Artificial Intelligence
Specify and extract information from documents using the new Queries feature in Amazon Textract
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from any document or image. Amazon Textract now offers the flexibility to specify the data you need to extract from documents using the new Queries feature within the Analyze Document API. You don’t need to know the structure of the data in the document (table, form, implied field, nested data) or worry about variations across document versions and formats.
In this post, we discuss the following topics:
- Success stories from AWS customers and benefits of the new Queries feature
- How the Analyze Document Queries API helps extract information from documents
- A walkthrough of the Amazon Textract console
- Code examples to utilize the Analyze Document Queries API
- How to process the response with the Amazon Textract parser library
Benefits of the new Queries feature
Traditional OCR solutions struggle to extract data accurately from most semi-structured and unstructured documents because of significant variations in how the data is laid out across multiple versions and formats of these documents. You need to implement custom postprocessing code or manually review the extracted information from these documents. With the Queries feature, you can specify the information you need in the form of natural language questions (for example, “What is the customer name”) and receive the exact information (“John Doe”) as part of the API response. The feature uses a combination of visual, spatial, and language models to extract the information you seek with high accuracy. The Queries feature is pre-trained on a large variety of semi-structured and unstructured documents. Some examples include paystubs, bank statements, W-2s, loan application forms, mortgage notes, and vaccine and insurance cards.
“Amazon Textract enables us to automate the document processing needs of our customers. With the Queries feature, we will be able to extract data from a variety of documents with even greater flexibility and accuracy,” said Robert Jansen, Chief Executive Officer at TekStream Solutions. “We see this as a big productivity win for our business customers, who will be able to use the Queries capability as part of our IDP solution to quickly get key information out of their documents.”
“Amazon Textract enables us to extract text as well as structured elements like Forms and Tables from images with high accuracy. Amazon Textract Queries has helped us drastically improve the quality of information extraction from several business-critical documents such as safety data sheets or material specifications” said Thorsten Warnecke, Principal | Head of PC Analytics, Camelot Management Consultants. “The natural language query system offers great flexibility and accuracy which has reduced our post-processing load and enabled us to add new documents to our data extraction tools quicker.”
How the Analyze Document Queries API helps extract information from documents
Companies have increased their adoption of digital platforms, especially in light of the COVID-19 pandemic. Most organizations now offer a digital way to acquire their services and products utilizing smartphones and other mobile devices, which offers flexibility to users but also adds to the scale at which digital documents need to be reviewed, processed, and analyzed. In some workloads where, for example, mortgage documents, vaccination cards, paystubs, insurance cards, and other documents must be digitally analyzed, the complexity of data extraction can become exponentially aggravated because these documents lack a standard format or have significant variations in data format across different versions of the document.
Even powerful OCR solutions struggle to extract data accurately from these documents, and you may have to implement custom postprocessing for these documents. This includes mapping possible variations of form keys to customer-native field names or including custom machine learning to identify specific information in an unstructured document.
The new Analyze Document Queries API in Amazon Textract can take natural language written questions such as “What is the interest rate?” and perform powerful AI and ML analysis on the document to figure out the desired information and extract it from the document without any postprocessing. The Queries feature doesn’t require any custom model training or setting up of templates or configurations. You can quickly get started by uploading your documents and specifying questions on those documents via the Amazon Textract console, the AWS Command Line Interface (AWS CLI), or AWS SDK.
In subsequent sections of this post, we go through detailed examples of how to use this new functionality on common workload use cases and how to use the Analyze Document Queries API to add agility to the process of digitalizing your workload.
Use the Queries feature on the Amazon Textract console
Before we get started with the API and code samples, let’s review the Amazon Textract console. The following image shows an example of a vaccination card on the Queries tab for the Analyze Document API on the Amazon Textract console. After you upload the document to the Amazon Textract console, choose Queries in the Configure Document section. You can then add queries in the form of natural language questions. After you add all your queries, choose Apply Configuration. The answers to the questions are located on the Queries tab.

Code examples
In this section, we explain how to invoke the Analyze Document API with the Queries parameter to get answers to natural language questions about the document. The input document is either in a byte array format or located in an Amazon Simple Storage Service (Amazon S3) bucket. You pass image bytes to an Amazon Textract API operation by using the Bytes property. For example, you can use the Bytes property to pass a document loaded from a local file system. Image bytes passed by using the Bytes property must be base64 encoded. Your code might not need to encode document file bytes if you’re using an AWS SDK to call Amazon Textract API operations. Alternatively, you can pass images stored in an S3 bucket to an Amazon Textract API operation by using the S3Object property. Documents stored in an S3 bucket don’t need to be base64 encoded.
You can use the Queries feature to get answers from different types of documents like paystubs, vaccination cards, mortgage documents, bank statements, W-2 forms, 1099 forms, and others. In the following sections, we go over some of these documents and show how the Queries feature works.
Paystub
In this example, we walk through the steps to analyze a paystub using the Queries feature, as shown in the following example image.

We use the following sample Python code:
The following code is a sample AWS CLI command:
Let’s analyze the response we get for the two queries we passed to the Analyze Document API in the preceding example. The following response has been trimmed to only show the relevant parts:
The response has a BlockType of QUERY that shows the question that was asked and a Relationships section that has the ID for the block that has the answer. The answer is in the BlockType of QUERY_RESULT. The alias that is passed in as an input to the Analyze Document API is returned as part of the response and can be used to label the answer.
We use the Amazon Textract Response Parser to extract just the questions, the alias, and the corresponding answers to those questions:
The preceding code returns the following results:
More questions and the full code can be found in the notebook on the GitHub repo.
Mortgage note
The Analyze Document Queries API also works well with mortgage notes like the following.

The process to call the API and process results is the same as the previous example. You can find the full code example on the GitHub repo.
The following code shows the example responses obtained using the API:
Vaccination card
The Amazon Textract Queries feature also works very well to extract information from vaccination cards or cards that resemble it, like in the following example.

The process to call the API and parse the results is the same as used for a paystub. After we process the response, we get the following information:
The full code can be found in the notebook on the GitHub repo.
Insurance card
The Queries feature also works well with insurance cards like the following.
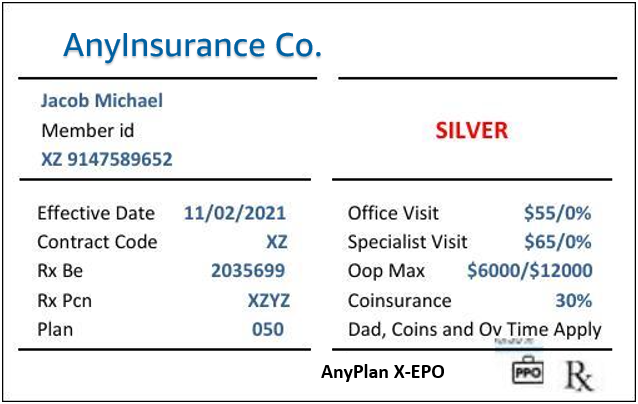
The process to call the API and process results is the same as showed earlier. The full code example is available in the notebook on the GitHub repo.
The following are the example responses obtained using the API:
Best practices for crafting queries
When crafting your queries, consider the following best practices:
- In general, ask a natural language question that starts with “What is,” “Where is,” or “Who is.” The exception is when you’re trying to extract standard key-value pairs, in which case you can pass the key name as a query.
- Avoid ill-formed or grammatically incorrect questions, because these could result in unexpected answers. For example, an ill-formed query is “When?” whereas a well-formed query is “When was the first vaccine dose administered?”
- Where possible, use words from the document to construct the query. Although the Queries feature tries to do acronym and synonym matching for some common industry terms such as “SSN,” “tax ID,” and “Social Security number,” using language directly from the document improves results. For example, if the document says “job progress,” try to avoid using variations like “project progress,” “program progress,” or “job status.”
- Construct a query that contains words from both the row header and column header. For example, in the preceding vaccination card example, in order to know the date of the second vaccination, you can frame the query as “What date was the 2nd dose administered?”
- Long answers increase response latency and can lead to timeouts. Try to ask questions that respond with answers fewer than 100 words.
- Passing only the key name as the question works when trying to extract standard key-value pairs from a form. We recommend framing full questions for all other extraction use cases.
- Be as specific as possible. For example:
- When the document contains multiple sections (such as “Borrower” and “Co-Borrower”) and both sections have a field called “SSN,” ask “What is the SSN for Borrower?” and “What is the SSN for Co-Borrower?”
- When the document has multiple date-related fields, be specific in the query language and ask “What is the date the document was signed on?” or “What is the date of birth of the application?” Avoid asking ambiguous questions like “What is the date?”
- If you know the layout of the document beforehand, give location hints to improve accuracy of results. For example, ask “What is the date at the top?” or “What is the date on the left?” or “What is the date at the bottom?”
For more information about the Queries feature, refer to the Textract documentation.
Conclusion
In this post, we provided an overview of the new Queries feature of Amazon Textract to quickly and easily retrieve information from documents such as paystubs, mortgage notes, insurance cards, and vaccination cards based on natural language questions. We also described how you can parse the response JSON.
For more information, see Analyzing Documents , or check out the Amazon Textract console and try out this feature.
About the Authors
 Uday Narayanan is a Sr. Solutions Architect at AWS. He enjoys helping customers find innovative solutions to complex business challenges. His core areas of focus are data analytics, big data systems, and machine learning. In his spare time, he enjoys playing sports, binge-watching TV shows, and traveling.
Uday Narayanan is a Sr. Solutions Architect at AWS. He enjoys helping customers find innovative solutions to complex business challenges. His core areas of focus are data analytics, big data systems, and machine learning. In his spare time, he enjoys playing sports, binge-watching TV shows, and traveling.
 Rafael Caixeta is a Sr. Solutions Architect at AWS based in California. He has over 10 years of experience developing architectures for the cloud. His core areas are serverless, containers, and machine learning. In his spare time, he enjoys reading fiction books and traveling the world.
Rafael Caixeta is a Sr. Solutions Architect at AWS based in California. He has over 10 years of experience developing architectures for the cloud. His core areas are serverless, containers, and machine learning. In his spare time, he enjoys reading fiction books and traveling the world.
 Navneeth Nair is a Senior Product Manager, Technical with the Amazon Textract team. He is focused on building machine learning-based services for AWS customers.
Navneeth Nair is a Senior Product Manager, Technical with the Amazon Textract team. He is focused on building machine learning-based services for AWS customers.
 Martin Schade is a Senior ML Product SA with the Amazon Textract team. He has over 20 years of experience with internet-related technologies, engineering, and architecting solutions. He joined AWS in 2014, first guiding some of the largest AWS customers on the most efficient and scalable use of AWS services, and later focused on AI/ML with a focus on computer vision. Currently, he’s obsessed with extracting information from documents.
Martin Schade is a Senior ML Product SA with the Amazon Textract team. He has over 20 years of experience with internet-related technologies, engineering, and architecting solutions. He joined AWS in 2014, first guiding some of the largest AWS customers on the most efficient and scalable use of AWS services, and later focused on AI/ML with a focus on computer vision. Currently, he’s obsessed with extracting information from documents.