AWS News Blog
Introducing Amazon MSK Connect – Stream Data to and from Your Apache Kafka Clusters Using Managed Connectors

|
March 14, 2023: There is now an example of how to use the Debezium MySQL connector plugin with a MySQL-compatible Amazon Aurora database as the source in the MSK documentation.
November 10, 2022: Post updated to include some clarifications on how to better set up Debezium using MSK Connect.
Apache Kafka is an open-source platform for building real-time streaming data pipelines and applications. At re:Invent 2018, we announced Amazon Managed Streaming for Apache Kafka (Amazon MSK), a fully managed service that makes it easy to build and run applications that use Apache Kafka to process streaming data.
When you use Apache Kafka, you capture real-time data from sources such as IoT devices, database change events, and website clickstreams, and deliver it to destinations such as databases and persistent storage.
Kafka Connect is an open-source component of Apache Kafka that provides a framework for connecting with external systems such as databases, key-value stores, search indexes, and file systems. However, manually running Kafka Connect clusters requires you to plan and provision the required infrastructure, deal with cluster operations, and scale it in response to load changes.
Today, we’re announcing a new capability that makes it easier to manage Kafka Connect clusters. MSK Connect allows you to configure and deploy a connector using Kafka Connect with a just few clicks. MSK Connect provisions the required resources and sets up the cluster. It continuously monitors the health and delivery state of connectors, patches and manages the underlying hardware, and auto-scales connectors to match changes in throughput. As a result, you can focus your resources on building applications rather than managing infrastructure.
MSK Connect is fully compatible with Kafka Connect, which means you can migrate your existing connectors without code changes. You don’t need an MSK cluster to use MSK Connect. It supports Amazon MSK, Apache Kafka, and Apache Kafka compatible clusters as sources and sinks. These clusters can be self-managed or managed by AWS partners and 3rd parties as long as MSK Connect can privately connect to the clusters.
Using MSK Connect with Amazon Aurora and Debezium
To test MSK Connect, I want to use it to stream data change events from one of my databases. To do so, I use Debezium, an open-source distributed platform for change data capture built on top of Apache Kafka.
I use a MySQL-compatible Amazon Aurora database as the source and the Debezium MySQL connector with the setup described in this architectural diagram:
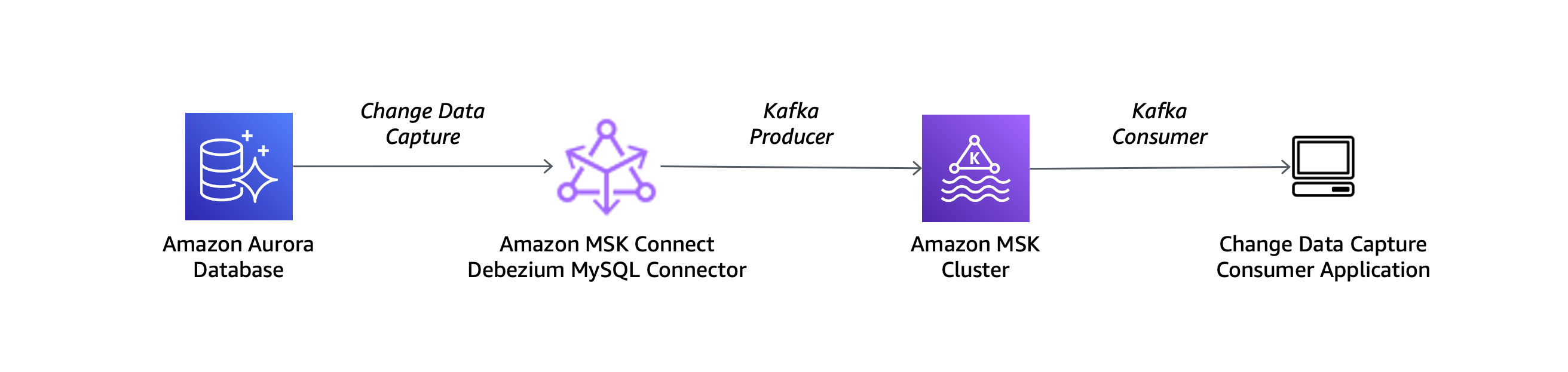
To use my Aurora database with Debezium, I need to turn on binary logging in the DB cluster parameter group. I follow the steps in the How do I turn on binary logging for my Amazon Aurora MySQL cluster article.
Next, I have to create a custom plugin for MSK Connect. A custom plugin is a set of JAR files that contain the implementation of one or more connectors, transforms, or converters. Amazon MSK will install the plugin on the workers of the connect cluster where the connector is running.
From the Debezium website, I download the MySQL connector plugin for the latest stable release. Because MSK Connect accepts custom plugins in ZIP or JAR format, I convert the downloaded archive to ZIP format and keep the JARs files in the main directory:
Then, I use the AWS Command Line Interface (AWS CLI) to upload the custom plugin to an Amazon Simple Storage Service (Amazon S3) bucket in the same AWS Region I am using for MSK Connect:
On the Amazon MSK console there is a new MSK Connect section. I look at the connectors and choose Create connector. Then, I create a custom plugin and browse my S3 buckets to select the custom plugin ZIP file I uploaded before.

I enter a name and a description for the plugin and then choose Next.

Now that the configuration of the custom plugin is complete, I start the creation of the connector. I enter a name and a description for the connector.

I have the option to use a self-managed Apache Kafka cluster or one that is managed by MSK. I select one of my MSK cluster that is configured to use IAM authentication. The MSK cluster I select is in the same virtual private cloud (VPC) as my Aurora database. To connect, the MSK cluster and Aurora database use the default security group for the VPC. For simplicity, I use a cluster configuration with auto.create.topics.enable set to true.
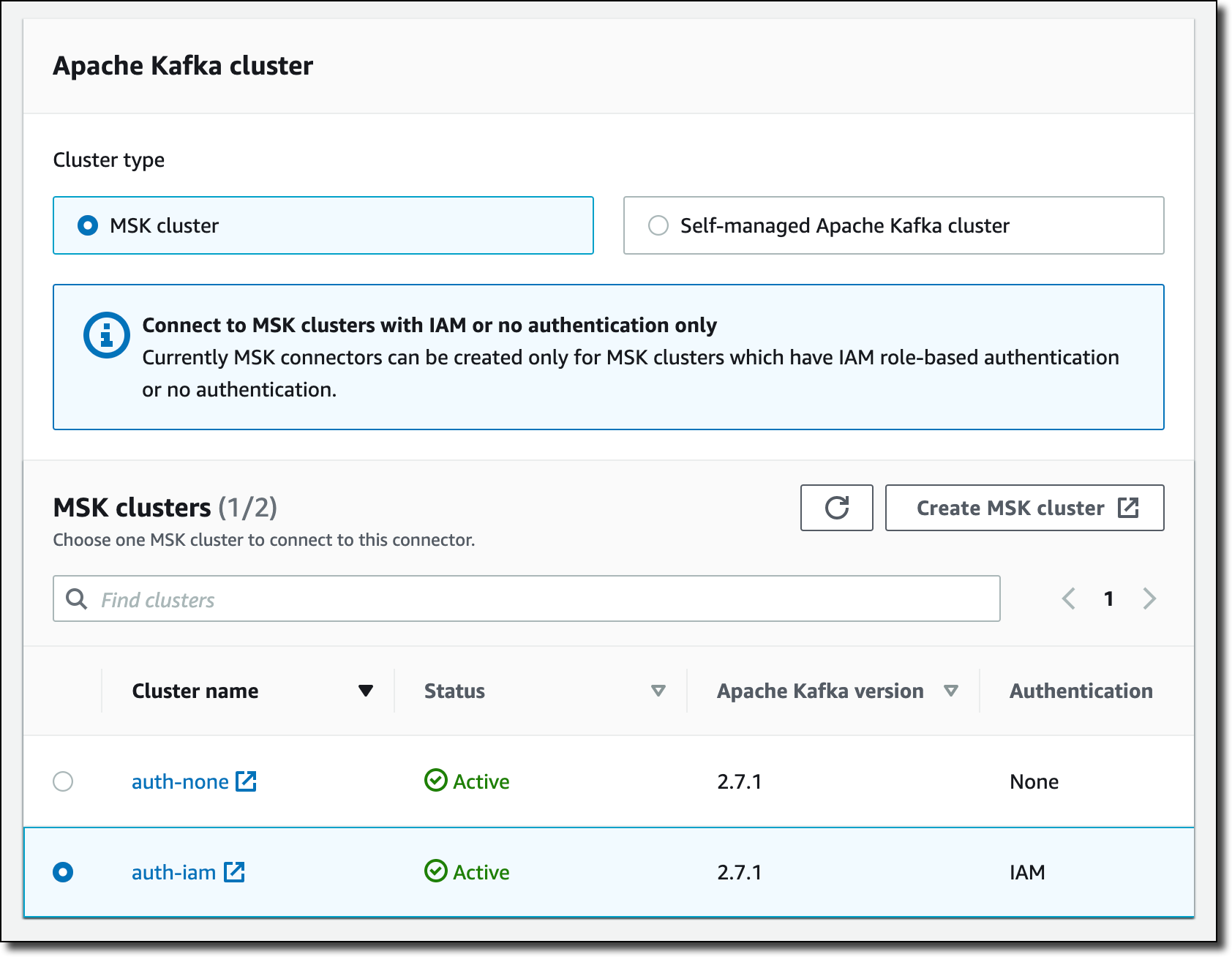
In Connector configuration, I use the following settings:
Some of these settings are generic and should be specified for any connector. For example:
connector.classis the Java class of the connector.tasks.maxis the maximum number of tasks that should be created for this connector.
Other settings are specific to the Debezium MySQL connector:
- The
database.hostnamecontains the writer instance endpoint of my Aurora database. - The
database.server.nameis a logical name of the database server. It is used for the names of the Kafka topics created by Debezium. - The
database.include.listcontains the list of databases hosted by the specified server. - The
database.history.kafka.topicis a Kafka topic used internally by Debezium to track database schema changes. - The
database.history.kafka.bootstrap.serverscontains the bootstrap servers of the MSK cluster. - The final eight lines (
database.history.consumer.*anddatabase.history.producer.*) enable IAM authentication to access the database history topic.
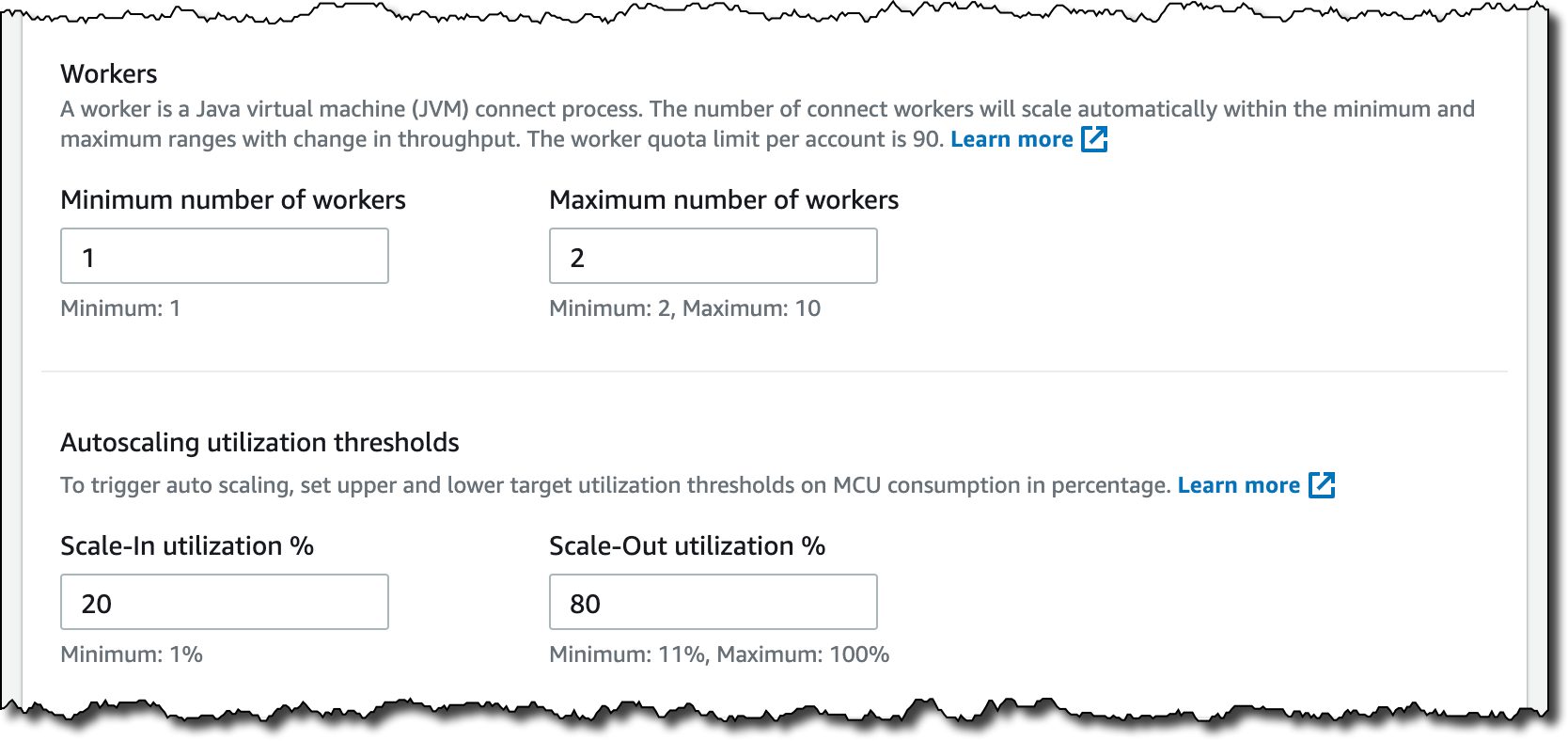
In Connector capacity, I can choose between autoscaled or provisioned capacity. For this setup, I choose Autoscaled and leave all other settings at their defaults.

With autoscaled capacity, I can configure these parameters:
- MSK Connect Unit (MCU) count per worker – Each MCU provides 1 vCPU of compute and 4 GB of memory.
- The minimum and maximum number of workers.
- Autoscaling utilization thresholds – The upper and lower target utilization thresholds on MCU consumption in percentage to trigger auto scaling.
Note added on November 10, 2022: The Debezium connector supports only 1 task per connector, hence it can use just use one worker per connector. Autoscaling workers per connector will not work with this specific connector. If you’re following this blog to set up Debezium with MSK Connect, choose the Provisioned capacity type and increase the MCUs as needed to scale up.
There is a summary of the minimum and maximum MCUs, memory, and network bandwidth for the connector.

For Worker configuration, you can use the default one provided by Amazon MSK or provide your own configuration. In my setup, I use the default one.
In Access permissions, I create a IAM role. In the trusted entities, I add kafkaconnect.amazonaws.com to allow MSK Connect to assume the role.
The role is used by MSK Connect to interact with the MSK cluster and other AWS services. For my setup, I add:
- Permissions to write logs to a Amazon CloudWatch log group I created earlier.
- Permissions to authenticate to my MSK cluster through IAM.
The Debezium connector needs access to the cluster configuration to find the replication factor to use to create the history topic. For this reason, I add to the permissions policy the kafka-cluster:DescribeClusterDynamicConfiguration action (equivalent Apache Kafka’s DESCRIBE_CONFIGS cluster ACL).
Depending on your configuration, you might need to add more permissions to the role (for example, in case the connector needs access to other AWS resources such as an S3 bucket). If that is the case, you should add permissions before creating the connector.
In Security, the settings for authentication and encryption in transit are taken from the MSK cluster.
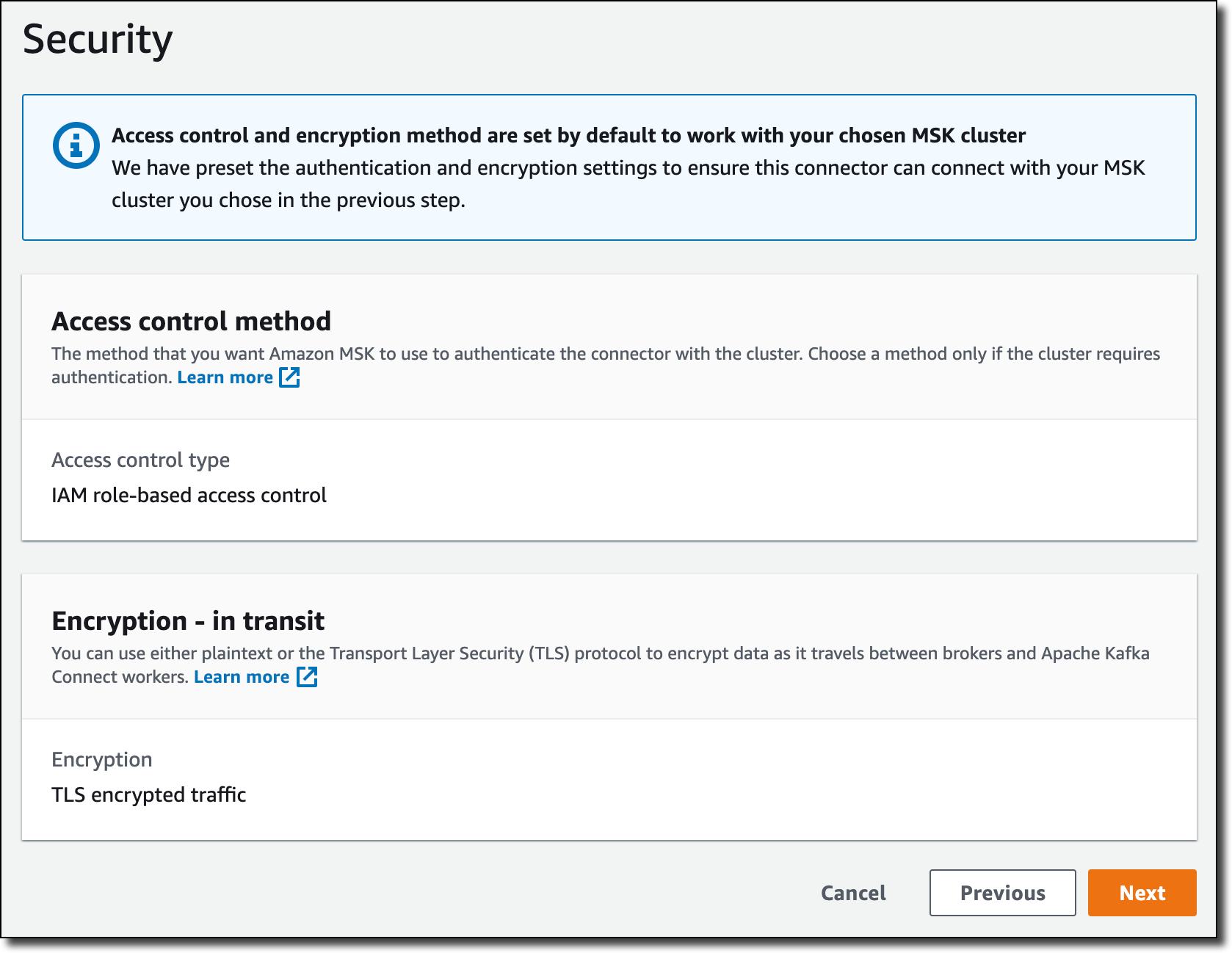
In Logs, I choose to deliver logs to CloudWatch Logs to have more information on the execution of the connector. By using CloudWatch Logs, I can easily manage retention and interactively search and analyze my log data with CloudWatch Logs Insights. I enter the log group ARN (it’s the same log group I used before in the IAM role) and then choose Next.

I review the settings and then choose Create connector. After a few minutes, the connector is running.
Testing MSK Connect with Amazon Aurora and Debezium
Now let’s test the architecture I just set up. I start an Amazon Elastic Compute Cloud (Amazon EC2) instance to update the database and start a couple of Kafka consumers to see Debezium in action. To be able to connect to both the MSK cluster and the Aurora database, I use the same VPC and assign the default security group. I also add another security group that gives me SSH access to the instance.
I download a binary distribution of Apache Kafka and extract the archive in the home directory:
To use IAM to authenticate with the MSK cluster, I follow the instructions in the Amazon MSK Developer Guide to configure clients for IAM access control. I download the latest stable release of the Amazon MSK Library for IAM:
In the ~/kafka_2.13-2.7.1/config/ directory I create a client-config.properties file to configure a Kafka client to use IAM authentication:
I add a few lines to my Bash profile to:
- Add Kafka binaries to the
PATH. - Add the MSK Library for IAM to the
CLASSPATH. - Create the
BOOTSTRAP_SERVERSenvironment variable to store the bootstrap servers of my MSK cluster.
$ cat >> ~./bash_profile
export PATH=~/kafka_2.13-2.7.1/bin:$PATH
export CLASSPATH=/home/ec2-user/aws-msk-iam-auth-1.1.0-all.jar
export BOOTSTRAP_SERVERS=<bootstrap servers>Then, I open three terminal connections to the instance.
In the first terminal connection, I start a Kafka consumer for a topic with the same name as the database server (ecommerce-server). This topic is used by Debezium to stream schema changes (for example, when a new table is created).
In the second terminal connection, I start another Kafka consumer for a topic with a name built by concatenating the database server (ecommerce-server), the database (ecommerce), and the table (orders). This topic is used by Debezium to stream data changes for the table (for example, when a new record is inserted).
In the third terminal connection, I install a MySQL client using the MariaDB package and connect to the Aurora database:
From this connection, I create the ecommerce database and a table for my orders:
These database changes are captured by the Debezium connector managed by MSK Connect and are streamed to the MSK cluster. In the first terminal, consuming the topic with schema changes, I see the information on the creation of database and table:
Then, I go back to the database connection in the third terminal to insert a few records in the orders table:
INSERT INTO orders VALUES ("123456", "123", "A super noisy mechanical keyboard", "50.00", "2021-08-16 10:11:12");
INSERT INTO orders VALUES ("123457", "123", "An extremely wide monitor", "500.00", "2021-08-16 11:12:13");
INSERT INTO orders VALUES ("123458", "123", "A too sensible microphone", "150.00", "2021-08-16 12:13:14");
In the second terminal, I see the information on the records inserted into the orders table:
My change data capture architecture is up and running and the connector is fully managed by MSK Connect.
Availability and Pricing
MSK Connect is available in the following AWS Regions: Asia Pacific (Mumbai), Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Canada (Central), EU (Frankfurt), EU (Ireland), EU (London), EU (Paris), EU (Stockholm), South America (Sao Paulo), US East (N. Virginia), US East (Ohio), US West (N. California), US West (Oregon). For more information, see the AWS Regional Services List.
With MSK Connect you pay for what you use. The resources used by your connectors can be scaled automatically based on your workload. For more information, see the Amazon MSK pricing page.
Simplify the management of your Apache Kafka connectors today with MSK Connect.
— Danilo