AWS Spatial Computing Blog
Simulating Expert Teams with Agentic AI and Amazon Bedrock AgentCore
Introduction
Answering technical questions that span multiple specialties is rarely just about finding the right answer. One of the hardest parts is often coordinating the right people to provide it. What if AI could augment this coordination—not by replacing expert teams, but by accelerating their initial research and synthesis?
When complex technical questions span multiple domains, the path to an answer often involves significant friction. A question about building an autonomous robotics system might require input from IoT specialists, GenAI practitioners, spatial computing experts, and HPC engineers. Each specialist maintains deep expertise, but coordinating their collective knowledge takes time.
Organizations have talented specialists across various specialty domains, but orchestration can be a hurdle: identifying which experts to involve, getting them aligned on the question, and synthesizing their perspectives into a coherent response.
For example, at AWS there’s an Advanced Computing organization that comprises seven specialized groups: HPC, Quantum Computing, Visual Computing, Spatial Computing, IoT, Technology Partnerships, and Emerging Technologies (heavily focused on applied GenAI). Customer questions frequently span two or three of these domains. The team structure works well, with specialists maintaining deep domain expertise while collaborating across boundaries, but like any organization with distributed expertise, coordination takes time.
This observation led to an experiment: what if we built a multi-agent AI system that mirrors this exact team structure? Seven AI agents, each representing a domain, with a coordinator that routes questions and assembles the right team for each query.
The resulting system runs on Amazon Bedrock AgentCore, AWS’s managed service for building and deploying agentic AI applications. The agents themselves are built with AWS Strands Agents, an open-source SDK for multi-agent orchestration.
The system handles initial research and cross-domain coordination, producing a draft architecture or solution approach. Human experts can then validate, refine, and make final decisions. This addresses the coordination bottleneck: instead of spending days identifying the right experts, scheduling meetings, and synthesizing perspectives, you get a starting point in minutes.
As we’ll see in the examples below, this can compress what might be days or weeks of research into a single consultation. The value proposition: not perfect answers, but accelerated time-to-draft that lets human experts focus on refinement rather than initial research.
In this post, we’ll walk through how this system works, demonstrate it handling real queries, and extract patterns you can apply. Whether you’re building similar systems for your organization, learning how Amazon Bedrock AgentCore works through a practical example, or exploring what types of problems agentic AI can solve, this post offers concrete implementation details.
The complete implementation is available on GitHub, including infrastructure code, agent definitions, and deployment scripts.
Solution overview
At its core, this implementation uses what we’ll call a coordinator-orchestrated dynamic swarm pattern, built with AWS Strands Agents. A coordinator agent analyzes incoming queries and decides how to respond: check past interactions stored in AgentCore Memory, answer directly for simple follow-ups, or dynamically spawn a temporary swarm of specialists from a pool of seven domain expert agents. Each expert agent is designed to respond like an AWS solutions architect specializing in their respective domain.
The coordinator selects which expert agents to involve based on the query. Simple questions might need just one specialist, while complex multi-domain questions might require two or three working together as a swarm. Once selected, these agents collaborate through handoffs, passing questions between each other as they work toward an answer.
Each expert agent has access to domain-specific knowledge bases containing current information—service documentation, customer success stories, API specifications, solution guides, and more. When an agent needs information, they query their knowledge base in real-time, read the results, and can query again to dig deeper or clarify.
The result is a dynamic multi-agent system where each agent can perform agentic RAG (Retrieval Augmented Generation) on a specialized knowledge base and where agents take turns and build off each other’s responses. Think about how you might query an LLM, read the result, then ask follow-up questions to steer toward a solution. These agents do the same thing, but each brings different domain expertise. One agent’s response becomes context for another’s query. Their perspectives combine in ways that wouldn’t happen with a single agent or a simple knowledge base lookup.
Behind the scenes, the system runs on Amazon Bedrock AgentCore Runtime for agent hosting, AgentCore Gateway for tool access, and AgentCore Memory for conversation continuity. AWS Lambda handles tool invocations through AgentCore Gateway, and Amazon Bedrock Knowledge Bases provides the domain-specific documentation related to agent queries. Let’s look at how these components fit together.
AWS Architecture
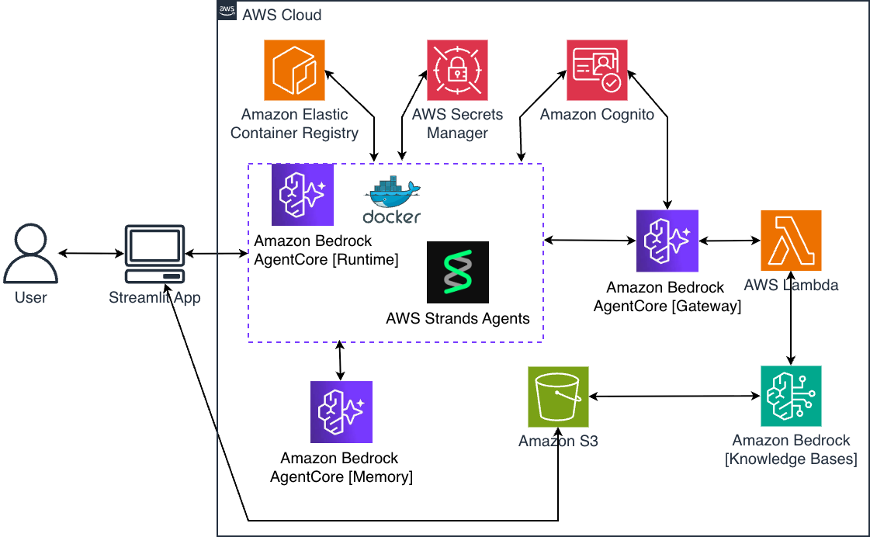
Figure 1: AWS infrastructure showing Amazon AgentCore Runtime, Gateway with MCP, Lambda routing to Knowledge Bases, and Memory for conversation continuity.
Figure 1 shows the AWS infrastructure that powers this multi-agent system. At the center is Amazon Bedrock AgentCore. This implementation uses three of AgentCore’s capabilities: Runtime for hosting the agent code, Gateway for secure tool access via the Model Context Protocol (MCP), and Memory for conversation continuity. AgentCore also provides Identity for authentication and Observability for monitoring, though this implementation doesn’t use those primitives.
The agent code itself runs in a serverless container on AgentCore Runtime. When the system is deployed, AWS Cloud Development Kit (CDK) automatically builds a Docker container from the agent code, pushes it to Amazon Elastic Container Registry (Amazon ECR), and configures the runtime to use it. The runtime scales automatically based on demand and only charges for actual usage.
When an expert agent needs to query a knowledge base, it goes through AgentCore Gateway. Gateway is built on the Model Context Protocol (MCP), an open standard that’s rapidly becoming the industry approach for connecting AI agents to tools and data sources. MCP provides a standardized way for agents to discover and invoke tools without custom integrations for each backend. This matters because as your agent ecosystem grows, you can add new tools through Gateway without modifying agent code since the agents discover available tools automatically through MCP.
AgentCore Gateway supports multiple target types for connecting to different backends: AWS Lambda functions, OpenAPI specifications, or custom MCP servers. This implementation uses a single Lambda target that routes to the appropriate knowledge base based on which expert agent is making the request. For authentication, this implementation uses OAuth with Amazon Cognito to ensure only authorized agents can access the knowledge bases.
The Lambda function receives the domain name and query text from the agent. The seven knowledge bases are built using Amazon Bedrock Knowledge Bases, each connected to an Amazon S3 bucket containing domain-specific documents. When you upload documents, the service automatically chunks them, generates embeddings, and indexes them for vector search.
AgentCore Memory provides conversation continuity through two complementary mechanisms. For short-term memory within a session, the system loads recent conversation history between the user and the AI system (the last few exchanges) and adds it directly to the agent’s context. This enables natural follow-up questions within the same conversation. For long-term memory across sessions, AgentCore Memory uses a semantic memory strategy that processes conversations to understand meaning and relationships. This makes it possible for the coordinator to search past knowledge when answering questions, even weeks later. The combination means conversations feel natural in the moment while building institutional knowledge over time.
Multi-agent system architecture
Now that we’ve explained the AWS architecture, let’s look at how the agents themselves collaborate to answer questions.
Figure 2 shows the multi-agent collaboration pattern. The coordinator analyzes each query and decides which expert agents to involve. For a simple question like “What is AWS PCS?”, it selects just the HPC agent. For a complex question about building a digital twin with AI-powered predictive maintenance, it might select three agents: Spatial Computing (for the digital twin architecture), IoT (for sensor data collection), and Generative AI (which also covers traditional ML like predictive maintenance).
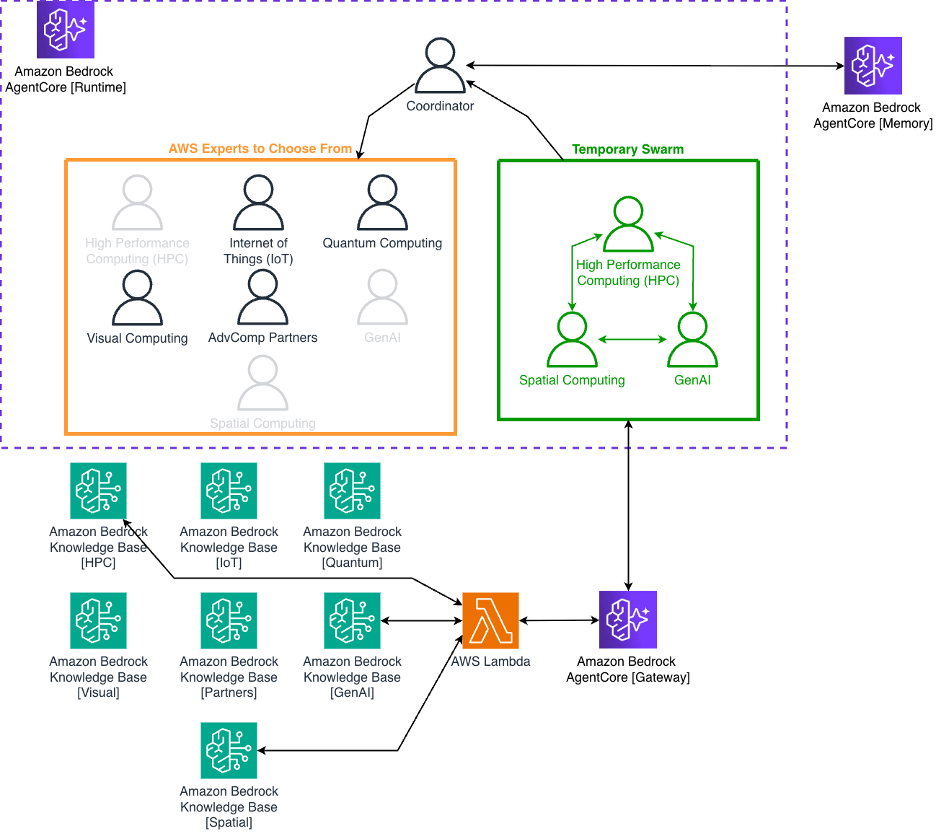
Figure 2: Multi-agent system showing coordinator selecting 3 experts (HPC, Spatial, GenAI) from a pool of 7 domain specialists, with handoff-based collaboration and MCP tools for knowledge base access.
Once the coordinator selects expert agents, it calls a tool called advcomp_swarm, which spawns a temporary team of those specialists using AWS Strands Agents’ swarm construct. In multi-agent architectures, this grouping is sometimes called a handoffs pattern —a set of agents where each agent can communicate directly with any other agent in the group. Each expert agent has a domain-specific system prompt that shapes how it thinks about problems. The HPC agent thinks like an AWS solutions architect specializing in high-performance computing. The Quantum agent thinks about quantum algorithms and Amazon Braket. The Generative AI agent focuses on Amazon Bedrock, AgentCore, and machine learning services.
Agents collaborate through handoffs. After one agent provides their analysis, they explicitly hand off to the next team member. This creates a conversation thread where each agent builds on what previous agents have said. The system enforces limits: maximum 20 handoffs and 20 iterations per swarm, with a 30-minute total execution timeout. These constraints keep the collaboration focused and prevent runaway execution.
Knowledge base access happens through AgentCore Gateway. When an agent needs information, they call the query_knowledge_base tool with their domain name and a search query. The agent includes a JSON web token (JWT), obtained from Amazon Cognito via OAuth, in the request. Gateway validates the token and routes to the AWS Lambda function.
The Lambda function maps the domain to the appropriate Amazon Bedrock Knowledge Base and calls the RetrieveAndGenerate API. This API performs vector search to find relevant document chunks, then uses a foundation model to synthesize those chunks into a coherent answer. The agent receives this synthesized response and can query again to dig deeper or clarify.
Each agent can only access their own domain’s knowledge base. The HPC agent queries the HPC knowledge base, the Quantum agent queries the Quantum knowledge base, and so on. This separation mirrors the human organizational structure we’re replicating: each specialist has deep expertise in their domain. The design rationale is that domain-specific agent prompts combined with focused knowledge base access helps agents maintain specialized perspectives—similar to how giving one agent access to 100 tools often works less effectively than distributing those tools across specialized agents. When multiple experts collaborate, their combined knowledge base access provides comprehensive coverage across domains.
The memory system runs throughout this process. Before the coordinator calls the expert agent swarm, it checks AgentCore Memory for relevant past conversations. If it finds sufficient information, it answers immediately without assembling experts. This memory-first approach improves efficiency for follow-up questions. After the swarm completes, the coordinator saves the conversation to memory, including which agents were involved. This creates a learning loop where the system gets better at answering similar questions over time.
The entire request flow looks like this: User submits query → Coordinator checks memory → If needed, coordinator selects expert agents and calls swarm tool → Expert swarm created with MCP tools → Agents collaborate via handoffs, querying knowledge bases → Gateway authenticates, AWS Lambda queries Bedrock Knowledge Bases → Swarm synthesizes final response → Coordinator saves conversation and learnings to memory. This architecture balances efficiency (memory-first), expertise (domain specialists), and current information (knowledge base access).
Seeing it in action
Let’s walk through three queries that demonstrate different aspects of the system: single-agent knowledge retrieval, multi-agent collaboration, and iterative back-and-forth between agents.
Query 1: “What is AWS PCS?”
Figure 3: Demo video showing single-expert knowledge retrieval for AWS PCS.
This simple question serves as our baseline. The coordinator selects the HPC agent, who queries the HPC knowledge base. The response explains that AWS Parallel Computing Service (PCS) is a managed service for running HPC workloads, distinct from AWS ParallelCluster. For this query, both the multi-agent system and a direct LLM call provide comparable answers – the models are recent enough to know about AWS PCS. This establishes a baseline: when foundation models have current information in their training data, both approaches work well.
Query 2: “Our factory floor has 2,800 cameras and sensors tracking our robots across a 500,000 sq ft facility. We’re drowning in data but can’t visualize where bottlenecks happen or use machine learning to predict equipment failure. How do we build a digital twin that incorporates generative AI to help our robots navigate more efficiently?”
Figure 4: Demo video showing multi-expert collaboration for factory digital twin architecture
This demonstrates multi-agent collaboration. The coordinator analyzes the query and identifies three distinct technical domains: spatial computing (digital twin architecture and 3D visualization), IoT (camera and sensor data collection), and AI/ML (predictive maintenance and navigation). It assembles a team of those three expert agents.
The agents collaborate through handoffs, with each building on the previous agent’s work. The IoT agent starts by designing the data ingestion layer with AWS IoT Core, Amazon Kinesis Video Streams for 2,800 cameras, AWS IoT Greengrass for edge processing, and AWS IoT SiteWise for asset modeling. They hand off to the Spatial Computing agent, who takes that IoT foundation and adds 3D spatial mapping with Visual Asset Management System (VAMS), spatial indexing in Amazon DynamoDB, and AWS IoT TwinMaker for visualization. Finally, the GenAI agent layers in the intelligence: a multi-agent navigation system using AWS Strands Agents and Amazon Bedrock AgentCore Runtime, Amazon SageMaker for predictive maintenance (which typically uses traditional ML models for time series forecasting), and Amazon Bedrock Knowledge Bases for natural language queries.
Each agent queries their domain-specific knowledge base multiple times during this collaboration. The IoT agent queries for “AWS IoT SiteWise asset modeling” and “fleet provisioning for 2,800 devices.” The Spatial agent queries for “spatial data management” and “bottleneck detection.” The GenAI agent queries for “AgentCore multi-agent orchestration” and “AWS Strands Agents collaboration.” These real-time queries ensure recommendations reflect current AWS capabilities.
This output is a starting point, not a final answer. A human expert would need to validate service choices, fill in missing components, and adjust for specific constraints. That’s the intended workflow. The system handles initial research and synthesis; humans validate and refine.
Compare this to what a direct LLM call produces: general guidance like “consider third-party digital twin platforms,” “use traditional ML first,” and “Gen AI is the cherry on top.” The LLM response is cautious and vendor-agnostic, which is reasonable for exploring options, but less specific when you need AWS implementation details.
The multi-agent system provides a detailed AWS-specific architecture with concrete services, integration patterns, and implementation steps. Interestingly, the coordinator’s high-level summary doesn’t look dramatically different from the direct LLM response. Both mention digital twins, IoT, and AI. The real value is in the agent traces. The IoT agent designs the data layer, the Spatial Computing agent adds visualization on top of that foundation, and the GenAI agent integrates intelligence with the spatial context. It’s not three separate answers stapled together but instead a coherent, integrated architecture where each layer depends on the previous one. A human reviewer can dig into these conversations to understand the reasoning, question specific choices, and refine the approach.
Query 3: “We run HPC weather simulations that generate terabytes of data. Historically we’ve used AWS ParallelCluster for these simulations but are open to using new HPC technology from AWS. Additionally, we want AI to find storm patterns and are thinking that GenAI/agentic AI might help but are not sure how and what AWS offers. Have your experts refine a proposal together, poking holes in each other’s arguments and coming up with some ideas for us.”
Figure 5: Demo video of HPC and GenAI experts iterating back and forth to refine an integrated architecture
This query demonstrates the network collaboration pattern that goes beyond supervisor architectures. The user explicitly asks experts to “refine a proposal together” and “poke holes in each other’s arguments”, triggering the system’s iteration mode where agents hand back and forth multiple times rather than executing a linear handoff chain.
Query 2’s factory digital twin could be solved with either a supervisor pattern (coordinator assigns tasks to IoT, Spatial, and GenAI worker agents who each respond back to coordinator) or a network pattern (worker agents can communicate directly with each other, with all communication paths available between agents). But this weather simulation query benefits specifically from the network approach. While a supervisor could technically route messages back and forth between the HPC and GenAI worker agents, supervisor architectures aren’t designed for iterative refinement—they excel at task delegation, not facilitating multi-round debates where worker agents challenge each other’s assumptions and validate claims against documentation. The network pattern allows worker agents to directly hand off to each other, creating a conversation thread where proposals get refined through (agent) peer review rather than coordinator-mediated exchanges.
First, let’s look at what a direct LLM call produces for this query. The response simulates a multi-agent discussion that challenges the premise of whether GenAI is even the right approach for pattern recognition in weather data and recommends starting with traditional computer vision and deep learning before adding GenAI capabilities. It provides a phased implementation strategy (Months 1-3, 3-6, 6+) and ends with clarifying questions about simulation frequency, specific patterns of interest, and data retention policies. This is valuable strategic thinking: the LLM pushes back on assumptions and helps refine requirements before diving into implementation. If you’re still exploring whether GenAI is the right fit or considering multiple cloud providers, this instant response provides quality strategic guidance.
The multi-agent system takes a different approach. The GenAI agent proposes an initial AI architecture: Amazon Bedrock Agents with streaming inference, Amazon SageMaker Processing for Network Common Data Form (NetCDF) data, and a cost estimate. But the HPC agent challenges five specific assumptions: Can Bedrock support real-time streaming? Is SageMaker the right tool for NetCDF preprocessing? Should we use separate VPCs for isolation? What’s the realistic cost for 10TB/day processing? How do we provide explainability for meteorologists?
The GenAI agent queries the knowledge base to validate claims, then revises the architecture: switches from SageMaker to AWS Batch (acknowledging “you’re right!”), confirms Bedrock streaming with 3-5 second latency, provides detailed cost breakdown ($15-19K/month total), and explains Bedrock’s trace capabilities for explainability. The HPC agent validates these revisions against their own knowledge base by confirming FSx export paths, VPC architecture, and network isolation patterns, then approves the final design with specific refinements like S3 prefix separation.
This back-and-forth produced four interactions with three handoffs between the two agents. Compare this to a supervisor pattern where a coordinator would assign tasks to worker agents who each respond once. The network approach allows worker agents to challenge each other’s proposals, validate against documentation, and iteratively refine until both agree on a solution. The HPC agent’s final response includes specific details about VPC subnet layouts, security group specifications, and S3 lifecycle policies that emerged through the iterative refinement process.
The multi-agent system works best when the user has already decided on the general direction and focuses on producing a detailed, AWS-specific implementation plan. If you know you want an AWS solution and need production-ready specifications with validated integration points, the multi-agent system delivers verifiable architecture details that emerged through collaboration. The trade-off is execution time (over six minutes versus a few seconds) but you get traceable reasoning (“My KB confirms FSx export capabilities”), validated cost estimates revised through expert challenges, and concrete specifications ready for implementation.
As with most AI-generated output today, this proposal requires human review. A human solutions architect might spot errors, identify missing components, question cost assumptions, or adjust for specific constraints the system doesn’t know about. But instead of starting from a blank page and spending days researching FSx export configurations, Bedrock streaming capabilities, VPC isolation patterns, and cost models across multiple services, then coordinating with domain experts to validate integration points, the human has a detailed starting point with documentation-grounded, cross-domain recommendations.
The system compressed what might be days or weeks of research and coordination into a six-minute consultation with traceable reasoning. That’s the value proposition: not perfect answers but accelerated time-to-draft that lets human experts focus on refinement rather than initial research.
This progression from single-expert knowledge retrieval to multi-expert collaboration to iterative back-and-forth demonstrates the multi-agent system’s range. Simple questions get fast, accurate answers. Complex problems get the coordinated expertise they need. And questions that span deeply intertwined domains benefit from agents iterating together rather than just handing off once.
Conclusion
Coordinating expertise across multiple domains is a real problem. The expertise exists in organizations. The bottleneck is bringing the right people together quickly. This system augments that coordination by accelerating initial research and draft solution creation.
We modeled the system described in this post on AWS’s actual Advanced Computing team structure: seven domain expert agents, a coordinator that routes questions, and access to current documentation through knowledge bases. The system handles initial research and synthesis. Human experts can then validate and refine. It’s augmentation, not replacement.
The factory digital twin example demonstrates this well: three expert agents collaborated to design an integrated architecture where IoT data collection, spatial visualization, and AI-powered navigation work together. The system compressed what might be days of research and cross-domain coordination into a six-minute consultation with traceable reasoning and validated integration points.
This demonstrates what becomes possible when you combine multi-agent orchestration, real-time knowledge access, and conversation memory. These capabilities can augment how technical teams work—reducing the activation energy to get started on complex problems, maintaining context across conversations, and coordinating distributed expertise.
Ready to explore multi-agent systems for your organization?
- Try the code: The complete implementation is available on Github with deployment instructions and infrastructure code
- Contact AWS: Reach out to your AWS account team or solutions architect for guidance on implementing similar systems
- Specialized support: For agentic AI and advanced computing expertise, ask your account team to connect you with the AWS Advanced Computing – Emerging Technologies team
- Share feedback: We’d love to hear how you’re thinking about multi-agent architectures—leave a comment below