Microsoft Workloads on AWS
Setting up Babelfish for Aurora PostgreSQL for performance testing using HammerDB
In this blog post, I will provide details on how to set up Babelfish for Aurora PostgreSQL for performance analysis using the HammerDB performance tool.
1. Introduction
Whether it’s a component of migrating to AWS or optimizing workloads already on AWS, customers are looking at the options to modernize their SQL Server workloads. An attractive modernization option is to migrate these workloads to open-source platforms, like Babelfish, to avoid expensive Microsoft licenses, vendor lock-in periods, and audits.
Babelfish for Aurora PostgreSQL is a capability of Amazon Aurora PostgreSQL-Compatible Edition that enables Aurora to understand commands from applications written for Microsoft SQL Server. By allowing Aurora PostgreSQL to understand Microsoft T-SQL and communicate using SQL Server’s proprietary Tabular Data Stream (TDS) protocol, Babelfish speeds up the migration of compatible workloads from SQL Server to the open-source database platform and lowers migration risk. With minimal to no changes, you may run applications developed for SQL Server against the Babelfish database migrated from SQL Server.
As Babelfish matures, providing more features and capabilities, more and more SQL Server workloads can be migrated to Babelfish. So it is unsurprising that many AWS customers are planning to or are migrating their SQL Server workloads to Babelfish. The Babelfish Compass tool helps to assess the compatibility of your database with Babelfish and identifies the migration path.
Besides Babelfish compatibility, customers are interested in understanding what kind of performance they can expect from Babelfish. HammerDB is the leading benchmarking and load-testing software for the world’s most popular databases supporting Oracle, Microsoft SQL Server, IBM Db2, MySQL, MariaDB, and PostgreSQL. While HammerDB does not directly support Babelfish, we can use the HammerDB SQL Server configuration to benchmark Babelfish.
This blog post highlights the issues of using HammerDB with Babelfish and shows how to overcome them to successfully implement Babelfish performance testing using HammerDB.
2. Prerequisites
You will need an AWS account with an Amazon Virtual Private Cloud (Amazon VPC) that you can use for Babelfish performance testing. To drive HammerDB performance testing for Babelfish, you will need a load-generating machine running HammerDB. You can deploy HammerDB on Windows or Linux machines. This guide focuses on using an Amazon Elastic Compute Cloud (Amazon EC2) Windows instance to drive performance testing. However, most of the following configuration steps equally apply to using the Linux machine to drive performance testing.
First, you need to install the HammerDB tool version 4.4 on your load-generating instance. HammerDB documentation details the installation of HammerDB on Windows or Linux. In the latest version of HammerDB, the ostat and payment stored procedures were changed to use a “SELECT 50 PERCENT” clause, which is not yet supported by Babelfish. I have reported the respective issue to the HammerDB project. Until the HammerDB team resolves this issue or Babelfish enables support for this clause, please use HammerDB version 4.4 to implement performance testing on Babelfish.
To run performance testing, you will need a Babelfish for Aurora PostgreSQL DB cluster, which you can create following AWS documentation. Aurora PostgreSQL version 13.4 and higher support Babelfish for Aurora PostgreSQL. I recommend selecting the latest supported version of Aurora PostgreSQL for your test cluster.
3. Building HammerDB OLTP database on Babelfish
To use HammerDB for performance benchmarking, it is necessary to first build a test database. HammerDB supports OLTP and analytical workloads for performance testing. I will focus on the OLTP workload in this blog post as it is more broadly used.
HammerDB supports building the OLTP test database on multiple platforms. As Babelfish is compatible with SQL Server, when generating the test database using HammerDB, I selected SQL Server as the target platform for the build. HammerDB builds a test database following a set of build options. Figure 1 shows a sample set of build options.
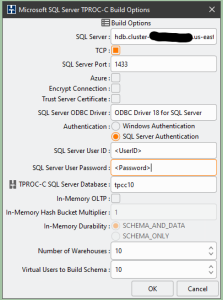 Figure 1. Setting HammerDB Schema Build options.
Figure 1. Setting HammerDB Schema Build options.
For the SQL Server field, you will use the writer endpoint of your Babelfish DB cluster. SQL Server Port is the default MS SQL Server port 1433. HammerDB defaults to ODBC Driver 18 for SQL Server, but you may enter the driver available on your test Windows instance.
For SQL Server User ID and SQL Server User Password fields, use the User ID and Password you specified when creating Babelfish for the Aurora PostgreSQL DB cluster.
For TPROC-C SQL Server Database field, enter your Babelfish cluster database name. While HammerDB can create and populate a test schema into an existing empty SQL Server database, with Babelfish, if you select the existing database, the loading of HammerDB database will fail! Thus, it is important to let HammerDB create a database instead of generating a schema into an existing database.
The field Number of Warehouses defines the size of the test database, with each warehouse using about 100 MB of database space. The larger the value of Virtual Users to Build Schema, the faster the build will proceed as virtual users will build the warehouses in parallel. Specify a number of virtual users that are equal or less than the target number of warehouses. Building a 10-warehouse database, as shown in Figure 1, may take 10 to 15 minutes, depending on the size of your test driver instance and Aurora for PostgreSQL cluster instance hosting the Babelfish database.
If you plan to build a large test database, then specifying a large number of virtual users would be highly beneficial as long as the test driver instance running HammerDB can support that many concurrent users and the Babelfish DB cluster uses a sufficiently large host. For example, to create a test database with 75,000 warehouses using 500 virtual users, as shown in Figure 2, I configured Aurora for PostgreSQL DB cluster with a db.r6i.32xlarge instance and used a General Purpose m6i.12xlarge instance for the HammerDB host machine. Still, building and populating this database took several days.
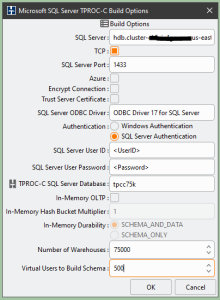 Figure 2. HammerDB Schema Build options for a large database.
Figure 2. HammerDB Schema Build options for a large database.
It is important to note that when the rest of the virtual users finish building and populating the database, HammerDB virtual user #1 will continue to create indexes and stored procedures, as shown in Figure 3, which may also take significant time for a large test database.
 Figure 3. Virtual user #1 continues working after other users finished
Figure 3. Virtual user #1 continues working after other users finished
4. Post-build configuration of HammerDB OLTP database
At the end of the build process, while all worker users terminate successfully, virtual user #1 will terminate with an error, as shown in Figure 4.
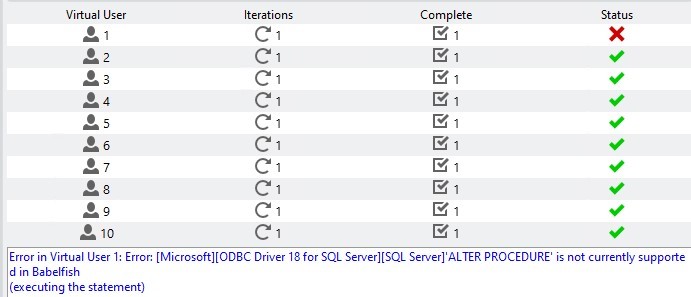 Figure 4. User #1 terminates with the error
Figure 4. User #1 terminates with the error
After analyzing the build log, I found out that this error was related to creating the dbo.sp_updstats procedure. This error happened because Babelfish currently does not support the qualifier with execute as ‘dbo’ as shown in Figure 5:
CREATE PROCEDURE dbo.sp_updstats
with execute as 'dbo'
as exec sp_updatestatsFigure 5. Failed CREATE PROCEDURE script
Remediation is simple–connect to your new Babelfish database using SSMS (or another tool compatible with SQL Server) and create procedure dbo.sp_updstats using the script shown in Figure 6:
CREATE PROCEDURE dbo.sp_updstats
as exec sp_updatestats
Figure 6. Changed script for sp_updstats HammerDB stored procedure.
HammerDB calculates a system-independent performance metric of New Orders per Minute (NOPM) and a database-specific metric of Transactions Per Minute (TPM). Starting with HammerDB 4.0, NOPM is the recommended metric.
HammerDB calculates TPM based upon system view sys.dm_os_performance_counters, which is not provided with Babelfish. So, to allow HammerDB to run successfully, I created a limited version of this system view in PL/pgSQL using PostgreSQL semantics. To implement this view, connect to your Babelfish database using a PostgreSQL client of your choice and run the script provided in Figure 7. DBeaver is the client that I like as it is a universal database tool providing a convenient GUI interface.
-- DDL for sys.dm_os_performance_counters view
-----------------------------------------------------
--CREATE OR REPLACE VIEW sys.dm_os_performance_counters
AS
SELECT 'SQLServer:SQL Statistics'::text AS object_name,
'Batch Requests/sec'::text AS counter_name,
272696576 AS cntr_type,
sum (pg_stat_database.xact_commit
+ pg_stat_database.xact_rollback)::integer
AS cntr_value
FROM pg_stat_database
WHERE pg_stat_database.datname = 'babelfish_db'::name;
--------------------------------------------------------------
-- To Enable access from TDS-SQL side execute following commands:
--------------------------------------------------------------
ALTER VIEW sys.dm_os_performance_counters OWNER TO master_dbo;
GRANT SELECT ON sys.dm_os_performance_counters TO PUBLIC;
Figure 7. Script for sys.dm_os-performance_counters limited view
With these minor changes, the Babelfish database is ready for HammerDB performance benchmarking.
5. Running HammerDB performance test against Babelfish
To run the HammerDB performance test, you must first configure the Driver Script options. I configured these options through the GUI screen presented in Figure 8. Some fields in this screen are similar to the Schema Build options I presented in Figure 1 and discussed in Section 3. Now let’s focus on options specific to the Driver Script.
 Figure 8. Setting Driver Script options.
Figure 8. Setting Driver Script options.
Selecting the Timed Driver Script option is appropriate for running a series of repeatable tests. The other option is to run manual benchmarks to validate installation and configuration. In the Minutes of Ramp-Up Time field, you specify the number of minutes for ramp-up before starting the test. This should include the time required to create all virtual users for the test, as well as warming up the database for the test. It is better to err on the high side because if you do not provide enough time to create all the virtual users and warm up the database (preload buffers, optimize query plans, etc.), you might get incorrect benchmarking results.
For the Minutes of Test Duration field, it is safe to use 5, but you may experiment with higher numbers as well. To ensure greater I/O activity, select the Use All Warehouses option.
To identify the top performance of the system, increase the number of virtual users running the workload until NOPM results stabilize. As performance numbers change slowly with the increase in the number of virtual users, the general recommendation is to increase the number of virtual users for subsequent tests in geometric progression. To achieve statistical consistency, repeat each test several times. I usually start a test series with a relatively large number of virtual users and then ignore this result to give the database an option to warm up before the actual tests. This results in a requirement to run quite a few tests. To automate running multiple tests, HammerDB provides an Autopilot feature.
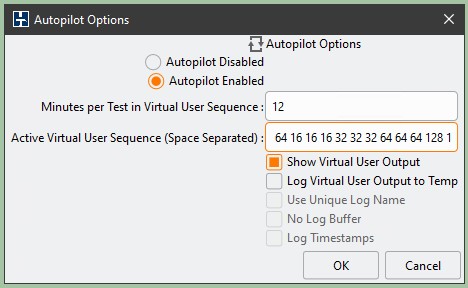 Figure 9. HammerDB Autopilot options.
Figure 9. HammerDB Autopilot options.
Figure 9 shows a sample Autopilot configuration. The Minutes per Test in Virtual User Sequence field specifies the time allocated to run each test. The HammerDB client starts counting this time after it creates all virtual users for the test run, which is part of the ramp-up time. Thus, you may select a number smaller than the sum of ramp-up and test time; this may reduce the overall time required to run the long test sequence. Monitor the first test in the sequence; if it does not provide results before starting the next test, increase this number. HammerDB documentation provides more details on the Autopilot configuration.
6. Identifying the size of your HammerDB test database
Babelfish performance, similar to most other databases, heavily depends on the size of the test database. With HammerDB, the size of the database depends on the number of warehouses defined when building the test database. The general guidance is to allow about 100MB per warehouse.
Suppose you need to get the exact size of your sample Babelfish database created by HammerDB. In that case, you may use the script presented in Figure 10, which I developed specifically to address this question. To run this script, connect to your Babelfish database using a PostgreSQL client of your choice, as this script is written in PL/pgSQL.
SELECT
schema_name,
pg_size_pretty(sum(table_size)) AS GB_size,
sum(table_size) as Byte_Size
FROM (
SELECT
pg_catalog.pg_namespace.nspname AS schema_name,
relname,
pg_relation_size(pg_catalog.pg_class.oid) AS table_size
FROM pg_catalog.pg_class
JOIN pg_catalog.pg_namespace
ON relnamespace = pg_catalog.pg_namespace.oid
) t
WHERE schema_name NOT LIKE 'pg_%’ AND schema_name NOT LIKE 'sys%’
AND schema_name NOT LIKE 'information_%’ AND schema_name NOT LIKE 'master_%'
AND schema_name NOT LIKE 'temp_%’ AND schema_name NOT LIKE 'msdb_%’
GROUP BY
schema_name;Figure 10. Script to calculate Babelfish test database size.
7. Cleanup
If you created the prerequisites defined in Section 2, dispose of them at the end of performance testing to avoid extra costs. To delete the Babelfish test database, delete the underlying Aurora for PostgreSQL cluster. If you do not need HammerDB, you may uninstall HammerDB. If you do not need the Windows EC2 instance used for testing, you may terminate it.
8. Conclusions
In this blog post, I outlined steps and provided details on how to build a sample Babelfish database to run benchmarking using the industry-standard HammerDB performance tool. I identified issues that may arise when building test databases and provided steps and scripts to resolve them. I discussed the basics of database performance testing using HammerDB and outlined important parameters.
With this information, you should be able to start Babelfish performance testing for your scenarios and get confidence in the Babelfish product to facilitate your migration from MS SQL Server to the open-source compatible Babelfish for Aurora PostgreSQL platform.
Using the approach outlined in this post, we performed multiple Babelfish performance tests and published our results in the blog post Babelfish for Aurora PostgreSQL Performance Testing Results.
AWS can help you assess how your company can get the most out of cloud. Join the millions of AWS customers that trust us to migrate and modernize their most important applications in the cloud. To learn more on modernizing Windows Server or SQL Server, visit Windows on AWS. Contact us to start your modernization journey today.