Amazon Web Services ブログ
AI エージェントをプロトタイプから製品へ: AWS DevOps Agent 開発で得た教訓
本記事は 2026 年 1 月 15 日 に公開された「From AI agent prototype to product: Lessons from building AWS DevOps Agent」を翻訳したものです。
re:Invent 2025 で Matt Garman は、インシデントを解決し、事前に防止することで、信頼性とパフォーマンスを継続的に改善するフロンティアエージェントである AWS DevOps Agent を発表しました。DevOps Agent チームのメンバーとして、私たちは「インシデント対応」機能が有用な発見と観察結果を生成できるよう注力してきました。特に、ネイティブな AWS アプリケーションの根本原因分析が正確かつ効率的となるように取り組んでいます。内部的には、DevOps Agent はマルチエージェントアーキテクチャを採用しており、リードエージェントがインシデントコマンダーとして機能します。リードエージェントは症状を理解して調査計画を作成し、コンテキスト圧縮が有効なタスクは専門のサブエージェントに委任します。サブエージェントはクリーンなコンテキストウィンドウでタスクを実行し、圧縮した結果をリードエージェントに報告します。例えば、大量のログレコードを調査する際、サブエージェントはノイズをフィルタリングし、関連するメッセージのみをリードエージェントに提示します。
本記事では、実用的なエージェント製品を構築するために必要なメカニズムに焦点を当てます。大規模言語モデル (LLM) を使ったプロトタイプ構築は参入障壁が低く、動作するものを比較的早く見せられます。しかし、プロトタイプを超えて多様な顧客環境で確実に動作する製品へと進むのは全く別のチャレンジであり、過小評価されがちです。本記事では、AWS DevOps Agent の構築で学んだことを共有し、皆さん自身のエージェント開発に活かしていただければと思います。
私たちの経験では、エージェントの品質を継続的に改善し、プロトタイプから本番環境へのギャップを埋めるには 5 つのメカニズムが必要です。まず、評価テスト (evals) を実施する必要があります。これにより、エージェントの失敗箇所と改善可能な領域を特定し、同時にエージェントが得意とするシナリオのタイプについて品質のベースラインを確立します。次に、エージェントの軌跡をデバッグし、どこで間違ったかを正確に把握するための可視化ツールが必要です。3 つ目に、失敗したシナリオをローカルで再実行して反復できる高速なフィードバックループが必要です。4 つ目に、確証バイアスを避けるためシステムを変更する前に成功基準を確立する、意図を持った変更が必要です。最後に、定期的に本番環境のサンプルを読んで、実際の顧客体験を理解し、まだ評価されていない新しいシナリオを発見する必要があります。
評価
評価は、従来のソフトウェアエンジニアリングにおけるテストスイートの機械学習版です。他のソフトウェア製品と同様に、良いテストケースの蓄積が品質への信頼を築きます。エージェントの品質を反復的に改善することはテスト駆動開発 (TDD) に似ています。エージェントが失敗する評価シナリオがあり (テストが Red)、エージェントが合格するまで変更を加えます (テストが Green)。評価に合格することは、エージェントが正しい推論を通じて正確で有用な出力に到達したことを意味します。
AWS DevOps Agent では、個々の評価シナリオのサイズは、従来のソフトウェアエンジニアリングのテストピラミッドにおけるエンドツーエンドテストに相当します。“Given-When-Then” スタイルのテストの観点から見ると:
- Given – テストのセットアップ部分は、作成に最も時間がかかる傾向にあります。AWS DevOps Agent の評価シナリオの例として、Amazon Elastic Kubernetes Service 上で動作するアプリケーションを考えます。複数のマイクロサービスで構成され、Application Load Balancer をフロントに配置し、Amazon Relational Database Service データベースや Amazon Simple Storage Service バケットなどのデータストアに読み書きし、AWS Lambda 関数がデータ変換を行います。依存関係の深い部分で S3 への書き込みに必要な AWS Identity and Access Management (IAM) 権限を誤って削除するコード変更をデプロイして障害を注入します。
- When – 障害が注入されるとアラームが発火し、AWS DevOps Agent が調査を開始します。評価フレームワークは、DevOps Agent ウェブアプリケーションがレンダリングするのと同様に、エージェントが生成する記録をポーリングします。このセクションは、統合テストやエンドツーエンドテストでアクションを定義するのと根本的に変わりません。
- Then – 複数のメトリクスを検証し、その結果をレポートします。基本的に、品質に対しては単一の “PASS” (1) または “FAIL” (0) メトリクスがあります。DevOps Agent のインシデント対応機能では、”PASS” は正しい根本原因が顧客に提示されたことを意味します。今回の例では、障害のあるデプロイを根本原因として特定し、依存関係のチェーンをたどって、影響を受けるリソースと S3 書き込み権限の不足を明らかにする観察結果を提示することです。それ以外は “FAIL” です。私たちはこれをルーブリックとして定義しています。「エージェントは根本原因を見つけたか?」だけでなく、「エージェントは正しい裏付けの証拠に基づいて正しい推論を行い、根本原因に到達したか?」を評価します。グラウンド・トゥルース (ソフトウェアテスト用語で “expected” や “wanted”) とシステムの応答 (“actual”) は LLM Judge を介して比較されます。LLM Judge とはグラウンド・トゥルースとエージェントの実際の出力の両方を受け取って、推論し、それらが一致しているか判定する LLM です。比較に LLM を使用するのは、エージェントの出力が非決定論的であるからです。つまり、エージェントは全体的には出力形式に従いますが、実際のテキストは自由に生成されるため、実行ごとに異なる単語や文構造を使用しながら同じ意味を伝える可能性があります。最終的な根本原因分析レポートではキーワードを厳密に検索するのではなく、ルーブリックの本質が満たされているかを評価したいのです。
評価レポートは、シナリオを行、メトリクスを列として構成されます。追跡する主要なメトリクスは、「能力」 (pass@k – k 回の試行で少なくとも 1 回合格したか)、「信頼性」 (pass^k – k 回の試行で何回合格したか、例えば k=3 で 3 回中 1 回合格なら 0.33)、「レイテンシー」と「トークン使用量」です。

評価が重要な理由
評価を行うことには複数の利点があります:
- 赤いシナリオは、エージェント開発チームが製品の品質を向上させるための明確な調査ポイントを提供します。
- 時間の経過とともに、緑のシナリオは回帰テストとして機能し、システムの変更によって既存の顧客体験が低下した場合に通知されます。
- 合格率が緑になったら、その他のメトリクスに基づいて顧客体験を改善できます。例えば、品質水準を維持しながらエンドツーエンドのレイテンシーを削減したり、コスト (トークン使用量で代用) を最適化したりできます。
評価の課題
高速なフィードバックループは、開発者がコードが機能するか (正しいか、パフォーマンスが良いか、安全か)、アイデアが良いか (主要なビジネスメトリクスを改善するか) を知るのに役立ちます。当たり前に思えるかもしれませんが、チームや組織が遅いフィードバックループを許容していることがあまりにも多いのです […] — Nicole Forsgren and Abi Noda、Frictionless: 7 Steps to Remove Barriers, Unlock Value, and Outpace Your Competition in the AI Era
評価にはいくつかの課題があります。難易度の高い順に:
- 現実的で多様なシナリオの作成が難しい。現実的なアプリケーションと障害シナリオを考え出すのは困難です。忠実度の高いマイクロサービスアプリケーションと障害を作成するには、業界経験を要する大変な作業です。効果的だと分かったのは、いくつかの「環境」(実際のアプリケーションアーキテクチャに基づく) を作成し、その上に多くの障害シナリオを作成することです。環境整備は評価のセットアップにおける高コストな部分なので、複数のシナリオで最大限に再利用します。
- 遅いフィードバックループ。「Given」の評価シナリオのデプロイに 20 分かかり、その後「When」の複雑な調査が完了するのにさらに 10〜20 分かかるとしたら、エージェント開発者は変更内容を徹底的にテストしません。代わりに、1 回の合格した評価で満足して本番環境にリリースしてしまい、包括的な評価レポートが生成されるまでリグレッションを引き起こす可能性があります。また、フィードバックループが遅いと、小さく段階的な実験ではなく複数の変更をまとめて実施する傾向が強まり、どの変更が実際に効果をもたらしたかを把握するのが難しくなります。私たちは、フィードバックループを高速化するには3 つのメカニズムが効果的であると発見しました:
- 評価シナリオのための長期稼働環境。アプリケーションとその正常状態は一度作成され、稼働し続けます。障害注入は定期的に (例えば週末に) 行われ、開発者はエージェントの認証情報を障害のある環境に向けることで、テストの「Given」部分を完全にスキップできます。
- 重要なエージェント領域のみの分離テスト。私たちのマルチエージェントシステムでは、開発者はエンドツーエンドフロー全体を実行するのではなく、過去の評価実行からのプロンプトで特定のサブエージェントを直接トリガーできます。さらに、「フォーク」機能を構築しました。これにより開発者は、失敗した実行から特定のチェックポイントメッセージまでの会話履歴を保持した任意のエージェントを初期化して、残りの軌跡のみを反復できます。どちらのアプローチも「When」部分の待ち時間を大幅に短縮します。
- エージェントシステムのローカル開発。開発者がテスト前に変更をマージしてクラウド環境にリリースしなければならない場合、ループが遅すぎます。ローカルで実行することで迅速な反復が可能になります。
軌跡の可視化
エージェントが評価や本番実行で失敗した場合、どこから調査を始めますか?最も生産性の高い方法はエラー分析です。エージェントの完全な軌跡、つまりサブエージェントの軌跡を含むユーザー・アシスタント間のすべてのメッセージ交換を可視化し、各ステップに “PASS” または “FAIL” の注釈をつけ、何が間違っていたかメモを残します。このプロセスは面倒ですが効果的です。
AWS DevOps Agent では、エージェントの軌跡は OpenTelemetry トレースにマッピングされ、Jaeger などのツールで可視化できます。Strands などのソフトウェア開発キットは、最小限のセットアップでトレース統合を提供します。
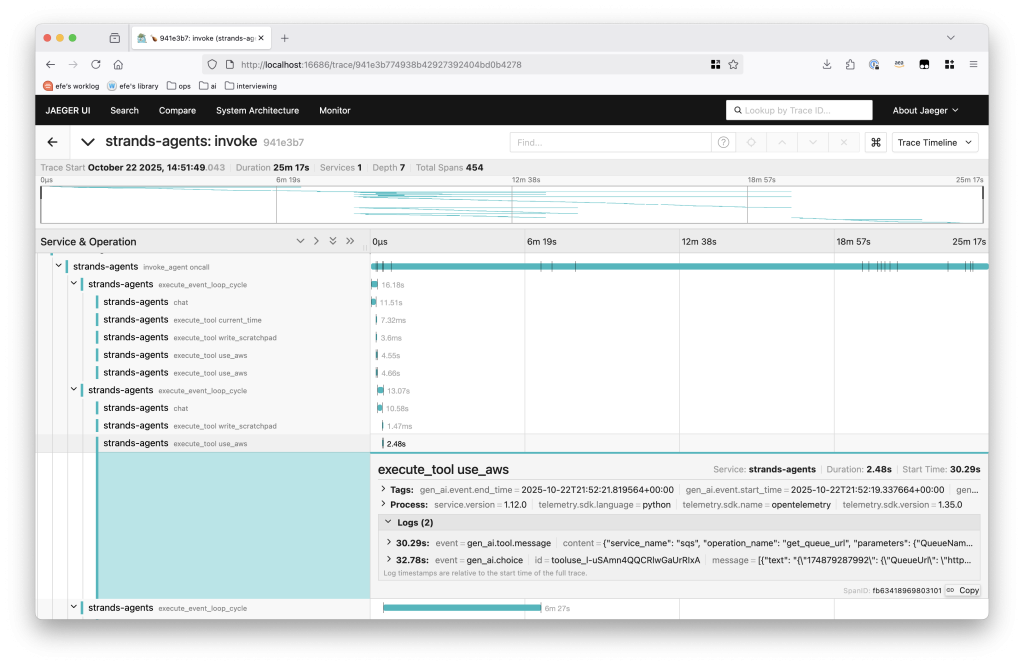
図 1 – AWS DevOps Agent のサンプルトレース
各スパンにはユーザー・アシスタントのメッセージの組み合わせが含まれています。各スパンの品質を次のような表で注釈付けします:

このローレベルの分析は、1 つだけでなく複数の改善点を一貫して明らかにします。1 つの評価が失敗すると、一般的に精度、パフォーマンス、コストにまたがる多くの具体的な変更点を特定できます。
意図を持った変更
私は父から意図を持って行うこと、すなわち自分が何をしようとしているのかを知り、すべての行動がその目標に向かっていることを確認すること、その重要さを学びました。— Will Guidara、Unreasonable Hospitality: The Remarkable Power of Giving People More Than They Expect
失敗したシナリオを特定し、軌跡の分析を通して問題を診断しました。さぁ、システムを修正する時です。
この段階で最もよく見られる誤信: 過学習につながる確証バイアスです。前述の評価上の課題 (遅いフィードバックループと包括的なテストスイートの非現実性) を考えると、開発者は通常、合格するまでいくつか特定の失敗シナリオのみをローカルでテストします。より広範な影響を考慮せずに、1 つか 2 つのシナリオが合格するまでコンテキスト (システムプロンプト、ツール仕様、ツール実装など) を修正してしまいます。変更がコンテキストエンジニアリングのベストプラクティスに従っていないと、限られた評価では捉えられない悪影響が生じる可能性が高いです。
勤勉さと判断力の両方が求められます: 利用可能な評価と再利用可能な過去の本番環境でのシナリオを通して成功基準を確立するだけでなく、変更の指針となるコンテキストエンジニアリングのベストプラクティスを学んでください。Anthropic のプロンプティングベストプラクティスとエンジニアリングブログ、Drew Breunig の“How Long Contexts Fail”、Manus 構築からの教訓は特に参考になりました。
まず成功基準を確立する
変更を加える前に、成功とはどのようなものかを定義します:
- ベースライン: 現在のシステムに特定の git コミット ID を固定します。どのメトリクスがエージェントの体験と顧客の体験の両方を改善するのかを慎重に検討し、それらをベースラインのメトリクスとして収集します。
- テストシナリオ: どの評価で変更の影響を測定しますか?評価を何回再実行しますか?このテストセットが、調査している 1 つの失敗だけでなく、より広い顧客のパターンを代表していると確信を持ってください。
- 比較: 同じメトリクスを使用して、ベースラインに対しての変更を測定します。
意図を持ったフレーミングにより、確証バイアス (結果を好意的に解釈する) とサンクコストの誤謬 (時間を費やしたという理由だけで変更を受け入れる) を避けられます。修正してもメトリクスが期待通りに動かない場合は、却下してください。
例えば、AWS DevOps Agent 内のサブエージェントを最適化する際、git コミット ID を固定し、同じシナリオを 7 回実行してベースラインを確立します。これにより、典型的なパフォーマンスと分散の両方が明らかになります。

各メトリクスは異なる側面を測定します:
- Correct observations – インシデントに直接関連する関連シグナル (ログレコード、メトリクスデータ、コードスニペットなど) をサブエージェントはいくつ提示したか?
- Irrelevant observations – サブエージェントはリードエージェントにどれだけのノイズをもたらしたか?インシデントに無関係で、エージェントの調査を妨げる可能性のあるシグナルをカウントします。
- Latency – サブエージェントはどのくらい時間がかかったか (分と秒で測定)?
- Sub-agent tokens – サブエージェントはタスクを達成するのにどれだけのトークンを消費したか?サブエージェント実行コストの代理メトリクスとして機能します。
- Lead-agent tokens – サブエージェントの入出力はリードエージェントのコンテキストウィンドウをどれだけ消費しているか?サブエージェントツールの最適化機会を具体的に特定できます。つまり、サブエージェントへの指示や返答結果を圧縮できるか?ということです。
ベースラインを確立した後、提案した変更に対して同じ測定値を比較します。これによって変更によって実際改善したかどうかが明確になります。
本番環境のサンプルを読む
幸運なことに、複数の Amazon のチームが AWS DevOps Agent を早期に採用してくれました。DevOps Agent チームのメンバーは、軌跡の可視化ツール (前述の OpenTelemetry ベースの可視化に似ていますが、根本原因分析レポートや観察結果などの DevOps Agent 固有のアーティファクトをレンダリングするようカスタマイズされています) を使用してローテーションで実際の本番実行を定期的にサンプリングし、エージェントの出力が正確であったかどうかをマークし、失敗したポイントを特定します。本番環境のサンプルは替えの効かないものです。実際の顧客体験を明らかにします。さらに、サンプルを継続的に確認することで、エージェントが得意なことと苦手なことの直感が磨かれます。本番実行が満足のいくものでない場合に反復するための実際のシナリオを持っています。エージェントをローカルで修正し、望ましい結果が得られるまで同じ本番環境に対して再実行してください。このような方法に協力してくれる重要なアーリーアダプターなチームとの信頼関係を築くことは非常に価値があります。彼らは迅速な反復のためのグラウンド・トゥルースを提供し、新しい評価シナリオを特定する機会を生み出します。本番データでの緊密なフィードバックループは、評価駆動開発と連携して機能し、包括的なテストスイートを形成します。
おわりに
現実のビジネス課題を解決できることを示すようなエージェントプロトタイプを構築することは、エキサイティングな第一歩です。より困難なのは、プロトタイプを様々な顧客環境とタスクにわたって確実に機能する製品に昇格させることです。本記事では、エージェントの品質を体系的に改善するための基盤となる 5 つのメカニズムを共有しました: 現実的で多様なシナリオでの評価、高速なフィードバックループ、軌跡の可視化、意図を持った変更、本番環境のサンプリングです。
エージェントアプリケーションを構築しているなら、今日から評価スイートの構築を始めてください。ほんの一握りの重要なシナリオから始めるだけでも、体系的に測定・改善するために必要な品質のベースラインを確立できます。AWS DevOps Agent がインシデント対応にこれらの原則をどのように適用しているかについては、入門ガイドをご覧ください。
翻訳はソリューションアーキテクトの大西朔が担当しました。原文はこちらです。