Blog de Amazon Web Services (AWS)
Exportando métricas de Amazon Connect a Databricks usando Kinesis Data Firehose
Por Oriol Matavacas Rodriguez, Senior Solutions Architect en AWS.
Introducción
Las organizaciones que utilizan Amazon Connect necesitan, a menudo, combinar las métricas de llamadas con datos de otros sistemas de negocio en plataformas de análisis externas. Correlacionar registros de contacto con datos de CRM, pipelines de ventas o bases de datos operativas que residen en Databricks es un requisito habitual para equipos de analítica y operaciones.
Amazon Connect ofrece un análisis nativo que almacena datos en buckets de Amazon Simple Storage Service (Amazon S3) gestionados por AWS. Sin embargo, acceder a estos datos desde plataformas externas como Databricks no está soportado de forma directa, debido a las limitaciones de distribución de credenciales de AWS Lake Formation sobre buckets gestionados internamente.
En este artículo, presentamos un patrón de integración que utiliza el data streaming de Amazon Connect, Amazon Kinesis Data Streams, Amazon Data Firehose, Amazon S3, AWS Glue y Lake Formation para exportar registros de contacto (contact records) y eventos de agentes (agent events) a un bucket de S3 propio del cliente. Una vez los datos se encuentran en el bucket propio, Databricks puede consultarlos a través de la federación de Hive Metastore (Hive Metastore Federation) con AWS Glue Data Catalog. Esto permite realizar analítica unificada sobre los datos del centro de contacto y los datos de negocio en un único workspace de Databricks.
Arquitectura de la solución
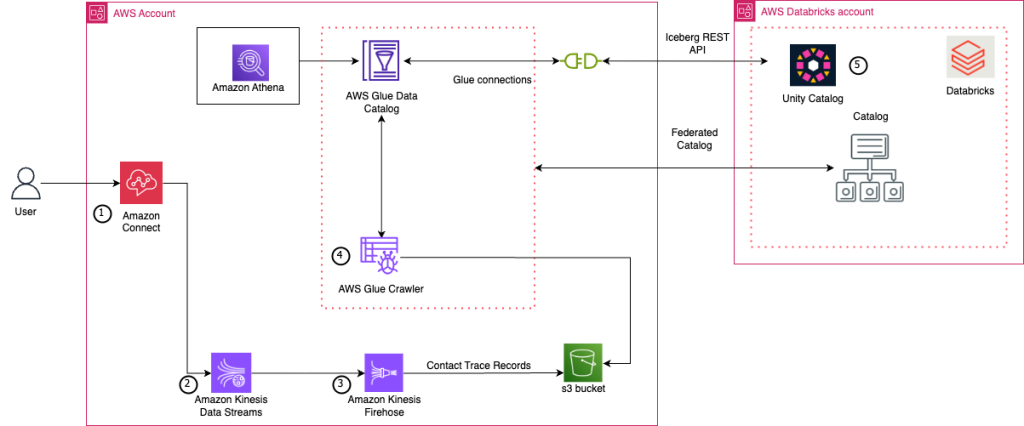
Figura 1 – Arquitectura de la solución.
El flujo de datos de esta solución sigue los siguientes pasos:
- Amazon Connect genera registros de contacto (contact records) y eventos de agentes (agent events) a partir de la actividad del centro de contacto.
- Amazon Kinesis Data Streams recibe los datos en tiempo real desde Amazon Connect mediante la funcionalidad de data streaming.
- Amazon Data Firehose consume los datos del stream de Kinesis y los entrega en formato JSON al bucket de Amazon S3 del cliente.
- AWS Glue Crawler lee el bucket de S3 periódicamente y registra los esquemas de las tablas en el AWS Glue Data Catalog.
- Databricks Unity Catalog accede a las tablas del Glue Data Catalog a través de la federación de Hive Metastore para AWS Glue, lo que permite consultar los datos directamente desde el SQL Editor de Databricks.
Esta arquitectura proporciona varios beneficios clave:
- Propiedad de los datos: los datos residen en buckets de S3 que tú controlas, lo que facilita la integración con cualquier plataforma de analítica.
- Procesamiento en tiempo real: la réplica es continua gracias a Kinesis Data Streams y Firehose, con latencia de segundos a minutos.
- Escalabilidad: todos los servicios son serverless y escalan automáticamente en función del volumen de contactos.
- Gobernanza centralizada: AWS Glue Data Catalog y Lake Formation ofrecen un punto centralizado de gobernanza de metadatos y permisos en AWS, mientras que en Databricks se gestiona desde Databricks Unity Catalog.
Implementación
Paso 1 – Requisitos previos
Para seguir esta guía, necesitarás:
- Una cuenta de AWS con permisos para crear recursos en Amazon Connect, Amazon Kinesis, Amazon Data Firehose, Amazon S3, AWS Glue, AWS Lake Formation e IAM.
- Un workspace de Databricks en AWS con permisos de administrador del Unity Catalog.
- Los buckets de Amazon S3, la instancia de Amazon Connect y el workspace de Databricks deben estar en la misma Región de AWS.
Paso 2 – Crear la instancia de Amazon Connect
Si aún no tienes una instancia de Amazon Connect, sigue los pasos de la documentación oficial para crear una instancia de Amazon Connect
Paso 3 – Reclamar un número de teléfono
Para generar registros de contacto, necesitas un número de teléfono asignado a tu instancia.
- Desde la consola de Amazon Connect, selecciona tu instancia y accede con credenciales de administrador.
- En el panel izquierdo, selecciona Channels → Phone numbers.
- Selecciona Claim a number. Para hacer una prueba rápida, dentro de la opción Toll Free, elige el país (por ejemplo, España). Selecciona alguno de los números propuestos.
- Selecciona el flujo Sample inbound flow (first contact experience) y luego Save para guardar el número. Este flujo es suficiente para realizar las pruebas iniciales.
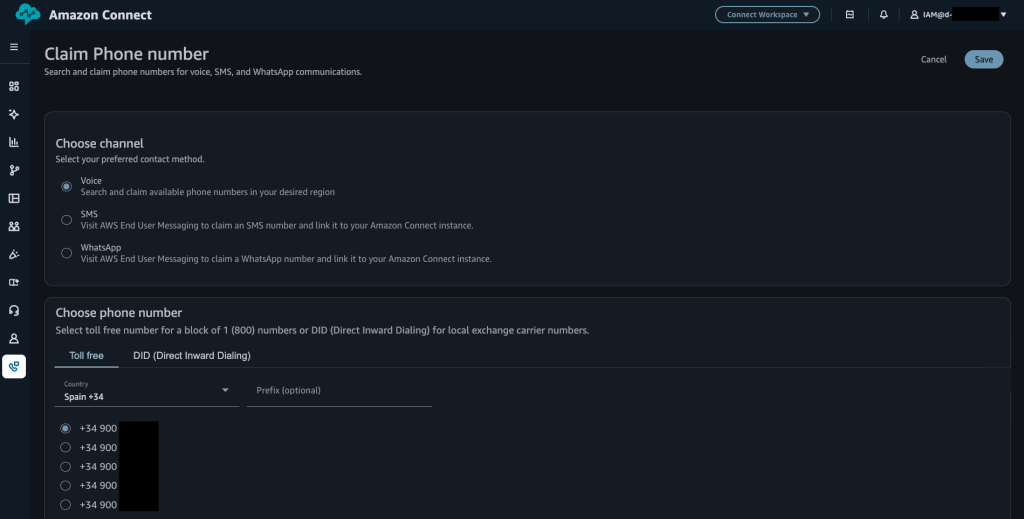
Figura 2 – Asignación de un número de teléfono toll free a la instancia de Amazon Connect.
Para más información, consulta la documentación sobre cómo reclamar un número de teléfono.
Paso 4 – Crear los buckets de Amazon S3
Esta solución requiere un bucket de Amazon S3 en la misma Región donde se encuentra la instancia de Amazon Connect y el workspace de Databricks.
| Bucket | Propósito | Quién escribe | Quién lee |
|---|---|---|---|
| myproject-connectdata-<randomnumber> | Almacena los registros de contacto (CTR) entregados por Amazon Data Firehose | Amazon Data Firehose | AWS Glue Crawler, Databricks |
Para más información sobre la creación de buckets, consulta Creating a general purpose bucket en la documentación de Amazon S3.
Paso 5 – Crear el Kinesis Data Stream
Amazon Connect envía los datos de contacto y eventos de agente a un stream de Kinesis. Crea un stream de capacidad On-demand para que el stream escale automáticamente. Deja todas las configuraciones por defecto.
Para más detalles, consulta la documentación sobre cómo crear un stream con la consola.
Paso 6 – Crear el stream de Amazon Data Firehose
Amazon Data Firehose consume los datos del Kinesis Data Stream y los entrega en el bucket de S3.
Crea un stream de Amazon Data Firehose con los siguientes parámetros:
- En Source (Origen), selecciona Amazon Kinesis Data Streams.
- En Destination (Destino), selecciona Amazon S3.
- En Source Settings, selecciona el Data Stream creado en el paso anterior.
- En Destination Settings, selecciona el bucket myproject-connect-data-<randomnumber>.
- Deja el resto de configuraciones por defecto y selecciona Create Firehose stream.
Para más información, consulta cómo elegir origen y destino para un stream de Firehose.
Paso 7 – Habilitar el data streaming en Amazon Connect
Configura Amazon Connect para enviar los registros de contacto y los eventos de agentes al Kinesis Data Stream.
- Abre la consola de Amazon Connect.
- Selecciona la instancia que creaste anteriormente.
- En el panel de navegación, selecciona Data streaming.
- Selecciona Enable data streaming (Habilitar transmisión de datos).
- Selecciona Kinesis Stream:
- En Contact records (Registros de contacto): Elige el stream creado en el paso 5.
- En Agent Events (Eventos de agentes): Elige el stream creado en el paso 5.
- Selecciona Save (Guardar).
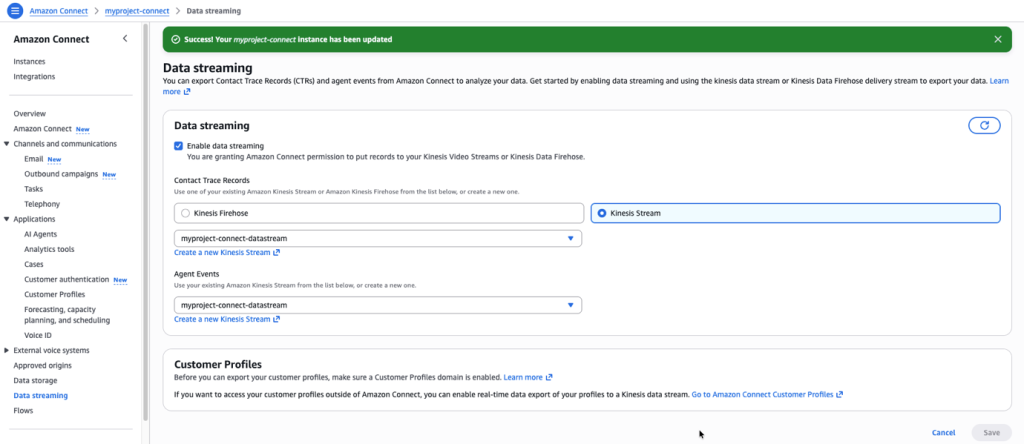
Figura 3 – Data streaming habilitado en Amazon Connect, configurado para enviar registros de contacto y eventos de agentes al Kinesis Data Stream.
Para más información, consulta habilitar data streaming para tu instancia de Amazon Connect.
Nota: Realiza una o varias llamadas de prueba al número de teléfono asignado y sigue las instrucciones para hablar con un agente, esto generará registros de contacto. Estos datos son necesarios en los pasos posteriores para verificar que la integración funciona correctamente.
Paso 8 – Crear una external location para cada bucket de S3 (AWS Quickstart)
Databricks necesita una external location para acceder a los datos de S3 en una cuenta externa.
- En el workspace de Databricks, selecciona Catalog en el panel de navegación lateral.
- Del símbolo +, selecciona Create External Location.
- Selecciona AWS Quickstart (Recommended). Databricks lanza un stack de AWS CloudFormation los recursos necesarios para acceder al bucket de S3.
- Sigue las instrucciones del asistente, introduciendo el nombre del bucket creado anteriormente (
myproject-connect-data-<randomnumber>). Selecciona Generate Token y Databricks generará un Personal Access Token que deberás introducir en el template de CloudFormation. - Una vez completado el stack, Databricks registra la external location automáticamente.
- Selecciona el catálogo que accederá a los datos de Amazon Connect. Selecciona el símbolo +, y luego Add Data.
- Selecciona Amazon S3 y elige la external location creada en el paso anterior. Haz click en Preview Table. En caso de obtener un error, selecciona Advanced attributes, y selecciona manualmente el formato del fichero a JSON.
- Haz click en Create table.
Ahora podrás acceder a los datos de Amazon Connect desde la plataforma de datos de Databricks.
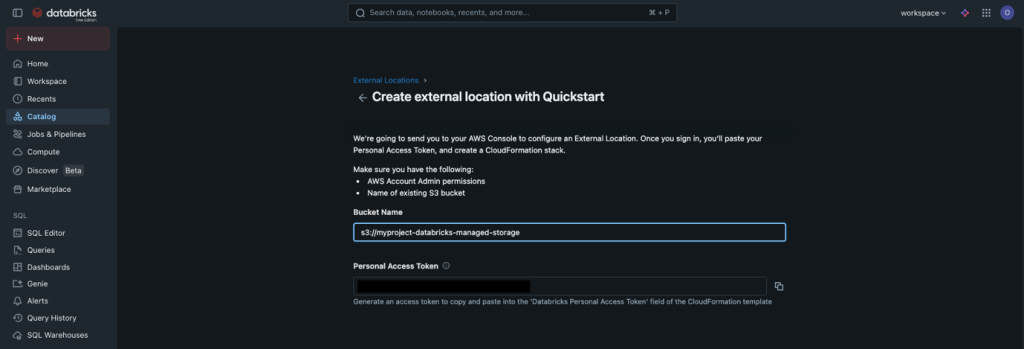
Figura 4 – Selección de la opción AWS Quickstart para crear una external location en Databricks. Esta opción automatiza la creación de los recursos de IAM necesarios mediante AWS CloudFormation.
Limpieza
Para evitar cargos no deseados, elimina los recursos creados durante esta guía en el siguiente orden:
- Databricks: elimina la external location y la credencial de servicio.
- AWS CloudFormation: elimina los stacks creados por AWS Quickstart durante la creación de las external locations.
- Amazon Connect: deshabilita el data streaming y, si no necesitas la instancia, elimínala.
- Amazon Data Firehose: elimina el stream de Firehose.
- Amazon Kinesis: elimina el data stream.
- AWS Glue: elimina el crawler, las tablas y la base de datos del Data Catalog.
- Amazon S3: vacía y elimina el bucket (
myproject-connect-data).
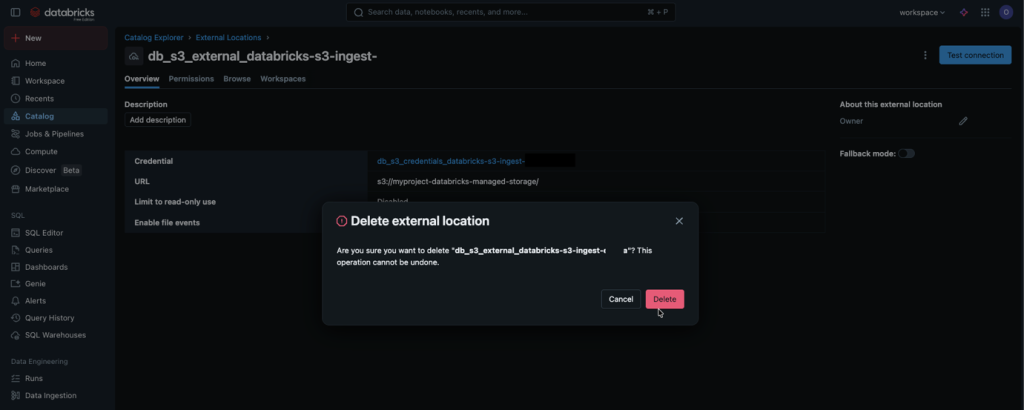
Figura 5 – Borrado de la external location en Databricks

Figura 6 – Borrado del Stack CloudFormation en la consola de AWS
Conclusión
En este artículo, mostramos cómo exportar métricas de llamadas de Amazon Connect a Databricks utilizando Amazon Kinesis Data Streams, Amazon Data Firehose, Amazon S3 y AWS Glue. Esta solución te permite ser propietario de los datos de tu centro de contacto en buckets de S3 que controlas, lo que facilita la integración con plataformas de analítica externas como Databricks.
El principal beneficio de esta arquitectura es que habilita la analítica unificada: puedes correlacionar métricas de llamadas con datos de CRM, ventas o sistemas operativos en un único workspace de Databricks. Además, la solución es completamente serverless, escala automáticamente según el volumen de contactos y sigue el principio de permisos mínimos para garantizar la seguridad del acceso a los datos.
Como posibles extensiones de esta solución, considera:
- Crear dashboards en Amazon QuickSight conectados al mismo Glue Data Catalog para visualizar tendencias de contacto.
- Entrenar modelos de machine learning con Amazon SageMaker sobre los datos de contacto almacenados en S3.
- Implementar JOINS entre tablas de contacto y tablas de negocio directamente en Databricks para obtener una visión 360° del cliente.
- Añadir transformaciones en Amazon Data Firehose para convertir los registros a formato Parquet antes de almacenarlos en S3, lo que optimiza el rendimiento de las consultas.
Prueba esta solución hoy usando la capa gratuita de AWS
Para más información sobre los servicios utilizados, consulta los siguientes recursos:
- Modelo de datos de registros de contacto de Amazon Connect
- Eventos de agentes de Amazon Connect
- Habilitar data streaming en Amazon Connect
- Crear y gestionar streams de Amazon Kinesis
- Elegir origen y destino en Amazon Data Firehose
- Crawlers de AWS Glue para poblar el Data Catalog
- Crear general purpose buckets en Amazon S3
- Federación de Hive Metastore para AWS Glue en Databricks
- Federación de catálogo con Databricks Unity Catalog en Lake Formation
Autor
 |
Oriol Matavacas Rodriguez es Senior Solutions Architect en AWS. Ayuda a organizaciones en la adopción estratégica de servicios de AWS, con amplia experiencia en arquitecturas serverless, migración y modernización de plataformas de datos. |