Microsoft Workloads on AWS
Babelfish for Aurora PostgreSQL Performance Testing Results
In this blog post, I will share results for Babelfish for Aurora PostgreSQL performance testing using the HammerDB database benchmarking tool. Based upon the results of testing various Aurora for PostgreSQL clusters hosting Babelfish, I will also provide recommendations on the optimal instance selection from the price-performance viewpoint.
This blog post concludes with a summary of performance values you may expect from Babelfish. I would like to emphasize that this analysis does not compare Babelfish to other RDBMSes but focuses on the performance characteristics of Babelfish itself.
1. Why we need Babelfish performance testing
Babelfish for Aurora PostgreSQL is a capability of Amazon Aurora PostgreSQL-Compatible Edition that enables Aurora to understand commands from applications written for Microsoft SQL Server. By allowing Aurora PostgreSQL to understand Microsoft T-SQL and communicate over SQL Server’s proprietary Tabular Data Stream protocol, Babelfish speeds up the migration of compatible workloads from SQL Server to open-source database platforms and lowers migration risk. With minimal to no changes, you may run applications developed for SQL Server against the Babelfish database migrated from SQL Server.
As Babelfish matures providing more features and capabilities, more and more SQL Server workloads can be migrated to Babelfish. So it is not surprising that a lot of AWS customers are planning to or are migrating their SQL Server workloads to Babelfish. The Babelfish Compass tool helps to assess the compatibility of the customer’s database with Babelfish and identifies the migration path.
In addition to the Babelfish compatibility, these customers are interested in understanding what kind of performance they may expect from Babelfish and how they should set up their Aurora cluster to save cost and optimize price/performance for their workload on Babelfish. To answer these questions, I ran a series of Babelfish performance tests following the setup outlined in the blog post Setting up Babelfish for Aurora PostgreSQL for performance testing using HammerDB.
2. Selecting Babelfish benchmarking scenarios
2.1. Setting up databases for benchmarking
I will use HammerDB 4.4 OLTP workload for Babelfish benchmarking as OLTP workloads are prevalent in SQL Server migrations to AWS. Also, for OLAP-type workloads, AWS offers specialized services like Amazon Redshift.
For the OLTP workloads, I tried to cover a broad range of various scenarios, so I generated three HammerDB databases using 8,000, 30,000, and 75,000 warehouses, which resulted in test databases of about 0.87, 3.3, and 8.2 terabytes. These databases represent a broad range of relatively small to quite large workloads.
2.2. Selecting instance types
Aurora for PostgreSQL, which is the base for Babelfish, supports many instance classes. Some of them, like db.r4 and db.r3, are legacy, and I will not consider them for testing. I also will not consider the db.serverless class, as Aurora adjusts the compute, memory, and network resources dynamically as the workload changes.
The first instance class I included in testing is db.r5. Instances in this class are memory-optimized, Nitro-based instances, which are well suited for memory-intensive applications such as high-performance databases.
Aurora also supports db.r6g and db.x2g instance classes, both of which are powered by AWS Graviton-2 processors. Additionally, the db.x2g instance class offers low cost per GiB of memory. Both classes are recommended for memory-intensive workloads, including open-source databases like PostgreSQL, which hosts Babelfish. Thus, I included these classes in Babelfish testing.
On July 15th, 2022, Amazon Aurora PostgreSQL-Compatible Edition announced support for the db.r6i instance class. Instances in this family are powered by 3rd-generation Intel Xeon Scalable processors and are an ideal fit for memory-intensive workloads, such as SQL and NoSQL databases. As Aurora now supports these new instances, it was natural to include them in the Babelfish testing lineup.
Considering the relatively large size of the test databases, I selected the large instances in each class for testing. The final lineup selected for testing is presented in Table 1:
 Table 1. Instance type lineup for Babelfish performance testing.
Table 1. Instance type lineup for Babelfish performance testing.
2.3. Selecting the number of virtual users for benchmarking
HammerDB virtual users are simulated users that stress test a database. To estimate the maximum performance of a system, it’s good practice to start with a relatively few virtual users and gradually increase their number until the database reaches its maximum performance level. When we increase the number of virtual users, representing the load on the system, the performance metric will grow until it reaches a saturation point, in which growth stops or even declines.
As the database gets close to the saturation point, performance change becomes slower and slower. Therefore, for HammerDB benchmarking, the number of virtual users for a series of tests is usually set in a geometric progression. I have selected the following set of virtual users for each of the environments: 256, 362, 512, 724, and 1024.
Typically, a 4 to 5 warehouses per virtual user would be a minimum value to ensure an even distribution of virtual users across provisioned warehouse. Considering that the smallest database in the test set contains 8,000 warehouses, it is safe to set the maximum number of virtual users to 1,024.
2.4. Selecting a performance metric
HammerDB reports two performance metrics – Transactions per Minute (TPM) and New Orders per Minute (NOPM). TPM is a legacy metric and depends on how the database system reports transactions. NOPM is a newer metric and is based on the number of orders inserted into the HammerDB new_order table during the test run. HammerDB calculates NOPM based upon the count of records in the new_order table before and after the test run, so NOPM does not depend on how the database system reports transactions. Also, NOPM has a close relation to the official tpmC statistic recording of new orders per minute.
Based upon these factors, I selected NOPM as a metric to report for Babelfish performance test runs.
2.5. Identifying performance for each test configuration
To get statistically stable results, for each set of databases (see Section 2.1) and each Aurora cluster configuration (see Section 2.2), I ran a series of performance tests at varying levels of workload with the number of virtual users defined in Section 2.3. I repeated each test 3 times and averaged results for the same level of workload.
For each Aurora cluster configuration and each database size, I defined Babelfish performance as the maximum performance reached for respective configuration. For example, Figure 1 presents results for Babelfish performance testing on Aurora cluster configured with an db.r5.12xlarge instance. Each point on this chart is the average of 3 test runs.
In this scenario, Babelfish reached the best performance at the load level of 724 virtual users for each of the three databases, so I accept the values of NOPM for 724 virtual users for each of the database sizes as Babelfish performance for this cluster for respective databases. When using more powerful instances for the cluster, Babelfish reached maximum performance at the load level corresponding to 1,024 virtual users.
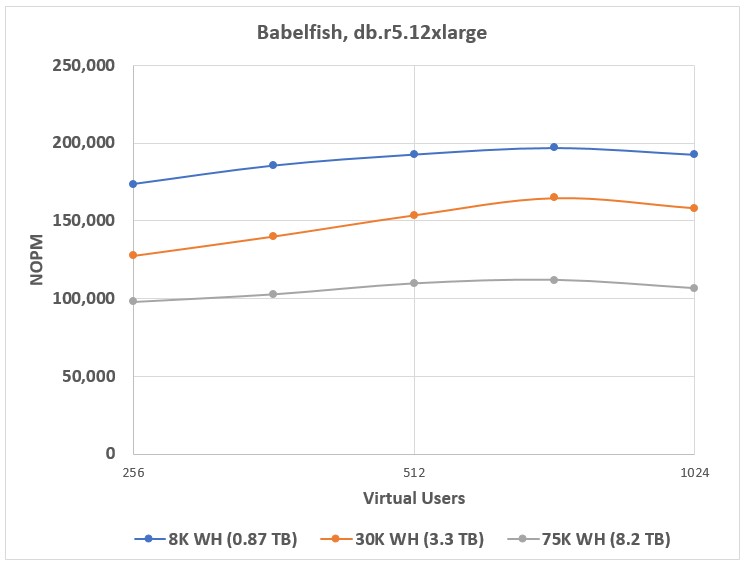 Figure 1. Babelfish benchmarking results for cluster based on db.r5.12xlarge.
Figure 1. Babelfish benchmarking results for cluster based on db.r5.12xlarge.
3. Analyzing performance results
Table 2 captures the benchmarking results for all Babelfish Aurora clusters I selected for testing for each of the three databases. Using the AWS Pricing Calculator, I also estimated the monthly cost for each of the clusters. As I compare performance results between clusters across the databases of the same size, I estimated cost just for the compute component of the cluster as the data storage cost for the databases of the same size would be the same. Note the calculated compute cost in the last column of Table 2.
 Table 2. Babelfish benchmarking results.
Table 2. Babelfish benchmarking results.
3.1. Comparing results for db.r5 and db.r6i instance classes
Let’s first focus on comparing results for the db.r5 and db.r6i classes. All instances in these two classes are memory-optimized and Intel-based. They offer the same instance sizes except that the db.r6i class offers db.r6i.32xlarge instance for which there is no comparable instance in the db.r5 class. For convenience of comparison, Table 3 shows Babelfish benchmarking results for comparable instances of these two classes.
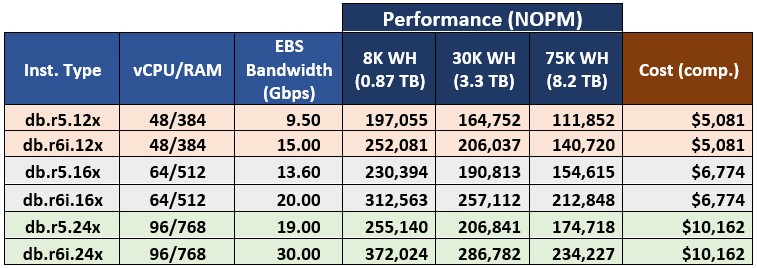 Table 3. Benchmarking results for comparable db.r5 and db.r6i instances.
Table 3. Benchmarking results for comparable db.r5 and db.r6i instances.
As you see in Table 3, comparable db.r5 and db.r6i instances offer the same cost for Aurora clusters but provide significantly different performance points — with db.r6i beating db.r5 for all instance and database sizes. I summarized performance gain of db.r6i instances over comparable db.r5 instances for various databases and presented these results in Figure 2.
 Figure 2. db.r6i instances performance gain over comparable db.r5 instances for various database sizes.
Figure 2. db.r6i instances performance gain over comparable db.r5 instances for various database sizes.
As you see in Figure 2, depending on the instance size and size of the database, db.r6i instances provide performance gain between 25% and 45%. To explain this difference in performance, I captured Amazon CloudWatch metrics for the test runs on db.r5.24xlarge and db.r6i.24xlarge (see Figure 3).
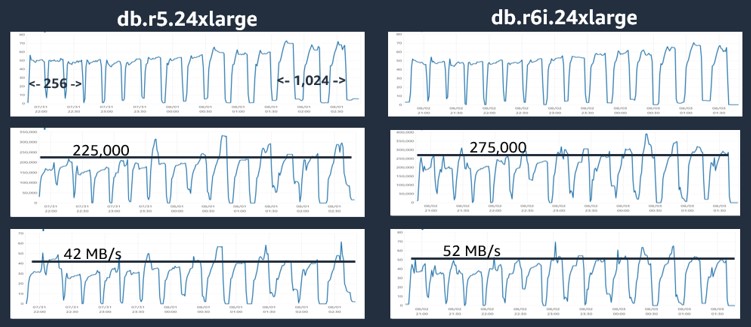 Figure 3. Amazon CloudWatch metrics snapshot.
Figure 3. Amazon CloudWatch metrics snapshot.
The first chart in Figure 3 represents CPU utilization. Each “peak” on the chart corresponds to a single test run in a series of 3 runs, progressing from 256 virtual users on the left to 1,024 virtual users on the right. For each instance family, CPU utilization starts at around 50% and reaches around 70% with increased load.
However, we see a totally different picture for IOPS. For db.r5.24xlarge, IOPS reaches about 225,000, while for db.r6i.24xlarge, IOPS is about 20% higher at around 275,000. We see a similar picture for the storage throughput with db.r6i.24xlarge, which is capable of achieving, again, about 25% higher throughput than db.r5.24xlarge.
Referring back to Table 3, comparable db.r6i instances provide significantly larger Amazon Elastic Block Storage (Amazon EBS) throughput than db.r5 instances. This difference in storage performance is the reason that Aurora clusters based upon db.r6i instance family provide higher HammerDB performance results than the clusters based upon db.r5 instances of the same size.
Considering the identical cost of Aurora PostgreSQL clusters based upon db.r5 and db.r6i instances of the same size and the performance benefits of db.r6i family, it makes little sense to consider db.r5 for new Babelfish deployments. For existing Babelfish deployments, it makes sense to upgrade the cluster to the db.r6i family and save on costs by scaling down to a smaller instance size without sacrificing performance. Thus, I will exclude db.r5 instance class from further consideration.
3.2. Analyzing price/performance of the various instance classes
Excluding db.r5 instances, leaves us with 8 instances. Table 4 presents test results with instances grouped by performance levels in 3 categories – low-end, mid-range, and high-end. For each performance group, I also provide the calculated cost per 1,000 NOPM, which offers a good base to compare different instance types.
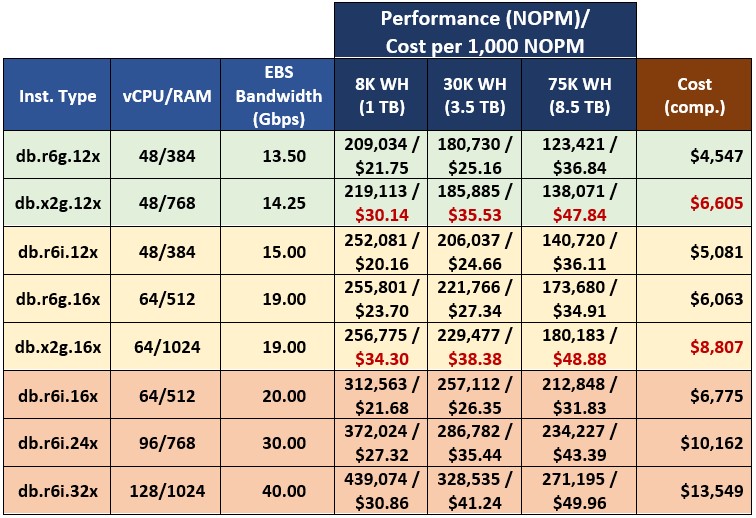 Table 4. Performance and cost per 1,000 NOPM.
Table 4. Performance and cost per 1,000 NOPM.
Instances of the db.x2g family do not offer competitive performance. The extended amount of RAM, which results in the higher price of the instances in this family, translates into marginally higher Babelfish performance not justified by the incurred extra cost.
Table 5 summarizes the best options for Babelfish OLTP workloads within this benchmark testing – that is, selected database sizes and virtual user’s range. I grouped the instances in this table by the Aurora cluster price range.
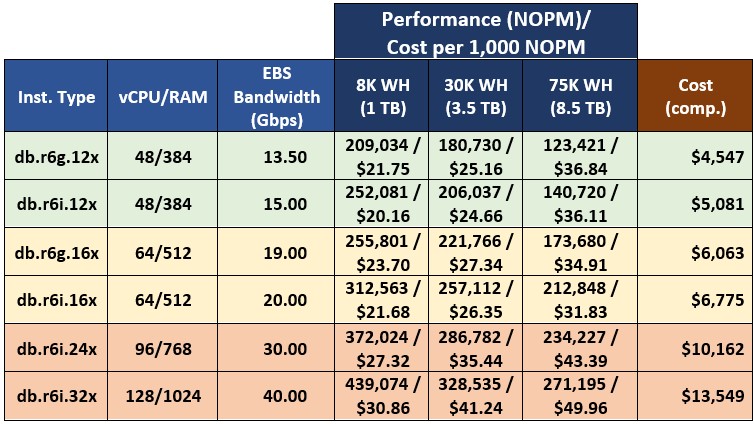 Table 5. Recommended instance families for Babelfish OLTP workloads.
Table 5. Recommended instance families for Babelfish OLTP workloads.
In the lower price brackets, the db.r6g.12xlarge instance offers a lower overall cost, albeit at lower performance, resulting in a comparable but slightly higher cost per 1,000 NOPM across all tested database sizes. There is a similar relationship between db.r6g.16xlarge and db.r6i.16xlarge instances in the middle bracket. At the top bracket, db.r6i high-end instances offer the highest performance but at a higher price point.
3.3. Performance as a function of database size
Another interesting point would be to analyze how Babelfish performance depends on the database size for various cluster configurations. I plotted the relevant data on the chart in Figure 4. The lower-end instances, like db.r6g.12xlarge and db.r6i.12xlarge, demonstrate a uniform, linear decrease in performance with an increase in the database size.
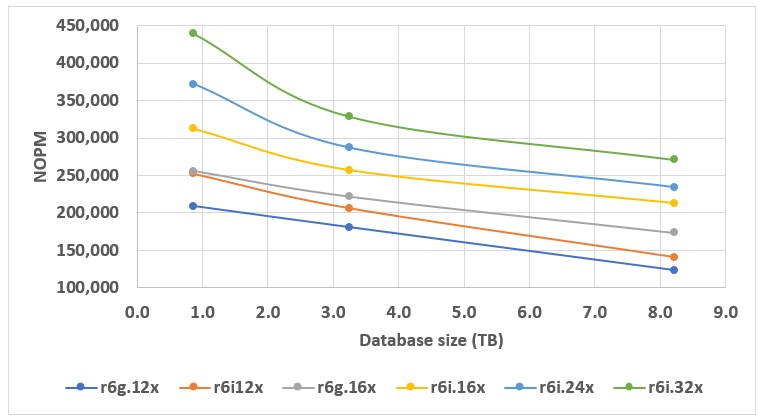 Figure 4. Performance versus database size.
Figure 4. Performance versus database size.
The larger the instance we use for a Babelfish cluster, the more sensitive it becomes to an initial change in database size, but then arrests the decline in performance as the database size grows further.
For smaller instances, even the smallest database significantly exceeds the amount of available RAM. So, from the start, the respective Babelfish performance is defined by the EBS throughput of the underlying instance.
For larger instances, a significant portion, if not the whole 0.87 TB database, fits into RAM. Thus, transition from a database of under 1 TB in size to 3.3 TB means transition from the database primarily fitting into RAM to a database that significantly exceeds the amount of available RAM. This is the reason for a rather sharp drop at the beginning, which later levels off as Babelfish performance relies more and more on the EBS throughput of the instance.
4 Conclusions
If your SQL Server database is compatible with Babelfish or you could make it compatible with a few changes, Babelfish is a solid tool to ease the migration of SQL Server workloads to the Amazon Aurora platform. Look at using DMS with the Aurora PostgreSQL target endpoint for the best performance for migrating SQL Server to Babelfish.
Consider deploying your Babelfish cluster using Graviton2-based instances because they are less expensive than comparable Intel-based instances, albeit at slightly lower performance level. Examine your database size and required level of performance when selecting a specific instance type for your Babelfish cluster.
Recognize the need to run load tests against your database to identify the optimal Aurora cluster configuration for your workload.
AWS can help you assess how your company can get the most out of cloud. Join the millions of AWS customers that trust us to migrate and modernize their most important applications in the cloud. To learn more on modernizing Windows Server or SQL Server, visit Windows on AWS. Contact us to start your modernization journey today.