AWS Compute Blog
Operating Lambda: Anti-patterns in event-driven architectures – Part 3
In the Operating Lambda series, I cover important topics for developers, architects, and systems administrators who are managing AWS Lambda-based applications. This three-part section discusses event-driven architectures and how these relate to Lambda-based applications.
Part 1 covers the benefits of the event-driven paradigm and how it can improve throughput, scale, and extensibility. Part 2 explains some of the design principles and best practices that can help developers gain the benefits of building Lambda-based applications. This post explores common anti-patterns in event-driven architectures.
Lambda is not a prescriptive service and provides broad functionality for you to build applications as needed. While this flexibility is important to customers, there are some designs that are technically functional but can sometimes be suboptimal.
The Lambda monolith
In many applications migrated from traditional servers, Amazon EC2 instances or AWS Elastic Beanstalk applications, developers “lift and shift” existing code. Frequently, this results in a single Lambda function that contains all of the application logic that is triggered for all events. For a basic web application, for example, a monolithic Lambda function handles all Amazon API Gateway routes and integrates with all necessary downstream resources:
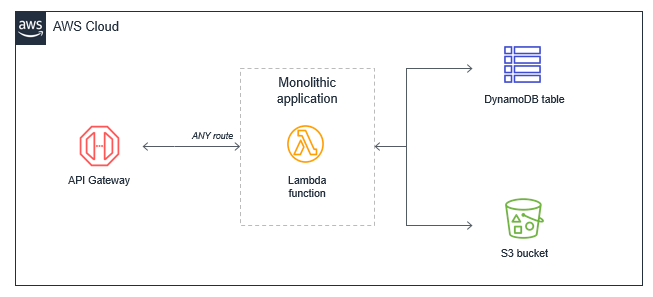
This approach can have several drawbacks:
- Package size: The Lambda function may be much larger because it contains all possible code for all paths, which makes it slower for the Lambda service to download and run.
- Harder to enforce least privilege: The function’s IAM role must grant permissions for all resources needed for all paths, making the permissions very broad. Many paths in the functional monolith do not need all the permissions that have been granted.
- Harder to upgrade: In a production system, any upgrades to the single function are more risky and could cause the entire application to stop working. Upgrading a single path in the Lambda function is an upgrade to the entire function.
- Harder to maintain: It’s more difficult to have multiple developers working on the service since it’s a monolithic code repository. It also increases the cognitive burden on developers and makes it harder to create appropriate test coverage for code.
- Harder to reuse code: Typically, it can be harder to separate libraries from monoliths, making code reuse more difficult. As you develop and support more projects, this can make it harder to support the code and scale your team’s velocity.
- Harder to test: As the lines of code increase, it becomes harder to unit all the possible combinations of inputs and entry points in the code base. It’s generally easier to implement unit testing for smaller services with less code.
The alternative is to decompose the monolithic Lambda function into individual microservices, mapping a single Lambda function to a single, well-defined task. In this example web application with a few API endpoints, the resulting microservice-based architecture is based on the API routes.

The process of decomposing a monolith depends upon the complexity of your workload. Using strategies like the strangler pattern, you can migrate code from larger code bases to microservices. There are many potential benefits to running a Lambda-based application this way:
- Package sizes can be optimized for only the code needed for a single task, which helps make the function more performant, and may reduce running cost.
- IAM roles can be scoped to precisely the access needed by the microservice, making it easier to enforce the principles of least privilege. In controlling the blast radius, using IAM roles this way can give your application a stronger security posture.
- Easier to upgrade: you can apply upgrades at a microservice level without impacting the entire workload. Upgrades occur at the functional level, not at the application level, and you can implement canary releases to control the rollout.
- Easier to maintain: adding new features is usually easier when working with a single small service than a monolithic with significant coupling. Frequently, you implement features by adding new Lambda functions without modifying existing code.
- Easier to reuse code: when you have specialized functions that perform a single task, it’s often easier to copy these across multiple projects. Building a library of generic specialized functions can help accelerate development in future projects.
- Easier to test: unit testing is easier when there are few lines of code and the range of potential inputs for a function is smaller.
- Lower cognitive load for developers since each development team has a smaller surface area of the application to understand. This can help accelerate onboarding for new developers.
To learn more, read “Decomposing the Monolith with Event Storming”.
Lambda as orchestrator
Many business workflows result in complex workflow logic, where the flow of operations depends on multiple factors. In an ecommerce example, a payments service is an example of a complex workflow:
- A payment type may be cash, check, or credit card, all of which have different processes.
- A credit card payment has many possible states, from successful to declined.
- The service may need to issue refunds or credits for a portion or the entire amount.
- A third-party service that processes credit cards may be unavailable due to an outage.
- Some payments may take multiple days to process.
Implementing this logic in a Lambda function can result in ‘spaghetti code’ that’s different to read, understand, and maintain. It can also become fragile in production systems. The complexity is compounded if you must handle error handling, retry logic, and inputs and outputs processing. These types of orchestration functions are an anti-pattern in Lambda-based applications.
Instead, use AWS Step Functions to orchestrate these workflows using a versionable, JSON-defined state machine. State machines can handle nested workflow logic, errors, and retries. A workflow can also run for up to 1 year, and the service can maintain different versions of workflows, allowing you to upgrade production systems in place. Using this approach also results in less custom code, making an application easier to test and maintain.
While Step Functions is generally best-suited for workflows within a bounded context or microservice, to coordinate state changes across multiple services, instead use Amazon EventBridge. This is a serverless event bus that routes events based upon rules, and simplifies orchestration between microservices.
Recursive patterns that cause invocation loops
AWS services generate events that invoke Lambda functions,and Lambda functions can send messages to AWS services. Generally, the service or resource that invokes a Lambda function should be different to the service or resource that the function outputs to. Failure to manage this can result in invocation loops.
For example, a Lambda function writes an object to an Amazon S3 object, which in turn invokes the same Lambda function via a put event. The invocation causes a second object to be written to the bucket, which invokes the same Lambda function:

While the potential for infinite loops exists in most programming languages, this anti-pattern has the potential to consume more resources in serverless applications. Both Lambda and S3 automatically scale based upon traffic, so the loop may cause Lambda to scale to consume all available concurrency and S3 to continue to write objects and generate more events for Lambda. In this situation, you can press the “Throttle” button in the Lambda console to scale the function concurrency down to zero and break the recursion cycle.
This example uses S3 but the risk of recursive loops also exists in Amazon SNS, Amazon SQS, Amazon DynamoDB, and other services. In most cases, it is safer to separate the resources that produce and consume events from Lambda. However, if you need a Lambda function to write data back to the same resource that invoked the function, ensure that you:
- Use a positive trigger: For example, an S3 object trigger may use a naming convention or meta tag that is only triggered on the first invocation. This prevents objects written from the Lambda function from invoking the same Lambda function again. See the S3-to-Lambda translation application for an example of this mechanism.
- Use reserved concurrency: Setting the function’s reserved concurrency to a lower limit prevents the function from scaling concurrently beyond that limit. It does not prevent the recursion, but limits the resources consumed as a safety mechanism. This can be useful during the development and test phases.
- Use Amazon CloudWatch monitoring and alarming: By setting an alarm on a function’s concurrency metric, you can receive alerts if the concurrency suddenly spikes and take appropriate action.
Lambda functions calling Lambda functions
Functions enable encapsulation and code reuse. Most programming languages support the concept of code synchronously calling functions within a code base. In this case, the caller waits until the function returns a response. In many cases, this model does not adapt well to serverless development.
For example, consider a simple ecommerce application consisting of three Lambda functions that process an order:

In this case, the Create order function calls the Process payment function, which in turn calls the Create invoice function. While this synchronous flow may work within a single application on a server, it introduces several avoidable problems in a distributed serverless architecture:
- Cost: With Lambda, you pay for the duration of an invocation. In this example, while the Create invoice functions runs, two other functions are also running in a wait state, shown in red on the diagram.
- Error handling: In nested invocations, error handling can become more complex. Either errors are thrown to parent functions to handle at the top-level function, or functions require custom handling. For example, an error in Create invoice might require the Process payment function to reverse the charge, or it may instead retry the Create invoice process.
- Tight coupling: Processing a payment typically takes longer than creating an invoice. In this model, the availability of the entire workflow is limited by the slowest function.
- Scaling: The concurrency of all three functions must be equal. In a busy system, this uses more concurrency than would otherwise be needed.
In serverless applications, there are two common approaches to avoid this pattern. First, use an SQS queue between Lambda functions. If a downstream process is slower than an upstream process, the queue durably persists messages and decouples the two functions. In this example, the Create order function publishes a message to an SQS queue, and the Process payment function consumes messages from the queue.
The second approach is to use AWS Step Functions. For complex processes with multiple types of failure and retry logic, Step Functions can help reduce the amount of custom code needed to orchestrate the workflow. As a result, Step Functions orchestrates the work and robustly handles errors and retries, and the Lambda functions contain only business logic.
Synchronous waiting within a single Lambda function
Within a single Lambda, ensure that any potentially concurrent activities are not scheduled synchronously. For example, a Lambda function might write to an S3 bucket and then write to a DynamoDB table: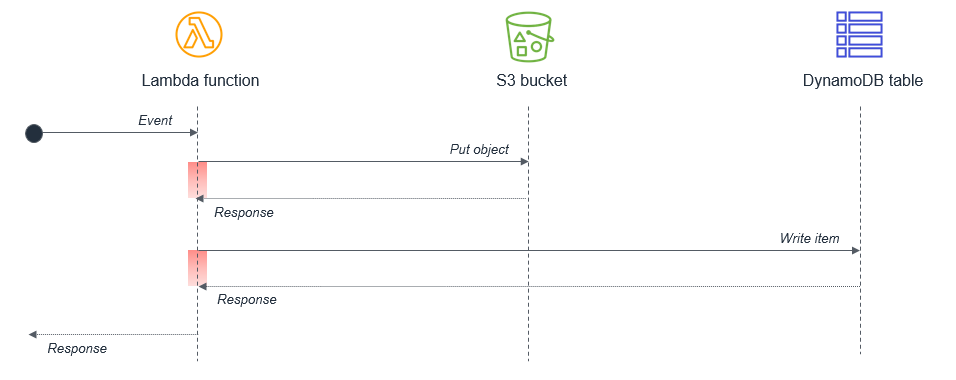
The wait states, shown in red in the diagram, are compounded because the activities are sequential. If the tasks are independent, they can be run in parallel, which results in the total wait time being set by the longest-running task.
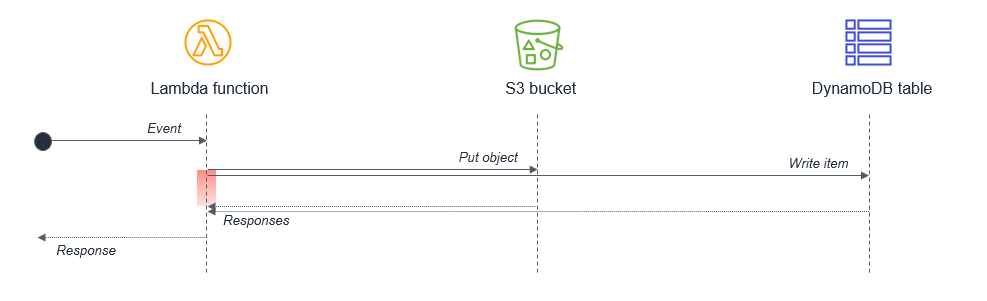
In cases where the second task depends on the completion of the first task, you may be able to reduce the total waiting time and the cost of execution by splitting the Lambda functions:

In this design, the first Lambda function responds immediately after putting the object to the S3 bucket. The S3 service invokes the second Lambda function, which then writes data to the DynamoDB table. This approach minimizes the total wait time in the Lambda function executions.
To learn more, read the “Serverless Applications Lens” from the AWS Well-Architected Framework.
Conclusion
This post discusses common anti-patterns in event-driven architectures using Lambda. I show some of the issues when using monolithic Lambda functions or custom code to orchestrate workflows. I explain how to avoid recursive architectures that may cause invocation loops and why you should avoid calling functions from functions. I also explain different approaches to handling waiting in functions to minimize cost.
For more serverless learning resources, visit Serverless Land.