AWS Partner Network (APN) Blog
How to Integrate VMware Cloud on AWS Datastores with AWS Analytics Services
By Balakrishnan Nair, Specialist Solutions Architect at AWS
By Kiran Reid, Partner Solutions Architect at AWS
 |
Customers who run VMware on-premises are incorporating VMware Cloud on AWS into their hybrid cloud strategy due to the immense benefits of using the AWS Global Infrastructure.
AWS Analytics Services, meanwhile, have provided customers with a means to gain business value from data located in their enterprise databases, data lakes, and log files repositories.
The main logic of any data analytics solution is to:
- Get the data from the source in its raw format. This can be text, numeric, or video files.
- Organize the data into storage solutions such as databases or data lakes.
- Visualize the data that is collected and cleaned to perform analytics and get insights.
In customer data centers, data is generated by many different sources and applications—such as file servers, FTP servers, databases, and logs—all of which store rich data vital to the business.
Managing and extracting useful data points can provide advantages to customers and also meet certain regulatory requirements they may be subject to.
Companies moving to VMware Cloud on AWS may be looking to migrate workloads with file systems that contain unstructured data. These can be rich sources for useful business data, but it can be daunting to determine how to draw meaningful insights from these datasets.
In this post, we will provide guidance to customers on to how VMware Cloud on AWS brings these datasets closer to AWS Analytics Services, making it easier to use services to draw meaningful insights from business data.
Architecture
As depicted in Figure 1 below, there is a VMware Software Defined Data Center (SDDC) on the left, which is hosting a customer’s MySQL database virtual machine, along with the customer’s front end virtual machines (VMs).
On the right is the customer’s AWS account which hosts the AWS-native services used for analytics.

Figure 1 – VMware Cloud on AWS integration with AWS over ENI.
When designing a data analytics solution, customers should take into consideration data volume, the speed at which data flows into or through their systems, and the different data formats to ensure the data is valid and has not been altered.
Leveraging VMware Cloud on AWS helps customers by bringing their workloads adjacent to these native AWS services. This allows them to be accessed directly through the Elastic Network Interface (ENI).
An ENI is a 25Gbps high bandwidth, private and dedicated link, and all of the analytic services will run inside the customer’s virtual private cloud (VPC). This ENI connection provides connectivity between these two environments, and helps process data faster as compared to having the database hosted in the customer’s data centers.
In the following example, we are going to perform an analysis on MySQL database that resides on VMs running on top of a VMware Cloud on AWS environment. The database contains data about COVID-19 vaccines, as well as data about the vaccination drive undertaken by different countries around the globe.
We will then leverage AWS analytics services to create insights into this data as down in the below figure.

Figure 2 – Analytic service components and processes.
By doing this, we’ll be able to answer simple questions like “What is the count of daily vaccinations per vaccine type?” without having to type in complex SQL queries.
As shown in Figure 2, we will create crawlers in AWS Glue to retrieve the data from the MySQL instance on VMware Cloud on AWS to the AWS Glue data catalogue and to the Amazon Simple Storage Service (Amazon S3) bucket.
We will then run an AWS Glue extract, transform, load (ETL) job to transform this data to the Parquet format on S3, which makes it suitable to run the analysis using Amazon Athena and Amazon QuickSight.
Setup
The workflow to configure and run the analysis has two parts:
- Configure AWS Glue to run an ETL job on the MSSQL database and store the output in an S3 bucket.
- Run Amazon Athena queries on the data inside S3 and visualize the data using QuickSight.
Before we get to AWS Glue, we need to ensure the virtual machine with the database is accessible from AWS. For that, we need to have the database endpoint, credentials, and the required security groups with the privileges in place.
Customers should follow these recommendations when working with AWS Security Groups using the least privilege model. This security group is applied to the ENI on the connected VPC, which all of the analytics services will be using to make the connections.
Part 1: Perform ETL in AWS Glue Using the JDBC Connection
To get started, we’ll create a crawler (bncrawler-01) which will sample the source data (VMware Cloud on AWS MySQL) and build the metadata in the AWS Glue Data Catalog.
Below are the configuration details for first crawler-01; follow the wizard on AWS Glue.

Figure 3 – Crawler-01 configuration details.
To connect to the source data, we need a JDBC connection. To complete the connection, you are required to provide the JDBC URL (the IP-address of the VMware Cloud on AWS MySQL virtual machine), the database credentials, and the name of the database.
Once configured, click on Run Crawler which will build the metadata in the AWS Glue Data Catalog. Review by clicking on Tables and the newly-created table in the previous step to ensure it has been updated.
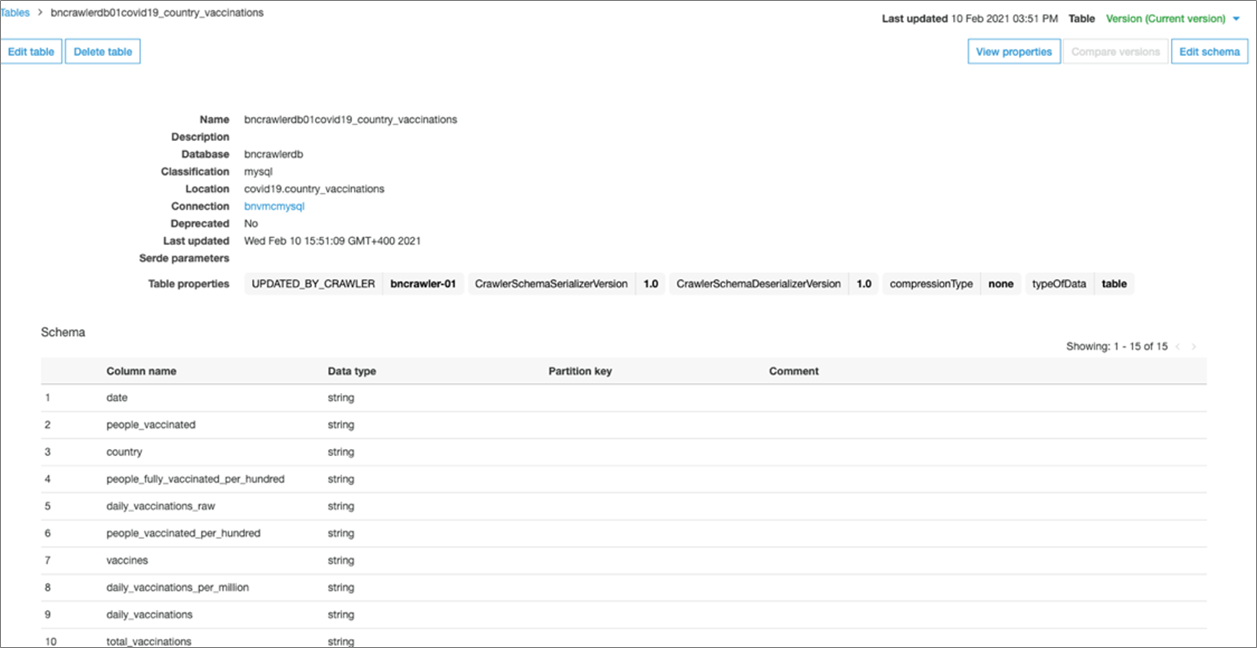
Figure 4 – Review AWS Glue Data Catalog.
You should see the catalog has been updated with the same columns that are present in the MySQL database table.
Next, we need to create an ETL job to move data from VMware Cloud on AWS MySQL to the S3 bucket in the Parquet format. More details can be found in the documentation.
Click on Jobs > Add Job, and follow the wizard. Next, choose the AWS Identity and Access Management (IAM) role and S3 bucket locations for the ETL script. You can create an S3 bucket if one does not exist.
On the next screen, choose the data source VMC MySQL from the AWS Glue Data Catalog that points to the VMware Cloud on AWS MySQL data catalog table.
Next, choose Create tables in your data target S3 bucket. For Format, choose Parquet, and set the data target path to the S3 bucket prefix.
Select transform data type – Change Schema. Specify the Data type (S3), Format (Parquet), Connection (S3 network connection) and Target path (S3 bucket).

Figure 5 – Choose Format and Connection Type.
Next, verify the mappings created in AWS Glue. Change the mappings by choosing other columns with Map to target. You can Clear all mappings and Reset to default AWS Glue mappings. AWS Glue generates your script with the defined mappings.
Click Next and verify the script and steps, and then click on Run Job.
Figure 6 – Verification process.
Once the job is completed, the transformed data is now available in the S3 bucket and can be used as a data lake. Data is now ready to be consumed by other services like Amazon Athena and Amazon QuickSight to perform analysis.
Part 2: Query Data Lake Using Athena and Visualize Using QuickSight
Next, we will create and run a new crawler over the partitioned Parquet data generated in the preceding step.
Click on Tables and then the new table created in the Data Catalog, and select Action > View data. You can now run a SQL query over the partitioned Parquet data in the Athena Query Editor, by selecting View data as shown below.

Figure 7 – View data.
When you click on View Data, it takes you to Athena and you can run simple queries such as select country, vaccines from “name_of_the_table”;
This output will show you which vaccines are adopted by each country.
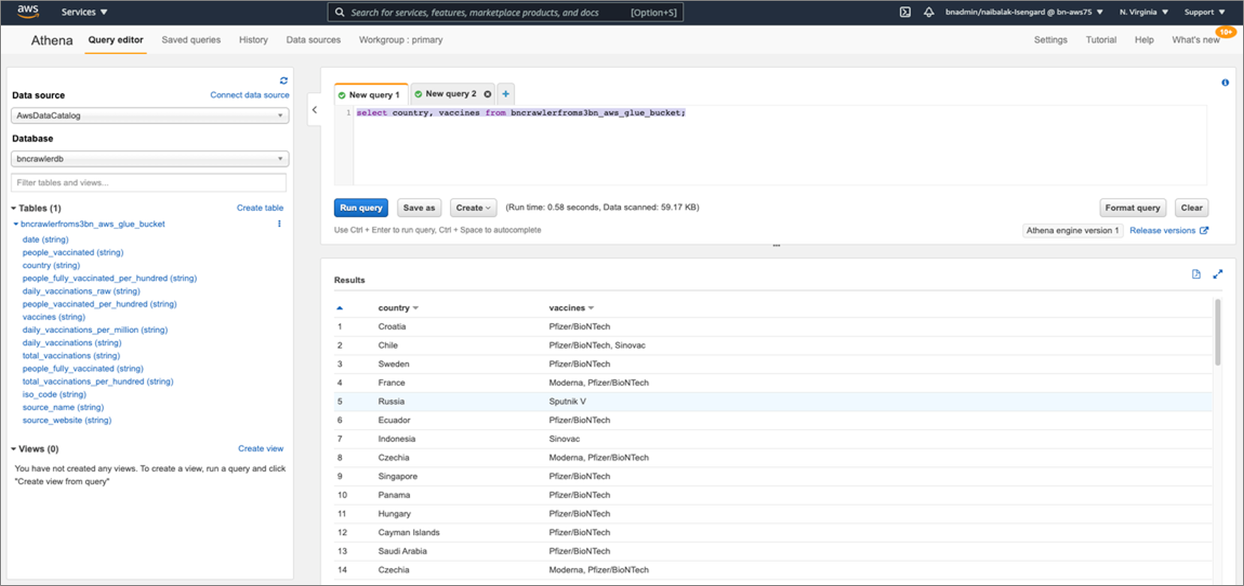
Figure 8 – Run Amazon Athena Query.
Now that we have seen the query working, we can use Amazon QuickSight to visualize the data.
In QuickSight, click on Create a new dataset and select Athena. Provide a name for your data source and click on Create data source.
Next, select the default for Catalog and choose the AWS Glue Data Catalog that we created in Part 1.
Select the table which was created earlier with the second crawler, and click Select. Choose Import to SPICE for quicker analytics and then click on Visualize.
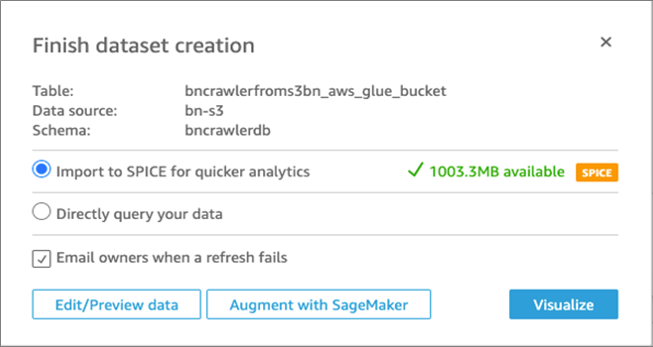
Figure 9 – Create visualization.
You can now visualize and customize your data to suit to your requirements.
Using QuickSight, we can gain some very quick insights and answer questions such as:
- What is the count of daily vaccinations per vaccine type?
- What is the total count of vaccinations till date?
- How many people have been vaccinated in each country so far?
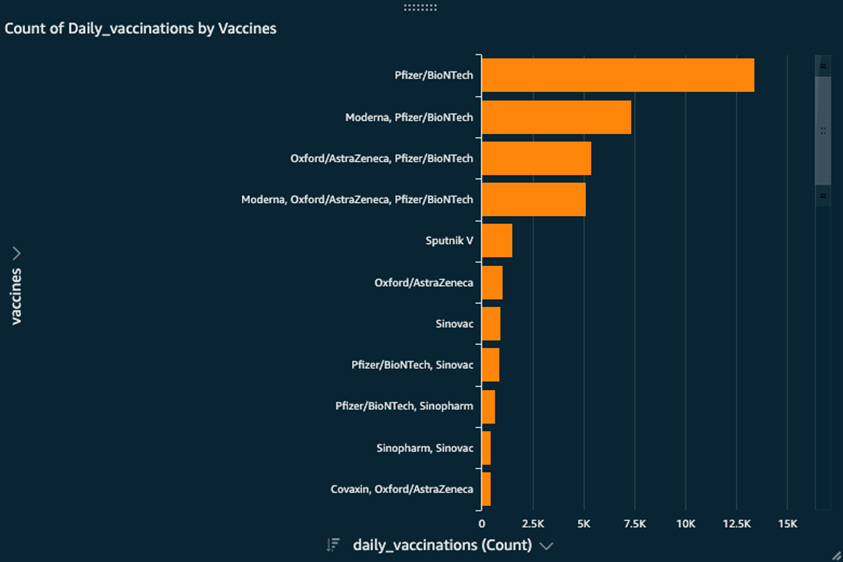
Figure 10 – Visualization output of simple queries.
Summary
Running virtual machines with databases or datastores on VMware Cloud on AWS lets you use the same management tools and VMs as on your on-premises VMware vSphere environment.
You can easily extend these workloads to the cloud and take advantage of AWS on-demand delivery, global footprint, elasticity, and scalability to meet your business objectives.
VMware Cloud on AWS provides additional value to your business data needs using the built-in SDDC capabilities and leveraging AWS native services.
While using AWS Glue as a managed ETL service in the cloud, you can use existing connectivity between your VPC and VMware Cloud on AWS environment to reach an existing database service without significant migration effort.
You can create a data lake setup using Amazon S3 and periodically move the data from a data source on VMware Cloud on AWS into the data lake. AWS Glue and other cloud services such as Amazon Athena, Amazon Redshift Spectrum, and Amazon QuickSight can interact with the data lake in a cost-effective manner.
To learn more about these AWS services, please visit the AWS Analytics Services page.