Amazon Web Services ブログ
グラフデータを使用した Network Digital Twin と Agentic AI を活用した被疑箇所の特定
本記事は 2025 年 8 月 18 日に公開された Beyond Correlation: Finding Root-Causes using a network digital twin graph and agentic AI を翻訳したものです。翻訳はソリューションアーキテクトの宮崎友貴が担当しました。
本稿では、NTT ドコモの通信ネットワークの運用の自動化・可視化部門の責任者である前島一夫氏と、同社通信ネットワークサービス監視・可視化担当の DevOps チームのマネージャー兼技術リーダーである今井識氏について取り上げます。両氏は AWS と提携し、グラフデータを活用した Network Digital Twin を実現する AWS ソリューションの MVP ( Minimum Viable Product ) 検証を行いました。
複雑なネットワーク障害が発生すると相関関係のある複数のアラームを精査する必要がありますが、これらのアラームは障害の実際の問題ではなく、大抵は症状を示しており、根本原因の特定には何時間もの調査を必要とすることがあります。根本原因分析(Root-cause analysis: RCA)システムは、多くの場合、定義されたルール、静的な閾値、事前定義されたパターンに基づいて作られており、全てのケースには対応しきれていません。ネットワークレベルの障害やサービスレベルの低下をトラブルシューティングする際に、これらの厳密な定義によるルールセットでは、連鎖的な障害や複雑な相互依存関係に適応できていない場合があります。
本稿では、グラフと Agentic AI を用いた Network Digital Twin を実現する AWS ソリューションアーキテクチャをご紹介します。また、AWS 上で Agentic AI を活用したグラフベースの RCA を実現する 4 つの Runbook デザインパターンをご紹介します。最後のセクションでは、4 つのうちの最初の Runbook デザインパターンを NTT ドコモが実際の商用ネットワークで検証された事例をご紹介します。この検証では、トランスポートネットワークおよび無線アクセスネットワークにおける複雑な障害ケースにおいて、15 秒 の MTTD (平均検知時間) という短時間での被疑箇所特定を実現しました。
根本原因分析 ( RCA ) における課題
通信分野における RCA とは、3rd Generation Partnership Project (3GPP) では「複数のエラーの原因となる障害を特定する体系的なプロセス」、GSM Association (GSMA) では「単に症状に対処するのではなく、根本原因を特定して対処するための構造化された手法」と定義されています。通信分野における RCA は、数十年にわたり、主にアラーム、主要業績評価指標(KPI)、ログ、その他のテレメトリの関係性を導き出し、そこから得られた特徴量を機械学習(ML)およびディープラーニング(DL)パイプラインに投入することで実現されてきました。
今日の実際の現場では、障害の特定には依然として定義済みの閾値と相関ベースの経験則に基づく問題解決アプローチであるヒューリスティックが主に利用されており、多くの場合、機械学習やディープラーニングの技術が補完的に用いられています。しかし、これらのアプローチは、複数のドメインエキスパートが複雑な状況を回避しながら真の RCA に到達するのに時間を要するプロセスが発生し、根本原因の特定にかかる時間が平均して数時間程になることが多く、現代のネットワークのオペレーションには不十分です。 誤った RCA は、実際の根本原因ではない部分への対処に人員が割り当てられてしまうといった現場のオペレータによる介入が要因の 1 つです。
相関関係から因果関係へ
NTT ドコモとの、無線アクセスネットワーク(RAN)およびトランスポートネットワークにおける RCA に関する協業、および世界中のお客様やパートナーとの協業を通じて、根本原因分析(Root Cause Analysis)の取り組みを再考し、単なる相関関係ではなく真の因果関係を捉えることに着目しました。私たちのアプローチは、「相関は因果関係を示唆しない」という既知の統計原理に基づいています。相関関係は 2 つの変数がどれだけ強く連動しているかを測定するのに対し、因果関係は一方の変数の変化がもう一方の変数の変化にどれだけ影響を与えるかを示します。
では、グラフデータ化された Network Digital Twin とは一体何でしょうか。ネットワークのリアルタイムでの鏡像、つまり現状を示すだけでなく、次に何が起こるかを予測するシミュレーションと捉えてみてください。Network Digital Twin によってネットワークの因果関係を把握することで、ネットワークの将来の振る舞いを予測してシミュレーションできるということです。これは、ネットワークの挙動を理解する Agentic AI による動作フローを通じて実行される、異常検知、グラフベースの予測、生成 AI により実現されています。その仕組みを簡単に説明します:
- 全てのネットワークセグメントとレイヤーに跨った複数のデータソースから、ネットワークの依存関係(ノード同士の関係性)と、発生中のアラームと、KPI(トラフィックデータなど)を取り込み、分析します。
- それらをネットワークナレッジレイヤーと呼ばれるトポロジーを考慮したグラフデータ構造に変換します。
- Agentic AI レイヤーで、入力されたネットワークに関するデータを、グラフ分析アルゴリズムやグラフ上のディープラーニングを組み合わせて分析し、データに基づいて 1 つまたは複数の専用の RCA Runbookを起動します。
次のセクションでは、ネットワークナレッジ、Agents / Agentic AI フロー、RCA Runbook という 3 つの中核となる要素について詳しく説明します。
ソリューションアーキテクチャ概要:ネットワークナレッジ、Agentic AI、Runbook デザインパターン
RCA 向けグラフソリューションアーキテクチャとしての Network Digital Twin は、NTT ドコモの商用ネットワークである RAN およびトランスポート網において検証済みであり、また、欧州の顧客向けに変更管理やサービス影響評価などのユースケースにも導入されています。ネットワークグラフ上に Agentic AI を搭載した Runbook は、現在 AWS パートナーと共同で世界中のさまざまな顧客向けに実装されているデザインパターンであり、RAN、伝送網、5G Core、トランスポート、サービスレイヤーなど、様々なネットワーク領域を跨った RCA を対象としています。
ネットワークナレッジレイヤー
ネットワークナレッジレイヤーは、ネットワーク関連のすべてのデータや情報を統合し、クエリ可能な構造化形式に変換し、分析、機械学習、深層学習、そしてエージェントレイヤーでの意思決定を可能にするためのデータ基盤です。これは専用のデータ処理パイプラインによって構築されます。マニュアル手順書とネットワーク設計に関するドキュメントは検索可能な形式に変換されて Amazon S3 Vectors に保存され、ネットワークトポロジーデータとネットワークのインターフェース情報から抽出された依存関係(ノード間の接続情報)は Amazon Neptune グラフデータベースに保存されます。パフォーマンスメトリクスは Amazon Timestream にストリームされ、インシデントチケットはアラームデータと共に Amazon DynamoDB に格納されます。アラーム、KPI、チケット管理/変更管理に関する履歴データや古い情報は Amazon S3 に保存されます。AWS Glue と AWS Lambda 関数は、バックグラウンドで動作し、これら全てのデータを処理し格納先へ送信します。その結果、リアルタイムで更新され続けるネットワークナレッジが得られ、エージェントの根本原因分析用のデータ基盤となります。次の図は、ネットワークナレッジレイヤーがこれらの AWS サービスを統合して、RCA オペレーションのための統合データ基盤を構成するアーキテクチャを示しています。
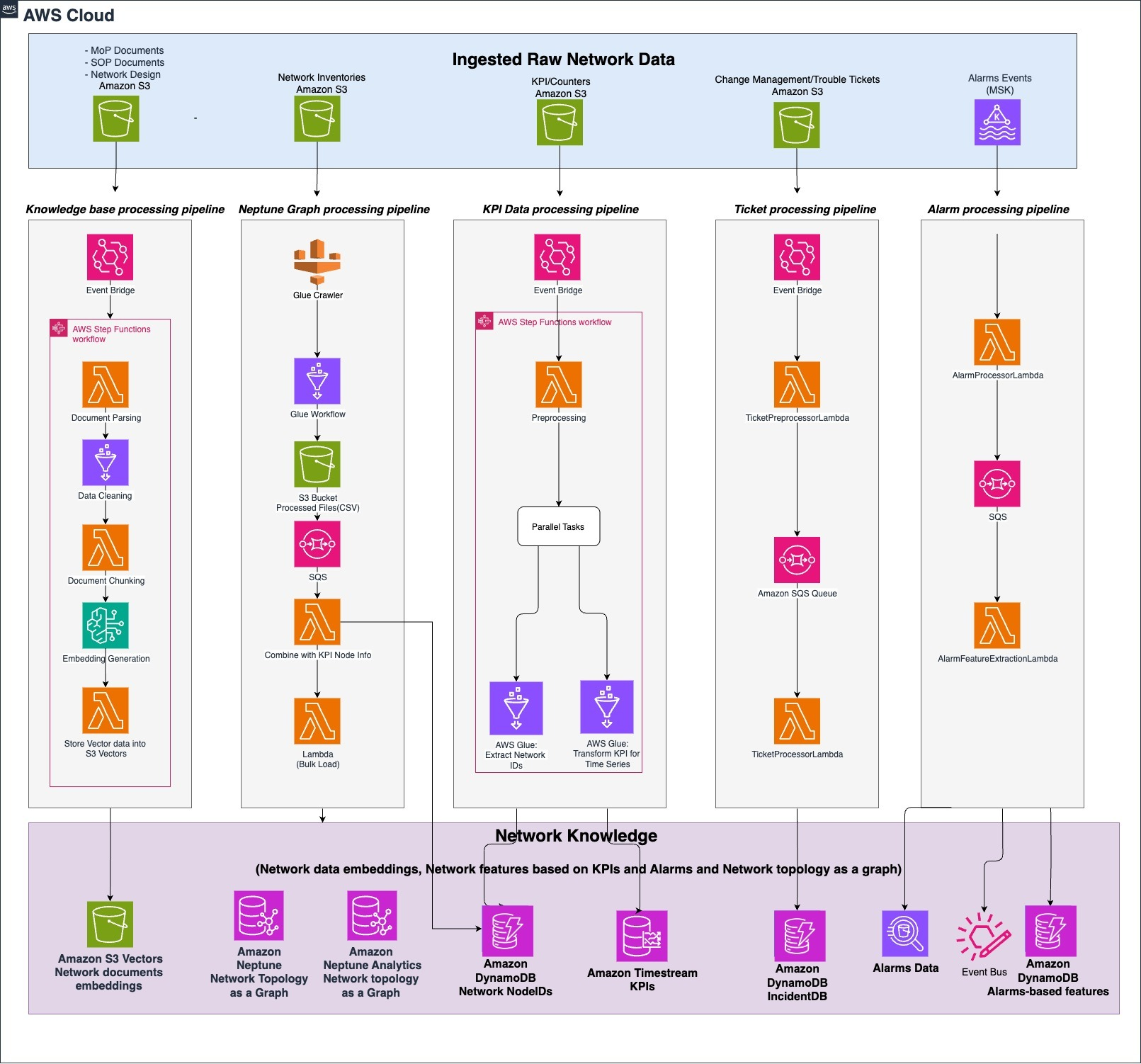 図 1. ネットワークナレッジレイヤー
図 1. ネットワークナレッジレイヤー
HLD アーキテクチャ概要と RCA Agentic AI レイヤー
前述のとおり、ネットワークナレッジは、Amazon Neptune が動的に変化するネットワークトポロジーを保持する基盤であり、アラーム、KPI、インシデント履歴、テレメトリストリームから得られるリアルタイムデータにより強化されています。本セクションで説明する RCA ワークフローは、アラームの発生パターン、KPI の異常検知や予測値との乖離の検知、ノードの重要度または障害伝播の可能性を表すグラフデータのスコアリングなどの様々なトリガー条件に基づいて起動されます(詳細は後述の各 Runbook で説明します)。これらの起動条件が満たされると、1 つ以上の RCA Runbook が実行され、診断および切り分け処理が実行されます。
ソリューションの中核を担うのは、Strands Agents で構成される Agentic AI レイヤーであり、Strands Agents のライフサイクル管理は Amazon Bedrock AgentCore によって行われます。各エージェントは、異常相関、予測値からの乖離の検出、依存関係を表すトポロジーグラフの構築、インシデントチケット管理などの各タスクを実行します。これらのエージェントは、RCA オペレーターが受信したデータに基づいて行った推論に応じて、Swarm ワークフローまたは DAG でトリガーされます。次の表は、必要なコアとなるエージェントを示しています。
| エージェント | エージェントの行うタスクの定義 |
| RCA operator | 各トリガー (アラームの大量発生、異常検知、予測と実績値の乖離の検知など) を検出し、対応する Runbook 1 ~ 4 を選択し、起動するエージェントを指定します。各ステップごとの処理を策定し、各エージェントに実行時の引数 (隣接ノードのホップ数、時間幅、閾値など) を渡し、実行結果を共有ダッシュボードに記録します。その後、新しい障害データやオペレーターからのフィードバックを得られる度に処理内容を更新します。 |
| Known-incident matcher | ナレッジベースから一致するインシデントを分析し、IKB (インシデントナレッジベース)で発生アラームや異常値、予測傾向、パターンを検索し、ベクトル類似性を算出し、信頼度の閾値による評価をして、一致したインシデントのケース ID や信頼度を返します。 |
| Dependency graph builder | アラーム発生ノードのサブグラフを抽出します。具体的には、Amazon Neptune に対して、Gremlin または SPARQL を使用して node_ID 周辺の接続関係を表すグラフデータをクエリし、最大 N ホップ先のノードまで拡張して取得します。結果となるサブグラフがグラフ追跡アルゴリズムの実行に十分になるまで反復処理を行います。 |
| Root-cause finder | Neptune Analytics の組み込みのグラフ分析アルゴリズムを呼び出すロジックを策定し、ネットワークノードに分析結果として出力されるスコアを付けます。具体的には、入力された特定のサブグラフ ID に対して、グラフのサイズや密度に基づいて Neptune Analytics の分解アルゴリズムやクラスタリングアルゴリズムやランク付けアルゴリズムを選択し、あるいは組み合わせて実行し、上位 K(デフォルトは10)の <node_ID, score (分析結果となるスコア)> を返します。 |
| Anomaly correlator | node_ID とルックバックウィンドウ (例:15 分) の KPI を使用して Amazon SageMaker 異常検知エンドポイントを呼び出し、返り値である anomaly_score (異常値) が閾値より大きいサンプルにフラグを付け、それらを発生中のアラームとマージするといった、統計的戦略を実行します。 |
| Forecast-drift monitor | 各 KPI について、期間 H における ST-GNN* 予測エンドポイントを照会し、残差 r = |実際値 – 予測値| を計算します。次に、残差 r > σ × band_factor の場合に偏差としてフラグを立てます。ここでの σ は、KPI とタイムスタンプの予測の標準偏差です。ここでの band_factor は、ユーザー定義の乗数です(例:95 % バンドの場合は、1.96)。最後に、フラグが立てられた偏差を同時発生しているアラーム群とマージします。 |
| Recent-events collector | それぞれの被疑ノードについて、最後の T 分間のアラームまたは KPI を取得し、目標イベント密度が達成されるか T_max (時間)に達するまで T を拡大または縮小し、時系列のイベントリストを出力します。 |
| MoP analyzer | 装置の種類、ベンダー、またはソフトウェアバージョンを検出し、障害情報からベクトル検索を行い、最も関連性の高い切り分けのためのコマンドやその説明を出力します。 |
| Incident-report builder | 被疑としてランク付けされたノード、タイムライン、MoP の抜粋を組み合わせ、構造化されたインシデントログを作成し、影響度の経験則からチケットまたはRCAレポートを作成します。チケット発行の場合は、チケット作成 API を呼び出して作成し、作成されたチケット ID を記録し、#noc-urgent でタグ付けしてアラートを通知します。 |
| Ticket manager | インシデントチケットのステータスフラグが「ticket」の場合、チケットが作成または更新され、チャネル名に通知が投稿され、現在のチケットと過去のチケットに関するチャットが提供され、そのリンクが共有ダッシュボードに保存されます。 |
| Operator feedback recorder | ネットワークオペレーションセンター (NOC) からの Agentic AI が作成したレポートに対するフィードバックを記録し、チケット ID、決定事項、およびオペレータのメモを IKB に書き足します。これによって AI エージェントの継続的な学習が可能になります。 |
| Guardrails policy advisor | 個人を特定できる情報 (PII) は含まないこと、承認されたファームウェアであること、変更オペレーションを実行可能な時間帯でのコマンドであること、などのガードレールを適用し、SLA (影響ユーザー数が 50 人を超える場合、または、平均復旧時間 (MTTR) が 30 分以下の場合は、10 分でエスカレーションを行う、など) をチェックし、それらのガードレールに違反する Procedure-Finder アクションをブロックし手順として参照されることを回避します。違反があった場合は、インシデントを非準拠としてマークし、チケットを P1-URGENT にアップグレードして、NOC チームに警告します。 |
| OpsMemory | エージェントの共有レポジトリには、各エージェントからの中間出力 (生データへのリンク、サブグラフの JSON データ、ランク付けされたノード、異常フラグ、MoP スニペット、チケット ID など) が保持、記憶されるため、各エージェントはそれらを共通的に読み取ることができます。エントリのバージョン管理や、インシデントのクローズ時にそれらのデータをクリアすることも可能です。 |
| Other agents | 通信事業者やパートナーによっては、ネットワークセグメントごとのエージェントフローを強化するために、RAN (無線アクセス ネットワーク) エキスパートエージェントや IMS セッションエージェントなど、その他の専用エージェントを追加することもあります。 |
*ST-GNN ( Spatial-Temporal GNN ): 空間的(Spatial)および時間的(Temporal)な依存関係を同時にモデル化するために設計されたグラフニューラルネットワーク(GNN)の一種
次の図は、4 つの Runbook にわたる RCA 用 Agentic AI の HLD アーキテクチャを示しています。
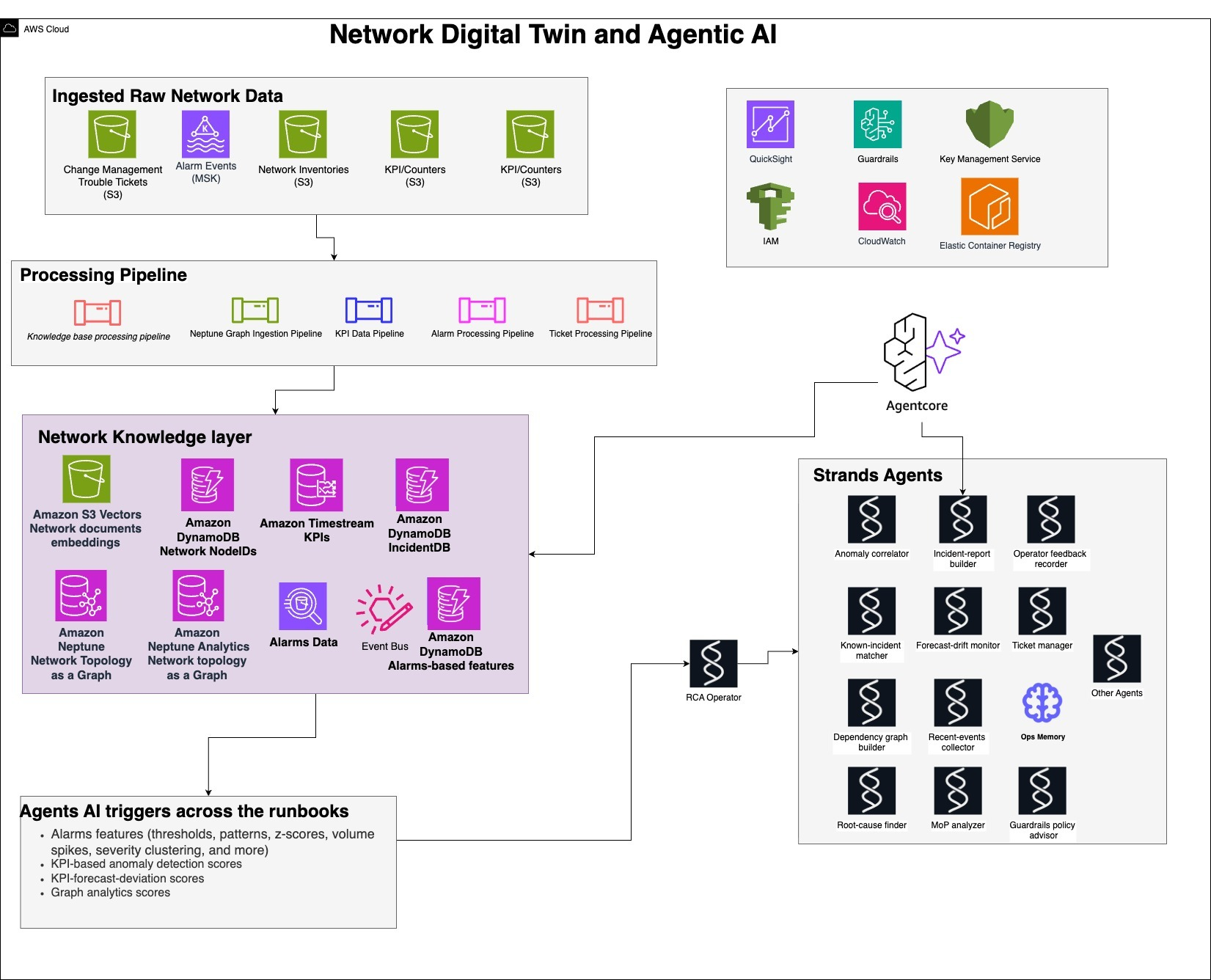
図 2. ソリューション概要
Runbook 1 ベースライン : グラフ分析と Agentic AI
アラームは、インシデント発生時またはスケジュールに基づいて、ライブストリームとして取り込まれます。アラームが発生すると、根本原因分析用に構築された専用の AWS Lambda 関数がトリガーされます。この関数は、受信したアラームデータから影響を受けるノード ID を抽出します。次に、Amazon Neptune から関連するネットワークのサブグラフを取得します。これらのサブグラフには、ネットワークノード間のすべての依存関係が含まれます。Amazon Neptune Analytics の組み込みのグラフ分析アルゴリズムを使って、サブグラフ構造を分解し、関連するノードをグループ化します。グラフ構造に対する RCA 用に、これらの Neptune Analytics アルゴリズムの具体的かつ実行可能なステップを定義しました。例えば、このステップには、1) WCC (弱連結コンポーネント) または SCC (強連結コンポーネント) によるグラフの分解、2) ラベル伝播によるグラフのクラスタリング、3) 中心性アルゴリズムによるネットワークノードのランク付けが含まれます。このアプローチについては、コードサンプルを含む続編のブログで詳細を説明します。これらのアルゴリズムは、アラームノードを含むネットワークサブグラフ内の構造的な重要度に基づいて、各ノードをランク付けします。
このランク付けに従い、エージェントは各候補となるノードの直近発生したアラームシーケンスを分析します。分析においては、過去数分( 2 ~ 5 分など)から開始し、アラームが少ない場合時間幅を拡大していきます。関連する手順書(MoP)を参照し、アラームの詳細と、障害が発生している各ノードに適した、障害の切り分けのためのコマンドを抽出します。
- エージェントはこれらの要素を使用して、障害ノード、アラームパターン、隣接ノード、インシデントの説明、推奨アクションを含むレコードを作成します。
- インシデントチケットを作成または更新し、レコード、完全なアラームタイムライン、および抽出した MoP の抜粋をチケットに記載します。チケットが開かれていない場合、エントリはRCAレポートとして表示され、NOCチームがレビューします。
- NOC チームは出力されたレポートを検証または拒否することができ、そのフィードバックはエージェントの記憶メモリを通じて取得され、インシデントデータベースに記録されます。
この Runbookでは、アラームが基本的なトリガーとなり、決定論的なアプローチであるグラフ分析によって障害領域が特定され、Agentic AI によって元のスコアが継続的なフィードバックループによって実用的なインシデントレコードに更新されていきます。次の図は、ソリューションのアーキテクチャ図を示しています。
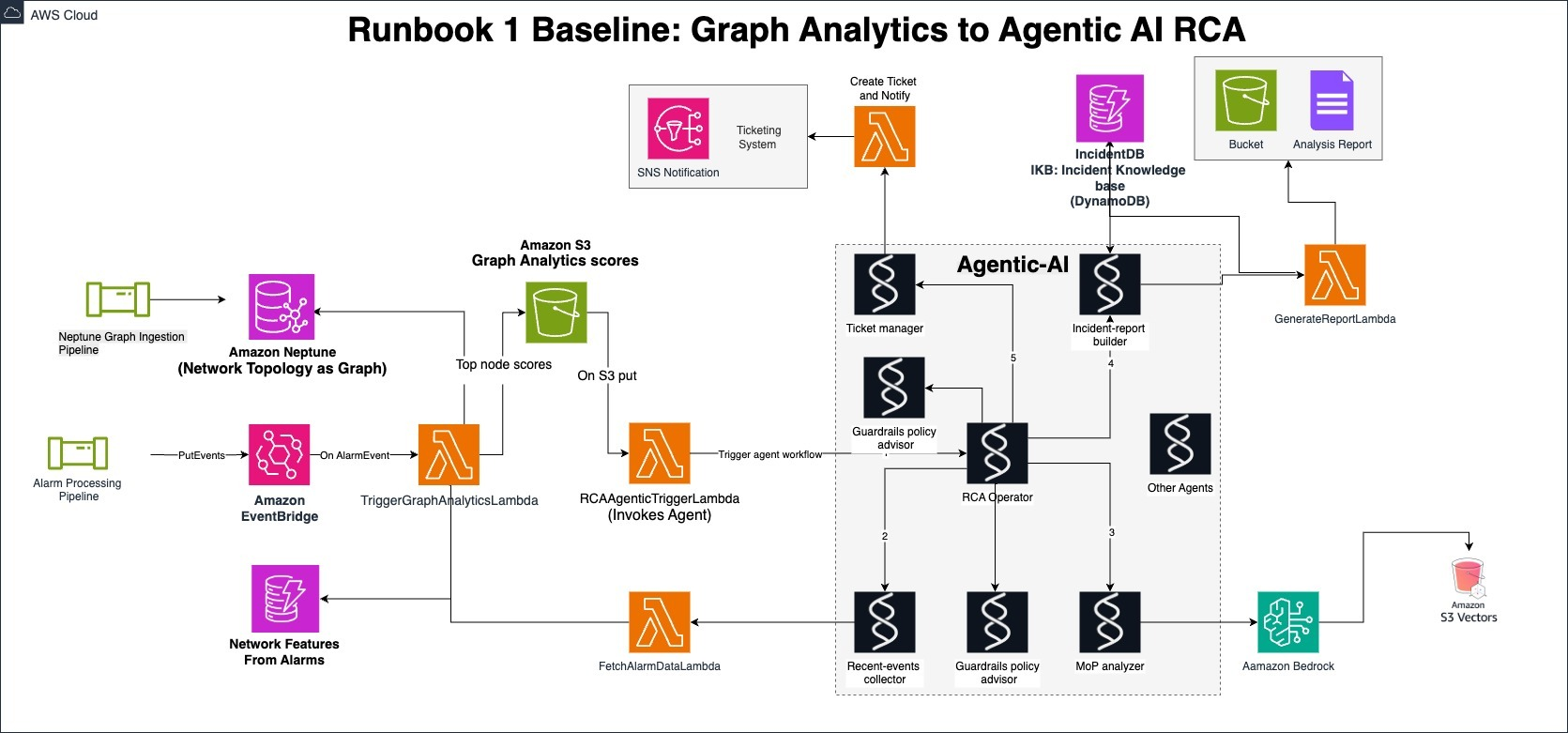
図 3. Runbook 1: グラフ分析と Agentic AI による RCA
Runbook 2: エージェントによる既知のアラームパターンマッチ
アラームは、Runbook_1 と同様に、継続的実行、オンデマンド実行、または定期実行によって受信します。個々のアラームは RCA 用の Lambda 関数を直接呼び出すことはありません。代わりに、受信ストリーム内のスパイクや異常なパターンを検出するようなアラーム機能に基づくトリガー方式を使用します。これには、アラーム数の監視、ベースラインからの Z スコアの偏差、アラーム重要度のクラスタリング、連鎖的な障害ケース(基地局に障害が発生し、影響を受けるすべての装置でアラームが発行される場合など)が含まれます。このトリガーが発動すると、RCA 固有の Lambda 関数が呼び出され、Agentic AI ワークフローが起動されます。その後、以下の手順が実行されます。
- 最初のステップは、インシデントナレッジベースです。受信アラームのパターンまたはシーケンスが過去のインシデントと高確率で一致する場合、エージェントはチケットを更新またはオープンし、定義済みの対処方法を適用してフローを終了します。
- 一致するものがない場合、エージェントはグラフ駆動型の追加分析を実行します。
- アラームが発生しているノード ID を抽出し、その依存関係にある隣接ノード(最大 N ホップ先)まで展開し、Runbook_1 で行われたのと同様に、障害発生中のサブグラフを抽出します。
- より詳細な分析のために、Neptune Analytics を使用して、分解、クラスタリング、ランク付けアルゴリズムを実行し、出力されたスコアを収集し、上位 10 のノードを抽出します。
- エージェントは各ノードについて、直近のアラーム履歴(通常、2 分または 5 分などの時間範囲ですが、データのスパース性により長い期間にするべき場合があります)を取得し、関連する MoP (手順書)を参照し、障害ノード、アラームのパターン、隣接ノード、インシデントの説明、推奨アクションで構成される構造化レコードを作成します。
- レコード、過去の類似ケースへのリンク、抽出した MoP スニペットを記載して、新しいチケットを作成します。もしくは既存のチケットに追記して更新します。
- エージェントは、NOC からのフィードバックを記憶メモリから取得し、インシデントナレッジベースに記録します。
次の図は、Runbook_2 ソリューション アーキテクチャの例です。
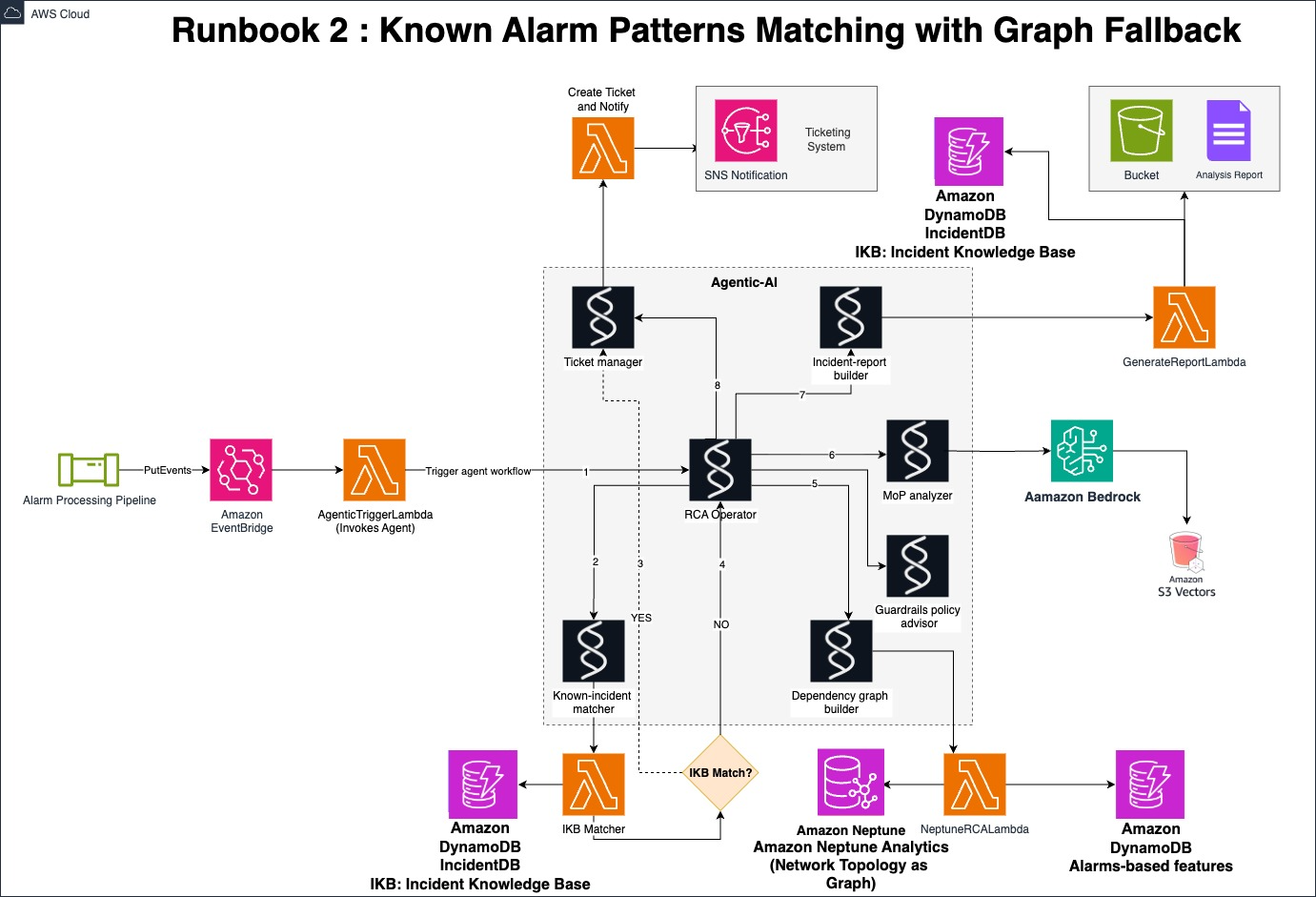
図 4. Runbook 2: エージェントによる既知のアラームパターンマッチ
Runbook 3 複数のシグナルを融合した異常検知 RCA(弱いシグナルの検出)
アラームは依然として主要なシグナルですが、リアルタイムな KPI ベースの異常検知スコアによってネットワークの異常をより検知できるようになります。本 Runbook では、Agentic AI ワークフローはアラーム発生ノードと異常を示すノードの組み合わせによってトリガーされます。Runbook 2 と同様に、アラーム数の急増、アラームの重要度のクラスタリング(分類)、Z スコア偏差といったアラーム分析機能に加え、KPI 異常検知スコアも含まれています。この組み合わせアプローチにより、NOC はアラームで検知する前のような目立たない兆候 (弱いシグナル) であっても異常として検知することができます。ワークフローは次のステップを実行します。
- エージェントは Runbook 2 と同様にインシデントナレッジベースにクエリを実行します。アラームシーケンスが既知のパターンと一致する場合、チケットを更新してフローを終了します。
- 一致しない場合、エージェントは次の処理を続行します。
- アラームの特徴(アラーム数の急増、アラームの重要度のクラスタリング、Z スコアの偏差)と ネットワークの KPI に基づく異常検知スコアを取得し組み合わせます。
- 複数ホップ先の依存関係のある隣接ノードに展開し、障害が伝播されたサブグラフを抽出します。
- Neptune Analytics を使って、分解、クラスタリング、ランク付けアルゴリズムなど、適切なアルゴリズムを選択もしくは複数のアルゴリズム組み合わせて実行します。
- 全てのノードにランク付けを行い、スコアの高いノードを被疑箇所として以降のステップに渡します。
- 被疑箇所として抽出されたノードごとに、エージェントはアラームと KPI 異常検知スコアの両方を、短いウィンドウ(2分または5分など)から開始し、必要に応じて延長しながら時系列で取得します。関連する MoP を参照し、障害ノード、アラームパターン、異常検知スコア、隣接ノード、インシデントの説明、推奨アクションを含むレコードをインシデントナレッジベースに記録します。
- エージェントは、NOC チームがレビューするための RCA レポートを生成します。
- NOC チームは、生成された RCA レポートの結果を承認または拒否することができ、それらのフィードバックはエージェントの記憶メモリに記録されます。
次の図は、Runbook 3 のソリューションアーキテクチャの例です。
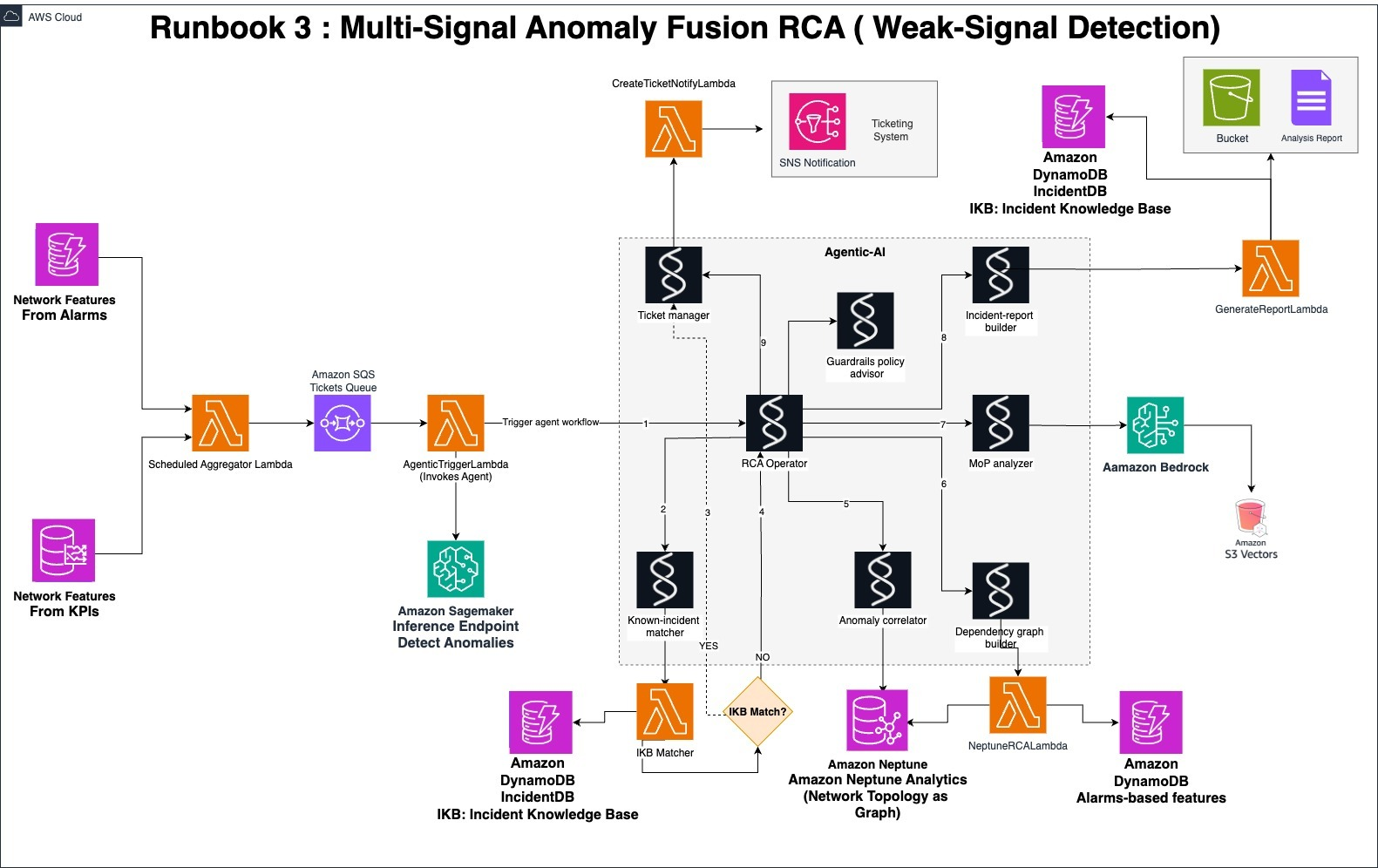
図 5. Runbook 3: 複数のシグナルを融合した異常検知 RCA(弱いシグナルの検出)
Runbook 4 予測からの乖離を検出する RCA (プロアクティブな検知)
アラームは基本的なシグナルとして機能しますが、ローリング型 Attention-based Spatio-Temporal Graph Neural Network(AST-GNN)から KPI 予測値からの逸脱を示すフラグが提供されます。このモデルは、ネットワーク装置ごとにトポロジと時間パターンを統合的に学習し、各 KPI の信頼区間を含む予測を生成します。実際の KPI が予測区間から外れた場合、絶対値が正常であってもシステムは偏差フラグを立てます。適切な特徴量エンジニアリングを適用したり、他のディープラーニングモデルを予測モデルとして用いることも可能です。Agentic AI ワークフローは、アラームの特徴とKPI 予測値からの逸脱を示すフラグの付いたノードの組み合わせによってトリガーされます。アラームの特徴とは、Runbook 1~3 と同様、アラーム数の急増、アラームの重要度のクラスタリング、Z スコア偏差といったアラームの分析結果であり、これらに加えて、KPI 予測値からの逸脱を示すフラグがトリガーとして含まれます。この予測アプローチにより、NOC は潜在的な問題が顕在化する前に異常を検知することができます。ワークフローは次のステップで実行します。
- エージェントは、以前の Runbook と同様に、インシデントナレッジベースを検索します。既存のインシデントと高い確率で一致するものが見つかった場合、チケットを更新し、フローを終了します。
- 一致するものがない場合、エージェントは以下の分析を実行します。
- アラームの特徴(アラーム数の急増、アラーム重要度のクラスタリング、Z スコアの偏差)を、KPI 予測値から逸脱したノードと組み合わせます。
- 複数ホップ先の依存関係のある隣接ノードまで拡張し、障害が伝播されたサブグラフを抽出します。
- Neptune Analytics を使用して、分解、クラスタリング、ランク付けアルゴリズムを実行します。
- 全てのノードに対して被疑箇所としてランク付けを行い、スコアの上位 10 ノードを抽出します。
抽出されたノードごとに、エージェントは、直近発生したアラームと KPI 残差曲線を取得します。これらの曲線は、短い期間( 2 分や 5 分など)で取得し始め、データがまばらで不足している場合は取得期間を長くします。関連する MoP を参照し、障害ノード、アラームパターン、予測の偏差、隣接ノード、インシデントの説明、推奨アクションを含むレコードを作成します。
エージェントは、レコードを記載したインシデントチケットを作成または更新し、RCA レポートを NOC に送付し、レビューを受けます。
NOC チームは、RCA レポートから Root Cause なのか、誤検知なのか、または新しいアラーム群なのかを確認します。NOC から得られたフィードバックは、エージェントの記憶メモリに記録されるだけではなく、 IKB (インシデントナレッジベース)にも記録されるため、将来の再発時により迅速な対処を行うことができるようになります。次の図は、Runbook_4のソリューションアーキテクチャの例を示しています。
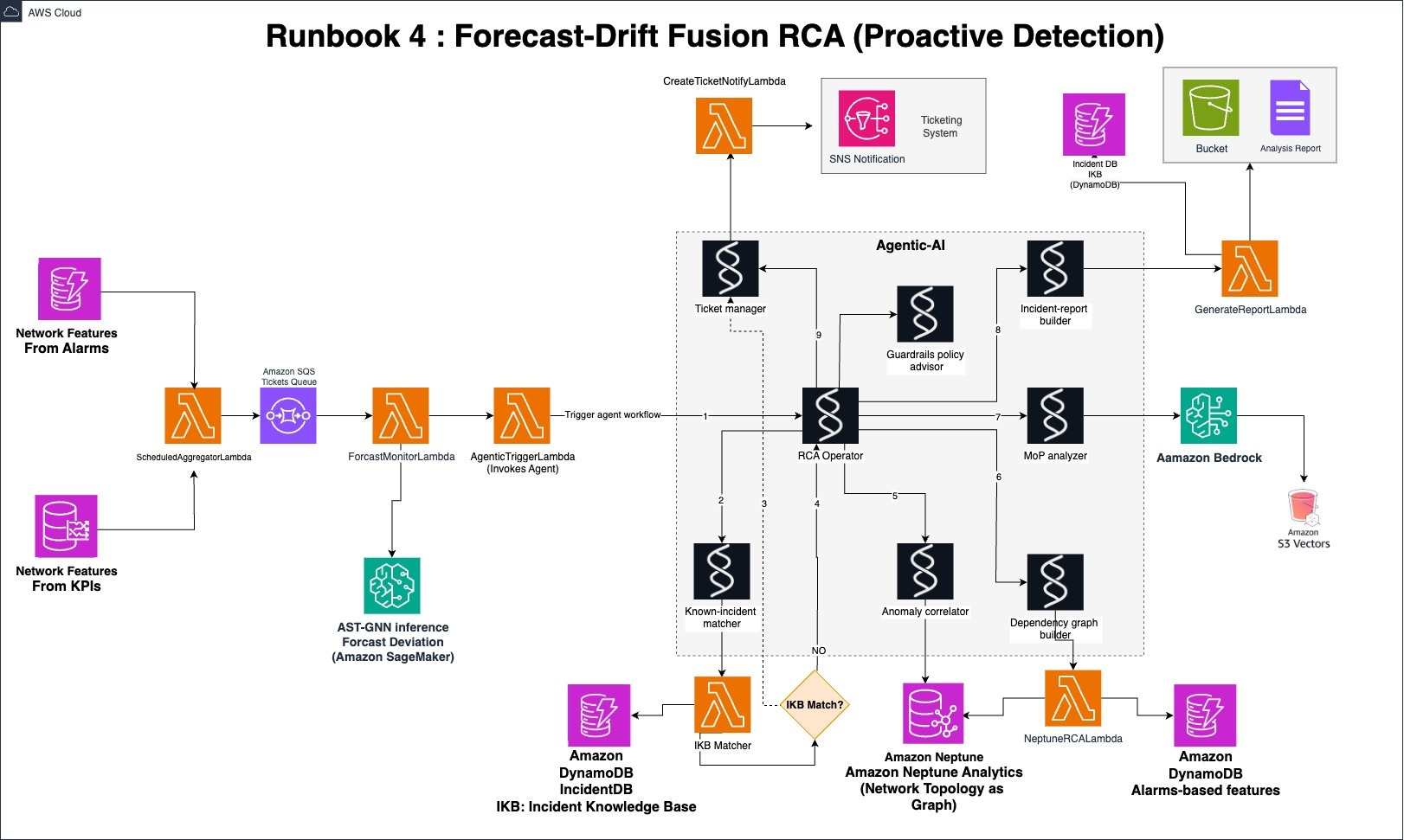
図 6. Runbook 4: 予測からの乖離を検出する RCA (プロアクティブな検知)
NTT ドコモのグラフデータを活用した Network Digital Twin
株式会社 NTT ドコモは、日本全国で 8,900 万人以上の加入者にサービスを提供する通信ネットワークを運用しています。このネットワークは、決済や物流データ、その他時間的制約が厳しいデータを運ぶ、国の重要なインフラの一部となっており、障害発生時には迅速な解決が求められます。しかし、デバイスとプロトコルの増加により、障害の特定はより複雑化し、時間がかかる場合があります。
NTT ドコモの運用チームは、障害を検知し、障害箇所を特定し、1時間以内にサービスを復旧させる必要があります。この時間を逃すと、NTT ドコモは顧客の信頼を失うことになります。
NTT ドコモは、トランスポートネットワークと 4G / 5G RAN を対象とし、RCA プロセスの変革を開始しました。AWS に取り込まれるデータには、5 分ごとのネットワークのパフォーマンスデータと、トランスポートネットワークから無線基地局までのパス全体をカバーするイベントベースのアラームが含まれています。
より具体的には、トランスポートネットワークのエッジルーターでは、受信トラフィックと送信トラフィックのバイト数とパケット数が、合計値、ユニキャスト、マルチキャスト、ブロードキャストパケットごとに、累積値と定期値の両方が記録され、加えて重要度の高いアラーム数も記録されます。中間パスとなる集約ルーターは、パケットレベルの統計データの合計値、平均値、破棄数、エラー数に加え、自身の重要度の高いアラーム数も記録します。evolved Node B( eNB、4G / LTE 基地局)や next-generation Node B( gNB、5G 基地局)では、収集されるデータは無線関連のメトリクスになります。これらの指標には、イーサネットの受信・送信レートと破棄率、無線リソース制御( RRC )接続要求数、完了数、再試行数、および重要度の高いアラーム数が含まれます。
NTT ドコモ の RCA のために設計した Amazon Neptune におけるグラフデータモデリングの抜粋:
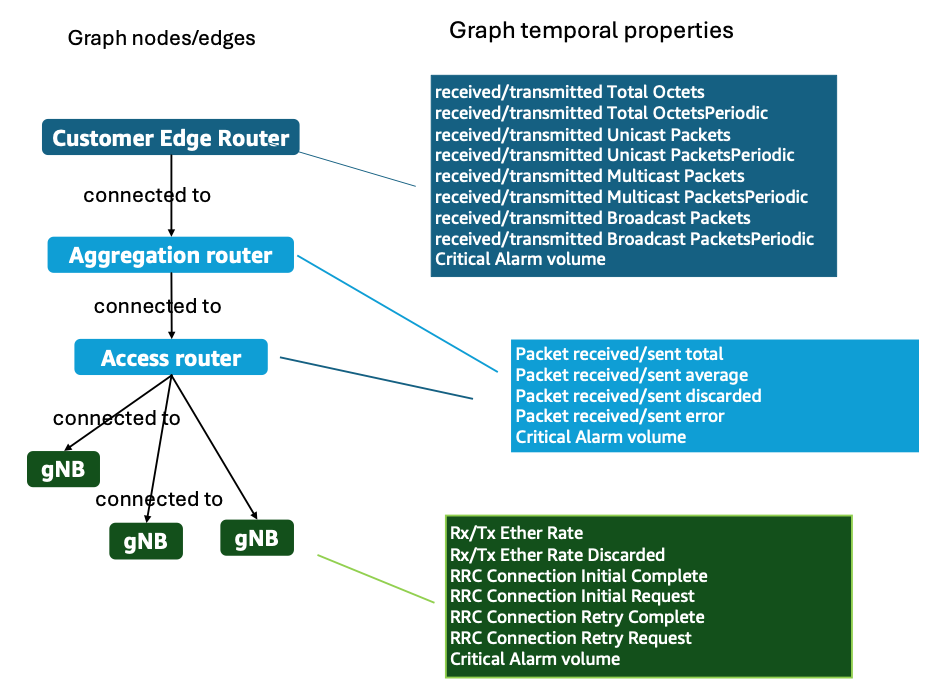
図 7. NTT ドコモのグラフデータモデリングの抜粋
NTT ドコモのグラフデータを使った Network Digital Twin は、NOC チームに以下の恩恵をもたらすをもたらします。
- データパイプラインとして維持されているグラフ化されたネットワークトポロジーの探索と検索
- KPI とアラームによって、動的なネットワークの状態をリアルタイムに可視化(時間変化するナレッジグラフ)
- グラフ分析に基づく被疑ノードの抽出
NTT ドコモの MVP は、Runbook 1 に準拠しています。このMVPは、現在、Agentic AI が静的エージェントの枠を超え、異常検知機能を組み込むように拡張されており、Runbook 3 を目指しています。
以下のスクリーンショットは、NTT ドコモによるグラフデータを使った Network Digital Twin のダッシュボード ( WebUI ) を示しています。
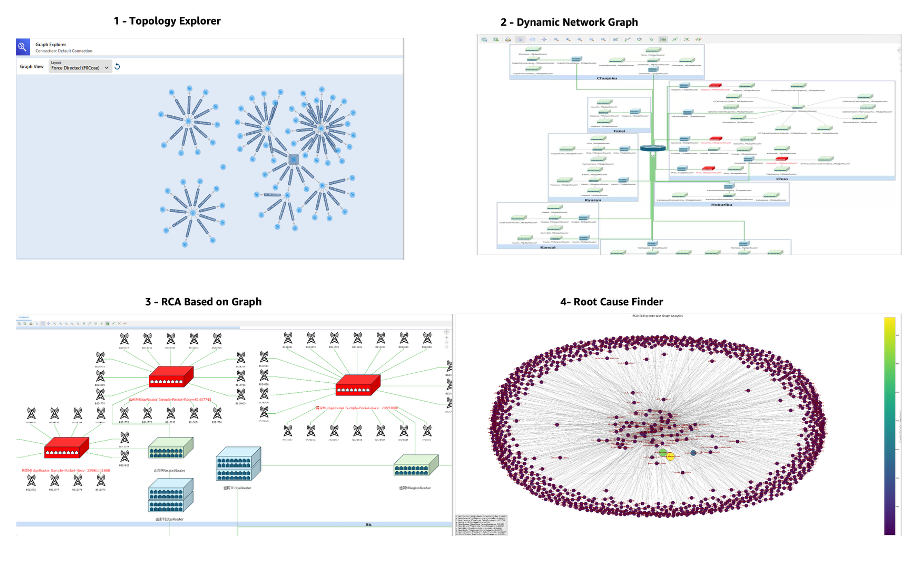
図 8. NTT DOCOMO によるグラフデータを使った Network Digital Twin ダッシュボード
- パフォーマンスデータ (PM: Performance Management) とアラームデータ (FM: Fault Management) は、トランスポートネットワークと RAN から 5 分ごとに AWS に収集され、Amazon S3 バケットに格納されます。
- AWS Lambda が Amazon Glue ジョブをトリガーします。
- Amazon Glue ジョブは生データを解析し、Amazon Neptune にデータをロードするために必要なフォーマットに変換します。変換されたファイルは S3 バケットに格納されます。
- 別の AWS Lambda が Neptune バルクローダー API を呼び出し、新しいグラフデータを自動的にインポートします。手動による介入は必要ありません。
NTTドコモは、本 RCA のトリガーとしてオンデマンド実行から始めました。具体的には、重要度の高いアラームの数が異常な数に達したことをトリガーとして、RCA パイプラインが起動し、それらのアラームを Digital Twin (グラフ DB)にロードし、グラフ分析アルゴリズムを実行します。Lambda 関数は、アラーム発生ノードのサブグラフを構築し、グラフ分析を実行して、RCA スコア結果とサブグラフの両方を Amazon S3 に保存します。その後、オペレーターは Tom Sawyer Perspectives で障害のあるデバイスを視覚的に確認することができます。被疑ノードは、ネットワークトポロジーを表示した可視化画面上で赤く強調表示されます。
次の図は、NTT ドコモの MVP ターゲットアーキテクチャを示しています。
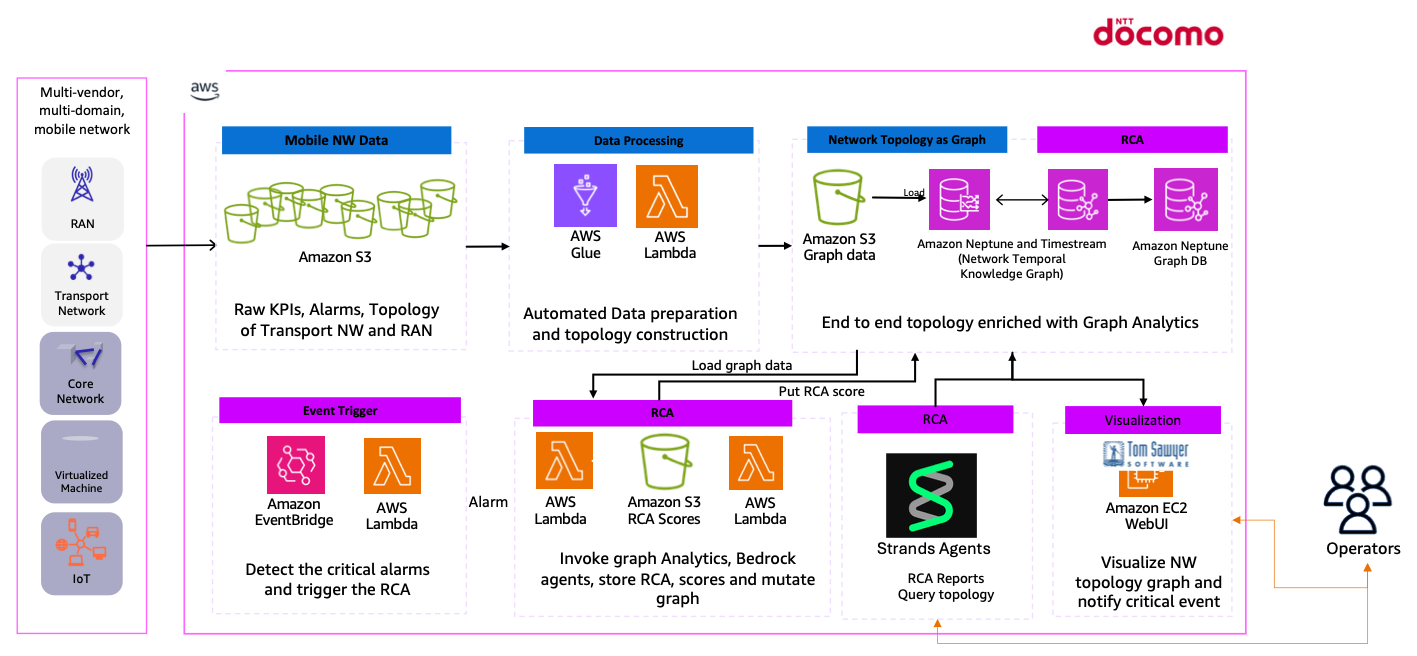
図 9. 現在の構成と将来の拡張を含む NTT ドコモの HLD ソリューションアーキテクチャ図
次のスクリーンショットは、Tom Sawyer Perspectives を使用して MVP として構築された NTT ドコモの オペレータ向け WebUI ダッシュボードです。MVP の詳細については、Mobile World Congress 2025 で展示されたデモ動画をご覧ください。
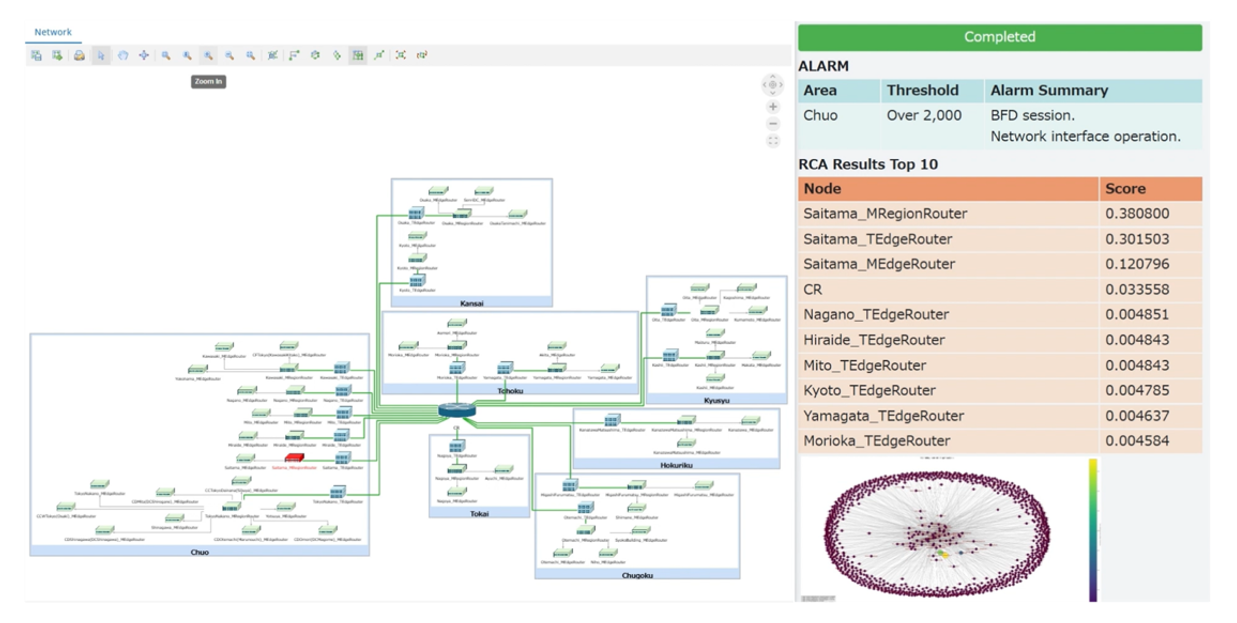
図 10. Neptune Analytics のグラフアルゴリズムを使用して、被疑箇所が特定された様子を示す WebUI
RCA (Root Cause Analysis) 領域における科学的な観点とグラフデータの台頭
4つの Runbook とナレッジレイヤーを備えた、AWS 上のエージェント型 AI 搭載グラフベース RCA の概要を説明しました。次に、このアプローチがネットワーク根本原因分析(RCA)の幅広い科学的進化とどのように整合しているかを示します。以下のタイムラインは、RCA がグラフ中心の手法を段階的に採用してきた背景を示しており、最先端技術を抜粋しています。モバイルおよびソフトウェアネットワークの根本原因分析(RCA)は、グラフデータを中心に4つのフェーズを経てきました。
- アラーム相関時代( 2011 ~ 2014 年) – 階層的なアラームデータのグラフにより、数万件もの生のアラームが数分以内に単一の因果関係の連鎖に集約されました。
- セルフモデリング時代( 2015 ~ 2017 年) – ソフトウェアデファインドネットワーク( SDN )またはネットワーク機能仮想化( NFV )コントローラからリアルタイムに生成される依存関係を表すグラフによって、30 秒未満で 95 %の精度で障害を特定できるようになりました。その後、オンラインベイジアン重み付け ( Online Bayesian weighting ) により、スタティックルールと比較して誤検知が約 30 % 削減されました。
- ログマイニングと説明可能な機械学習( ML )時代( 2020 年):有向区間グラフ – 有向非巡回グラフ( DIG – DAG )構造は、第 4 世代( 4G )および第 5 世代( 5G )のアラームをクエリ可能な因果関係を表すサブグラフにストリーミングしました。Ericsson は、SHAP( SHapley Additive exPlanations )と勾配ブースティングを組み合わせて、スライスのサービスレベル契約( SLA )違反の背後にある主要業績評価指標( KPI )パスを明らかにしました。
- ディープグラフラーニング時代( 2022 ~ 2024 年):グラフ構造学習グラフニューラルネットワーク( GNN )は、隠れたセル間のリンクを推定し、メトリクスが欠落している場合の F1 スコアを 15 % 向上させました。ディープラーニングによるオートエンコーダでは、産業用 IoT( IIoT )アプリケーションにおいて異常を 1 秒未満のレイテンシで特定しました。最新の GNN-Transformer hybrid では、数千の 5G セルにわたる時空間パターンを捉え、テストケースにおいて初回の推論で 90 % 以上の確率で根本原因を特定しています。
今後の展望
本記事では、グラフデータと Agentic AI を活用した Network Digital Twin ソリューションについてご紹介しました。リアルタイムなネットワークトポロジー、アラーム、KPI が格納された Amazon Neptune データ基盤レイヤーについてもご説明しました。このソリューションには、基本的なアラーム相関分析から KPI 予測まで、4つの Runbook が用意されており、それぞれ専門の Agentic AI による RCA が実行されます。今後の展望は以下のとおりです。
- より詳細な技術ブログの更改:近日中に実装方法を記述したブログを 4 本公開予定です。各ブログでは、ネットワークシナリオとコードのサンプルを含む 1 つの Runbook を取り上げ、実用的な導入方法をご紹介します。
- NTT ドコモにおける商用運用への導入:運用チームとの連携を継続し、新機能の追加や、他のネットワークドメインおよびサービスレイヤーへの拡張を進めています。
- パートナーシップの拡張:現在、複数のお客様およびパートナーと連携し、根本原因分析、サービス影響の評価、変更管理のための Digital Twin リューションを開発しています。
AWS での RCA およびサービス影響の評価のためにグラフデータを活用した Network Digital Twin に関する過去の顧客事例については、以下のサイトを参照ください:
– Networks for AI and AI for Networks: AWS and Orange’s Journey
– DOCOMO- Network digital twin as a graph: powered with generative AI
– re:invent 2024 with Orange, Generative AI–powered graph for network digital twin
– Telenet Belguim/LG, Celfocus and AWS- Network operations powered by network digital twin
|
Imen は、 AWS のプリンシパル AI/ML スペシャリストです。ネットワーク(可観測性、根本原因分析、レコメンデーションシステム、クローズドループシステム)に適用するクラウドネイティブな機械学習/ディープラーニング/生成 AI パイプラインの設計と構築に携わり、60 本以上の機械学習/ディープラーニングに関する科学論文を執筆しています。パリ工科大学テレコム・シュッドパリ校で、ネットワークに応用された AI/認知技術の博士号を取得しています。 |

|
Brad は、AWSのディレクターであり、Amazon Neptune(マネージドグラフデータベース)と Timestream(マネージド時系列データベース)の ジェネラルマネージャーも務めています。グラフと時系列は素晴らしいものであり、ユーザーにとってデータ内の関係性を利用して洞察を得るのに役立つと考えています。2016 年にAWSに入社する前は、ワシントンD.C.を拠点とし、Blazegraph の CEO を務め、Blazegraph プラットフォームのオープンソースへの積極的な contributor として活躍していました。 |

|
Naveen は、コンテナソリューションとクラウドネイティブアーキテクチャを専門とする DevOps コンサルタントです。コンテナ化の専門知識を活かし、組織がスケーラブルなインフラストラクチャを導入できるよう支援しています。現在は通信事業者向けに、従来のインフラストラクチャと AI イノベーションを組み合わせた 生成 AI アプリケーションを開発しています。 |

|
宮崎 友貴 Yuki Miyazaki Yuki は、AWS の日本の通信事業者向けソリューションアーキテクトです。通信事業者が AWS を活用して通信業界を再定義する革新的なソリューションを構築する支援をしています。主に、OSS および 5G コアの移行とモダナイズ、そして AWS サービスを活用した Autonomous Network の推進をリードしています。 |

|
前島 一夫 NTTドコモにおいて、通信ネットワークの運用の自動化・可視化の責任者を務めています。
|

|
NTTドコモにおいて、通信ネットワークサービスの監視と可観測性を担当する DevOps チームのマネージャー兼テクニカルリードを務めています。OpenStack ベースのプライベートクラウド開発、SIP AS およびメディアサーバー仮想化のための MANO 統合、3G/4G/5G ネットワークにおけるユーザーエクスペリエンス向上のための TCP 最適化など、通信ネットワークの開発経験を有しています。 |
