Artificial Intelligence
Introducing Disaggregated Inference on AWS powered by llm-d
We thank Greg Pereira and Robert Shaw from Red Hat for their support in bringing llm-d to AWS.
In the agentic and reasoning era, large language models (LLMs) generate 10x more tokens and compute through complex reasoning chains compared to single-shot replies. Agentic AI workflows also create highly variable demands and another exponential increase in processing, bogging down the inference process and degrading the user experience. As the world transitions from prototyping AI solutions to deploying AI at scale, efficient inference is becoming the gating factor.
LLM inference consists of two distinct phases: prefill and decode. The prefill phase is compute bound. It processes the entire input prompt in parallel to generate the initial set of key-value (KV) cache entries. The decode phase is memory bound. It autoregressively generates one token at a time while requiring substantial memory bandwidth to access model weights and the ever-growing KV cache. Adding to this complexity, inference requests vary widely in computational requirements based on input and output length, making efficient resource utilization particularly challenging.
Traditional approaches often involve deploying models on predetermined infrastructure and topology or using basic distributed strategies that don’t account for these unique phases of LLM inference. This leads to suboptimal resource utilization, with GPUs either underutilized or overloaded during different inference phases. While vLLM has emerged as a popular open source inference engine that improves efficiency through nearly continuous batching and PagedAttention, organizations deploying at scale still face challenges in orchestrating deployments and optimizing routing decisions across multiple nodes.
We are announcing a joint effort with the llm-d team to bring powerful disaggregated inference capabilities to AWS so that customers can boost performance, maximize GPU utilization, and improve costs for serving large-scale inference workloads. This launch is the result of several months of close collaboration with the llm-d community to deliver a new container ghcr.io/llm-d/llm-d-aws that includes libraries that are specific to AWS, such as Elastic Fabric Adapter (EFA) and libfabric, along with integration of llm-d with the NIXL library to support critical features such as multi-node disaggregated inference and expert parallelism. We have also conducted extensive benchmarking through multiple iterations to arrive at a stable release that allows customers to access these powerful capabilities out of the box on AWS Kubernetes systems such as Amazon SageMaker HyperPod and Amazon Elastic Kubernetes Service (Amazon EKS).
Throughout this blog post, we introduce the concepts behind next-generation inference capabilities, including disaggregated serving, intelligent request scheduling, and expert parallelism. We discuss their benefits and walk through how you can implement them on Amazon SageMaker HyperPod EKS to achieve significant improvements in inference performance, resource utilization, and operational efficiency.
What is llm-d?
llm-d is an open source, Kubernetes-native framework for distributed large language model (LLM) serving. Built on top of vLLM, llm-d extends the core inference engine with production-grade orchestration, advanced scheduling, and high-performance interconnect support to enable scalable, multi-node model serving.
Rather than treating inference as a single-node execution problem, llm-d introduces architectural patterns for disaggregated serving—separating and improving stages such as prefill, decode, and KV-cache management across distributed GPU resources. This allows operators to efficiently use high-speed fabrics such as AWS Elastic Fabric Adapter (EFA), while maintaining compatibility with Kubernetes-native deployment workflows.
To make these capabilities accessible, llm-d provides a set of well-lit paths—reference serving architectures that package proven optimization strategies for different performance, scalability, and workload goals:
Intelligent inference scheduling
While the intelligent scheduling example makes routing decisions based on other factors, such as queue depth, its unique approach to routing is that it attempts to guess the locality of requests in the KVcache, without requiring it to have visibility into the state of the KVCache. In a single-instance environment, engines like vLLM use Automatic Prefix Caching to reduce redundant computation by reusing prior KV cache entries, driving faster and more efficient performance. However, the moment you scale to a distributed, multi-replica environment, assumptions about which kvblocks exist on which GPUs can’t hold. Without awareness of the locality of requests in their intermediary states, requests might be routed to instances that lack relevant cached context, negating the benefits of prefix caching entirely.
The llm-d scheduler addresses this by maintaining visibility into the cache state across the serving replicas and routing requests accordingly. For workloads with high prefix reuse, such as multi-turn conversations or agentic workflows, this cache-aware routing can lead to significant improvements in throughput and latency by making sure that requests are directed to servers that already hold relevant KV cache entries.
Prefill and Decode disaggregation
As described earlier, the prefill and decode phases of LLM inference have fundamentally different resource profiles, with prefill being compute-intensive and decode being memory-bandwidth-intensive. In a traditional deployment, both phases share the same hardware, meaning neither can be independently optimized. Separating these two phases unlocks several optimization opportunities. For example, if your output context length is higher than your input length, you can assign more GPUs to decode than prefill. You can also place these two phases on different types of hardware, each tuned for its respective workload characteristics.
In llm-d, prefill servers are optimized for processing input prompts efficiently, while decode servers are focused on generating output tokens with low latency. The intelligent scheduler decides which instances should receive a given request, and the transfer is coordinated using a sidecar running alongside decode instances. The sidecar instructs vLLM to perform point-to-point KV cache transfers over fast interconnects to make sure that the decode server receives the necessary cached context from the prefill server with minimal overhead. This disaggregation significantly improves both time to first token (TTFT) and overall throughput, particularly for workloads with long prompts or when processing large models.
Wide expert parallelism
For Mixture-of-Experts (MoE) models such as DeepSeek-R1, Qwen3.5, Minimax, and Kimi K2.5, llm-d provides optimized deployment patterns that use data parallelism and expert parallelism. This approach enables efficient deployment of large MoE models by distributing experts horizontally across multiple nodes while maintaining performance. By spreading model experts across accelerators and using improved communication patterns, llm-d can significantly reduce end-to-end latency and increase throughput for these complex architectures. However, scaling MoE models introduces more complex parallelism, communication, and scheduling requirements that must be carefully tuned for each deployment scenario.
Tiered prefix caching
Prefix caching avoids performing repetitive and expensive KV cache computations, improving metrics such as TTFT and overall throughput. While inference engines like vLLM have native prefix caching built in, they’re constrained by the amount of GPU memory available on a given instance. To expand the effective size of the KV cache beyond GPU memory limits, llm-d offers a tiered caching path that offloads KV cache entries from GPU memory to other storage tiers such as CPU memory or local disk.
These well-lit paths are offered as starting points for configuration and deployment of model servers. They’re designed as composable building blocks for vLLM deployments and inference scheduler configuration, meaning features across multiple paths can be combined and configured together to suit specific workload requirements.
Running llm-d on AWS
Amazon SageMaker HyperPod EKS
Amazon SageMaker HyperPod offers resilient, high-performance Kubernetes infrastructure optimized for large-scale model training and inference. It provides persistent, high-performance clusters that address many of the infrastructure challenges organizations face when deploying large models. Health monitoring is built into the system, with proactive detection and remediation of hardware failures to maintain high availability for production workloads. Native Kubernetes support simplifies container orchestration, making it an ideal foundation for llm-d’s Kubernetes-native architecture.
Reference Architecture
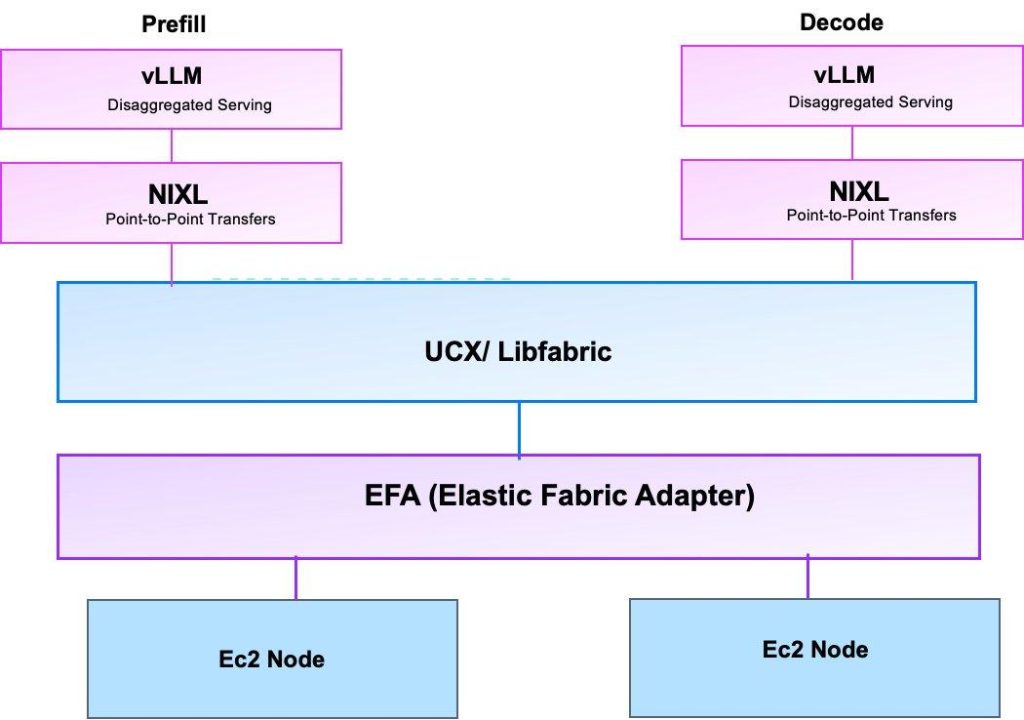
To understand how llm-d operates efficiently on AWS infrastructure, it is important to understand the communication layers that enable high-performance distributed inference. For GPU to GPU communication on a single node, NVLink and NVSwitch are used for high-bandwidth transfers between prefill and decode workers. The following sections describe the key components and how they work together.
NIXL for Point-to-Point Inference Transfers
NCCL, which is widely used in LLM training excels at collective communication patterns, disaggregated inference architectures require efficient point-to-point data transfers, for example, moving KV cache data from a prefill node to a decode node. NVIDIA Inference Xfer Library (NIXL) is purpose-built for this scenario. NIXL provides a memory abstraction layer that spans CPU memory, GPU memory, and storage backends including file, block, and object stores such as Amazon S3. It functions as an abstraction layer over different transfer methods, including libfabric for EFA interfaces, UCCL, and GPUDirect Storage.
Through NIXL, instances transfer KV cache data between prefill and decode servers using RDMA. RDMA allows GPUs to bypass the operating system and read peer device memory directly, which is critical for inference workloads where TTFT is a key performance metric. In the llm-d architecture, vLLM servers are deployed in InferencePools for routing, and prefill/decode disaggregation is configured using NIXL as the connector for KV cache sharing. NIXL leverages the EFA interfaces connected to instances for high-bandwidth communication, making sure that the overhead of transferring cached context between disaggregated phases remains minimal.
NIXL Libfabric plugin and the Transport Layer
NIXL libfabric plugin provides a high-performance RDMA backend for NIXL using the OpenFabrics Interfaces (OFI) Libfabric library. Libfabric supports RDMA operations that enable zero-copy, GPU-Direct, kernel-bypass networking, which is critical for minimizing latency and maximizing bandwidth in distributed workloads. Importantly, NIXL has native support for AWS Elastic Fabric Adapter (EFA) through the libfabric plugin, providing the high- performance plumbing that NIXL relies on when GPUs need to communicate across nodes.
Elastic Fabric Adapter (EFA)
EFA provides high performance networking interface on AWS, which is essential for scaling distributed inference across multiple nodes. EFA uses libfabric as its userspace interface, and NIXL Libfabric plugin includes a libfabric transport layer that can leverage EFA directly. This integration means that when llm-d deploys vLLM across multiple nodes, the underlying communication stack can take full advantage of EFA’s low-latency, high-bandwidth networking without requiring changes at the application level.
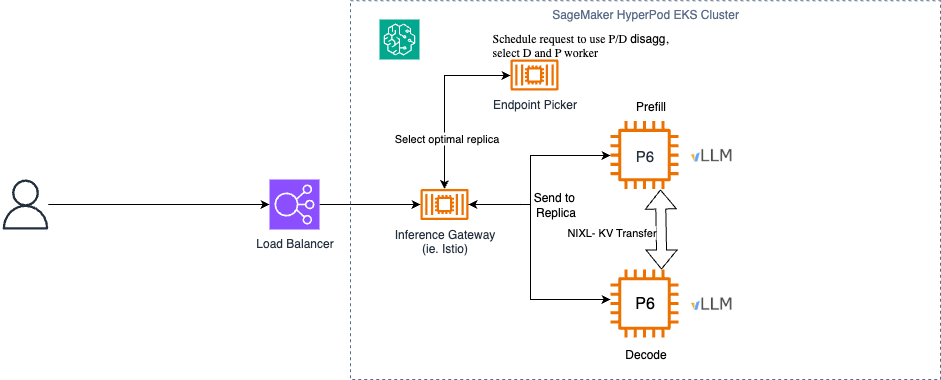
We can configure the AWS Load Balancer Controller to provision load balancers for connecting to the Inference Gateway. The Inference Gateway (IGW) sits in front of vLLM instances, providing intelligent request scheduling and routing based on various factors including cache locality and server load. The KV Cache Manager enables cache-aware routing and distributed cache management, tracking which KV cache blocks reside on which nodes. These components work together to create a flexible, extensible system for LLM inference that addresses the unique challenges of serving large models at scale.
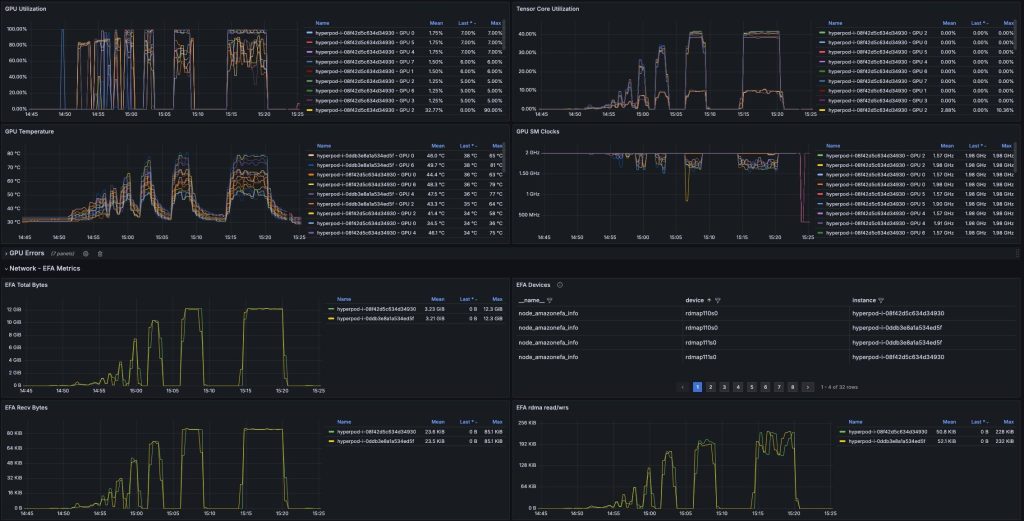
With SageMaker HyperPod’s observability dashboards, you can monitor key metrics during inference time such as GPU utilization, EFA metrics and error counts for proactively monitoring and optimizing your inference workloads.
Best Practices
Disaggregated inference allows you to scale your prefill nodes separately to your decode nodes, allowing you to tune your performance for your workloads. For example, larger input sequence lengths with short output sequence lengths are a prefill-heavy workload. Disaggregated inference allows you to scale your prefill pods to handle more requests efficiently without an increase in cost. It is not for all workloads however. You can try it with larger models, longer input sequences, and sparse MoE architectures.
llm-d also provides paths for intelligently routing traffic to specific pods based on metrics such as request queues and KV cache events via the inference gateway. This works to improve performance and KV cache hits for LLM inference workloads for improving throughput. The project is still developing and adding more paths and improvements for hosting LLM workloads.
Deployment Overview
Prerequisites
Before we proceed with deploying either pattern, you need the following components set up locally on your device:
- AWS Command Line Interface (AWS CLI)
- kubectl
- HuggingFace account for creating an access token
- Helm
- helmfile
- Access to a SageMaker HyperPod or EKS cluster
llm-d Setup
llm-d uses the Gateway Inference API Extension, which requires the installation of the CRDs and an implementation such as Istio. Clone the llm-d repository and navigate to the installation helper:
Install the provider and implementation
Once they are installed, you can start deploying the guides.
Model Deployment
The llm-d repository provides a number of well-lit paths for inference on Kubernetes located on their GitHub. Each guide is configured using a helmfile and is split under two folders. One for the Gateway AI Extension, which configures the Kubernetes Gateway and one for the model service, which configures the model hosting configuration.
Docker image with AWS libraries :ghcr.io/llm-d/llm-d-aws:v0.5.1
To expose a Gateway with an AWS Load Balancer, you can configure the required Type and Annotations under ./guides/prereq/gateway-provider/common-configurations.
For example, we configured ./guides/prereq/gateway-provider/common-configurations/istio.yaml as
When the Istio Gateway is created, it will provision a network load balancer in your VPC for use. From here, you can configure the example as per the instructions in the README file to deploy the stack. To get started running the inference-scheduling example, from the llm-d directory run:
Here you will see the structure appearing like:
The ms-inference-scheduling folder contains the configuration values for running vLLM replicas on your nodes. gaie-inference-scheduling will configure the inference gateway using your selected provider from previously.
Once you are ready to deploy, run helmfile apply to deploy the guide on your cluster.
Deploying with Prefill-Decode Disaggregation
The guide to deploy with prefill/decode disaggregation is located in guides/pd-disaggregation. For running within an environment such as a SageMaker HyperPod cluster, you must configure the replicas to run using an EFA-enabled image and make sure to allocate EFA interfaces to the pods.
Within the ms-pd/values.yaml, you configure it similar to:
The image need to use llm-d’s AWS-compatible container. vLLM is configured where NIXL will use the libfabric backend to maximise network bandwidth. For configuring the number of EFA interfaces, you should allocate based on the number of GPUs each Pod is running with and the number of EFA interfaces available on the instance. For example, a p5.48xlarge instance has 8 H100 GPUs with 32 Elastic Fabric Adapter interfaces, so you should configure each replica to have 4 EFA interfaces per GPU.
Optionally, you can also configure "enable_cross_layers_blocks": "True" for the kv_connector_extra_config for reducing the amount of data that vLLM will transfer.
Running Inference
Once deployed, EKS will have created an AWS Network Load Balancer for deployment. To get the Load Balancer DNS name, run kubectl get gateways. You can then invoke this with curl:
Disaggregated Inference
Benchmarking
We deployed OpenAI’s GPT-OSS on vLLM with a tensor parallel degree of 4 on an ml.p6-b200.48xlarge. We compared it against llm-d’s path for prefill/decode disaggregation with 4 prefill pods each with a tensor parallel degree of 1 and 1 decode pods with a tensor parallel degree of 4. The pods were connected using NIXL with Libfabric as the underlying transport backend for using Elastic Fabric Adapter networking on the instances.
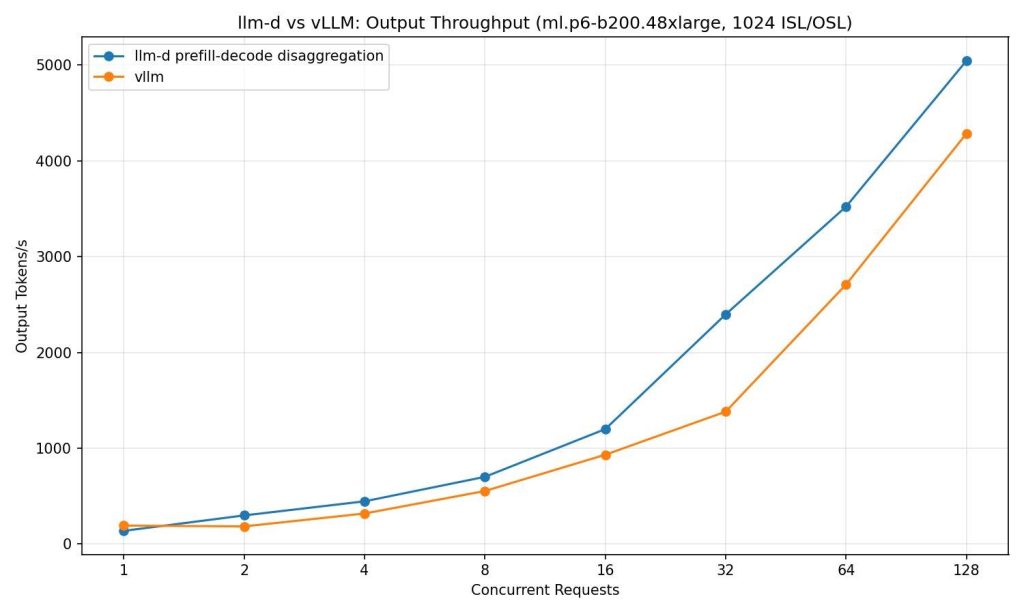
In our testing, we found that using llm-d’s prefill/decode disaggregation path increases tokens per second by up to 70% as concurrency increases compared to using a standard vLLM deployment when load testing with an input sequence of 1024 input tokens and receiving 1024 output tokens up to a concurrency of 128. This performance profile varies based on your vLLM configuration and workload. Tuning your prefill/decode ratio and other parameters available from vLLM server can potentially bring more performance.
Conclusion
llm-d provides paths for deployment methods such as prefill/decode disaggregation, precise KV aware routing and tiered KVcaching. These provide further methods to improve performance for hosting at scale. You can tune the vLLM settings as required to improve metrics such as TTFT, ITL, or cache hits. You can also use frameworks such as LMCache for KV offloading. Checkout llm-d at https://llm-d.ai/docs/architecture