Amazon Web Services ブログ
データサイロの解消: Volkswagen の Amazon DataZone を活用したアプローチ
本記事は 2025 年 10 月 7 日 に公開された「Breaking down data silos: Volkswagen’s approach with Amazon DataZone」を翻訳したものです。
長年にわたり、多くの組織は特定の用途に合わせたクラウドベースのデータウェアハウスを構築してきましたが、それらは互いにサイロ化しています。現在、こうした組織が直面している大きな課題の 1 つが、異なる技術スタックで構築されたサイロ化されたデータウェアハウス間で、組織を横断したデータ検出とアクセスを可能にすることです。データメッシュパターンはこの課題に対応するもので、ドメイン指向の分散型データオーナーシップとアーキテクチャ、データをプロダクトとして扱う考え方、セルフサービス型のデータインフラをプラットフォームとして提供すること、連邦型ガバナンスの実装という 4 つの原則に基づいています。データメッシュパターンは、組織構造をデータドメインとして反映し、組織内外でデータを共有してビジネスモデルを改善できます。
2019 年、Volkswagen AG と Amazon Web Services (AWS) は Digital Production Platform (DPP) の共同開発を開始しました。製造コストを 30% 削減し、生産と物流の効率を 30% 向上させることが目標です。DPP は、工場のデバイスや製造システムからのデータアクセスを効率化し、統合処理と標準化されたインターフェースを提供します。しかし、プラットフォーム上でアプリケーションやユースケースが発展するにつれて、大きな課題が浮かび上がりました。特定のユースケース向けに分離された AWS アカウント内の隔離されたデータウェアハウス (Amazon Redshift) に保存されているデータを、中央のデータウェアハウスに集約することなく、アプリケーション間で共有する仕組みです。もう 1 つの課題は、複数のデータウェアハウスに保存されているすべての利用可能なデータを発見することと、各工場内の業務ドメインをまたいだデータアクセス申請ワークフローの整備でした。従来は、メールや一般的なコミュニケーション (チケットやメール経由) に頼る主に手動の方法が使われていました。手動のアプローチは運用負荷を増やすだけでなく、データガバナンスの観点でもユースケースごとにばらつきが生じていました。
本記事では、Amazon DataZone を紹介し、Volkswagen がどのように Amazon DataZone を使ってデータメッシュを構築し、直面した課題に取り組み、データサイロを解消したかを解説します。ソリューションの要は、データ提供者がデータプロダクトを Amazon DataZone に自動公開し、データディスカバリ機能を高めた中央データメッシュとして機能させることです。また、デプロイと実装手順のコードも提供します。
Amazon DataZone の紹介
Amazon DataZone は、AWS、オンプレミス、サードパーティのソースに保存されたデータのカタログ化、検出、共有、ガバナンスを迅速かつシンプルに行えるデータ管理サービスです。ビジネスデータカタログでは、公開されたデータを検索してアクセスを申請し、数週間ではなく数日でデータ活用を開始できます。また、チーム間のコラボレーションを促進し、異なる組織単位にまたがるデータ資産の管理と監視を支援します。Amazon DataZone ポータルでは、Web ベースのアプリケーションや API でデータ資産に対するパーソナライズされた分析体験を提供します。さらに、ガバナンス付きワークフローにより、適切なユーザーが適切な目的で適切なデータにアクセスできます。
ソリューション概要
以下のアーキテクチャ図は、データメッシュパターンに基づく全体設計を示しています。わかりやすくするため、ソースシステム、データドメインのプロデューサー (データ公開者)、データドメインのサブスクライバー (データ利用者)、中央ガバナンスを分けて示しています。データメッシュアーキテクチャは、複数の AWS アカウント間での利用を特に想定した設計です。本アプローチの狙いは、データガバナンスの基盤を大規模に構築し、一貫したガバナンスのもとでプロデューサーと利用者双方の目的を両立させることです。
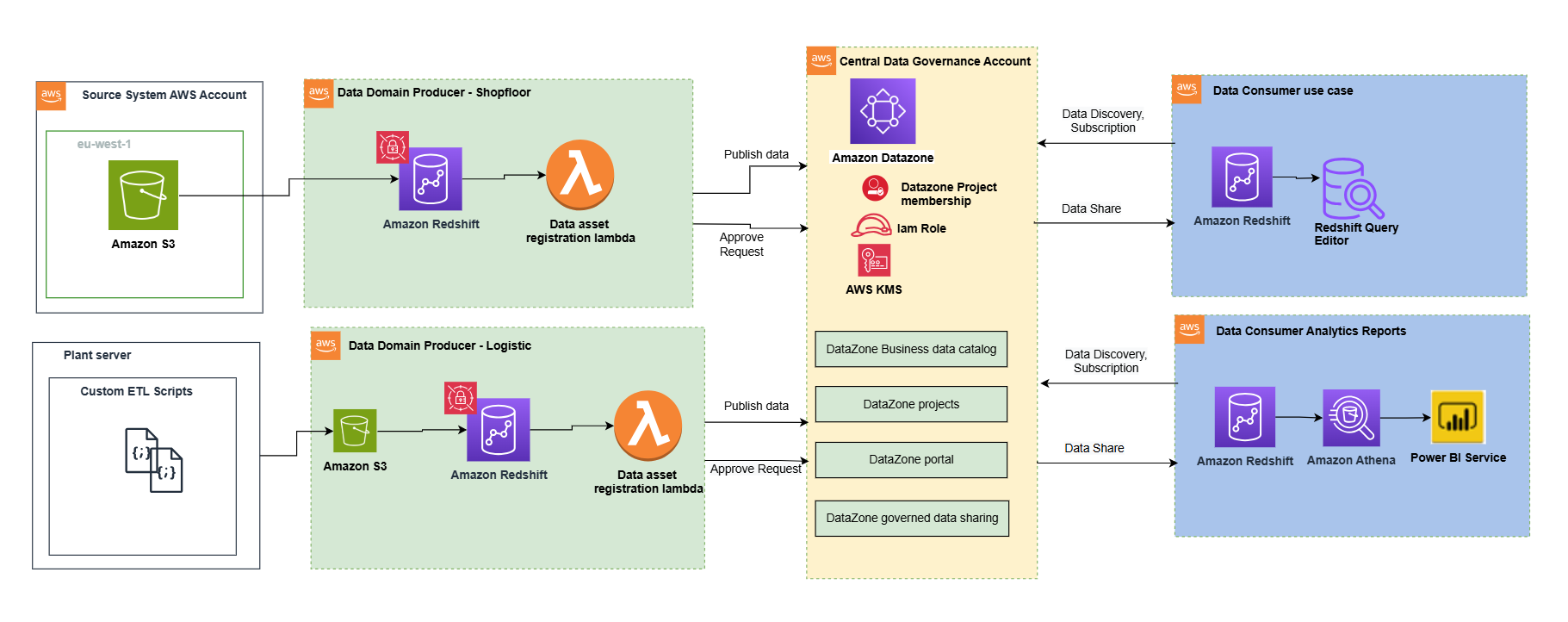
複数のデータウェアハウスを、各環境のメタデータをすべて保管する中央ガバナンスアカウントに統合できます。
データドメインのプロデューサーは、Amazon Redshift を分析用データウェアハウスとして利用し、構造化データと半構造化データの保管、処理、管理を行います。データドメインのプロデューサーは、管理・運用する ETL パイプラインを通じて、それぞれの Amazon Redshift クラスターにデータをロードします。プロデューサーは、カラムレベルのアクセス制御や動的データマスキングなどの Amazon Redshift セキュリティ機能を使い、ソース側でデータガバナンスを確保しつつ、データの制御を維持します。データドメインのプロデューサーは、Amazon Redshift ETL と Amazon Redshift Spectrum を使い、生データを処理・変換して利用可能なデータプロダクトにします。データプロダクトは、Amazon Redshift のテーブル、ビュー、マテリアライズドビュー のいずれでも構いません。
データドメインのプロデューサーは、Amazon DataZone サービスにデータセットを登録して組織の他の関係者に公開します。Amazon DataZone は中央データカタログとして機能します。プロデューサーは、どのデータ資産をどの期間共有するか、利用者がどのように操作できるかを選択できます。また、データの保守と正確性・最新性の維持もプロデューサーの責任です。
プロデューサーのデータ資産は、データソースの実行によって中央ガバナンスアカウント内の Amazon DataZone に公開されます。データソース実行により、各データ資産のテクニカルメタデータがビジネスデータカタログに登録されます。ビジネスメタデータは、ビジネスユーザー (データアナリスト) が追加でき、データセットのビジネスコンテキスト、タグ、データ分類を付与できます。この仕組みにより、プロデューサーは Redshift クラスターで構築したすべてのデータウェアハウスから、Amazon Redshift のカタログエントリを作成するために必要な機能が得られます。加えて、中央のデータガバナンスアカウントは、プロデューサーと利用者の間でデータセットを安全に共有するために使われます。重要な点として、共有はメタデータのリンクのみで行われます。ガバナンスアカウントにはデータは存在しません (ログを除く)。データは中央アカウントにコピーされず、データへの参照のみが使われるため、データのオーナーシップはプロデューサーに残ります。
Amazon DataZone はデータ検索を効率化します。Amazon DataZone データポータルは、ユーザーがデータ資産を発見・検索するためのパーソナライズされたビューを提供します。データポータルにアクセスする権限を持つ Amazon DataZone ユーザー (利用者) は、Web ベースのアプリケーションで資産を検索し、データ資産のサブスクリプションリクエストを送信できます。その後、承認者がサブスクリプションリクエストを承認または却下できます。
データドメインの利用者は、カタログ内の資産にアクセスできるようになると、Amazon Redshift クエリエディタを使ってその資産を利用 (クエリと分析) できます。各利用者は自分のユースケースに基づいて独自のワークロードを実行します。チームは自社の AWS 利用者環境で分析や機械学習に使うツールを自由に選べます。
Amazon DataZone へのデータ資産の公開と登録
プロデューサーアカウントからデータ資産を公開するには、利用者がサブスクライブできるように各資産を Amazon DataZone に登録する必要があります。詳しくは Amazon Redshift の Amazon DataZone データソースの作成と実行 を参照してください。登録プロセスが自動化されていない場合、データ資産ごとに必要な作業を手動で行う必要があります。
自動登録ワークフローを使えば、Amazon DataZone ドメインで公開する必要のある Amazon Redshift のデータ資産 (Redshift テーブルまたはビュー) について、手動ステップを自動化できます。すでに公開されているデータ資産にスキーマ変更が発生した場合にも利用できます。
以下のアーキテクチャ図は、Amazon Redshift データウェアハウスのデータ資産を、Amazon DataZone で作成されたデータメッシュに自動公開する仕組みを示しています。
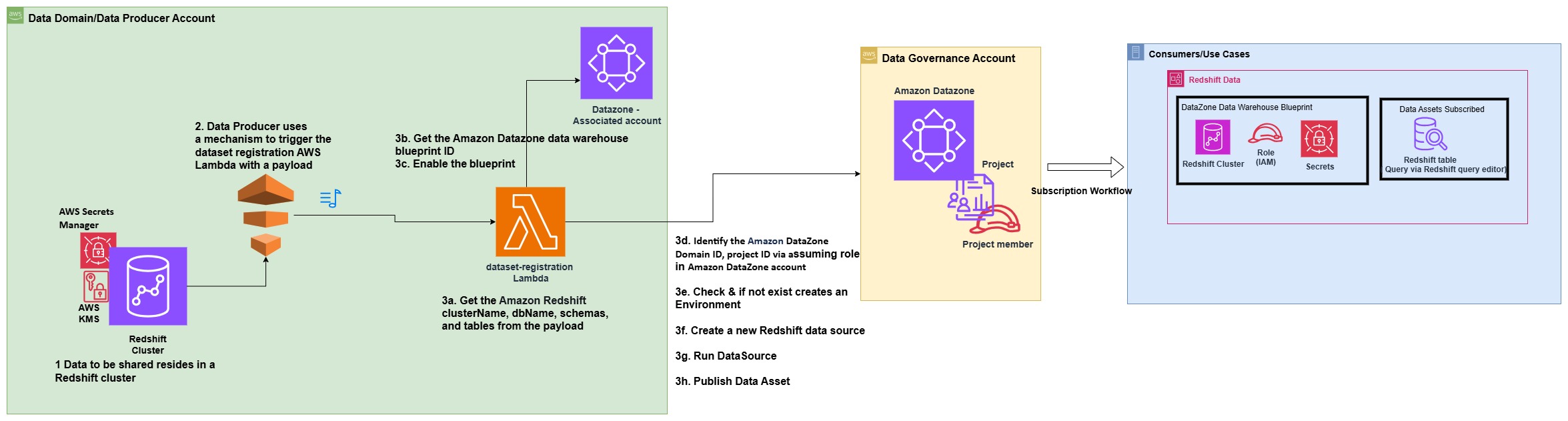
プロセスは以下の手順で構成されます。
- プロデューサーアカウント (アカウント B) では、共有対象のデータが Redshift クラスターに存在します。
- プロデューサーアカウント (アカウント B) は、メタデータに変更があるデータベース、スキーマ、テーブル、ビューの情報と名前を含む特定のペイロードで、データセット登録用の AWS Lambda 関数をトリガーする仕組みを使用します。
- Lambda 関数は、Amazon DataZone でデータセットを自動登録・公開する手順を実行します。
- Lambda 関数をトリガーするイベントとして使われる JSON ペイロードから、Amazon Redshift の clusterName、dbName、schemas、tables を取得します。
- Amazon DataZone のデータウェアハウスブループリント ID を取得します。
- データプロデューサーアカウントでブループリントを有効化します。
- Amazon DataZone アカウント (アカウント A) で IAM ロールを引き受け、プロデューサーの Amazon DataZone ドメイン ID とプロジェクト ID を特定します。
- プロジェクトに環境が既に存在するかを確認します。存在しない場合は、環境を作成します。
- 新しく作成された環境で、適切な Redshift データベース情報を指定して新しい Redshift データソースを作成します。
- データソースでデータソース実行リクエストを開始し、Redshift のテーブルまたはビューを Amazon DataZone で利用可能にします。
- Amazon DataZone カタログでテーブルまたはビューを公開します。
前提条件
開始前に以下の前提条件が必要です。
- 本記事で説明するソリューションを実装するための AWS アカウントが 2 つ必要です。ただし、Amazon DataZone は単一アカウント内や複数アカウント間でもデータを公開できます。
- Amazon DataZone アカウント (アカウント A) – 中央データガバナンスアカウントで、Amazon DataZone ドメインとプロジェクトを配置します。
- データドメインプロデューサーアカウント (アカウント B) – データドメインのプロデューサーとして機能します。アカウント A の関連アカウントとして追加されています。
データドメインプロデューサーアカウント (アカウント B) の前提条件
本記事では、既存の Redshift クラスターから資産を公開し、資産にサブスクライブします。アカウント B をセットアップするため、以下の前提条件の手順を実施してください。
- Redshift クラスターをセットアップします。データベース、スキーマ、テーブル、ビュー (オプション) を含めます。ノードタイプは RA3 ファミリーである必要があります。詳しくは Amazon Redshift プロビジョニングクラスター を参照してください。
Amazon DataZone 用の スーパーユーザーを Amazon Redshift で作成します。Redshift クラスターでは、AWS Secrets Manager で指定するデータベースユーザーにスーパーユーザー権限が必要です。詳細は、Amazon Redshift のサンプルデータを使ったクイックスタートガイドの note セクションを参照してください。
- ユーザーの認証情報を Secrets Manager に保存します。認証情報のタイプを選択し、認証情報の値を入力して、シークレットの暗号化に使う AWS Key Management Service (AWS KMS) キーを選択します。
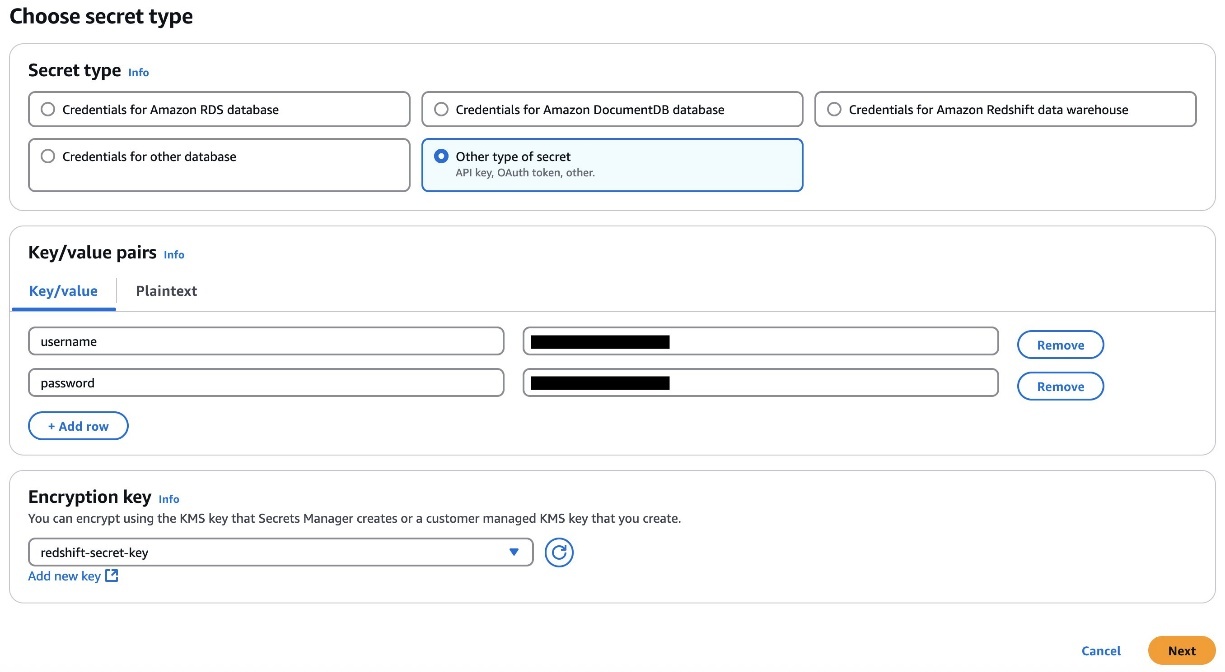
- Amazon DataZone がシークレットを見つけ、アクセスを特定の Amazon DataZone ドメインおよびプロジェクトに限定できるように、Secrets Manager シークレットにタグを追加します。Redshift クラスターの Amazon Resource Name (ARN) をタグとして追加する必要があります。これにより Amazon Redshift は ARN を有効な認証情報として利用できます。詳細は、Amazon Redshift のサンプルデータを使ったクイックスタートガイドの note セクションを参照してください。
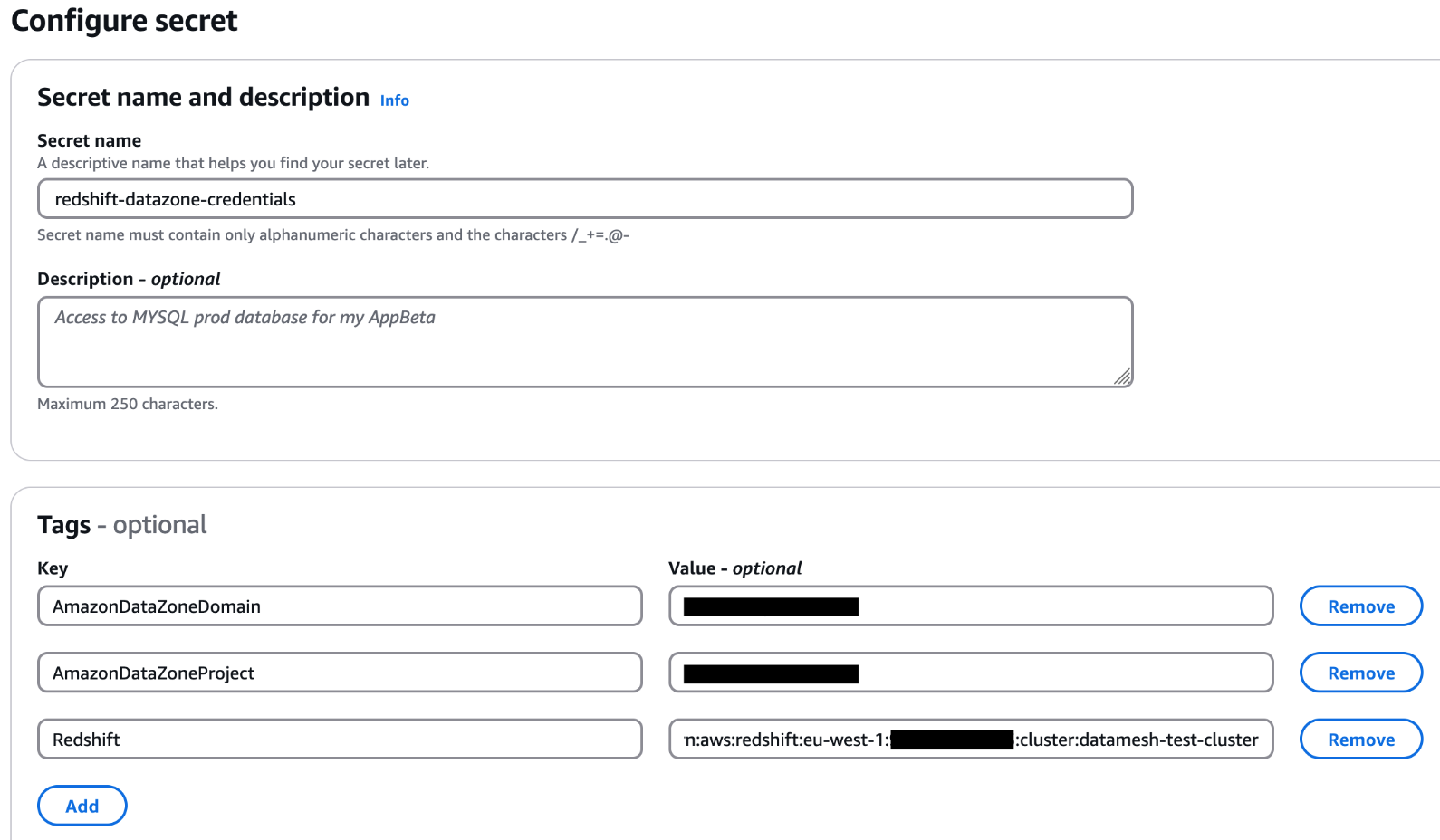
- シークレットのリソースポリシーに、Amazon DataZone プロビジョニング IAM ロールと Amazon Redshift 管理アクセス IAM ロールを追加します。これらの AWS Identity and Access Management (IAM) ロールは、AWS Cloud Development Kit (AWS CDK) のデプロイの一環で作成されます (本記事で後述)。以下のコードは、Secrets Manager シークレットのリソースポリシーの例です。シークレット ARN は AWS Systems Manager パラメータに保存します。
 シークレットをカスタム KMS キーで暗号化している場合は、キーポリシーに以下のステートメントを追加し、キーに
シークレットをカスタム KMS キーで暗号化している場合は、キーポリシーに以下のステートメントを追加し、キーに AmazonDatazoneEnvironment = Allというタグを付与します。AWS マネージドの KMS キーを使う場合、このステップは不要です。 - 以下のペイロードを生成してデータセット登録 Lambda 関数をトリガーする仕組みを用意します。ペイロードには、Amazon DataZone ドメインで公開する Redshift データベース、スキーマ、テーブルまたはビューの情報を含めます。以下の例では、Redshift クラスターに 3 つのデータベースがあり、それぞれにスキーマ、テーブル、ビューが存在することを想定しています。ユースケースに応じてペイロードを調整してください。
Amazon DataZone アカウント (アカウント A) の前提条件
Amazon DataZone アカウント (アカウント A) をセットアップする手順は以下のとおりです。
- アカウント A にサインインし、Amazon DataZone ドメインとその中のプロジェクトがすでにデプロイされていることを確認します。ドメインの作成手順は Amazon DataZone ドメインの作成 を参照してください。
- Amazon DataZone ドメインが KMS キーで暗号化されている場合は、KMS キーポリシーにデータドメインアカウント (アカウント B) を以下のアクションで追加します。
- アカウント B から引き受け可能な IAM ロールを作成します。ロールには以下のポリシーをアタッチし、Amazon DataZone プロジェクトにコントリビューターとして参加させてください。本記事では、ロール名を
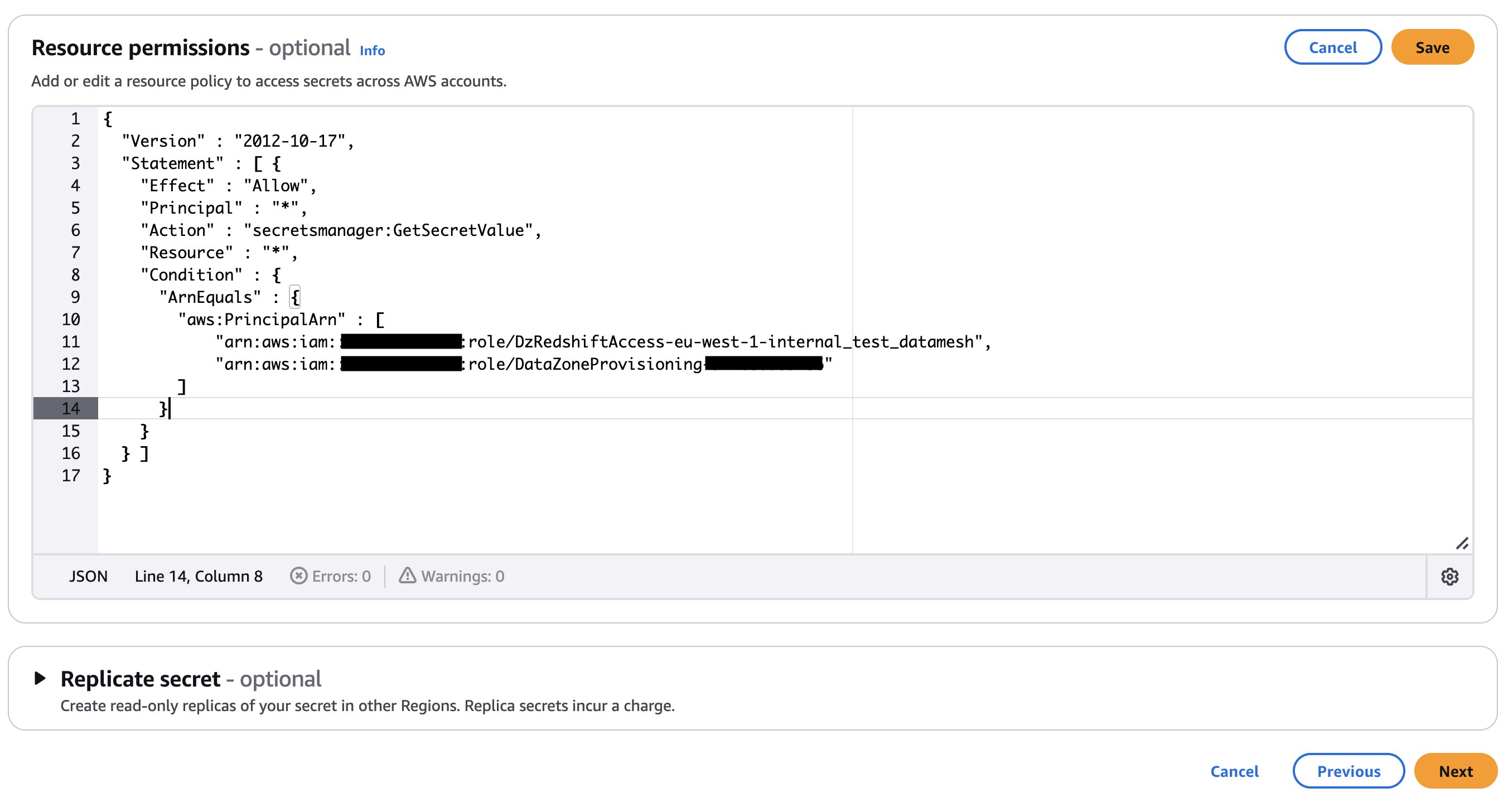
dz-assumable-env-dataset-registration-roleとします。このロールを追加することで、登録 Lambda 関数を正常に実行できます。- 以下のポリシーで、Amazon DataZone ドメインが作成された AWS リージョンとアカウント ID、およびドメインの暗号化に使用した KMS キー ARN を指定します。
- 以下の信頼関係で、このロールにアカウント B を追加します。
- データソースを登録したい Amazon DataZone プロジェクトのメンバーとしてこのロールを追加します。詳しくは プロジェクトへのメンバーの追加 を参照してください。
追加ツール
AWS CDK で本ソリューションをデプロイするには、以下のツールが必要です。
- Bash または ZSH ターミナル
- Node Version Manager を使った Node と NPM
- Node Version Manager (NVM) のインストール
- 以下のコマンドで Node バージョン 18.12.0 をインストール (node と npm のバイナリが利用可能になります)
- Python
- AWS Command Line Interface (AWS CLI)。AWS CLI の最新バージョンへのインストールまたは更新 を参照
- AWS CDK for Python (Boto3)。Installation を参照
- AWS CDK
ソリューションのデプロイ
前提条件を完了したら、GitHub リポジトリで提供されている AWS CDK スタックを使って、データ資産を Amazon DataZone ドメインに自動登録するソリューションをデプロイします。以下の手順を実行してください。
- 以下のコマンドで、GitHub からリポジトリをお好みの統合開発環境 (IDE) にクローンします。
- リポジトリフォルダのベースで、以下のコマンドを実行して AWS にリソースをビルド・デプロイします。
- AWS CLI を使い、プロファイル名でアカウント B (データドメインプロデューサーアカウント) にサインインします。
- 認証情報の設定ファイルでリージョンを設定済みであることを確認します。
- 以下のコマンドをリポジトリフォルダのベースで実行し、AWS CDK 環境をブートストラップします。デプロイアカウント (アカウント B) のプロファイル名を指定してください。ブートストラップは一度きりの作業で、AWS アカウントが既にブートストラップされている場合は不要です。
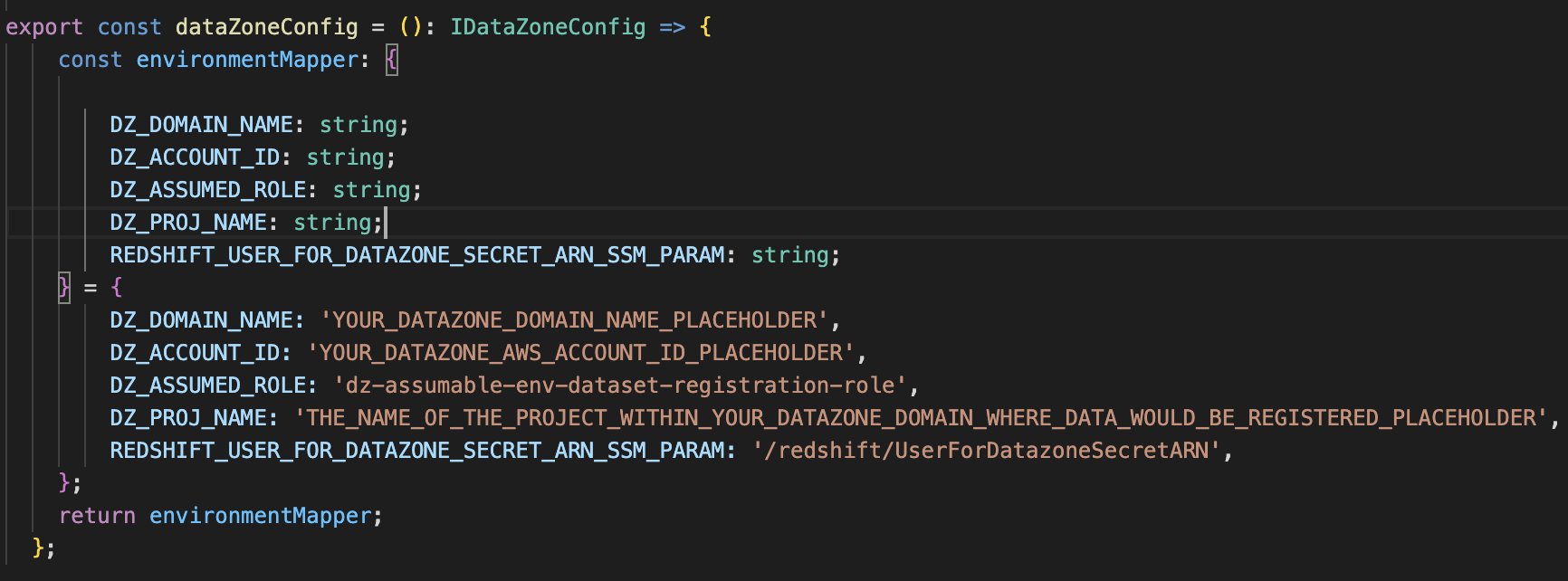
config/DataZoneConfig.tsファイル内のプレースホルダーパラメータ (_PLACEHOLDERサフィックス付き) を置き換えます。- Amazon DataZone インスタンスの Amazon DataZone ドメインとプロジェクト名。すべて小文字で指定してください。
- Amazon DataZone アカウント (アカウント A) の AWS アカウント ID。
- 前提条件で作成した引き受け可能な IAM ロール。
- Amazon Redshift 認証情報の Secrets Manager シークレット ARN を含む AWS Systems Manager パラメータ名。
- ベースフォルダで以下のコマンドを実行して AWS CDK ソリューションをデプロイします。デプロイ中、
Do you wish to deploy these changes (y/n)?というプロンプトが表示された際、一部のスタックで変更をデプロイする場合はyを入力します。 - デプロイが完了したら、アカウント B にサインインし、AWS CloudFormation コンソールを開いてインフラがデプロイされたことを確認します。
Amazon DataZone への自動データ登録のテスト
ソリューションをテストする手順は以下のとおりです。
- アカウント B (プロデューサーアカウント) にサインインします。
- Lambda コンソールで、
datazone-redshift-dataset-registration関数を開きます。 - TEST EVENTS で Create new test event を選択します。
- Event name に
Redshiftを入力し、Event JSON に以下の JSON 構造を入力します (クラスター名、スキーマ名、データベース名、テーブル名はお使いの環境に合わせて変更してください)。 - Save を選択します。
- Invoke を選択します。
- リソースをデプロイしたアカウント A で Amazon DataZone コンソールを開きます。
- ナビゲーションペインで Domains を選択し、ドメインを開きます。
- ドメイン詳細ページの Summary セクションで Amazon DataZone データポータル URL を探し、データポータルへのリンクを選択します。
Amazon DataZone へのアクセスについて詳しくは、Amazon DataZone にアクセスする方法 を参照してください。
- データポータルでプロジェクトを開き、Data タブを選択します。

- ナビゲーションペインで Data sources を選び、新しく作成された Amazon Redshift 用データソースを見つけます。
- データソースが正常に公開されたことを確認します。
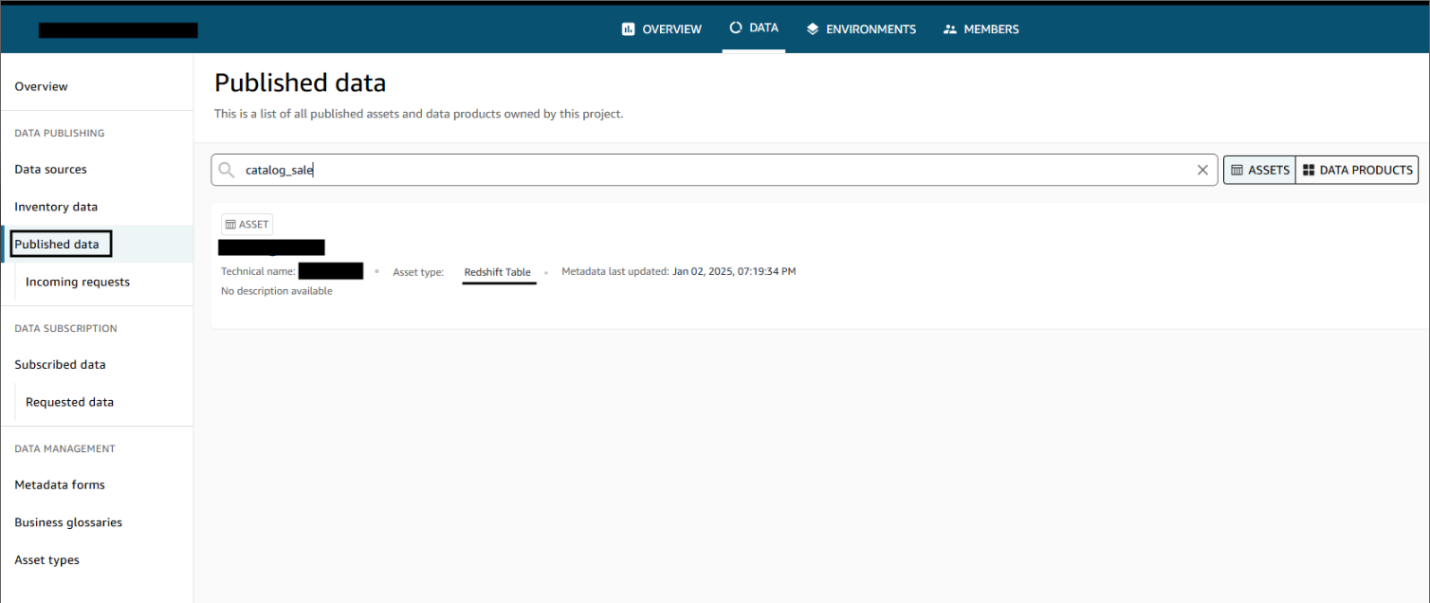
データソースが公開されたら、ユーザーは公開されたデータを発見し、サブスクリプションリクエストを送信できます。データプロデューサーはリクエストを承認または却下できます。承認されると、ユーザーは Amazon Redshift クエリエディタでデータをクエリして利用できます。以下のスクリーンショットは、Amazon DataZone データポータルでのデータ発見の様子を示しています。

クリーンアップ
AWS CDK でデプロイしたリソースをクリーンアップする手順は以下のとおりです。
- アカウント B にサインインし、Amazon DataZone ドメインポータルに移動して、公開したデータ資産にサブスクリプションがないことを確認します。サブスクリプションがある場合は、サブスクライバーにサブスクリプションの解除を依頼するか、サブスクリプションを取り消します。
- データセット登録 Lambda 関数によって Amazon DataZone プロジェクトに作成された公開データ資産を削除します。
- ベースフォルダで以下のコマンドを使い、残りのリソースを削除します。
まとめ
Amazon DataZone は AWS サービスと統合でき、本記事で紹介したシンプルな実装でデータサイロを解消し、効果的なデータメッシュアーキテクチャを構築できます。Volkswagen は Amazon DataZone を使うことでデータ共有の課題に対応しつつ、自動車製造業界でより俊敏なデータ駆動型の未来に向けた土台を築きました。様々なウェアハウスからのデータ自動公開と標準化されたガバナンスワークフローにより、データエンジニアリングチームの手動作業は大幅に削減されました。現在、Volkswagen のデータエンジニアやデータサイエンティストは、メールやチケットに煩わされることなく、セキュリティとコンプライアンスの基準を保ちながら必要なデータを素早く発見してアクセスできます。
Amazon DataZone を使うことで、組織はサイロ化したデータを統合し、セキュリティとコンプライアンスを維持しながらチーム間の協働をシンプルにできます。本アプローチは、現在のデータガバナンスの課題に対応するだけでなく、将来のデータ駆動型イノベーションに向けたスケーラブルな基盤を築きます。組織のデータメッシュを Amazon DataZone で構築するためのガイダンスについては、AWS チームにお問い合わせください。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の Woosuk Choi がレビューしました。