AWS Cloud Operations Blog
How Netflix’s ML framework, Metaflow drives open source adoption with AWS Service Catalog
It’s indisputable that organizations are increasingly becoming more and more data-driven and data science proficient. The volume of data and the number of people working with data is growing. In places where machine learning is necessary, organizations have typically looked towards the data scientists doing the work to investigate and introduce new tools in this space, keep up with new algorithms and research. They are also expected, to some extent, to productionalize this work. These activities usually involve a significant amount of undifferentiated heavy lifting in terms of infrastructure set-up for experimentation and modeling causing slower progress than desired. Successful machine learning projects need something more besides data and algorithms: they need productive data scientists; who are able to quickly prototype new ideas and deploy their models into production. All without having to worry about the underlying infrastructure, so that they can focus on delivering business value.
What?
In this article, we walk you through how AWS Service Catalog helps your organization in taking care of this undifferentiated heavy lifting so that your engineers and data scientists can focus more on problem-solving and less on infrastructure set-up. We talk about how Netflix, which has been running machine learning on AWS for more than ten years, uses AWS Service Catalog for its open source Machine Learning (ML) framework, Metaflow, to provide isolated AWS environments for driving adoption in the open source community.
How?
In December of 2019, the ML Infrastructure team at Netflix partnered with AWS to open source our ML framework, Metaflow. Metaflow is a human-friendly framework that helps data scientists and software engineers to build and manage real-life data science projects and leverage the scale of the cloud. Metaflow has been eagerly adopted inside Netflix, and with our open source release, we were keen on rapidly driving its adoption in the open source community.
As with any open-source infrastructure offering, it takes a significant investment in infrastructure to even begin to evaluate Metaflow in an existing environment. Getting the onboarding experience right for our users was critical for the success of Metaflow. In most organizations, this requires collaboration between data scientists, who may be the ones asking for Metaflow to be adopted, and infrastructure engineers, who manage the organization’s storage, compute, and networking environment. This effort can result in frustration and failure as the teams may not be aligned on outcomes. While the production deployment may be a complex effort by nature, we wanted to provide a simple and straightforward path for prospective users to evaluate Metaflow without having to go through the full-scale deployment process. The purpose of this evaluation process was to convince the stakeholders about the value of Metaflow so that they would be adequately motivated to commit to the actual deployment process.
To address this onboarding problem, we provide limited Metaflow sandbox environments on AWS where users can evaluate Metaflow’s integration with various AWS offerings and experience a realistic production setup of Metaflow without any engineering effort required. The user would use the sandbox to ship parts of their workload to be run inside the sandbox, which provides more compute and storage resources than their local workstation.
During our conversations with AWS about the recommended way to implement these sandbox environments, we converged to a solution where all sandboxes live under a shared, isolated AWS account. Each sandbox is defined by an AWS CloudFormation template and is provisioned automatically through AWS Service Catalog. Each sandbox instance includes the following elements:
- Custom Amazon Virtual Private Cloud (Amazon VPC) for each sandbox
- Amazon Simple Storage Service (Amazon S3) with a custom bucket
- Custom AWS Batch job queue for compute with a pre-defined compute environment
- AWS Step Functions and Amazon EventBridge for job scheduling
- Amazon CloudWatch for log management
- Amazon SageMaker for Jupyter notebooks
- Metadata tracking service on AWS Fargate with Amazon Relational Database Service (Amazon RDS)
Metaflow’s integrations with AWS provides a straightforward way for data scientists to build complete ML workflows and operate them independently. It helps data scientists structure their code so that it can be run in the cloud on AWS Batch efficiently. It stores the internal state of the ML workflows in Amazon S3 automatically and tracks the workflow execution in Amazon RDS so data scientists can easily observe their models in real-time using Amazon SageMaker notebooks – the interface that is familiar to most data scientists. Once they are happy with the results, they can deploy their workflows on AWS Step Functions and monitor them via Amazon CloudWatch.
Since the sandbox enables the user to run arbitrary code with arbitrary user-provided data, it must be fully isolated from other surrounding sandboxes including the parent AWS account. This is achieved by carefully crafted IAM policies in addition to blocking all inbound and outbound network access. Metaflow syncs all data dependencies in addition to all code dependencies (e.g, ML libraries) in Amazon S3 from the user’s workstation, providing sandbox users complete flexibility in terms of their choice of ML tooling and datasets; even without any network access.
At the expiration of the sandbox, the AWS Service Catalog provisioned product is terminated and all resources associated with it are purged.
At a high level, the request flow from a new sandbox sign-up to sandbox creation and deletion looks as follows.
Architecture
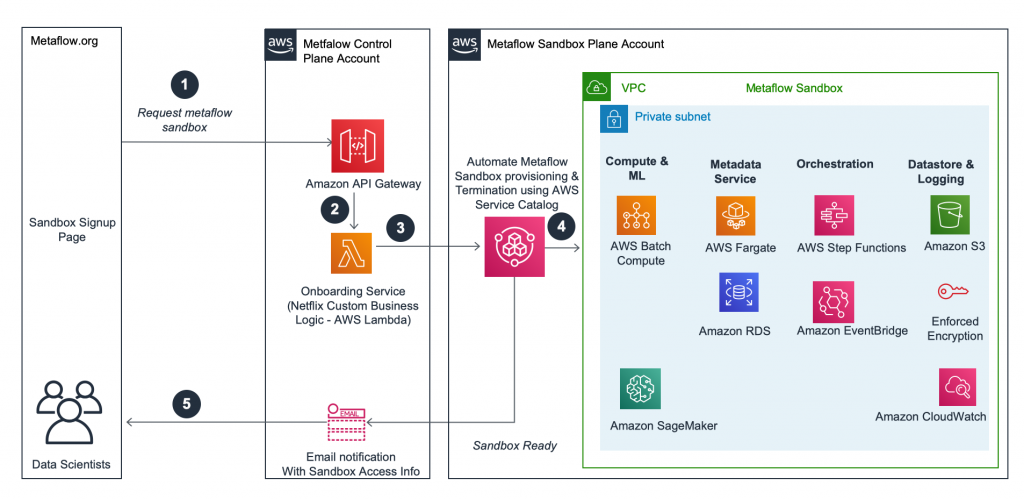
- The user requests a sandbox using their GitHub credentials.
- The request is verified and queued in the Metaflow Control Plane Account until a sandbox is available to be dispensed.
- When a sandbox slot becomes available, an AWS Lambda function requests AWS Service Catalog to provision an AWS Service Catalog product that has been already configured in the Metaflow Sandbox Plane Account.
- AWS Service Catalog manages the lifecycle for sandboxes. AWS Service Catalog’s provision product API provisions sandboxes via a governed AWS CloudFormation template.
- Once the sandbox has been created successfully, the user is notified with further instructions to configure their Metaflow installation with this sandbox.
Upon the expiry of the sandbox, AWS Service Catalog’s terminate provisioned product API is used to purge the resources related to the sandbox as a result all compute is stopped, the data is permanently deleted and all AWS resources associated with the sandbox are purged. A new vacant slot is also made available for the next pending request for a sandbox and the cycle repeats using API driven automation.
Conclusion
AWS Service Catalog has greatly simplified Metaflow’s user onboarding process and enabled data scientists in the open source community to experience the value proposition of Metaflow in a simple and streamlined manner. Metaflow sandboxes provision AWS resources required for running ML workloads and you can similarly create and customize your AWS Service Catalog product with the AWS resources that make sense for your end users. In conclusion, AWS Service Catalog provides an easy and automated way for you to centrally manage your cloud footprint while providing self-service infrastructure provisioning capabilities to your engineering and data science teams.
About the Authors

Savin Goyal
Savin is a software engineer at Netflix responsible for Metaflow, Netflix’s ML platform. He focuses on building generalizable infrastructure to accelerate the impact of data science at Netflix.

Sanjay Garje
Sanjay Garje leads Global & Strategic technical business development for AWS Service Catalog and AWS Control Tower. Sanjay is a passionate technology leader who takes pride in helping customers on their AWS Cloud journeys by showing them how to transform their business through technology outcomes. In his free time, Sanjay enjoys running, learning new things, teaching Cloud & Big Data technologies and traveling to new destinations with his family.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.