Artificial Intelligence
NVIDIA Nemotron 3 Ultra now available on Amazon SageMaker JumpStart
Today, we are excited to announce the day-zero availability of NVIDIA Nemotron 3 Ultra on Amazon SageMaker JumpStart.
With this launch, you can now deploy the Nemotron 3 Ultra model using a one-click deployment experience. Nemotron 3 Ultra is an open model built for frontier reasoning and orchestration in long-running autonomous agents, delivering 5x faster inference and up to 30% lower cost for agentic workloads. Nemotron 3 Ultra is optimized for the NVFP4 format, which makes the model much faster and cost effective to host.
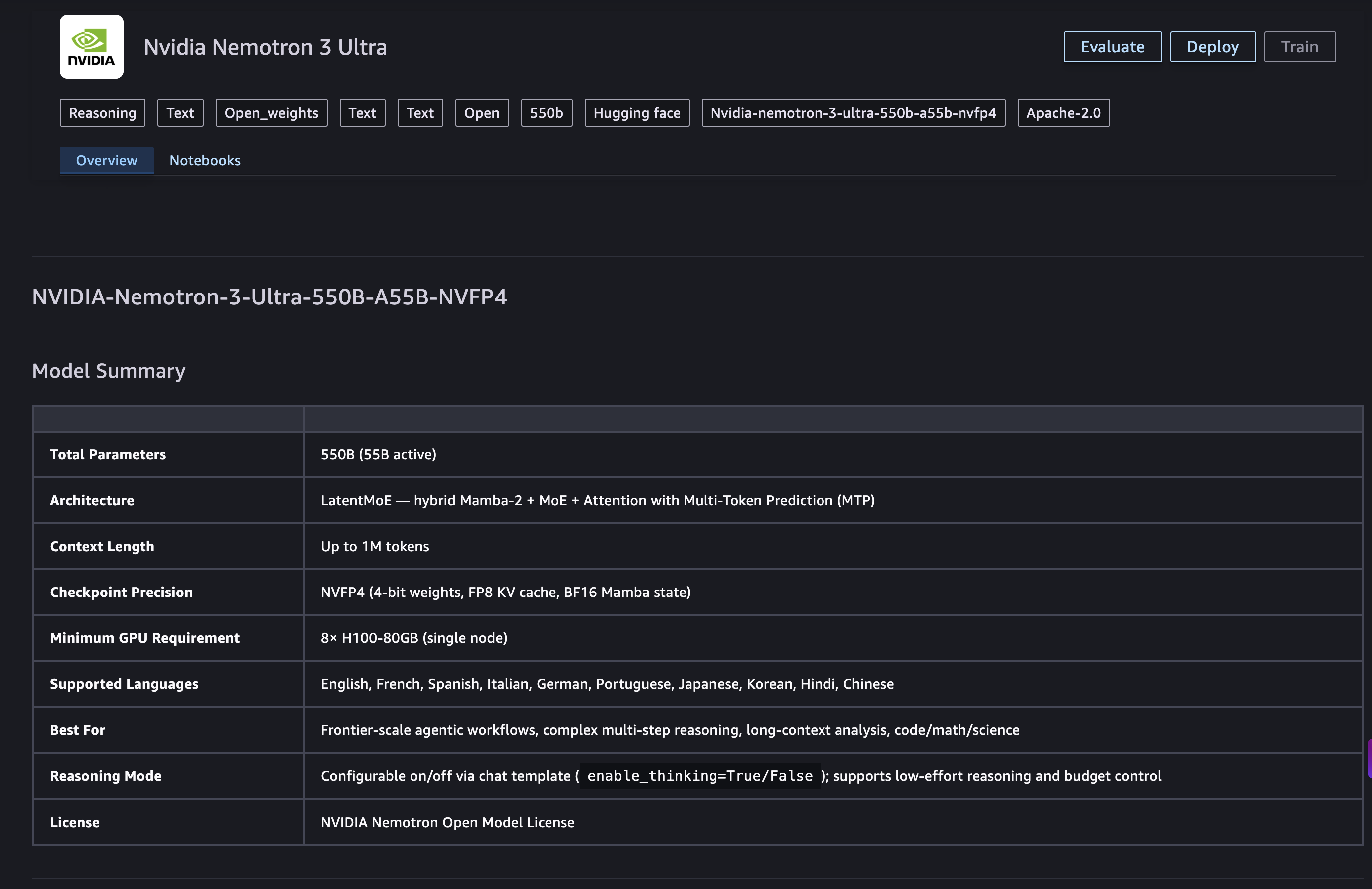
Overview of NVIDIA Nemotron 3 Ultra
NVIDIA Nemotron 3 Ultra is an open large language model with 550 billion total parameters and 55 billion active parameters. It is built on a hybrid Transformer-Mamba Mixture-of-Experts (MoE) architecture, designed to deliver frontier intelligence at a fraction of the compute cost of dense models of equivalent quality.
| Specification | Details |
|---|---|
| Architecture | Hybrid Transformer-Mamba MoE |
| Parameters | 550B total / 55B active |
| Context length | Up to 1M tokens |
| Input / Output | Text in, text out |
| Precision | NVFP4 |
| Inference speed | 5x faster for long-running agent workflows |
| Cost | Up to 30% lower for complex agentic tasks |
Why agentic AI needs purpose-built models
Agents don’t just answer once. They plan, call tools, delegate work to sub-agents, check results, and keep going across hundreds of turns. Every step adds tokens and compute, so the metrics that matter are task completion at useful accuracy, time-to-finish, and cost-per-task.
Nemotron 3 Ultra addresses this directly. Its MoE architecture activates only 55B of its 550B parameters per forward pass, keeping throughput high even at million-token context lengths. This means agents can sustain planning, tool calling, and self-correction loops that span hundreds of turns while helping maintain coherence and manage cost.
Enterprise use cases
Nemotron 3 Ultra excels in workloads that require sustained multi-step reasoning:
- Agent orchestrators – coordinate multiple sub-agents, manage state across long tool-calling chains
- Coding agents – generate, test, debug, and iterate on code across large repositories
- Deep research – synthesize information from multiple sources, maintain coherent reasoning over extended context
- Complex enterprise workflows – automate multi-step business processes with decision branching and error recovery
Getting started with SageMaker JumpStart
You can deploy Nemotron 3 Ultra through Amazon SageMaker JumpStart with one-click deployment, removing the need to manage infrastructure or configure serving frameworks.
Prerequisites
Before you begin, make sure you have:
- An AWS account
- Appropriately scoped permissions for SageMaker JumpStart
- Sufficient service quota for GPU instances (for example, ml.p5en.48xlarge, ml.p5.48xlarge, or ml.g7e.48xlarge)
Important: Deploying this model creates a SageMaker endpoint that incurs charges while running. GPU instances like ml.p5en.48xlarge can cost several dollars per hour. See Amazon SageMaker AI pricing for details. Remember to delete your endpoint when finished to avoid ongoing charges.
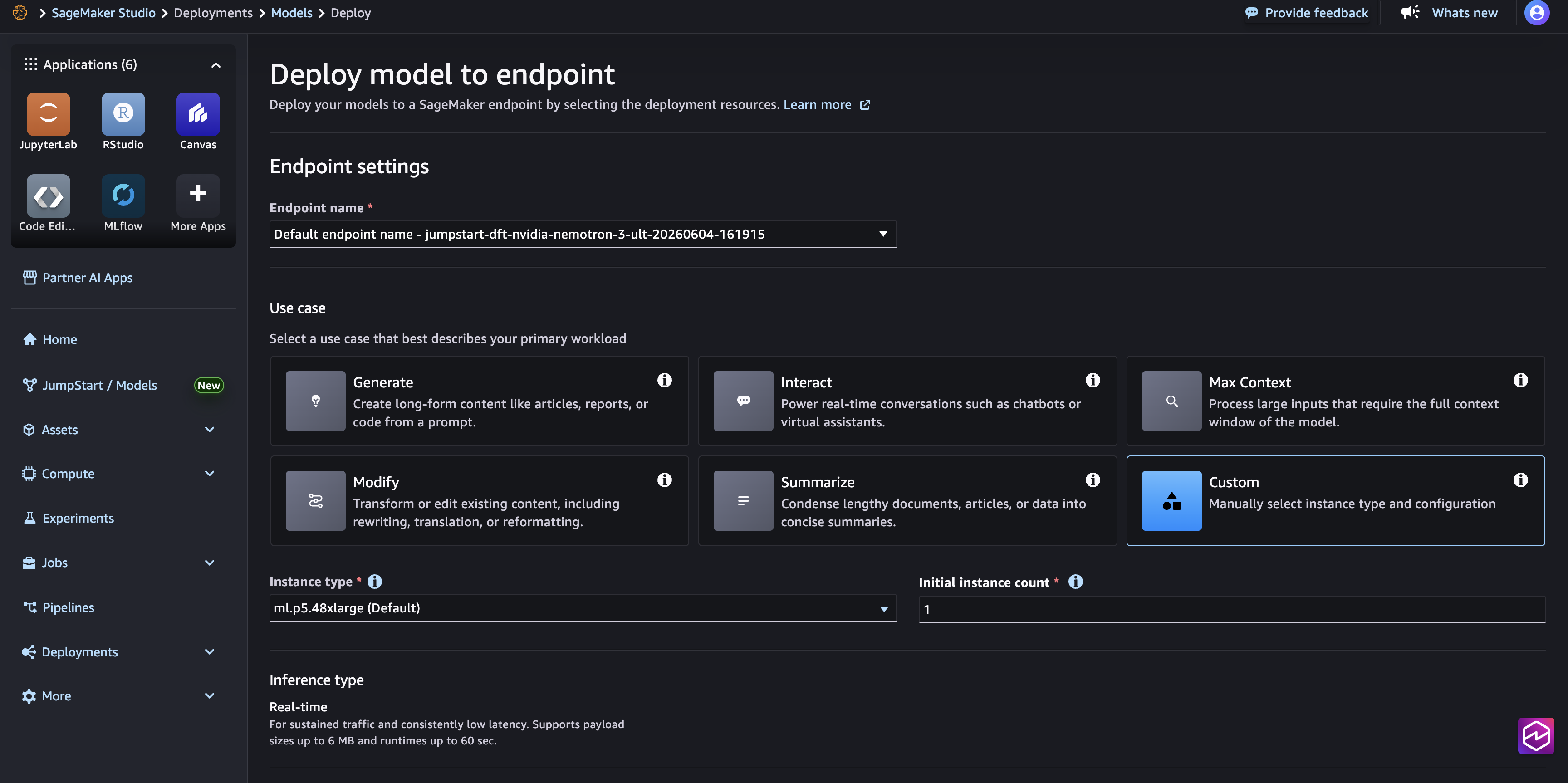
Deploy using SageMaker Studio
- Open Amazon SageMaker Studio
- In the left navigation pane, choose SageMaker JumpStart
- Search for Nemotron 3 Ultra
- Select the model card
- Choose Deploy
- Select your instance type (supported instance types are ml.p5en.48xlarge, ml.p5.48xlarge, or ml.g7e.48xlarge)
- Review deployment settings (defaults are sufficient for most use cases)
- Choose Deploy to create the endpoint
- Wait for the endpoint status to show InService before proceeding to inference
Deploy using the SageMaker Python SDK
Run inference
Clean up
To avoid incurring unnecessary charges, delete the SageMaker endpoint when you are done:predictor.delete_endpoint()
Conclusion
NVIDIA Nemotron 3 Ultra brings frontier-class reasoning to Amazon SageMaker JumpStart with 5x faster inference and up to 30% lower cost for agentic workloads. Its hybrid Transformer-Mamba MoE architecture and million-token context window make it purpose-built for the sustained, multi-step reasoning that production agents demand.
Whether you are building agent orchestrators, coding agents, deep research systems, or complex enterprise automation, Nemotron 3 Ultra is ready to deploy today from SageMaker JumpStart.
Get started now by searching for Nemotron 3 Ultra in Amazon SageMaker JumpStart.
About the authors
 Dan Ferguson is a Solutions Architect at AWS, based in New York, USA. As a machine learning services expert, Dan works to support customers on their journey to integrating ML workflows efficiently, effectively, and sustainably.
Dan Ferguson is a Solutions Architect at AWS, based in New York, USA. As a machine learning services expert, Dan works to support customers on their journey to integrating ML workflows efficiently, effectively, and sustainably.
 Malav Shastri is a Software Development Engineer at AWS, where he works on the Amazon SageMaker JumpStart and Amazon Bedrock teams. His role focuses on enabling customers to take advantage of state-of-the-art open source and proprietary foundation models. Malav holds a Master’s degree in Computer Science.
Malav Shastri is a Software Development Engineer at AWS, where he works on the Amazon SageMaker JumpStart and Amazon Bedrock teams. His role focuses on enabling customers to take advantage of state-of-the-art open source and proprietary foundation models. Malav holds a Master’s degree in Computer Science.
 Vivek Gangasani is a Worldwide Leader for Solutions Architecture, SageMaker Inference. He leads Solution Architecture, Technical Go-to-Market (GTM) and Outbound Product strategy for SageMaker Inference. He also helps enterprises and startups deploy and optimize a GenAI models and build AI workflows with SageMaker and GPUs. Currently, he is focused on developing strategies and content for optimizing inference performance and use-cases such as Agentic workflows, RAG etc. In his free time, Vivek enjoys hiking, watching movies, and trying different cuisines.
Vivek Gangasani is a Worldwide Leader for Solutions Architecture, SageMaker Inference. He leads Solution Architecture, Technical Go-to-Market (GTM) and Outbound Product strategy for SageMaker Inference. He also helps enterprises and startups deploy and optimize a GenAI models and build AI workflows with SageMaker and GPUs. Currently, he is focused on developing strategies and content for optimizing inference performance and use-cases such as Agentic workflows, RAG etc. In his free time, Vivek enjoys hiking, watching movies, and trying different cuisines.