AWS Database Blog
Archive data from Amazon DynamoDB to Amazon S3 using TTL and Amazon Kinesis integration
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more.
In this post, we share how you can use Amazon Kinesis integration and the Amazon DynamoDB Time to Live (TTL) feature to design data archiving. Archiving old data helps reduce costs and meet regulatory requirements governing data retention or deletion policies. Amazon Kinesis Data Streams for DynamoDB captures item-level modifications in a DynamoDB table and replicates them to a Kinesis data stream.
DynamoDB TTL is provided at no added cost and can be used to define when to automatically delete expired items from your tables. TTL eliminates the complexity and cost of scanning tables and deleting items that you don’t want to retain. This saves you money on throughput and storage.
Solution overview
Customers often use DynamoDB to store time series data, such as webpage clickstream data or IoT data from sensors and connected devices. Rather than delete older, less frequently accessed items, many customers want to archive them.
This solution uses DynamoDB TTL to automatically delete expired items from the DynamoDB tables, and Kinesis Streams to capture the expired items. As new items are added to the Kinesis stream (that is, as TTL deletes older items), they are sent to an Amazon Kinesis Data Firehose delivery stream. Kinesis Data Firehose provides a simple, fully managed solution to load the data into Amazon Simple Storage Service (Amazon S3) for long term archive.

Figure 1 – High-level architecture of archiving solution
The following steps are a high-level overview of the solution. Figure 1 preceding illustrates the process.
- Enable DynamoDB TTL with an attribute that will store the TTL timestamp.
- Enable Kinesis Data Streams for DynamoDB. This streams data into a Kinesis data stream for further archival processing.
- Connect Kinesis Data Firehose to Kinesis Data Streams using:
- An AWS Lambda function to perform data transformation to select TTL records.
- An S3 bucket to store the selected TTL records.
- Validate the expiration and delivery of records processed by TTL to the S3 bucket.
Prerequisites
This post assumes that you already have a DynamoDB table and an attribute on that table that you can use as the timestamp for TTL.
Enable DynamoDB TTL
In this solution, let’s assume you have a DynamoDB table that receives a stream of data from IoT devices every five seconds. The data is stored in a DynamoDB table with DeviceID as a partition key. The sort key is a combination of status and date to support an access pattern that must return items ordered within a time range for a specific status.
When inserting items, an ExpiryDate attribute with an epoch timestamp value that is a month after the insertion date is added. Using this timestamp, DynamoDB TTL deletes an item from the table when the ExpiryDate timestamp is in the past. This deletion isn’t guaranteed to happen the moment when the timestamp expires but usually completes within 48 hours.
In the example shown in Figure 2 that follows, we put an ExpiryDate attribute in every item with a timestamp in epoch format. In this example, it is one month from the time data is inserted. So when we use this attribute for TTL, these items will be eligible for expiry after a month.

Figure 2 – DeviceIDs assigned an ExpiryDate (TTL)
To enable DynamoDB TTL
- In the AWS Management Console for DynamoDB, choose Tables from the left navigation pane, then choose the table you want to enable TTL on.
Figure 3 – Select a table in DynamoDB
- In DeviceLog, choose the Additional settings tab.

Figure 4 – DeviceLog additional settings tab
- Scroll down to Time to Live (TTL) and select Enable in the upper corner.

Figure 5 – Enable TTL
- In TTL attribute name, enter the name of the attribute that will be stored in the TTL timestamp.

Figure 6 – Enter the TTL attribute name in DynamoDB
Set up a Kinesis data stream
Kinesis Data Streams for DynamoDB captures item-level changes in your table and replicates the changes to a Kinesis data stream.
To set up a Kinesis data stream
- Go back to tables in the DynamoDB Console and choose the DeviceLog table.
- On the DeviceLog table properties page, choose the Exports and Streams tab.
- Under Amazon Kinesis data stream details, select Enable.
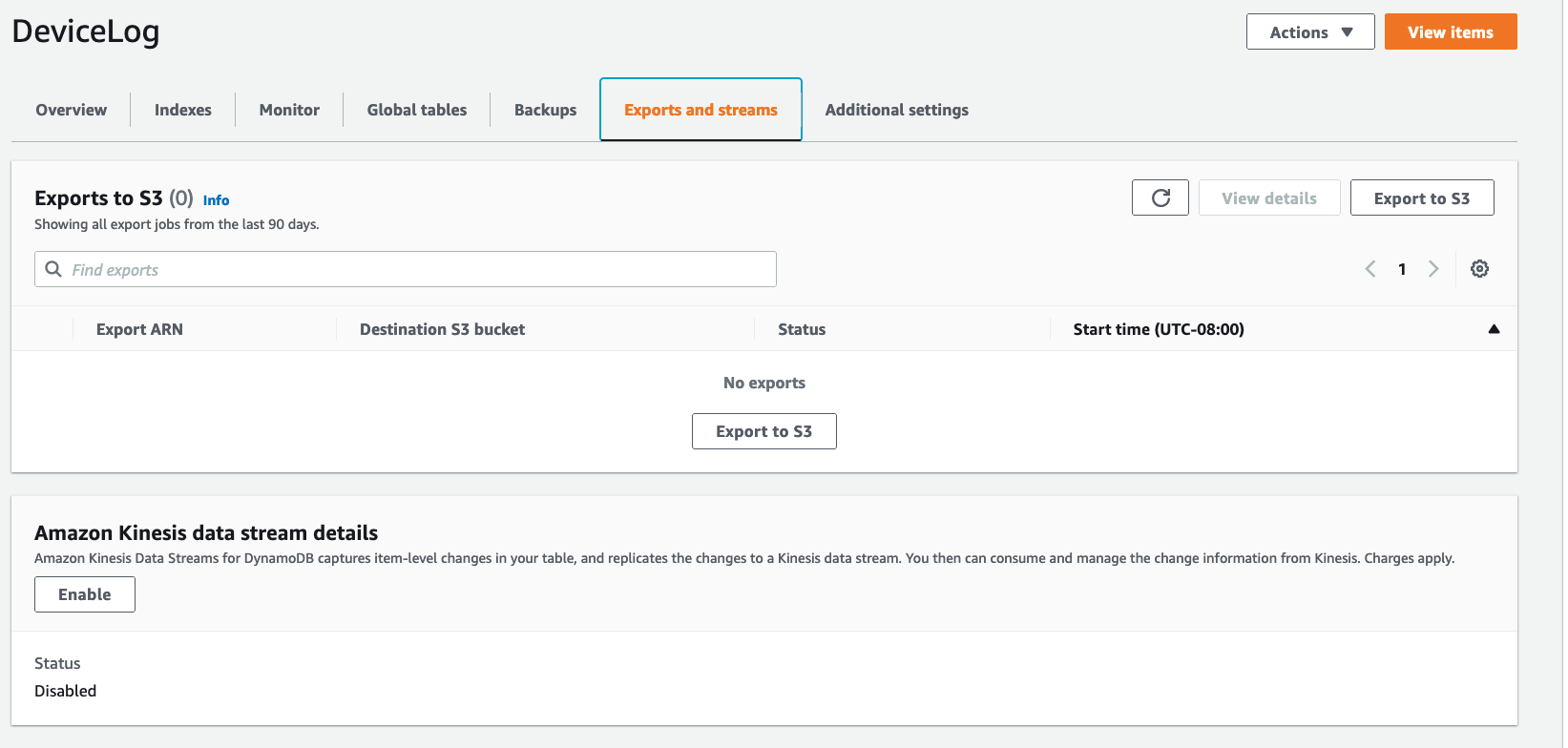
Figure 7 – Enable Kinesis data stream
- You can select an existing Destination Kinesis data stream or create a new one. For this example, choose Create new to create a new stream and name it
DevicelogDataStream.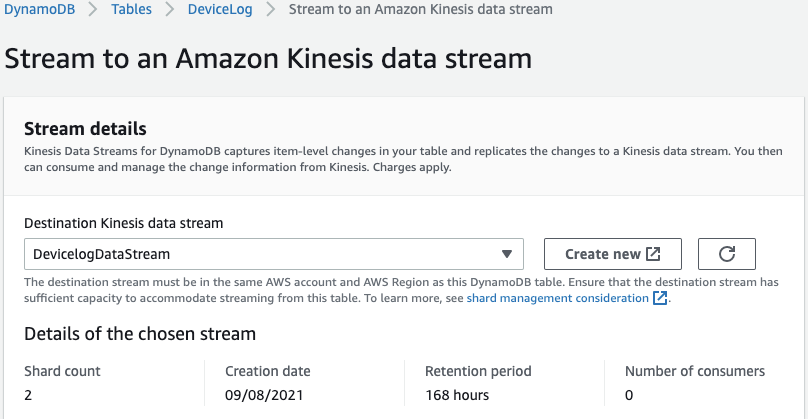
Figure 8 – Select or create a destination Kinesis data stream
- In Data stream configuration, under Data stream capacity, select On-demand. This capacity mode eliminates the need for provisioning and managing the capacity for streaming data. Using Kinesis Data Streams On-demand automatically scales the capacity in response to varying data traffic.

Figure 9 – Set the Kinesis data stream capacity mode to On-demand
Note: If you instead would like to use a Kinesis data stream in provisioned mode, make sure that the destination stream has enough capacity. If there isn’t enough capacity, writes from DynamoDB to the Kinesis data stream will be throttled and the replication latency of data entering the stream will increase. For more information, see Resharding a Stream.
Create a Lambda function to select TTL records
Kinesis Streams will continuously capture items as they are modified in DynamoDB, including item updates done by the application. The solution uses a Lambda function to select only items expired by DynamoDB TTL process. Items that are deleted by the TTL process after expiration have the attribute userIdentity.principalId: "dynamodb.amazonaws.com".
To create a Lambda function
- In the Lambda console, choose Dashboard from the left navigation pane, and then choose Create function.

Figure 10 – Lambda console dashboard
- Select Author from scratch. Enter a Function name, and then under Runtime, choose Python 3.9.
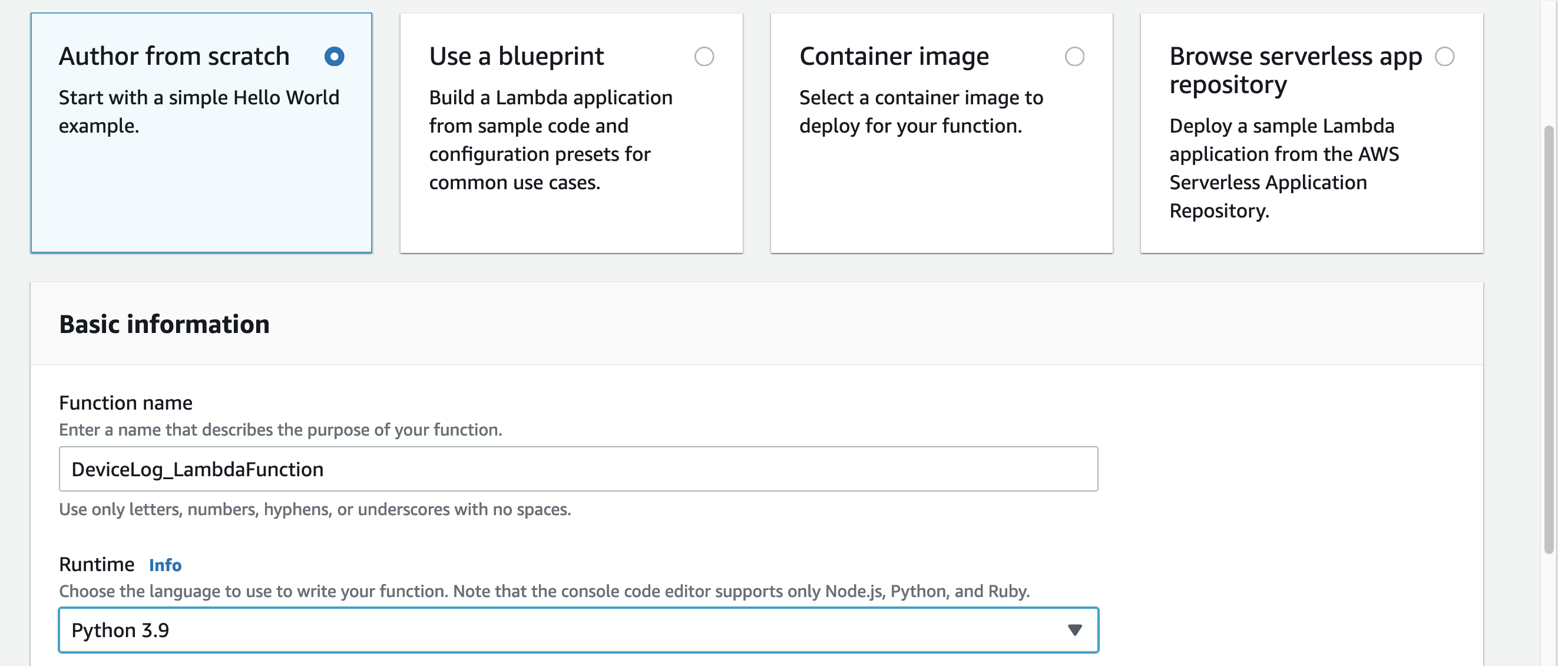
Figure 11 – Enter a function name and choose a language
- Select the Code tab and paste the following code snippet in lambda_function. The function selects the items expired by the DynamoDB TTL process.

Figure 12 – Lambda function code selects DynamoDB TTL records
Lambda function to select TTL records:
Set up a Kinesis Data Firehose delivery stream
Kinesis Data Firehose loads data from a streaming source into a data store. Data Firehose is a fully managed service that automatically scales to match the throughput of your data and requires no ongoing administration. Data Firehose can also invoke a Lambda function to transform, filter, decompress, convert, and process your source data records. In this solution, the streaming source is a Kinesis data stream and the target destination is an S3 bucket.
To set up a Data Firehose delivery stream
- In the Data Firehose console, choose Delivery streams from the left navigation pane, and then choose Create delivery stream.

Figure 13 – Create a delivery stream
- On the Choose source and destination page, under Source, select Amazon Kinesis Data Streams. Under Destination, select Amazon S3.
 Figure 14 – Select the data stream source and destination
Figure 14 – Select the data stream source and destination - Select the Kinesis data stream DevicelogDataStream that you created in a previous step.
- Scroll down to Transform and convert records and add the Lambda function you created in the previous procedure to select only items expired by the DynamoDB TTL process.
Figure 15 – Enable data transformation
- Scroll down to Destination settings and select a destination S3 bucket. This is where the Data Firehose delivery stream will be exported to.

Figure 16 – Select a destination S3 bucket
Verify TTL records expiration and delivery to the S3 bucket
When TTL is enabled on the table, you can verify that records are being deleted as expected by reviewing the TimeToLiveDeletedItemCount CloudWatch metric.
To verify TTL records expiration
- Go to the DynamoDB console and select Tables from the left navigation pane, and then select the table you want to verify.

Figure 17 – DynamoDB Console with DeviceLog table
- Choose the Monitor tab to see the CloudWatch metrics for the table.

Figure 18 – CloudWatch metrics for the DynamoDB table
- Scroll down on the Monitor tab to see the CloudWatch metrics for the table. CloudWatch metrics are updated every minute with the number of items removed by DynamoDB TTL.

Figure 19 – Graph of TTL deleted items in CloudWatch metrics
Now that you’re seeing TTL deletes in the TimeToLiveDeletedItemCount metric, you can check that the workflow is archiving items as expected. In other words, you can verify that TTL items are being put into the Kinesis stream, forwarded to the Firehose delivery stream, batched into objects, and stored in an S3 bucket.
To verify that items are being delivered to the S3 bucket
- Open the Amazon Kinesis console and choose Delivery streams from the left navigation pane, and then select your Kinesis Data Firehose delivery stream.
Figure 20 – Select the Data Firehose delivery stream to be monitored
- Choose the Monitoring tab. You should start to see data and records flowing in.
- As part of monitoring the Firehose delivery stream, go to the Kinesis Firehose console and select your delivery stream.

Figure 21 – Amazon Kinesis Firehose Delivery Stream
- Choose the Monitoring tab and look for the DeliveryToS3.Records metric.
- Scroll down on the Monitoring tab to see the CloudWatch metrics for the stream.

Figure 24 – CloudWatch metric showing number of records delivered to an S3 bucket
- Go to the Amazon S3 console, select Buckets from the left navigation pane, and then choose your destination S3 bucket.
- After about 15 minutes, you should see objects being written into folders in the format year/month/day/hour.

Figure 23 –S3 bucket containing the deleted TTL objects
DynamoDB Streams and Kinesis Data Streams
You can design a similar archiving strategy that uses Amazon DynamoDB Streams and AWS Lambda, such as the one described in Automatically Archive Items to S3 Using DynamoDB Time to Live (TTL) with AWS Lambda and Amazon Kinesis Firehose. Kinesis Data Streams and DynamoDB Streams have some functional differences to consider when deciding on an archiving strategy. Some of the differences are:
- DynamoDB Streams data retention is 24 hours. If you need longer retention, Kinesis Data Streams provides 7 days extended data retention and up to 365 days long-term data retention.
- DynamoDB Streams allows up to two processes to simultaneously read from a stream shard. Kinesis Data Streams allows up to five processes to simultaneously read from the same shard. Whether you use DynamoDB Streams or Kinesis Data Streams, each shard provides up to 2 MB per second of data output, regardless of the number of processes accessing data in parallel from a shard. When data consumers use enhanced fan-out, each shard provides up to 2 MB per second of data output to each of those consumers.
- Kinesis Data Streams gives you access to other Kinesis services, such as Amazon Kinesis Data Firehose and Amazon Kinesis Data Analytics. You can use Kinesis services to build applications to power real-time dashboards, generate alerts, implement dynamic pricing and advertising, and perform sophisticated data analytics, such as applying machine learning algorithms.
- Kinesis Data Streams doesn’t provide strict item-level ordering guarantees like DynamoDB Streams does. Use
ApproximateCreationDateTimein the Kinesis data stream record to order items with the same primary keys, or to order items across multiple keys.ApproximateCreationDateTimeis created by DynamoDB when the update is made and is accurate to the nearest millisecond.
DynamoDB Standard-IA table class
In re:Invent 2021, DynamoDB announced Standard Infrequent Access (DynamoDB Standard-IA) table class. This new table class for DynamoDB reduces storage costs by 60 percent compared to existing DynamoDB Standard tables, and delivers the same performance, durability, and scaling.
DynamoDB Standard-IA is a great solution if you want to maintain fast access to infrequently accessed data in storage-heavy workloads. If your use case requires archiving data and would benefit from storing the data in your S3 data lake, then you can use TTL combined with Kinesis Data Streams or TTL combined with DynamoDB Streams.
Conclusion
In this post, we covered how you can use Kinesis Data Streams to archive data from your DynamoDB table to Amazon S3. Archiving based on TTL eliminates the complexity and cost of scanning tables and deleting items that you don’t want to retain, thereby saving you money on provisioned throughput and storage.
If you have any questions or suggestions, please leave us a comment.
About the Authors
 Bhupesh Sharma is a Data Lab Solutions Architect with AWS. His role is helping customers architect highly-available, high-performance, and cost-effective data analytics solutions to empower customers with data-driven decision-making. In his free time, he enjoys playing musical instruments, road biking, and swimming.
Bhupesh Sharma is a Data Lab Solutions Architect with AWS. His role is helping customers architect highly-available, high-performance, and cost-effective data analytics solutions to empower customers with data-driven decision-making. In his free time, he enjoys playing musical instruments, road biking, and swimming.
 Veerendra Nayak is a Senior Database Solution Architect with AWS.
Veerendra Nayak is a Senior Database Solution Architect with AWS.