Amazon Web Services ブログ
Amazon S3 アノテーション: クエリ可能かつリッチなコンテキストをオブジェクトに直接アタッチ
2026 年 6 月 16 日、Amazon Simple Storage Service (Amazon S3) 向けの新しいメタデータ機能であるアノテーションを発表しました。これにより、大規模かつリッチなビジネスコンテキストをオブジェクトに直接アタッチできるようになります。オブジェクトごとに最大 1,000 個の名前付きアノテーションを保存できます。各アノテーションのサイズは最大 1 MB、合計でオブジェクトあたり最大 1 GB です。JSON、XML、YAML、プレーンテキストなど、柔軟な形式に対応しています。オブジェクトを書き換えることなく、いつでもアノテーションを変更または削除できるため、オブジェクトのコンテキストを常に最新の状態に保つことができます。
組織は、人間の介入なしにデータを検索および理解し、データに基づいてアクションを実行する必要がある AI エージェントや自律型ワークフローを構築しています。これらのエージェンティックワークフローをサポートするには、データとともに進化し、ペタバイト規模のオブジェクトにスケールでき、高コストの取得なしでクエリ可能な状態を維持できるメタデータが必要です。
S3 アノテーションを使用することで、AI が生成したトランスクリプト、コンテンツの評価、技術仕様などのコンテキストを、オブジェクトとともに保存できます。コンテキストは、コピー、レプリケーション、クロスリージョン転送中に自動的にオブジェクトとともに移動し、オブジェクトを削除すると S3 によって削除されます。S3 Metadata を有効にすると、アノテーションは自動的にフルマネージドアノテーションテーブルに反映され、Amazon Athena や他の分析エンジンでクエリできます。
一般的なユースケース
アノテーションは、業界を問わず、複雑なメタデータの課題を解決します:
- メディア & エンターテイメント: 動画アセットで、トランスクリプト、コンテンツモデレーションの結果、字幕ファイル、ライセンスメタデータを個別のアノテーションとして追跡することで、複数のメディアアセット管理システムでメタデータを同期する必要がなくなります。
- 金融サービス: AI が生成した投資の要約と感情分析を調査ドキュメントにアタッチすることで、自律型調査エージェントが個別のメタデータデータベースを維持することなく、自然言語クエリを通じて関連データセットを検出できるようになります。
- ライフサイエンス: 臨床試験データに、規制関連のステータス、患者コホートの詳細、承認履歴などのアノテーションを付加することで、Amazon S3 Glacier ストレージクラスにアーカイブされたデータについての完全なコンテキストに取得料金なしでアクセスできるようにしながら、コンプライアンス監査を迅速化できます。
アノテーションがメタデータに関する課題をどのように解決するか
Amazon S3 は、オブジェクトを記述するための複数の方法を既にサポートしています。システム定義メタデータは、サイズやストレージクラスなどのプロパティをキャプチャします。オブジェクトタグは、アクセスコントロールやライフサイクル管理などの運用タスクをサポートします。ユーザー定義メタデータを使用すると、アップロード時に少量のカスタム情報を追加できます。
これらの機能はそれぞれの目的には適していますが、別途メタデータシステムを構築および維持することなく、よりリッチなコンテキストをアタッチする必要がある場合には限界があります。アノテーションは、根本的に異なる規模と柔軟性でメタデータ機能を提供することで、これらのニーズに対応します。10 個のイミュータブルなタグや 2 KB のヘッダーとは異なり、オブジェクトごとにミュータブルかつクエリ可能なコンテキストを提供します。
| 機能 | 最大サイズ | ミュータブル? | 最適な用途 |
| システム定義メタデータ | 固定 | いいえ | オブジェクトのプロパティ (サイズ、ストレージクラス、作成時刻) |
| ユーザー定義メタデータ | 2 KB | いいえ (アップロード時に設定) | 小規模な key-value ペア |
| オブジェクトタグ | 10 個のタグ、キー/値ごとに 128/256 文字 | はい | アクセスコントロール、ライフサイクルルール、コスト配分 |
| アノテーション | 1 GB (1,000 × 1 MB) | はい | リッチなビジネスコンテキスト (JSON、XML、YAML、プレーンテキスト) |
現在、S3 オブジェクトを記述するメタデータは、多くの場合、別のデータベースまたはサイドカーファイルに格納されており、データストレージよりも高いコストがかかる可能性がある、複雑な同期ワークフローが必要となります。S3 Metadata アノテーションテーブルを有効にすると、このコンテキストは Amazon Athena を通じて大規模にクエリ可能になります。AI エージェントは、S3 Tables MCP サーバーを使用して自然言語を通じてデータを検出できます。このサーバーは、AI モデルがアノテーションをクエリするための標準化されたインターフェイスを提供します。あらゆるストレージクラスのオブジェクトのアノテーションを、オブジェクトを復元したり、取得料金を支払ったりすることなくクエリできます。
アノテーションの開始方法
アノテーションの使用を開始するには、AWS Identity and Access Management (IAM) ポリシーまたはバケットポリシーが、s3:PutObjectAnnotation アクションと s3:GetObjectAnnotation アクションの許可を付与していることを確認してください。その後、PutObjectAnnotation API を使用して、既存または新規の S3 オブジェクトにアノテーションを追加できます。
例えば、メディア企業は、AWS コマンドラインインターフェイス (AWS CLI) を使用して、技術仕様と AI が生成した要約を動画アセットにアタッチできます。
# 技術メタデータを含む JSON ファイルを作成します
cat > mediainfo.json << 'EOF'
{"codec":"H.265","resolution":"3840x2160","audio_tracks":8,"frame_rate":29.97}
EOF
# それをアノテーションとしてアタッチします
aws s3api put-object-annotation \
--bucket my-media-bucket \
--key videos/documentary-2026.mp4 \
--annotation-name mediainfo \
--annotation-payload ./mediainfo.json
# AI が生成したプレーンテキストの要約を、別のアノテーションとしてアタッチします
echo "A 90-minute nature documentary covering wildlife migration patterns across three continents, featuring aerial footage and underwater sequences.Languages: English, Spanish, Portuguese." > ai_summary.txt
aws s3api put-object-annotation \
--bucket my-media-bucket \
--key videos/documentary-2026.mp4 \
--annotation-name ai_summary \
--annotation-payload ./ai_summary.txt
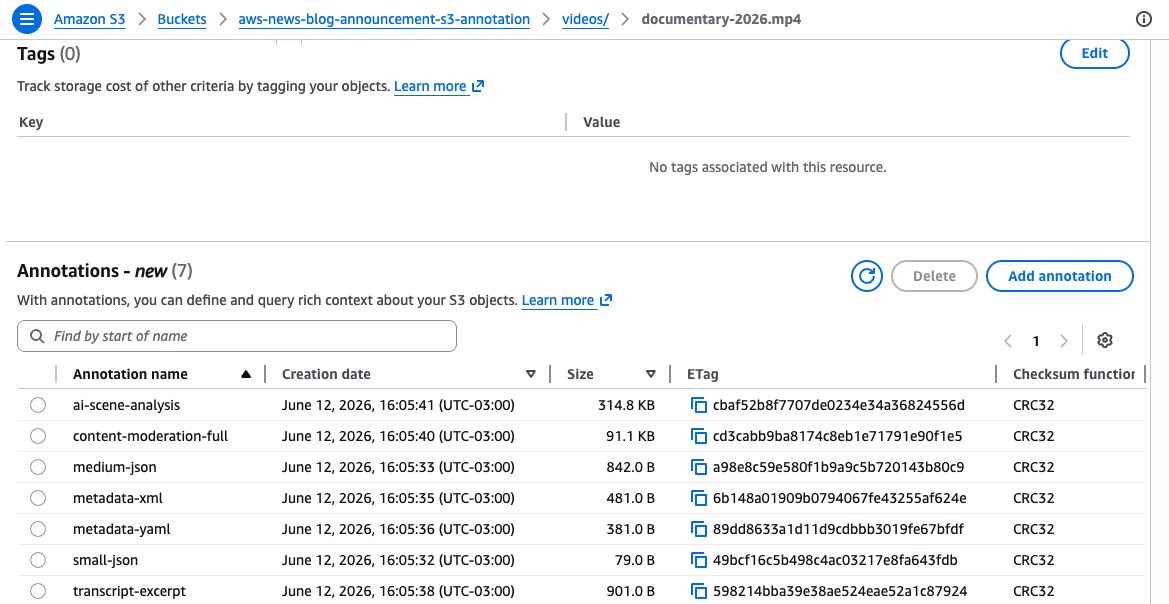
これらのコマンドは、2 つの別々のアノテーションを同じ動画オブジェクトにアタッチします。mediainfo アノテーションには構造化された技術仕様が JSON 形式で格納され、ai_summary アノテーションにはテキストの説明が格納されます。各アノテーションは一意の名前で識別され、それぞれを個別に読み取り、変更できます。各アノテーションの一意の名前により、異なるアノテーションを使用して、複数の同時実行エンリッチメントワークフローをサポートできます。例えば、あるチームが技術メタデータを追加し、別のチームがコンテンツ分類を追加するといった作業を、互いに干渉することなく行うことができます。
GetObjectAnnotation API を使用して特定のアノテーションを取得します。
aws s3api get-object-annotation \
--bucket my-media-bucket \
--key videos/documentary-2026.mp4 \
--annotation-name mediainfo \
./mediainfo-output.json
オブジェクトにアタッチされているすべてのアノテーションを表示するには、ListObjectAnnotations API を使用します。
aws s3api list-object-annotations \
--bucket my-media-bucket \
--key videos/documentary-2026.mp4
特定のアノテーションが不要になった場合は、DeleteObjectAnnotation API を使用して削除します。
aws s3api delete-object-annotation \
--bucket my-media-bucket \
--key videos/documentary-2026.mp4 \
--annotation-name mediainfo
既存のアノテーションは、同じアノテーション名を指定して PutObjectAnnotation API を再度呼び出すことで、いつでも更新できます。マルチパートアップロードを使用してアップロードされた大きなオブジェクトの場合、マルチパートアップロードの完了後に PutObjectAnnotation API を使用してアノテーションをアタッチします。
S3 Metadata テーブルを使用した、アノテーションの大規模なクエリ
個々のオブジェクトにアノテーションをアタッチすることは便利ですが、その真の力は、すべてのアノテーションを大規模にクエリする際に発揮されます。バケットで S3 Metadata のアノテーションテーブルを有効にすると、S3 は、アノテーションテーブルと呼ばれるフルマネージド Apache Iceberg テーブルにアノテーションを自動でインデックス化します。Amazon Athena または Iceberg 互換のエンジンを使用して、アノテーションテーブルをクエリできます。
アノテーションテーブルを有効にするには、S3 コンソールまたは CreateBucketMetadataConfiguration API を使用します。次の例では、変更追跡用のジャーナルテーブルを保持し、ライブインベントリテーブルを無効にしつつ、アノテーションテーブルを有効にした新しいメタデータ設定を作成します。
{
"JournalTableConfiguration": {
"RecordExpiration": { "Expiration": "DISABLED" }
},
"InventoryTableConfiguration": { "ConfigurationState": "DISABLED" },
"AnnotationTableConfiguration": {
"ConfigurationState": "ENABLED",
"Role": "arn:aws:iam::123456789012:role/S3MetadataAnnotationRole"
}
}
この設定により、S3 は、クエリ可能なテーブルのすべてのアノテーションを自動的にキャプチャします。適用されると、このバケット内のオブジェクトにアタッチしたアノテーションは、約 1 時間以内にテーブルに表示されます。
メタデータ設定が既にバケットに存在している場合は、UpdateBucketMetadataAnnotationTableConfiguration API を使用します。
aws s3api update-bucket-metadata-annotation-table-configuration \
--bucket my-media-bucket \
--annotation-table-configuration '{"ConfigurationState":"ENABLED","Role":"arn:aws:iam::123456789012:role/S3MetadataAnnotationRole"}'
有効にすると、アノテーションは自動的にアノテーションテーブルに反映されます。ジャーナルテーブルはほぼリアルタイムで更新されますが、アノテーションテーブルは 1 時間以内に更新されます。事前定義済みのスキーマを必要とする従来のメタデータテーブルとは異なり、アノテーションテーブルは、記述した JSON、XML、または YAML 構造に自動的に適応します。各アノテーションはテーブルの行となり、その内容は [text_value] 列に格納されます。これにより、スキーマ移行なしで、すべてのアノテーションをクエリできます。
既にアノテーション付きオブジェクトが存在するバケットでアノテーションテーブルを有効にすると、S3 は、既存のアノテーションを自動的にテーブルにバックフィルします。バックフィルプロセスはバックグラウンドで実行され、オブジェクトの数によっては数時間から数日かかる場合があります。
例えば、Amazon Athena を利用してバケット全体で 8 個を超える音声トラックを含むすべての動画アセットを検索するには、次のクエリを使用します:
SELECT DISTINCT bucket, object_key
FROM "s3tablescatalog/aws-s3"."b_my_media_bucket"."annotation"
WHERE name = 'mediainfo'
AND CAST(json_extract_scalar(text_value, '$.audio_tracks') AS INTEGER) > 8
このクエリは、アノテーションテーブルをスキャンして mediainfo という名前のすべてのアノテーションを検索し、JSON コンテンツから [audio_tracks] フィールドを抽出して、カウントが 8 を超えるオブジェクトを返します。
あるいは、ジャーナルテーブルを通じて直近 24 時間以内に新しいアノテーションを受け取ったすべてのオブジェクトを検索するには、次のクエリを使用します:
SELECT bucket, key, version_id, record_timestamp, annotation.name
FROM "s3tablescatalog/aws-s3"."b_my_media_bucket"."journal"
WHERE record_timestamp >= (current_date - interval '1' day)
AND annotation.name IS NOT NULL
AND record_type IN ('CREATE_ANNOTATION', 'DELETE_ANNOTATION')
このクエリはジャーナルテーブルを使用して、アノテーションの変更をほぼリアルタイムで追跡します。これは、新規または削除されたアノテーションに対応するイベントドリブンのワークフローの構築に最適です。
また、Amazon SageMaker Unified Studio または S3 Tables MCP サーバーを備えた任意の IDE でエージェントを使用して、自然言語でアノテーションによるオブジェクト検索を実行することもできます。例えば、「2023 年に公開されたスペイン語の字幕付き PG 指定映画をすべて検索してください」と指示すると、数秒で結果が返されます。接続されていない複数のシステムにクエリする場合には数時間かかるでしょう。
今すぐ始めましょう
Amazon S3 アノテーションは、AWS 中国リージョンを含むすべての AWS リージョンで今すぐご利用いただけます。アノテーションテーブルは、S3 Metadata が利用可能なすべての AWS リージョンで利用可能です。
自律的にデータを検出する必要がある AI エージェントの構築、複雑なメタデータを持つペタバイト規模のメディアアセットの管理、アーカイブされたデータセットのコンプライアンスコンテキストの追跡のいずれを行う場合でも、アノテーションを使用することで、個別のシステムを管理することなく、リッチなメタデータをオブジェクトに直接アタッチできるスケールと柔軟性を活用できます。
アノテーションのストレージは、親オブジェクトが S3 Glacier または他のストレージクラスにある場合でも、常に S3 Standard 料金で課金されます。料金の詳細については、Amazon S3 の料金ページにアクセスしてください。
さらに詳しく知りたい場合や利用を開始するには、Amazon S3 Metadata の概要ページおよび Amazon S3 ドキュメントにアクセスしてください。フィードバックは、AWS re:Post for S3 宛てに、または通常の AWS サポート担当者を通じてお寄せください。
Daniel Abib
原文はこちらです。