AWS Compute Blog
Operating Lambda: Design principles in event-driven architectures – Part 2
In the Operating Lambda series, I cover important topics for developers, architects, and systems administrators who are managing AWS Lambda-based applications. This three-part section discusses event-driven architectures and how these relate to Lambda-based applications.
Part 1 covers the benefits of the event-driven paradigm and how it can improve throughput, scale and extensibility. This post explains some of the design principles and best practices that can help developers gain the benefits of building Lambda-based applications.
Overview
Many of the best practices that apply to software development and distributed systems also apply to serverless application development. The broad principles are consistent with the Well-Architected Framework. The overall goal is to develop workloads that are:
- Reliable: offering your end users a high level of availability. AWS serverless services are reliable because they are also designed for failure.
- Durable: providing storage options that meet the durability needs of your workload.
- Secure: following best practices and using the tools provided to secure access to workloads and limit the blast radius, if any issues occur.
- Performant: using computing resources efficiently and meeting the performance needs of your end users.
- Cost-efficient: designing architectures that avoid unnecessary cost that can scale without overspending, and also be decommissioned, if necessary, without significant overhead.
When you develop Lambda-based applications, there are several important design principles that can help you build workloads that meet these goals. You may not apply every principle to every architecture and you have considerable flexibility in how you approach building with Lambda. However, they should guide you in general architecture decisions.
Use services instead of custom code
Serverless applications usually comprise several AWS services, integrated with custom code run in Lambda functions. While Lambda can be integrated with most AWS services, the services most commonly used in serverless applications are:
| Category | AWS service |
| Compute | AWS Lambda |
| Data storage | Amazon S3
Amazon DynamoDB Amazon RDS |
| API | Amazon API Gateway |
| Application integration | Amazon EventBridge
Amazon SNS Amazon SQS |
| Orchestration | AWS Step Functions |
| Streaming data and analytics | Amazon Kinesis Data Firehose |
There are many well-established, common patterns in distributed architectures that you can build yourself or implement using AWS services. For most customers, there is little commercial value in investing time to develop these patterns from scratch. When your application needs one of these patterns, use the corresponding AWS service:
| Pattern | AWS service |
| Queue | Amazon SQS |
| Event bus | Amazon EventBridge |
| Publish/subscribe (fan-out) | Amazon SNS |
| Orchestration | AWS Step Functions |
| API | Amazon API Gateway |
| Event streams | Amazon Kinesis |
These services are designed to integrate with Lambda and you can use infrastructure as code (IaC) to create and discard resources in the services. You can use any of these services via the AWS SDK without needing to install applications or configure servers. Becoming proficient with using these services via code in your Lambda functions is an important step to producing well-designed serverless applications.
Understanding the level of abstraction
The Lambda service limits your access to the underlying operating systems, hypervisors, and hardware running your Lambda functions. The service continuously improves and changes infrastructure to add features, reduce cost and make the service more performant. Your code should assume no knowledge of how Lambda is architected and assume no hardware affinity.
Similarly, the integration of other services with Lambda is managed by AWS with only a small number of configuration options exposed. For example, when API Gateway and Lambda interact, there is no concept of load balancing available since it is entirely managed by the services. You also have no direct control over which Availability Zones the services use when invoking functions at any point in time, or how and when Lambda execution environments are scaled up or destroyed.
This abstraction allows you to focus on the integration aspects of your application, the flow of data, and the business logic where your workload provides value to your end users. Allowing the services to manage the underlying mechanics helps you develop applications more quickly with less custom code to maintain.
Implementing statelessness in functions
When building Lambda functions, you should assume that the environment exists only for a single invocation. The function should initialize any required state when it is first started – for example, fetching a shopping cart from a DynamoDB table. It should commit any permanent data changes before exiting to a durable store such as S3, DynamoDB, or SQS. It should not rely on any existing data structures or temporary files, or any internal state that would be managed by multiple invocations (such as counters or other calculated, aggregate values).
Lambda provides an initializer before the handler where you can initialize database connections, libraries, and other resources. Since execution environments are reused where possible to improve performance, you can amortize the time taken to initialize these resources over multiple invocations. However, you should not store any variables or data used in the function within this global scope.
Lambda function design
Most architectures should prefer many, shorter functions over fewer, larger ones. Making Lambda functions highly specialized for your workload means that they are concise and generally result in shorter executions. The purpose of each function should be to handle the event passed into the function, with no knowledge or expectations of the overall workflow or volume of transactions. This makes the function agnostic to the source of the event with minimal coupling to other services.
Any global-scope constants that change infrequently should be implemented as environment variables to allow updates without deployments. Any secrets or sensitive information should be stored in AWS Systems Manager Parameter Store or AWS Secrets Manager and loaded by the function. Since these resources are account-specific, this allows you to create build pipelines across multiple accounts. The pipelines load the appropriate secrets per environment, without exposing these to developers or requiring any code changes.
Building for on-demand data instead of batches
Many traditional systems are designed to run periodically and process batches of transactions that have built up over time. For example, a banking application may run every hour to process ATM transactions into central ledgers. In Lambda-based applications, the custom processing should be triggered by every event, allowing the service to scale up concurrency as needed, to provide near-real time processing of transactions.
While you can run cron tasks in serverless applications by using scheduled expressions for rules in Amazon EventBridge, these should be used sparingly or as a last-resort. In any scheduled task that processes a batch, there is the potential for the volume of transactions to grow beyond what can be processed within the 15-minute Lambda timeout. If the limitations of external systems force you to use a scheduler, you should generally schedule for the shortest reasonable recurring time period.
For example, it’s not best practice to use a batch process that triggers a Lambda function to fetch a list of new S3 objects. This is because the service may receive more new objects in between batches than can be processed within a 15-minute Lambda function.
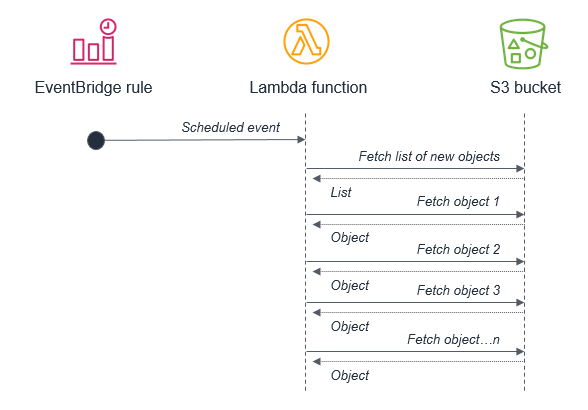
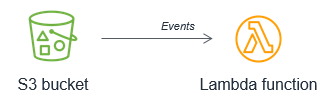
Instead, the Lambda function should be invoked by the S3 service each time a new object is put into the S3 bucket. This approach is significantly more scalable and also invokes processing in near-real time.
Orchestrating workflows
Workflows that involve branching logic, different types of failure models and retry logic typically use an orchestrator to keep track of the state of the overall execution. Avoid using Lambda functions for this purpose, since it results in tightly coupled groups of functions and services and complex code handling routing and exceptions.
With AWS Step Functions, you use state machines to manage orchestration. This extracts the error handling, routing, and branching logic from your code, replacing it with state machines declared using JSON. Apart from making workflows more robust and observable, it allows you to add versioning to workflows and make the state machine a codified resource that you can add to a code repository.
It’s common for simpler workflows in Lambda functions to become more complex over time, and for developers to use a Lambda function to orchestrate the flow. When operating a production serverless application, it’s important to identify when this is happening, so you can migrate this logic to a state machine.
Developing for retries and failures
AWS serverless services, including Lambda, are fault-tolerant and designed to handle failures. In the case of Lambda, if a service invokes a Lambda function and there is a service disruption, Lambda invokes your function in a different Availability Zone. If your function throws an error, the Lambda service retries your function.
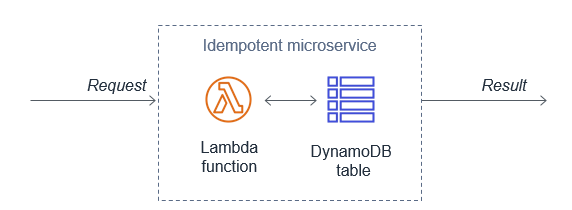
Since the same event may be received more than once, functions should be designed to be idempotent. This means that receiving the same event multiple times does not change the result beyond the first time the event was received.
For example, if a credit card transaction is attempted twice due to a retry, the Lambda function should process the payment on the first receipt. On the second retry, either the Lambda function should discard the event or the downstream service it uses should be idempotent.
A Lambda function implements idempotency typically by using a DynamoDB table to track recently processed identifiers to determine if the transaction has been handled previously. The DynamoDB table usually implements a Time To Live (TTL) value to expire items to limit the storage space used.
For failures within the custom code of a Lambda function, the service offers a number of features to help preserve and retry the event, and provide monitoring to capture that the failure has occurred. Using these approaches can help you develop workloads that are resilient to failure and improve the durability of events as they are processed by Lambda functions.
Conclusion
This post discusses the design principles that can help you develop well-architected serverless applications. I explain why using services instead of code can help improve your application’s agility and scalability. I also show how statelessness and function design also contribute to good application architecture. I cover how using events instead of batches helps serverless development, and how to plan for retries and failures in your Lambda-based applications.
Part 3 of this series looks at common anti-patterns in event-driven architectures and how to avoid building these into your microservices.
For more serverless learning resources, visit Serverless Land.