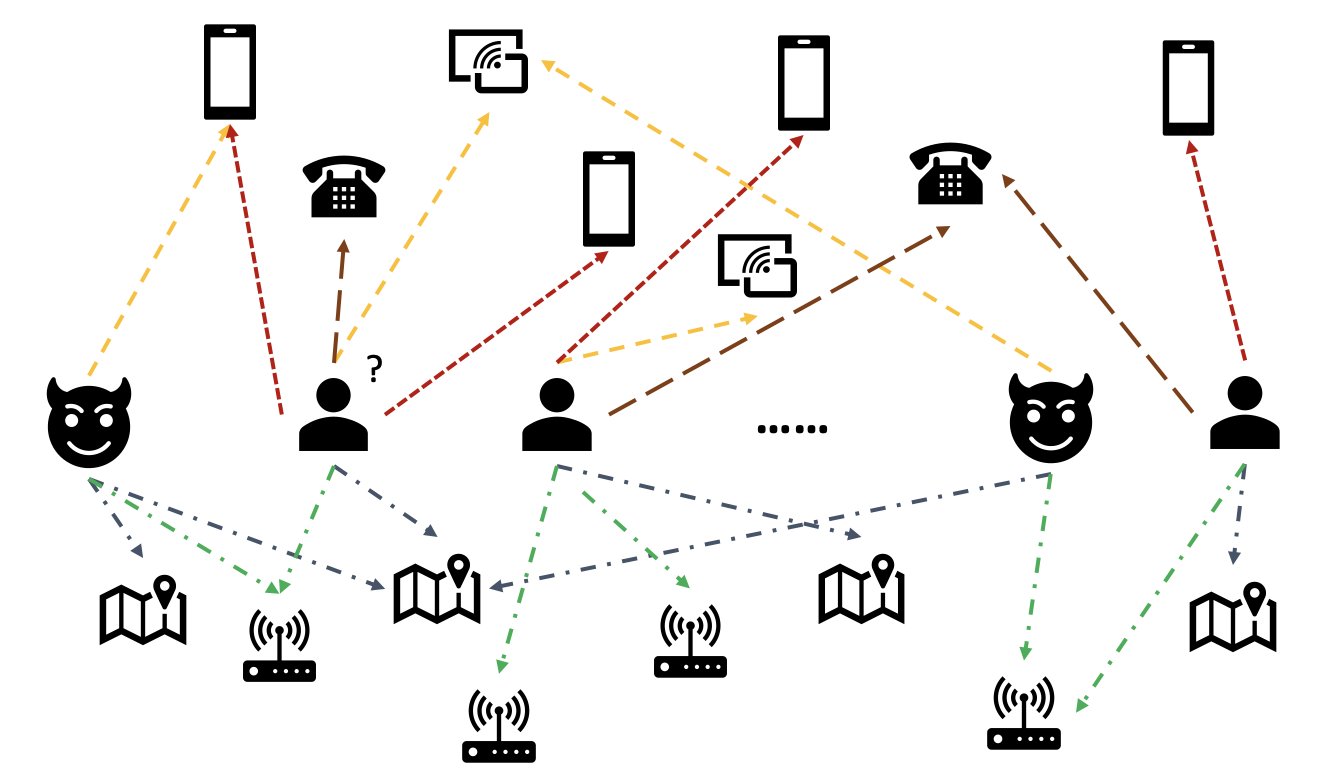
Build a GNN-based real-time fraud detection solution using Amazon SageMaker, Amazon Neptune, and the Deep Graph Library
Fraudulent activities severely impact many industries, such as e-commerce, social media, and financial services. Frauds could cause a significant loss for businesses and consumers. American consumers reported losing more than $5.8 billion to frauds in 2021, up more than 70% over 2020. Many techniques have been used to detect fraudsters—rule-based filters, anomaly detection, and machine […]

Amazon SageMaker Automatic Model Tuning now supports SageMaker Training Instance Fallbacks
Today Amazon SageMaker announced the support of SageMaker training instance fallbacks for Amazon SageMaker Automatic Model Tuning (AMT) that allow users to specify alternative compute resource configurations. SageMaker automatic model tuning finds the best version of a model by running many training jobs on your dataset using the ranges of hyperparameters that you specify for your […]

Create Amazon SageMaker model building pipelines and deploy R models using RStudio on Amazon SageMaker
In November 2021, in collaboration with RStudio PBC, we announced the general availability of RStudio on Amazon SageMaker, the industry’s first fully managed RStudio Workbench IDE in the cloud. You can now bring your current RStudio license to easily migrate your self-managed RStudio environments to Amazon SageMaker in just a few simple steps. RStudio is […]

MLOps at the edge with Amazon SageMaker Edge Manager and AWS IoT Greengrass
October 2023: Starting in April 26th, 2024, you can no longer access Amazon SageMaker Edge Manager. For more information about continuing to deploy your models to edge devices, see SageMaker Edge Manager end of life. Internet of Things (IoT) has enabled customers in multiple industries, such as manufacturing, automotive, and energy, to monitor and control […]

Optimal pricing for maximum profit using Amazon SageMaker
This is a guest post by Viktor Enrico Jeney, Senior Machine Learning Engineer at Adspert. Adspert is a Berlin-based ISV that developed a bid management tool designed to automatically optimize performance marketing and advertising campaigns. The company’s core principle is to automate maximization of profit of ecommerce advertising with the help of artificial intelligence. The […]

Promote feature discovery and reuse across your organization using Amazon SageMaker Feature Store and its feature-level metadata capability
Amazon SageMaker Feature Store helps data scientists and machine learning (ML) engineers securely store, discover, and share curated data used in training and prediction workflows. Feature Store is a centralized store for features and associated metadata, allowing features to be easily discovered and reused by data scientist teams working on different projects or ML models. […]
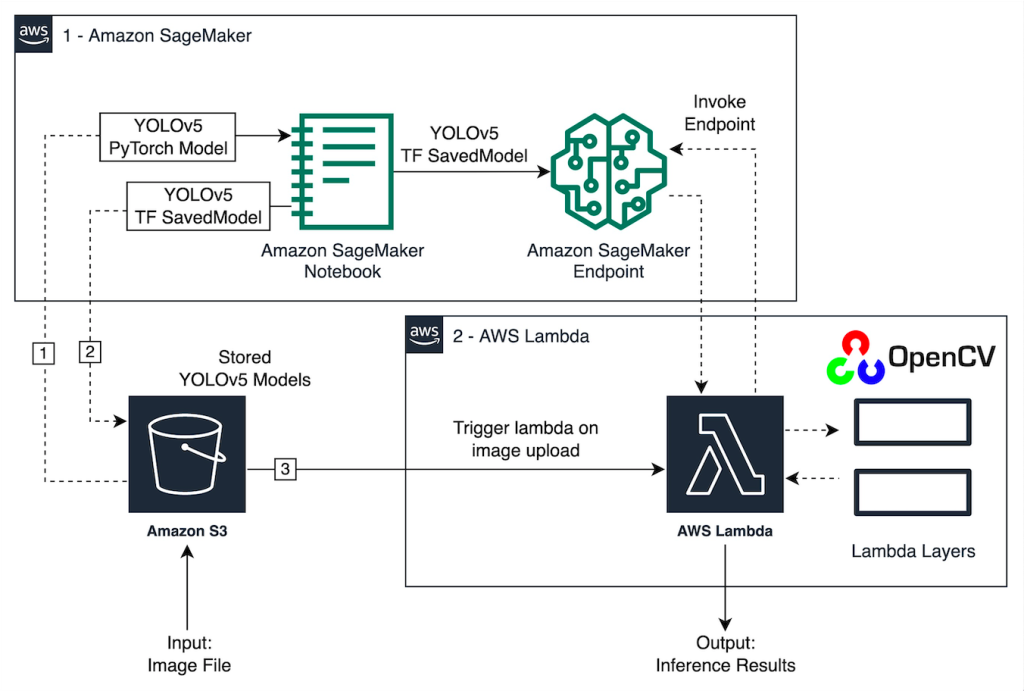
Scale YOLOv5 inference with Amazon SageMaker endpoints and AWS Lambda
After data scientists carefully come up with a satisfying machine learning (ML) model, the model must be deployed to be easily accessible for inference by other members of the organization. However, deploying models at scale with optimized cost and compute efficiencies can be a daunting and cumbersome task. Amazon SageMaker endpoints provide an easily scalable […]
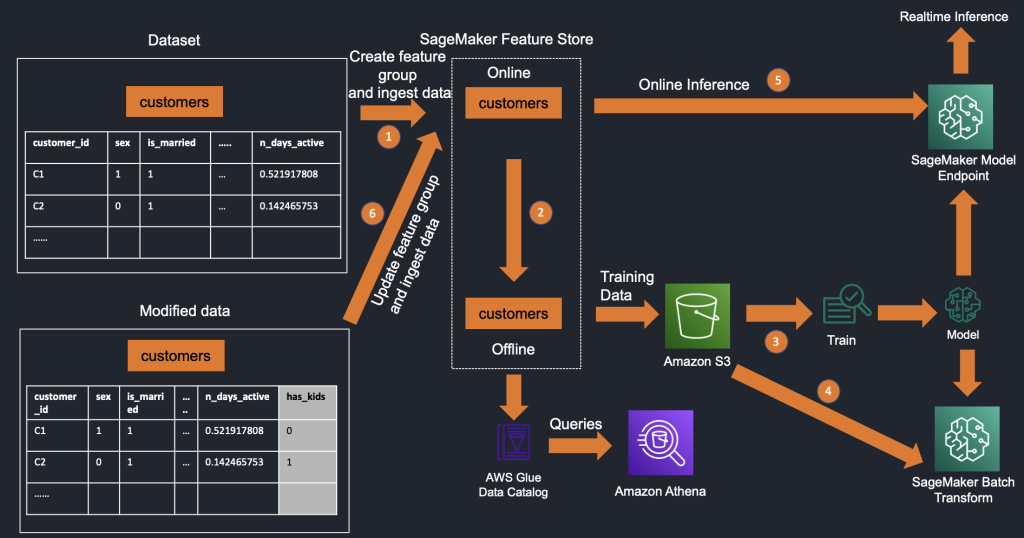
Simplify iterative machine learning model development by adding features to existing feature groups in Amazon SageMaker Feature Store
Feature engineering is one of the most challenging aspects of the machine learning (ML) lifecycle and a phase where the most amount of time is spent—data scientists and ML engineers spend 60–70% of their time on feature engineering. AWS introduced Amazon SageMaker Feature Store during AWS re:Invent 2020, which is a purpose-built, fully managed, centralized […]