Artificial Intelligence
How Rufus scales conversational shopping experiences to millions of Amazon customers with Amazon Bedrock
Our team at Amazon builds Rufus, an AI-powered shopping assistant which delivers intelligent, conversational experiences to delight our customers.
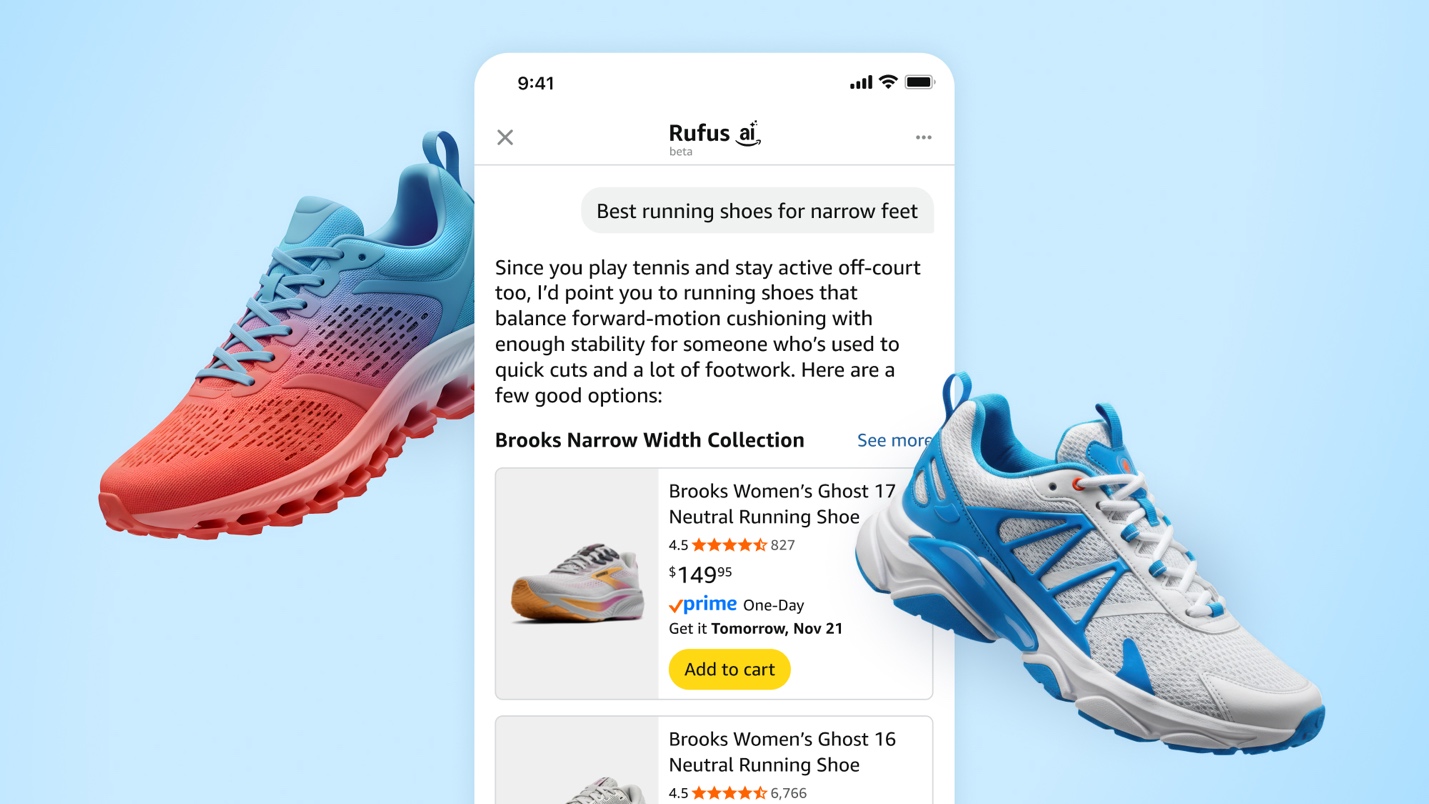
More than 250 million customers have used Rufus this year. Monthly users are up 140% YoY and interactions are up 210% YoY. Additionally, customers that use Rufus during a shopping journey are 60% more likely to complete a purchase. To make this possible, our team carefully evaluates every decision, aiming to focus on what matters most: building the best agentic shopping assistant experience. By focusing on customer-driven features, Rufus is now smarter, faster, and more useful.
In this post, we’ll share how our adoption of Amazon Bedrock accelerated the evolution of Rufus.
Building a customer-driven architecture
Defining clear use cases are fundamental to shaping both requirements and implementation, and building an AI-powered shopping assistant is no exception. For a shopping assistant like Rufus our use cases align with the kinds of questions customers ask, and we aim to exceed their expectations with every answer. For example, a customer may want to know something factual about the shoes they’re considering and ask, “are these shoes waterproof?” Another customer may want to ask Rufus for recommendations and ask, “give me a few good options for shoes suitable for marathon running.” These examples represent just a fraction of the diverse question types we designed Rufus to support by working backwards from customer use cases.
After we defined our customer use cases, we design Rufus with the entire stack in mind to work seamlessly for customers. From initial release to subsequent iterations, we collect metrics to see how well Rufus is doing with the aim to keep getting better. This means not only measuring how accurately questions are answered using tools like LLM-as-a-judge, but also analyzing factors such as latency, repeat customer engagement, and number of conversation turns per interaction, to gain deeper insights into customer engagement.
Expanding beyond our in-house LLM
We first launched Rufus by building our own in-house large language model (LLM). The decision to build a custom LLM was driven by the need to use a model that was specialized on shopping domain questions. At first, we considered off-the-shelf models but most of these did not do well in our shopping evaluations (evals). Other models came with the cost of being larger and therefore were slower and more costly. We didn’t need a model that did well across many domains, we needed a model that did well in the shopping domain, while maintaining high accuracy, low latency, and cost performance. By building our custom LLM and deploying it using AWS silicon, we were able to go into production worldwide supporting large scale events such as Prime Day when we used 80,000 AWS Inferentia and Trainium chips.
After the initial success of Rufus, we aimed to expand into use cases requiring advanced reasoning, larger context windows, and multi-step reasoning. However, training an LLM presents a significant challenge: iterations can take weeks or months to complete. With newer more capable models being released at an accelerated pace, we aimed to improve Rufus as quickly as possible and began to evaluate and adopt state-of-the-art models rapidly. To launch these new features and build a truly remarkable shopping assistant Amazon Bedrock was the natural solution.
Accelerating Rufus with Amazon Bedrock
Amazon Bedrock is a comprehensive, secure, and flexible platform for building generative AI applications and agents. Amazon Bedrock connects you to leading foundation models (FMs), services to deploy and operate agents, and tools for fine-tuning, safeguarding, and optimizing models along with knowledge bases to connect applications to your latest data so that you have everything you need to quickly move from experimentation to real-world deployment. Amazon Bedrock gives you access to hundreds of FMs from leading AI companies along with evaluation tools to pick the best model based on your unique performance and cost needs.
Amazon Bedrock provides us great value by:
- Managing hosting of leading foundation models (FMs) from different providers and making them available through model agnostic interfaces such as the converse API. By providing access to frontier models we can evaluate and integrate them quickly with minimal changes to our existing systems. This increased our velocity. We can use the best model for the task while balancing characteristics like cost, latency, and accuracy.
- Addressing significant operational overhead from the Rufus team such as managing model hosting infrastructure, handling scaling challenges, or maintaining model serving pipelines around the world where Amazon operates. Bedrock handles the heavy lifting, allowing customers to concentrate on building innovative solutions for their unique needs.
- Providing global availability for consistent deployment supporting multiple geographic regions. By using Amazon Bedrock we launched in new marketplaces quickly with minimal effort.
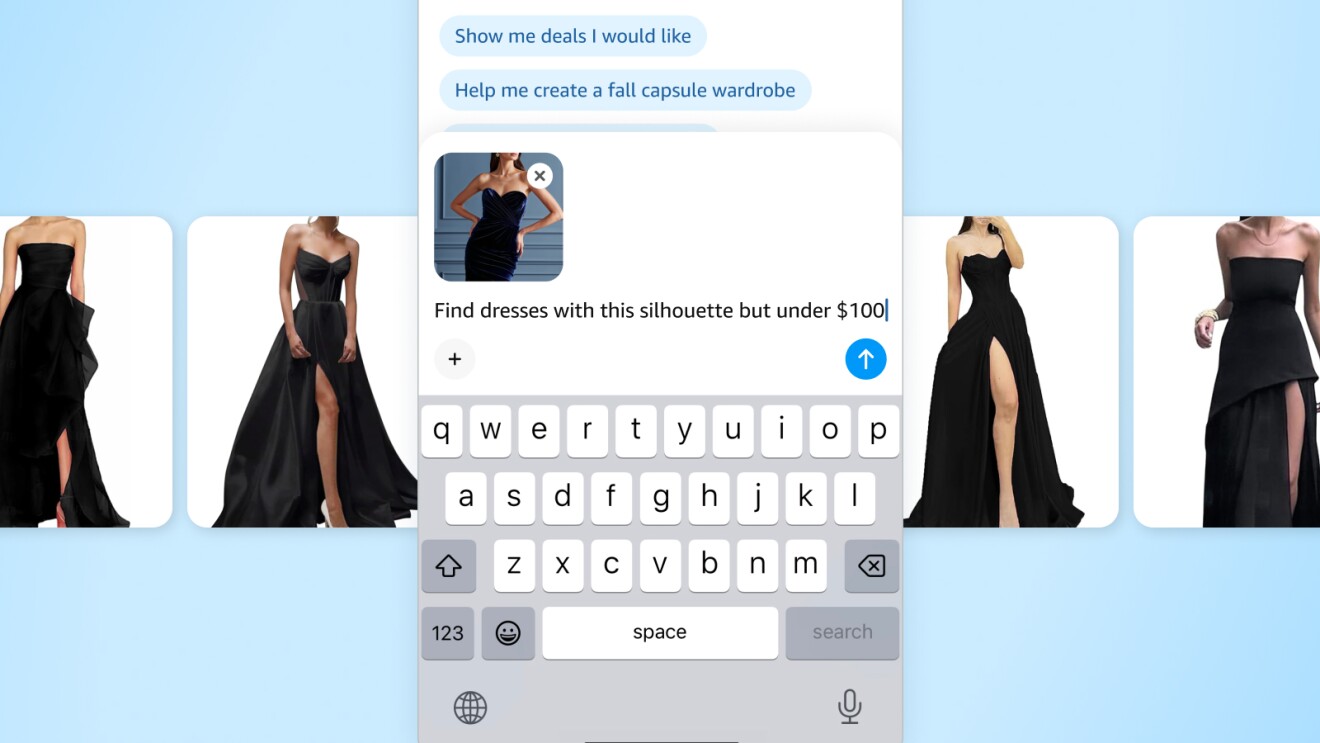
Models hosted by Amazon Bedrock also helps Rufus support a wide range of experiences across modalities, including text and images. Even within a particular modality like text-to-text, use cases can vary in complexity, traffic, and latency requirements. Some scenarios such as “planning a camping trip,” “gift recommendations for my mom,” or style advice requires deeper reasoning, multi-turn dialogue, and access to tools like web search to provide contextually rich, personalized answers. Straightforward product inquiries, such as, “what is the wattage on this drill?” can be handled efficiently by smaller, faster models.
Our strategy combines multiple models to power Rufus including Amazon Nova, and Anthropic’s Claude Sonnet, and our custom model, so we can deliver the most reliable, fast, and intuitive customer experience possible.
Integrating Amazon Bedrock with Rufus
With Amazon Bedrock, we can evaluate and select the optimal model for each query type, balancing answer quality, latency, and engagement. The benefits of using Amazon Bedrock increased our development velocity by over 6x. Using multiple models gives us the ability to break down a conversation into granular pieces. By doing so, we’re able to answer questions more effectively and we’ve seen meaningful benefits. After we know what models we plan to use, we also take a hybrid approach in providing the model proper context to perform its task effectively. In some cases, we may already have the context that Rufus needs to answer a question. For example, if we know a customer is asking a question about their previous orders, we can provide their order history to the initial inference request of the model. This optimizes the number of inference calls we need to make and also provides more determinism to help avoid downstream errors. In other cases, we can defer the decision to the model and when it believes it needs more information it can use a tool to retrieve additional context.
We found that it’s very important to ground the model with the proper information. One of the ways we do this is by using Amazon Nova Web Grounding because it can interact with web browsers to retrieve and cite authoritative internet sources, resulting in significantly reduced answer defects and improved accuracy and customer trust. In addition to optimizing model accuracy, we’ve also worked with Amazon Bedrock features to decrease latency whenever possible. By using prompt caching and parallel tool calling we decreased latency even more. These optimizations, from model response to service latency, means customers that use Rufus are 60% more likely to complete a purchase.
Agentic functionality through tool integration
More importantly, the Amazon Bedrock architecture supports agentic capabilities that makes Rufus more useful for shoppers through tool use. Using models on Bedrock, Rufus can dynamically call services as tools to provide personalized, real-time, accurate information or take actions on behalf of the user. When a customer asks Rufus about product availability, pricing, or specifications, Rufus goes far beyond its built-in knowledge. It retrieves relevant information such as your order history and uses integrated tools at inference time to query live databases, check the latest product catalog, and access real-time data. To be more personal Rufus now has account memory, understanding customers based on their individual shopping activity. Rufus can use information you may have shared previously such as hobbies you enjoy, or a previous mention of a pet, to provide a much more personalized and effective experience.
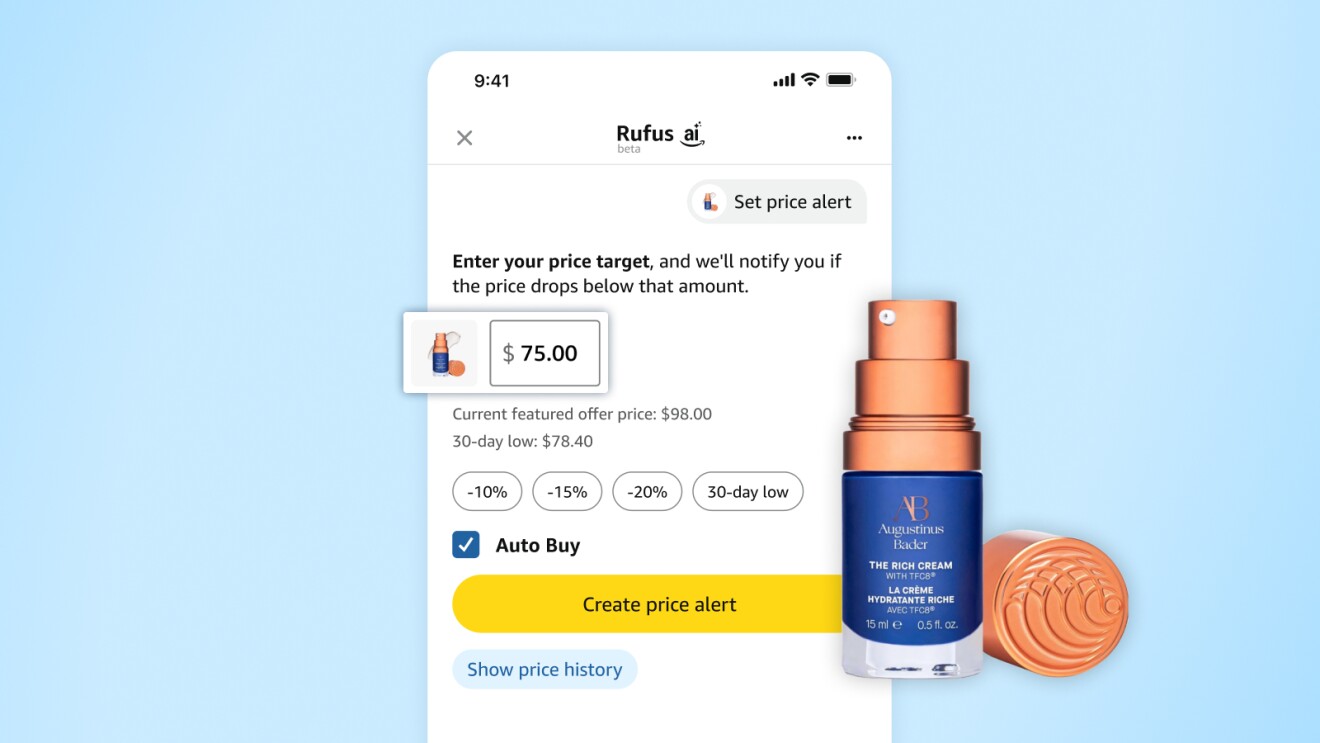
When building these agentic capabilities, it might be necessary build a service for your agent to interact with to be more effective. For example, Rufus has a Price history feature on the product detail page that lets customers instantly view historical pricing to see if they’re getting a great deal. Shoppers can ask Rufus directly for price history while browsing (for example, For example, “Has this item been on sale in the past thirty days?”) or set an agentic price alert to be notified when a product reaches a target price (“Buy these headphones when they’re 30% off”). With the auto-buy feature, Rufus can complete purchases on your behalf within 30 minutes of when the desired price is met and finalize the order using your default payment and shipping details. Auto-buy requests remain active for six months, and customers currently using this feature are saving an average of 20% per purchase. The agent itself can create a persistent record in the price alert and auto-buy service, but the system then uses traditional software to manage the record and act on it accordingly. This tight integration of models, tools, and services transforms Rufus into a truly dynamic personalized shopping agent.
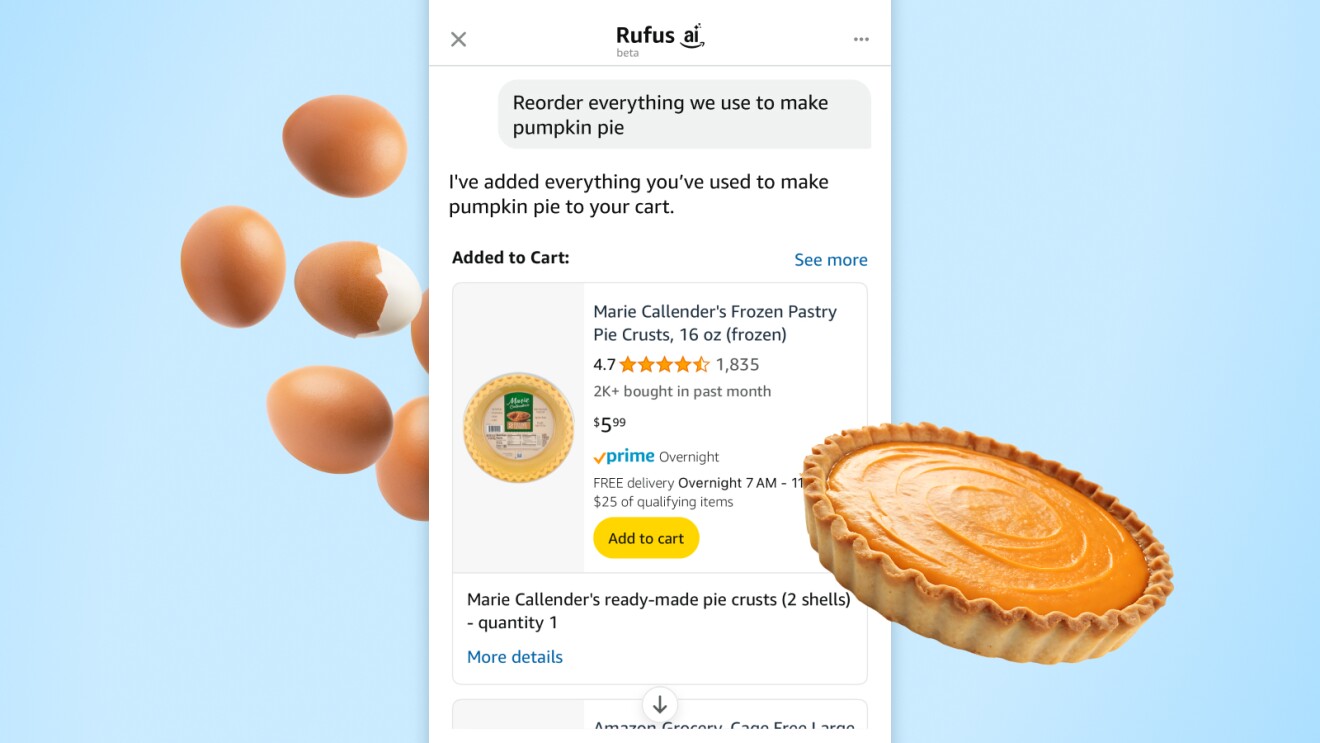
Beyond price tracking, Rufus supports natural, conversational reordering. Customers can simply say, “Reorder everything we used to make pumpkin pie last week,” or “Order the hiking boots and poles I browsed yesterday.” Rufus connects the dots between past activity and current intent and can suggest alternatives if items are unavailable. Rufus uses agentic AI capabilities to automatically add products to the cart for quick review and checkout. In these scenarios, Rufus can determine when to gather information to provide a better answer or to perform an action that’s directed by the customer. These are just two examples of the many agentic features we’ve launched.
The result: AI-powered shopping at Amazon scale
By using Amazon Bedrock, Rufus demonstrates how organizations can build sophisticated AI applications that scale to serve millions of users. The combination of flexible model selection, managed infrastructure, and agentic capabilities enables Amazon to deliver a shopping assistant that’s both intelligent and practical while maintaining tight controls on accuracy, latency, and cost. If you are considering your own AI initiatives, Rufus showcases Bedrock’s potential to simplify the journey from AI experimentation to production deployment, allowing you to focus on customer value rather than infrastructure complexity. We encourage you to try Bedrock and observe the same benefits we have and focusing on your agentic solutions and their core capabilities.
About the authors
 James Park is a ML Specialist Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In his spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends.
James Park is a ML Specialist Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In his spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends.
 Shrikar Katti is a Principal TPM at Amazon. His current focus is on driving end-to-end delivery, strategy, and cross-org alignment for a large-scale AI products that transforms the Amazon shopping experience, while ensuring safety, scalability, and operational excellence. In his spare time, he enjoys playing chess, and exploring the latest advancements in AI.
Shrikar Katti is a Principal TPM at Amazon. His current focus is on driving end-to-end delivery, strategy, and cross-org alignment for a large-scale AI products that transforms the Amazon shopping experience, while ensuring safety, scalability, and operational excellence. In his spare time, he enjoys playing chess, and exploring the latest advancements in AI.
 Gaurang Sinkar is a Principal Engineer at Amazon. His recent focus is on scaling, performance engineering and optimizing generative ai solutions. Beyond work, he enjoys spending time with family, traveling, occasional hiking and playing cricket.
Gaurang Sinkar is a Principal Engineer at Amazon. His recent focus is on scaling, performance engineering and optimizing generative ai solutions. Beyond work, he enjoys spending time with family, traveling, occasional hiking and playing cricket.
 Sean Foo is an engineer at Amazon. His recent focus is building low latency customer experiences and maintaining a highly available systems at Amazon scale. In his spare time, he enjoys playing video and board games with friends and wandering around.
Sean Foo is an engineer at Amazon. His recent focus is building low latency customer experiences and maintaining a highly available systems at Amazon scale. In his spare time, he enjoys playing video and board games with friends and wandering around.
 Saurabh Trikande is a Senior Product Manager for Amazon Bedrock and Amazon SageMaker Inference. He is passionate about working with customers and partners, motivated by the goal of democratizing AI. He focuses on core challenges related to deploying complex AI applications, inference with multi-tenant models, cost optimizations, and making the deployment of generative AI models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
Saurabh Trikande is a Senior Product Manager for Amazon Bedrock and Amazon SageMaker Inference. He is passionate about working with customers and partners, motivated by the goal of democratizing AI. He focuses on core challenges related to deploying complex AI applications, inference with multi-tenant models, cost optimizations, and making the deployment of generative AI models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
 Somu Perianayagam is an Engineer at AWS specializing in distributed systems for Amazon DynamoDB and Amazon Bedrock. He builds large-scale, resilient architectures that help customers achieve consistent performance across regions, simplify their data paths, and operate reliably at massive scale.
Somu Perianayagam is an Engineer at AWS specializing in distributed systems for Amazon DynamoDB and Amazon Bedrock. He builds large-scale, resilient architectures that help customers achieve consistent performance across regions, simplify their data paths, and operate reliably at massive scale.