Amazon Web Services ブログ
Amazon Kinesis Firehose, Amazon Athena, Amazon QuickSightを用いたVPCフローログの分析
多くの業務や運用において、頻繁に更新される大規模なデータを分析することが求められるようになっています。例えばログ分析においては、振る舞いのパターンを認識したり、アプリケーションのフロー分析をしたり、障害調査をしたりするために大量のログの可視化が必要とされます。
VPCフローログはAmazon VPCサービス内のVPCに属するネットワークインターフェースを行き来するIPトラフィック情報をキャプチャします。このログはVPC内部に潜む脅威やリスクを認識したり、ネットワークのトラフィック・パターンを調査するのに役立ちます。フローログはAmazon CloudWatchログに格納されます。いったんフローログを作成すれば、Amazon CloudWatchログを用いて見たり取り出したりすることができるようになります。
フローログは様々な業務を助けてくれます。例えば、セキュリティグループのルールを過度に厳しくしすぎたことによって特定のトラフィックがインスタンスに届かない事象の原因調査などです。また、フローログを、インスタンスへのトラフィックをモニタリングするためのセキュリティツールとして使うこともできます。
この記事はAmazon Kinesis Firehose、AWS Lambda、Amazon S3、Amazon Athena、そしてAmazon QuickSightを用いてフローログを収集し、格納し、クエリを実行して可視化するサーバーレス・アーキテクチャを構成する手順を示します。構成する中で、Athenaにおいてクエリにかかるコストや応答時間を低減させるための圧縮やパーティショニング手法に関するベストプラクティスを学ぶこともできることでしょう。
ソリューションのサマリ
本記事は、3つのパートに分かれています。
- Athenaによる分析のためにVPCフローログをS3へ格納。このセクションではまずフローログをLambdaとFirehoseを用いてS3に格納する方法と、格納されたデータにクエリを発行するためAthena上のテーブルを作成する方法を説明します。
- QuickSightを用いてログを可視化。ここではQuickSightとQuickSightのAthenaコネクタを用いて分析し、その結果をダッシュボードを通じて共有する方法を説明します。
- クエリのパフォーマンス向上とコスト削減を目的とした、Athenaにおけるデータのパーティション化。このセクションではLambda関数を用いてS3に格納されたAthena用のデータを自動的にパーティション化する方法を示します。この関数はFirehoseストリームに限らず、他の手段でS3上に年/月/日/時間のプリフィックスで格納されている場合でも使用できます。
パーティショニングはAthenaにおいてクエリのパフォーマンス向上とコスト削減を実現するための3つの戦略のうちの1つです。他の2つの戦略としては、1つはデータの圧縮、そしてもう1つはApache Parquetなどの列指向フォーマットへの変換があります。本記事では自動的にデータを圧縮する方法には触れますが、列指向フォーマットへの変換については触れません。本ケースのように列指向フォーマットへの変換を行わない場合でも、圧縮やパーティショニングは常に価値のある方法です。さらに大きなスケールでのソリューションのためには、Parquetへの変換も検討して下さい。
VPCフローログを分析するためのサーバレスアーキテクチャ
以下の図はそれぞれのサービスがどのように連携するかを示しています。
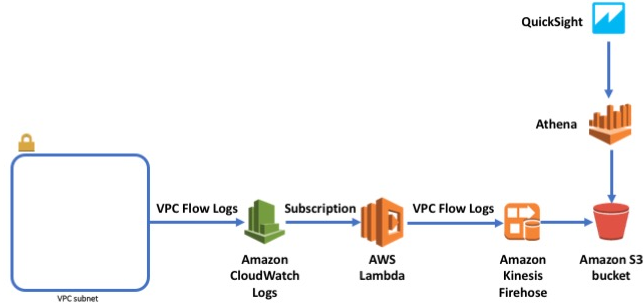
VPCにフローログを作成すると、ログデータはCloudWatchログのロググループとして発行されます。CloudWatchログのサブスクリプションを利用することにより、S3に書き込むためにFirehoseを用いたLambda関数に対して、リアルタイムにログデータイベントを送り込むことが可能になります。
いったんS3にログデータが格納され始めれば、Athenaを利用してSQLクエリをアドホックに投入することができます。ダッシュボードを構築したり、画面からインタラクティブにデータを分析したりすることを好む場合には、Athenaに加えQuickSightによるリッチな可視化を簡単に構成できます。
Athenaの分析を目的としたS3へのVPCフローログの送信
この章では、Athenaによるクエリを可能とするためにフローログデータをS3に送信する方法を説明します。この例ではus-east-1リージョンを使用していますが、AthenaとFirehoseが利用できるのであればどのリージョンでも可能です。
Firehoseデリバリーストリームの作成
既存もしくは新しいS3バケットを格納先とするFirehoseデリバリーストリームを作成するためには、この手順を参考にして下さい。ほとんどの設定はデフォルトで問題ありませんが、格納先のS3バケットへの書き込み権限を持つIAMロールを選択し、GZIP圧縮を指定して下さい。デリバリーストリームの名前は‘VPCFlowLogsDefaultToS3’とします。
VPCフローログの作成
まず、この手順に従ってデフォルトVPCのVPCフローログを有効にしましょう。(訳注:デフォルトVPC以外の任意のVPCで構いません。)
Firehoseに書き込むLambda用のIAMロールの作成
Firehoseに書き込むLambda関数を作成する前に、Firehoseにバッチ書き込みを許可するLambda用のIAMロールを作成する必要があります。次のように定義されるインラインアクセスポリシーを組み込んだ‘lambda_kinesis_exec_role’という名前のLambda用ロールを作成して下さい。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:*:*:*"
},
{
"Effect": "Allow",
"Action": [
"firehose:PutRecordBatch"
],
"Resource": [
"arn:aws:firehose:*:*:deliverystream/VPCFlowLogsDefaultToS3"
]
}
]
}
CloudWatchログからFirehoseに配信するLambda関数の作成
ログイベントをCloudWatchから先に作成したFirehoseデリバリーストリームである‘VPCFlowLogsDefaultToS3’に配信するためのLamdba関数を作成するには、次の手順を実施します。
- Lambdaのコンソールから一から作成を選択して新しいLambda関数を作成します。
- 基本的な情報ページでは関数に‘VPCFlowLogsToFirehose’と名付けます。さらにロールには先の手順で作成した‘lambda_kinesis_exec_role’を指定します。
- 関数コードにおいて、Python 2.7ランタイムを選択し、このGitHub上のコードをコードパネルにコピーします。環境変数にはDELIVERY_STREAM_NAMEという名前の変数を追加します。この変数の値には本手順の最初に作成したデリバリーストリームの名前(‘VPCFlowLogsDefaultToS3’)を設定します。また、タイムアウトは1分にします。

Lambda関数に対するCloudWatchサブスクリプションの作成
CloudWatchログにて、次の手順を実施します。
- VPCフローログのロググループを選択します(フローログを作成したばかりであればロググループが表示されるまで数分待つ必要がある場合があります)。
- アクションからLambdaサービスへのストリーミングの開始を選択します。

- 先の手順で作成したLambda関数 ‘VPCFlowLogsToFirehose’ を選択します。
- ログの形式は Amazpn VPC フローログ を選択します。
![]()
Athenaでのテーブル作成
Amazon Athenaは、特に他のインフラストラクチャをプロビジョニングしたり管理することなく、標準的なSQLによりS3に格納されたデータを問い合わせることを可能にします。AthenaはCSV、JSON、ParquetやORCなど様々な標準的なデータ形式を扱え、問合せ前にそれらのデータを変換する必要はありません。スキーマを定義し、そしてAWSマネジメントコンソールのクエリエディタやAthena JDBCドライバを使用したプログラムからクエリを実行するだけです。
AthenaはHiveメタストアと互換性のあるデータカタログにデータベースとテーブル定義を格納します。本記事では、フローログを1つのテーブル定義として作成します。テーブルに対するDDLについてはこのセクションの後半で述べます。DDL実行前に、次の点に注意しておいて下さい。
-
- DDL上の<bucket_and_prefix>はFirehoseからフローログの書き込み先として実際に作成したS3バケットの名前に書き換えます(プリフィックスも含めるのを忘れずに)。
- CREATE TABLE定義にEXTERNALというキーワードが含まれています。もしこのキーワードを除くと、Athenaはエラーを返します。EXTERNALキーワードはS3に格納されている元データに影響を与えずに、データカタログへテーブルメタデータを格納されるようにします。もし外部テーブルを削除したとしても、カタログからはメタデータが削除されますが、S3上のデータは維持されます。
- vpc_glow_logsテーブルのカラムはフローログレコード上のフィールドにマッピングされます。フローログレコードはスペース区切りの文字列を含みます。各行のフィールドを解析するために、Athenaはどのようにデータを扱うべきかを示すカスタムライブラリとしてシリアライズ-デシリアライズクラス、またはSerDeを用います。
- ここでは、スペース区切りのフローログレコードを解析するためにSerDe用の正規表現を指定します。この正規表現は”input.regex”というSerDeのプロパティによって提供されます。
Athenaのクエリエディタに以下のDDLを入力し、Run Queryをクリックして下さい。
Athenaでのデータ問合せ
テーブルを作成した後は、テーブル名の隣にある小さなアイコンからPreview tableを実行し、レコードセットのサンプルを確認しましょう(訳注:VPCフローログをクリーニングせずに投入しているため、サンプリングされる箇所によってはnullのレコードが表示される場合もあります)。


フローログを調査するために様々なクエリを実行することができます。ここでは例として、拒否されたトラフィックの中からソースIPアドレスのトップ25を取得してみます。

QuickSightによるログの可視化
QuickSightはわずか数度のクリックでAthena上のテーブルを可視化することを可能にします。AWSアカウントによってQuickSight上にサインアップすることができ、1GBのSPICEキャパシティ無料利用枠を持つユーザアカウント1つを取得できます。
QuickSightをAthenaに接続させる前に、ここで説明されている手順を参考に、QuickSightに対するAthena及び関連するS3バケットへのアクセス権限の付与を確認します。
QuickSightにログインし、Manage data→New data setと選択します。データソースとしてAthenaを選びます。

データソースに“AthenaDataSource”と名前を付けます。defaultスキーマ→vpc_flow_logsテーブルと選択します。

Edit/Preview dataを選択します。starttimeとendtimeのデータは数値形式よりも日付形式が適しています。これらの2つのフィールドはフローログのキャプチャウィンドウとシステムに到達した時刻をUnix時間で表現しています。
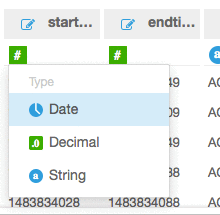
ここでSave and visualizeを選択します。
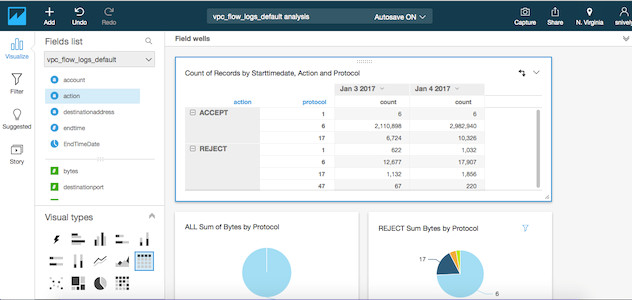
異なるstart timeのキャプチャウィンドウとその時の送信バイト数を見てみましょう。StartTimeとBytesをフィールドリストから選択することでそれが可能です。覚えておいて頂きたいのは、QuickSightはこれを自動的に通信量のタイムチャートとして可視化することです。異なる日付/時間単位への変更はとても簡単です。

これは、1日の中の通信で大きなスパイクがあった例です。この例はプロットされている他の日と比べてこの日に大量の通信が発生していることを教えてくれます。

データに含まれるポート、IPアドレスその他のファセットを通じて通信許可/拒否に関するリッチな分析を行うことも簡単です。作られた分析結果をダッシュボードとして同じ組織の他のQuickSightユーザに共有することもできます。
クエリのパフォーマンス向上とコスト削減のためのデータのパーティション化
ここまで述べてきたソリューションでは、S3に対して頻繁にGZIP圧縮されたフローログを配置します。Firehoseはこれらのファイルをデリバリーストリームの作成時に指定したバケット内に /year/month/day/hour というキーで格納します。Athenaでvpc_flow_logsテーブルを作成した時に使用していた外部テーブル定義には、この時系列キースペース内にある全てのファイルが含まれています。
Athenaはスキャンされたデータの量に応じて、クエリ毎に課金されます。ここまでのソリューションでは、クエリを発行する毎にS3に配置されたすべてのファイルがスキャンされます。VPCフローログの数が増加するに従い、データのスキャン量も増加し、クエリの応答時間やコストの両方に影響を与えることになります。
データの圧縮、パーティショニング、そして列指向フォーマットへの変換によって、クエリのコストを削減し、パフォーマンスを向上させることが可能です。Firehoseにて、既に圧縮された状態でS3へデータを配置するように設定されています。ここではパーティショニングに着目します。(Apache Parquetのような列指向フォーマットへの変換については本記事の対象外とします)
テーブルをパーティショニングすることで、クエリ発行時のデータスキャン量を制限することができます。多くのテーブルに置いて、特に発行するクエリの大半に時間ベースでの範囲制限が含まれる場合には、時間別での分割が有効です。AthenaはHiveのパーティショニング形式を使用します。これにより、パーティショニングの体系が直接反映されたkey-valueペアを含む名前付けをされたフォルダにパーティションが分割されます(詳しくはAthenaのドキュメントを参照)。
Firehoseにより作成されたこのフォルダ構造(例:s3://my-vpc-flow-logs/2017/01/14/09/)は、Hiveパーティショニング形式(例:s3://my-vpc-flow-logs/dt=2017-01-14-09-00/)とは異なります。しかし、ALTER TABLE ADD PARTITION文を用いると、手動でパーティションを追加してそのパーティションをデリバリーストリームによって作成されたキー空間の一部分に割り当てることができます。
ここでは、S3で新しいファイルを受信した際にALTER TABLE ADD PARTITION文を実行するためにLambda関数とAthena JDBCドライバを使い、自動的にFirehoseのデリバリーストリームに対する新しいパーティションを作成する方法を示します。
Athenaにてクエリを実行するLamba用のIAMロールの作成
Lambda関数を作成する前に、Lambdaに対してAthena上でクエリを実行することを許可するためのIAMロールを作成する必要があります。ユーザーガイドも参考に、次のように定義されるインラインアクセスポリシーを組み込んだ ‘lambda_athena_exec_role’ という名前のロールを作成して下さい。
パーティション化されたvpc_flow_logテーブルの作成
前の手順でAthena上に定義したvpc_flow_log外部テーブルはパーティション化されていません。‘IngestDateTime’という名前のパーティションを付したテーブルを作成するために、元のテーブルを削除して、次に示すDDLにてテーブルを再作成します。
Athenaのパーティションを生成するためのラムダ関数の作成
次の手順でLamda関数を作成します。
- GitHub上にあるLambda Javaのプロジェクトをクローンします。
- READMEファイルの手順に従って、ソースをコンパイルし、出力された.jarファイルをS3のバケットにコピーします。
- Lambdaコンソールから関数の作成を開始し、一から作成を選択します。
- 基本的な情報ページでは、名前に‘CreateAthenaPartitions’、既存のロールとして’lambda_athena_exec_role’を選択し、関数の作成をクリックします。
- 関数コードページに遷移します。ランタイムからJava 8を選択します。
- コードエントリタイプは、Amazon S3からのファイルのアップロードを選択します。S3リンクのURLには、先ほどアップロードした.jarファイルへのURLを入力します。
- ハンドラには’com.amazonaws.services.lambda.CreateAthenaPartitionsBasedOnS3Event::handleRequest’と入力します。
- このLambda関数のためには、いくつかの環境変数を設定する必要があります。
- PARTITION_TYPE: [Month, Day, Hour]のうちどれかの値を設定します。この環境変数はオプションです。もし設定しなかった場合、Lambda関数はデフォルトとして日次でパーティションを作成します。例:’Hour’
- TABLE_NAME: <データベース名>.<テーブル名>という形式で指定します。必須です。例:‘default.vpc_flow_logs’.
- S3_STAGING_DIR: クエリの出力が書き込まれるAmazon S3のロケーション。(Lambda関数はDDL文だけを実行していますが、Athenaはその結果もS3に対して書き込みます。前の手順で作成したIAMポリシーでは、クエリ出力バケット名は‘aws-athena-query-results-’で開始されると仮定しています)
- ATHENA_REGION: Athenaが動作するリージョンです。例:’us-east-1′

- 最後に、タイムアウトを1分に設定して保存します。
S3上の新しいオブジェクトをLambda関数に通知するための設定
VPCフローログデータを含むS3バケットのプロパティページにおいて、Eventsペインを開き、通知の追加を押して新たな通知を作成します。
- 名前: FlowLogDataReceived
- イベント: ObjectCreated(All)
- 送信先: Lambda function
- Lambdaドロップボックスから‘CreateAthenaPartitions’を選択

これで、FirehoseによりS3バケットにファイルが配置される度に、‘CreateAthenaPartitions’ 関数がトリガーされます。この関数は新たに受信したオブジェクトのキーを解析します。キーの year/month/day/hour という部分に基づいて、関数作成の際に環境変数で指定したPARTITION_TYPEの設定(Month/Day/Hour)に従い、そのファイルがどのパーティションに属するかを判断します。次に、このパーティションが既に存在するかどうかをAthenaに問い合わせます。存在しなければ新たにパーティションを作成し、S3のキー空間の関連部分にマッピングします。
このロジックを詳しく見てみましょう。時間単位のパーティションを作成するために ‘CreateAthenaPartitions’ 関数を作成し、Firehoseによりちょうどフローログデータのファイルが s3://my-vpc-flow-logs/2017/01/14/07/xxxx.gz に配信されたと仮定します。
新しいファイルのS3キーを見て、Lambda関数はそれが’2017-01-14-07’という時間単位のパーティションに属すると推測します。Athenaを確認すると、そのようなパーティションはまだ存在していないため、次のDDL文を実行します。
もしLambda関数が日次のパーティションとして作成されていた場合には、新しいパーティションは‘s3://my-vpc-flow-logs/2017/01/14/’ とマッピングされます。月次であれば ‘s3://my-vpc-flow-logs/2017/01/’ となります。
パーティションは、各ログがS3に取り込まれた日時を表しています。これは、各パーティションに含まれる個々のレコードのStartTimeやEndTimeの値よりも後の時間であることに注意して下さい。
Athenaを用いたパーティション化されたデータへの問合せ
これで、問合せはパーティションを利用できるようになりました。
過去3時間以内に取り込まれたデータを問い合わせるには、次のような問合せを実行します(ここでは時間単位のパーティショニングを行っていると仮定します)。
次の2つのスクリーンショットが示しているのは、パーティションを利用することでスキャンするデータ量を減らせるということです。そうすることで、クエリのコストと応答時間が削減できます。1つめのスクリーンショットはパーティションを無視したクエリの結果です。

2つめのスクリーンショットは、WHERE句でパーティションの使用を指示したクエリの結果です。

このように、パーティションを用いることで2つめのクエリは半分の時間で済み、データのスキャン量は最初のクエリの1/10以下にできたことがわかります。
結論
以前は、ログ分析というのは特定のクエリのためだけに大規模なデータを準備しなければならなかったり、大規模なストレージやマシンリソースを準備したり運用したりする必要がありました。Amazon AthenaとAmazon QuickSightによって、ログデータの発行から格納、分析、そして視覚化まで、より柔軟性高く実現することができるようになっています。クエリを実行してデータを視覚化するのに必要なインフラストラクチャに焦点を当てるのではなく、ログの調査に集中できるようになるのです。
著者について

Ben Snively – a Public Sector Specialist Solutions Architect. 彼は政府や非営利団体、教育組織の顧客におけるビッグデータや分析プロジェクトについて、AWSを用いたソリューションの構築を通じた支援に従事しています。また、彼は自宅にIoTセンサーを設置してその分析も行っています。

Ian Robinson – a Specialist Solutions Architect for Data and Analytics. 彼はヨーロッパ・中東・アジア地域において顧客が持つデータを結びつけることによる価値の創出のためにAWSを利用することを支援しています。また彼は現在、1960年代のダーレク(Dalek)の複製を修復する活動をしています。
(翻訳はSA五十嵐が担当しました。原文はこちら)
関連文書
Analyze Security, Compliance, and Operational Activity Using AWS CloudTrail and Amazon Athena