AWS Database Blog
Build aggregations for Amazon DynamoDB tables using Amazon DynamoDB Streams
Amazon DynamoDB is a key-value database that delivers single-digit-millisecond performance at any scale. In transactional applications, developers who prioritize Key-Value operations often place significant importance on retrieving results with minimal latency. This holds true even when dealing with composite primary keys that consist of a partition and a sort key. The additional functionalities offered by relational databases, such as complex queries, ad hoc queries, joins, and aggregations, are often considered as overhead in these scenarios. The white paper Amazon DynamoDB – a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications dives deep into the architecture decisions made while designing Amazon DynamoDB.
Regardless of the access patterns that your application might have, you can still perform aggregations while working with Amazon DynamoDB. For instance, you can export the data to Amazon Simple Storage Service (Amazon S3) and utilize tools such as Amazon Athena for performing aggregations. Alternatively, you can load the data into data warehousing solutions like Amazon Redshift and run aggregations remotely. Another option is to perform a scan on the table to calculate counts, maximums, minimums, and sums. However, depending of the frequency of your queries, this approach can be costly due to the expenses incurred from retrieving all items in the table, which depend on their number and size. As a result, developers often employ different techniques to achieve aggregations based on specific use cases and requirements.
In this post, we discuss how to perform aggregations on a DynamoDB table using Amazon DynamoDB Streams and AWS Lambda. The content includes a reference architecture, a step-by-step guide on enabling DynamoDB Streams for a table, sample code for implementing the solution within a scenario, and an accompanying AWS CloudFormation template for easy deployment and testing.
Solution overview
Imagine a scenario where we have a retail company called AnyCompany, specializing in the sale of books and stationary items. The business stakeholders at AnyCompany have a pressing need to track the real-time sales of specific items. Let’s take the example of a newly released book. By having immediate access to the number of units sold, they can accurately monitor inventory levels and promptly respond to the demand for the book. This valuable insight empowers them to take proactive measures, ensuring they have sufficient stock on hand to meet customer demands and optimize their operations effectively.
The following figure shows the overview architecture of the solution.

The workflow includes the following steps:
- A new item is created or inserted via Amazon API Gateway into the DynamoDB table.
- A new entry to the DynamoDB Stream is processed, representing the mutation of an item.
- Lambda polls the configured DynamoDB Stream 4 times per second, if the filter criteria is met the function runs.
- The Lambda function performs the required aggregation logic and inserts the data into the target DynamoDB table (Which could also be the same table).
Based on the scenario that we have discussed earlier and for simplicity, we use the following two tables:
- Order_by_item – This table is used to capture the orders and order details, in the diagram is represented by the first table on the left. The following image shows a snippet of the table attributes from NoSQL workbench.

- Item_count_by_date – This table stores the aggregated data—the number of items that are placed on a given day, in the diagram is represented by the table on the right

We implement the solution with the following steps:
- Create the source DynamoDB table and enable DynamoDB streams.
- Create the target DynamoDB table.
- Set up AWS Identity and Access Management (IAM) permission for the Lambda function.
- Deploy the Lambda function.
- Enable trigger for the source table.
- Configure Lambda function to add environment variables and filter criteria.
- Insert a new item into the source table to trigger the lambda function and verify the aggregated data on the target table.
If you are using CloudFormation template you can go directly to Step 7 (Insert a new record into the source table to trigger the lambda function and verify the aggregated data on the target table) and test the solution.
Prerequisites
To complete this walk through, you must have the following prerequisites:
- An active AWS account. To sign up, see Set Up an AWS Account and Create a User.
- The AWS CLI installed.
- The visual editor of your choice, for example Visual Studio Code.
- Install CloudFormation template to quickly deploy and test the solution. Follow the steps that are mentioned in this link to deploy the stack.
- Permissions to deploy an DynamoDB table and an AWS Lambda function.
Create the source DynamoDB table and enable streams
In this step, we create a DynamoDB table to store the order ID, order date, item number, quantity, and price per item. The primary key for this table is the orderid, and the sort key is the order_date. You can create the table using the DynamoDB console, AWS Command Line Interface (AWS CLI), or any AWS SDK. Capture the TableArn in the output, we will be using it for creating the IAM policy.
For Linux or mac:
For Windows:
Create the target DynamoDB table
In this step, we create the target DynamoDB table where we capture the count of each item that has been sold for the current day and the past days since the solution has been deployed. Capture the TableArn in the output, we will be using it for creating the IAM policy.
For Linux or mac:
For Windows:
Set up IAM permission for the Lambda function
In this step, we set up the necessary permissions that are required for the Lambda function to process the records in the streams and load it to the target table.
First, create an IAM role and attach the policies AWSLambdaDynamoDBExecutionRole and AWSLambdaBasicExecutionRole to the new role:
To limit access to only read and write actions, you can create a custom policy that only grants permissions to the dynamodb:PutItem, dynamodb:GetItem, dynamodb:UpdateItem, dynamodb:DeleteItem, and dynamodb:Query actions. This will provide more fine-grained control over access to the table.
- Create a file
policy.jsonand copy the below JSON to the file. ReplaceSource_table_arnandTarget_table_arnwith the actualTableArnthat we have saved when creating the tables. - Create a policy
MyDynamoDBPolicyusing the following command. Save the policy arn from the output, as it is required to attach the policy to theddb_lambda_rolerole: - Attach the policy
MyDynamoDBPolicyto the roleddb_lambda_roleusing the following command:
Deploy the Lambda function to perform the aggregation and load it to a target table
The Lambda function AggregateFunctions counts the quantity of an item for any order that is received. The target table has order_date as the partition key and item_number as the sort key. Deploy the Lambda function
- Open the Functions page of AWS Lambda console.
- Choose Create function. Enter function name
AggregateFunctions, RuntimePython3.10, and chooseddb_lamda_role

- Copy and paste the following code in
lambda_function.pyand save the function and deploy the function.
Create a trigger for the source table
To create a trigger for the source table, complete the following steps:
- On the DynamoDB console, navigate to the source table
Order_by_item. - On the Exports and streams tab, in the Trigger section, choose Create trigger.
- For Lambda function, enter the function that you deployed earlier.
- For Batch size, enter a value 10 (Since we are testing the solution with less than 10 records) for this scenario.
- Select Turn on trigger.
- Choose Create trigger.
Configure Lambda function to add environment variables and filter criteria
Now we create two variables source_table_name and target_table_name using the following steps:
- Open the Functions page of AWS Lambda console.
- Select the
AggregateFunctionsfunction. - Choose the configuration tab, select Environment variables and choose Edit.
- Choose add environment variable, add
source_table_namein key andOrder_by_itemin Value - And click Add environament variable to enter
target_table_namein key anditem_count_by_tablein Value and Save.
- Choose add environment variable, add
Add the filtercriteria for the lambda function to trigger only when there is an Insert or Modify event type and ignore rest of the event types that are present in the DynamoDB Stream.
- Locate the Triggers tab under Configuration.
- Select the exiting trigger for
Order_by_itemand choose edit.

- Select the Additional settings, in Filter criteria section add
{"eventName": ["INSERT", "MODIFY"]}and Save.

Insert a new record into the source table to trigger the lambda function which performs the aggregation.
- Insert test items to the source DynamoDB table and verify the aggregated data based on Item in the target table.
For Linux or Mac:For Windows:
The following image shows how the table data would look like after the insert statements in NoSQL Workbench.

- Verify if the target table has the aggregated data using AWS CLI:
For Linux or Mac:Response:
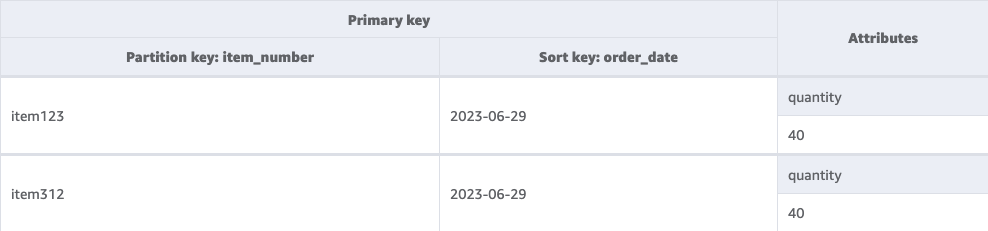
The following image is how the item_count_by_date table which contains the aggregated data in NoSQL Workbench.
Clean Up
To prevent incurring future expenses, after testing the solution, ensure resource deletion by following the steps below:
- If you have used the CloudFormation template follow the steps mentioned in this link to delete the resources.
- Delete the Lambda function AggregateFunctions by running the following command:
- Delete the DynamoDB tables
Order_by_itemanditem_count_by_dateby running the following command:
Conclusion
In this post, we showed how to build aggregations on data stored in DynamoDB tables using DynamoDB Streams and Lambda. DynamoDB Streams provides an easy integration point to retrieve changed data without needing to query your table. Lambda provides a serverless, event-driven mechanism to update counts and aggregates for more efficient retrieval later. Together, these tools offer a simple and effective way to implement real-time aggregations with DynamoDB.
Test the procedure that is outlined in this post by deploying the sample code provided and share your feedback in the comments section. Use this CloudFormation template to deploy the solution for testing.
We have adapted the concepts from this post into a deployable solution, now available as Guidance for Processing Real-Time Data Using Amazon DynamoDB in the AWS Solutions Library. To get started, review the architecture diagrams and the corresponding AWS Well-Architected framework, then deploy the sample code to implement the Guidance into your workloads.
About the author
 Rajesh Kantamani is a Senior Database Specialist SA. He specializes in assisting customers with designing, migrating, and optimizing database solutions on Amazon Web Services, ensuring scalability, security, and performance. In his spare time, he loves spending time outdoors with family and friends.
Rajesh Kantamani is a Senior Database Specialist SA. He specializes in assisting customers with designing, migrating, and optimizing database solutions on Amazon Web Services, ensuring scalability, security, and performance. In his spare time, he loves spending time outdoors with family and friends.