Amazon Web Services ブログ
Amazon Aurora DSQL での Change Data Capture 入門
本記事は 2026 年 5 月 14 日 に公開された「Getting started with Change Data Capture in Amazon Aurora DSQL」を翻訳したものです。
本日、Amazon Aurora DSQL はパブリックプレビューで Change Data Capture (CDC) を発表しました。これにより、データベースの変更をほぼリアルタイムで Amazon Kinesis Data Streams にストリーミングできます。Amazon Aurora DSQL は、常時利用可能なアプリケーション向けのサーバーレス分散 SQL データベースです。新しいアクティブ-アクティブ分散アーキテクチャにより、シングルリージョン構成で 99.99%、マルチリージョン構成で 99.999% の可用性を実現するよう設計されているため、可用性の高いアプリケーション構築に適しています。
最新のアプリケーションでは、分析、自動化、イベント駆動アーキテクチャを支えるリアルタイムデータパイプラインへの依存度が高まっています。従来、運用データベースから下流システムへデータを移動するには、スケジュール実行されるエクスポート、ポーリングクエリ、独自のレプリケーションソリューションが必要でした。これらの方法ではレイテンシーが発生し、運用負荷が増え、システム間の整合性維持が困難になります。
CDC の登場により、Aurora DSQL は下流サービスへのデータベース変更のネイティブストリーミングをサポートするようになりました。CDC は行レベルの変更を捕捉し、外部システムにほぼリアルタイムで配信します。
本記事では、Aurora DSQL Change Data Capture を構成し、データベースの変更を Kinesis Data Streams にストリーミングする方法を説明します。CDC の仕組み、ストリーミングパイプラインの構成方法、変更イベントの消費方法を学べます。
本記事を読み終えると、データベースの変更を耐久性のあるイベントストリームに送り出し、下流のアプリケーションで処理できる動作中の CDC パイプラインを構築できます。
Change Data Capture とは
Change Data Capture は、データベースに対する変更を識別および記録し、外部システムから利用できるようにします。データセット全体を繰り返しコピーするのではなく、CDC は変更のあった行のみに焦点を当てます。アプリケーションが INSERT、UPDATE、DELETE ステートメントを実行するたびに、CDC は変更を捕捉して対応するイベントを生成します。これらのイベントには通常、操作の種類、対象テーブル、変更前後のデータが含まれます。この方式によりリソース消費を抑えつつ、低レイテンシーでデータパイプラインを動作させられます。
例えば、INSERT 操作では新しい行の値を含むイベントが生成されます。UPDATE 操作では更新後の完全な行を含むイベントが生成されます。DELETE 操作では削除された行の主キー値を含むイベントが生成されます。CDC は変更分のみを捕捉するため、下流システムは大きなテーブルを繰り返しスキャンせずにデータの同期を維持できます。
Aurora DSQL Change Data Capture の概要
今回のリリースで、Aurora DSQL CDC は変更イベントを Amazon Kinesis Data Streams にストリーミングできるようになりました。Kinesis Data Streams はフルマネージドかつサーバーレスのストリーミングサービスで、AWS Lambda などの他の AWS サービスと統合でき、Apache Kafka のような外部ストリーミングシステムとも統合できます。
Aurora DSQL CDC はネイティブな機能で、データベースの変更を継続的に記録し、ストリーミング先に発行します。アプリケーションが SQL ステートメントでデータを変更すると、Aurora DSQL は発生した行レベルの変更を捕捉し、構造化されたイベントに変換します。
各変更イベントには、データベース操作と変更対象データを記述するメタデータが含まれます。このメタデータにより、下流のコンシューマーはデータベース変更の順序を正確に再構成できます。Aurora DSQL の CDC はアプリケーションのデータベーストランザクションとは独立して動作します。Aurora DSQL は変更イベントをバックグラウンドで捕捉および配信するため、運用ワークロードのパフォーマンスに影響を与えません。現在のリリースでは、CDC はクラスターレベルで動作し、すべてのテーブルの変更を捕捉します。テーブル単位の選択的なフィルタリングはサポートされていないため、特定のテーブルのみが必要な場合は下流のコンシューマー側でフィルタリングロジックを適用する必要があります。CDC の基本概念を理解したところで、実際のアーキテクチャでこの機能がどのように活用されるか見てみましょう。
Aurora DSQL CDC のユースケース
Aurora DSQL CDC は、幅広い最新のデータアーキテクチャをサポートします。CDC はデータベース変更のほぼ連続したストリームを提供するため、新しいデータに対してシステムが素早く反応できます。代表的なユースケースの 1 つが リアルタイム分析 です。多くの組織では、運用データを最小の遅延で分析システムに反映する必要があります。CDC ストリームをデータウェアハウスや分析プラットフォームで消費することで、継続的に更新されたデータセットを維持できます。これにより、ダッシュボードやレポートに最新のビジネス活動を反映できます。
もう 1 つの重要なユースケースが イベント駆動アーキテクチャ です。最新のアプリケーションの多くは、イベントを介して通信する疎結合のサービスで構成されています。CDC により、データベースの変更をアプリケーションのイベントとして扱えます。例えば、新しい注文レコードを挿入すると、決済処理や在庫更新などの下流ワークフローを起動できます。
CDC は データレプリケーションのシナリオ でも有用です。多くの組織では、運用データベース、検索インデックス、分析システムなど、用途別に複数のデータストアを運用しています。CDC によって、データ全体をコピーすることなくシステム間で増分同期できます。
最後に、CDC はデータベース活動の包括的な監査証跡を提供します。各変更がイベントとして記録されるため、CDC ストリームはコンプライアンスやトラブルシューティング目的でアーカイブおよび分析できます。
アーキテクチャの概要
次のアーキテクチャは、Aurora DSQL CDC が下流のコンシューマーへデータベース変更をストリーミングする仕組みを示しています。
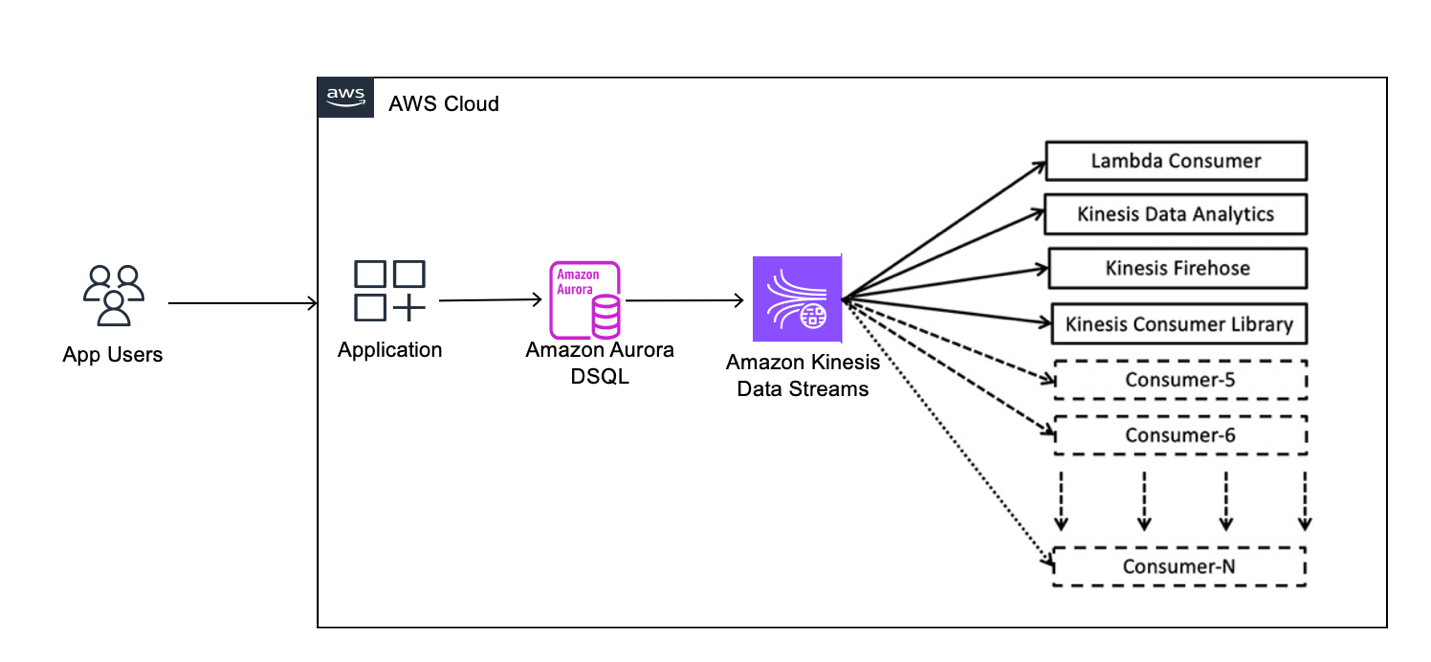
アプリケーションは標準の SQL ステートメントを使用して Aurora DSQL とやり取りします。これらの操作はデータベース内の行を変更し、変更イベントの主要な発生源となります。Aurora DSQL はテーブルの変更を監視し、変更内容を記述する CDC イベントを生成します。各イベントには、操作の種類、タイムスタンプ、トランザクション識別子、行の値などの情報が含まれます。
Aurora DSQL は CDC イベントを Kinesis データストリームに発行します。ストリームは、データベースワークロードと下流処理を切り離す耐久性とスケーラビリティに優れたバッファです。コンシューマーアプリケーションはストリームからイベントを読み取り、アプリケーションの要件に従って処理します。コンシューマーは分析システムの更新、ワークフローの起動、外部データベースの同期などを行います。
このアーキテクチャにより、Aurora DSQL は信頼できる唯一の情報源となり、下流のシステムは非同期にデータを消費できます。このアーキテクチャを構築する前に、環境を準備する必要があります。
前提条件
本セクションでは、Aurora DSQL Change Data Capture を構成するために必要なツールと権限を説明します。詳細については、前提条件を参照してください。
- AWS アカウントにアクセスできる認証情報で構成済みの AWS Command Line Interface (AWS CLI) バージョン 2 が必要です。AWS CLI は、Aurora DSQL クラスターの作成、CDC ストリームの構成、関連リソースの管理に使用します。
- 単一の AWS リージョンに Aurora DSQL クラスターが必要です。
- クライアントマシンに PostgreSQL クライアントユーティリティ
psqlがインストールされている必要があります。Aurora DSQL は PostgreSQL 互換の接続を提供しており、psqlを使って接続、テーブル作成、テストデータ生成を行います。 jqユーティリティは必須ではありませんが、JSON 出力の閲覧が容易になるため推奨します。- AWS の ID には、Aurora DSQL クラスターの作成、CDC ストリームの管理、Kinesis ストリームの作成、IAM ロールの構成を行う権限が必要です。次のポリシーが必要な権限を提供します。Aurora DSQL クラスターの作成、CDC ストリームの管理、Kinesis ストリームの作成、IAM ロールの構成に必要な IAM 権限を以下に示します。
環境の準備ができたら、次は AWS CLI を使って Aurora DSQL CDC を有効化します。
マルチリージョンの Aurora DSQL クラスターでは、CDC ストリームはストリームが作成されたリージョンに関係なく、すべてのリージョンからコミット済みの書き込みを捕捉します。Aurora DSQL クラスター、ストリーミングターゲット、IAM ロール、呼び出し元プリンシパルなどのすべてのリソースは、同じ AWS アカウントとリージョン内に存在する必要があります。複数のリージョンに CDC レコードを配信するには、各リージョンで個別のストリームを作成してください。各ストリームは独立して同じコミット済み変更のセットを配信します。
注意: 本記事では、<プレースホルダー値> を実際の情報に置き換えてください。
ステップ 1: Kinesis データストリームを作成する
Aurora DSQL CDC はイベントをストリーミング先に発行します。本記事では、ストリーミング先として Amazon Kinesis データストリームを使用します。単一のシャードで新しい Kinesis ストリームを作成します。シャードは CDC イベントで利用可能なスループット容量を決定します。ストリームを構成する際は、ストリーミング設定でサポートされる最大レコードサイズを考慮してください。Aurora DSQL は最大 2 MiB の行サイズをサポートしており、CDC イベントはスキーマやワークロード次第でこの上限に近づくことがあります。設定したレコードサイズが発行されるイベントのサイズより小さい場合、配信に失敗し CDC パイプラインが機能しなくなる可能性があります。
新しい Kinesis ストリームを作成する前に、まずこのデモで使用する環境変数を設定します。
ストリームを作成したら、ストリームステータスが “ACTIVE” になるまで待ちます。Aurora DSQL は、ストリームが完全に利用可能になるまでイベントを発行できません。
次に、ストリームの Amazon Resource Name (ARN) を取得します。
ARN はストリームを一意に識別するもので、CDC を構成する際に必要です。後で使用する可能性があるため、ストリーム ARN をメモしておいてください。ストリーミング先が準備できたら、次に Aurora DSQL がイベントを発行する権限が必要です。
ステップ 2: CDC 用の IAM ロールを作成する
Aurora DSQL は、Kinesis ストリームに書き込む権限を持つ IAM ロールを引き受けて CDC イベントを発行します。IAM ロールには、Aurora DSQL がロールを引き受けることを許可する信頼ポリシーが必要です。信頼ポリシーは特定の Aurora DSQL クラスターへのアクセスを制限します。ロールには、Kinesis ストリームへの書き込みアクセスを付与するアクセス許可ポリシーも必要です。
まず、次のセクションのように信頼ポリシーとアクセス許可ポリシーを作成します。
次に、ロールを作成してポリシーをアタッチします。
ロールを作成してアクセス許可ポリシーをアタッチしたら、ロール ARN を取得します。
ロール ARN をメモしておいてください。ロール ARN は CDC ストリームの作成時に必要です。権限を構成したら、CDC ストリームを作成できます。
ステップ 3: CDC ストリームを作成する
CDC ストリームは Aurora DSQL クラスターと Kinesis ストリームを接続します。CDC ストリームを作成すると、Aurora DSQL はデータベースの変更を Kinesis ストリームに発行し始めます。ストリームの作成には通常数分かかり、その間に Aurora DSQL は CDC 処理に必要な内部インフラストラクチャをプロビジョニングします。
ストリームが “ACTIVE” になるまで待ちます。
ストリームが “ACTIVE” になると、Aurora DSQL はデータベースの変更を捕捉する準備ができます。次のステップでは、データベースの活動を生成します。
ステップ 4: データベースの変更を生成する
CDC を有効化したら、データベースに変更を加えて構成を検証できます。PostgreSQL クライアントで Aurora DSQL に接続し、テスト用テーブルを作成します。CDC に参加するテーブルに主キーは厳密には必要ありませんが、定義することを推奨します。主キーがあれば Aurora DSQL は行を一意に識別でき、より意味のある変更イベントを生成できます。主キーがない場合、INSERT および UPDATE 操作は完全な行データを含みますが、DELETE イベントには削除された行を識別する十分な情報が含まれない可能性があります。
テーブルを作成したら、いくつかのレコードに対して挿入、更新、削除を行います。これらの操作によって Aurora DSQL が Kinesis ストリームに発行する CDC イベントが生成されます。次のコマンドで Aurora DSQL クラスターへの接続を確立します。
接続を確立したら、次のコードで主キー付きのテーブルを作成します。
次のコードでいくつかの行を挿入します。
続いて、変更レコードを生成します。テストデータの生成が終わったら、データベースから切断します。
次のステップでは、ストリームから CDC イベントを読み取ります。
ステップ 5: CDC イベントを読み取る
CDC イベントは Kinesis ストリームに保存され、AWS CLI またはコンシューマーアプリケーションで読み取れます。まず、ストリーム内のシャードを一覧表示します。
各シャードはレコードのシーケンスを表します。本例では簡単のためシャードを 1 つだけ使用していますが、本番環境のワークロードではストリームに複数のシャードを含められ、コンシューマーはすべてのレコードを読み取るためにシャードを横断的に処理する必要があります。次に、読み取りを開始する位置を指定するシャードイテレータを取得します。例えば TRIM_HORIZON は、利用可能な最も古いレコードから読み取りを開始します。シャードイテレータを使用してストリームからレコードを取得します。CDC イベントのペイロードは Base64 でエンコードされています。ペイロードをデコードすると、イベントは読み取り可能な JSON になります。各イベントはデータベースの変更を記述し、タイムスタンプ、トランザクション識別子、スキーマ名、テーブル名などのメタデータを含みます。
続いて、データをデコードしてみましょう。
CDC イベントの構造とセマンティクスの理解
Amazon Kinesis Data Streams からレコードを取得した後、次のステップは CDC イベントペイロードの解釈方法を理解することです。Amazon Aurora DSQL が発行する各イベントは、データの変更とそれに関連するメタデータを記述する一貫した JSON 構造に従います。大まかに見ると、すべての CDC イベントには操作の種類、変更前後の行の状態、ソースとイベントのタイミングに関するメタデータが含まれます。
op フィールドは操作の種類を示します。パブリックプレビュー期間中、Aurora DSQL は INSERT 操作と UPDATE 操作の両方を c (create) で表します。これは、更新が行の新しいバージョンとしてモデル化されるためです。DELETE 操作は d で表されます。INSERT と UPDATE を区別するには、特定の主キーが過去に観測されたかを追跡する必要があります。
u 操作タイプを導入する予定です。そのため、コンシューマーは将来のすべての行変更が c イベントのみを使い続けると仮定すべきではなく、それを踏まえてイベント処理ロジックを設計する必要があります。
op フィールドは操作の種類を示します。Aurora DSQL は INSERT 操作と UPDATE 操作の両方を c (create) で表します。これは、更新が行の新しいバージョンとしてモデル化されるためです。DELETE 操作は d で表されます。そのため、INSERT と UPDATE を区別するには、特定の主キーが過去に観測されたかを追跡する必要があります。
before フィールドと after フィールドは行の状態を表します。INSERT および UPDATE 操作では、イベントには変更後の完全な行が含まれ、before フィールドは null になります。DELETE 操作では after フィールドが null になり、before フィールドには削除された行の主キーのみが含まれます。この設計により、削除されたレコードを下流システムが識別可能なまま、ペイロードサイズを抑えられます。
各イベントには 2 種類のタイムスタンプも含まれます。ルートレベルの ts_ms および ts_ns フィールドは、変更がデータベースにコミットされた時刻を表します。source.ts_ms および source.ts_ns フィールドは、CDC パイプラインがイベントを処理してストリームに発行した時刻を表します。これらのタイムスタンプの差は、データベースからストリーミングシステムへの伝播レイテンシーを示します。source オブジェクトには、トランザクション ID、スキーマ名、テーブル名、データベース名、クラスター識別子などの追加メタデータが含まれます。これらのメタデータは、監査、デバッグ、下流処理ロジックの構築に有用です。
詳細については、CDC レコード形式を参照してください。
次の例は、各種データベース操作が CDC イベントとしてどのように表されるかを示します。
次の例は INSERT 操作を示します。”Alice” の新しい行が挿入されました。op フィールドは “c”、before は null、after には完全な行が含まれます。コミットタイムスタンプ (ts_ms) は CDC 発行タイムスタンプ (source.ts_ms) より前で、変更が CDC パイプラインを伝播するのにかかった時間を示しています。
次の例は UPDATE 操作を示します。Alice のメールアドレスが更新されました。op フィールドは c で、イベントには更新後の完全な行が含まれます。Aurora DSQL は更新を行の新しいバージョンとして表すため、このイベントは構造的には INSERT と同一です。UPDATE と INSERT を区別するには、同じ主キーが過去のイベントで現れたかを追跡する必要があります。
次の例は DELETE 操作を表します。行が削除されました。op フィールドは d、after フィールドは null、before フィールドには削除された行の主キーのみが含まれます。これにより、下流システムは行データ全体を含めなくても、どのレコードが削除されたかを識別できます。
これらのイベントをアプリケーションで消費することで、リアルタイムのデータパイプラインを構築できます。
Aurora DSQL CDC のイベント順序の理解
CDC を基盤としてアプリケーションを構築する際に最も重要な検討事項の 1 つが、変更イベントが下流システムに配信される順序です。イベントの処理順序は、コンシューマーが変更を解釈および適用する方法に直接影響します。
Aurora DSQL CDC は、CDC ストリーム作成時に明示的な順序設定を導入しています。この設定はストリーミング先に配信されるイベントの順序保証を定義し、追加の順序モードや統合の導入に伴って今後変化する可能性があります。Aurora DSQL CDC は現在パブリックプレビュー段階のため、下流のコンシューマーは操作タイプのセマンティクスに関する仮定をハードコードすることを避け、将来のイベント形式の拡張を許容できるよう設計する必要があります。
本記事の執筆時点では、Aurora DSQL CDC ストリームは順序を保証しないイベント配信を提供します。つまり、行やトランザクション間で厳密な順序保証なしにイベントが配信されます。詳細については、順序と配信のセマンティクスを参照してください。この方式は高いスケーラビリティとスループットをサポートするため、効率的で大規模な変更ストリーミングを必要とするワークロードに適しています。各イベントは完全かつ一貫していますが、下流のコンシューマーは順序が前後して到着するイベントを正しく処理できるよう、冪等処理や状態の整合性確保といったパターンを使って設計する必要があります。ストリーム作成時に順序を明示することで、配信セマンティクスを最初から明確に理解した上でアプリケーションを設計できます。順序を保証しないストリームを処理するコンシューマーの設計について、ポーリングやバッチ処理などの手法を含めた詳細は、Lambda を使用した Amazon Kinesis Data Streams のレコード処理と順序と重複排除の戦略を参照してください。
ベストプラクティス
Amazon Kinesis Data Streams を使用する際は、データストリームを作成し、ワークロードに合った適切なキャパシティモードを選択できます。ストリーム管理を簡素化するには、オンデマンドキャパシティモードを選びます。このモードでは、Kinesis が CDC トラフィックに合わせてスループットを自動的にスケーリングするため、シャードを手動でプロビジョニングおよび管理する必要がありません。詳細については、適切なストリームモードを選択するを参照してください。
Amazon Aurora DSQL から Amazon Kinesis Data Streams へ CDC イベントをストリーミングする際は、ストリームでサポートされる最大レコードサイズを考慮することが重要です。Kinesis は個々のレコードのサイズに上限を設けています。CDC イベントがこの上限を超えると、ストリームにイベントを配信できません。その場合、サイズ制約が解消されるまで CDC パイプラインが機能しなくなる可能性があります。これを避けるため、データモデルのサイズ特性を考慮し、想定されるペイロードサイズを処理できるようストリーミングパイプラインとコンシューマーを構成してください。これらの上限を踏まえて設計することで、中断のない継続的かつ信頼性の高い CDC イベント配信を維持できます。
下流のシステムは、重複イベントの処理と順序が前後して到着するイベントの処理に対応できるよう設計してください。CDC の配信は非同期で厳密な順序を保証しないため、コンシューマーは同じイベントを複数回受信したり、順序が前後して到着するイベントを観測したりする可能性があります。正確性を保つため、アプリケーションは冪等な処理ロジックを実装し、イベントが繰り返されても結果に不整合が生じないようにする必要があります。これは通常、主キーやトランザクションのメタデータ (タイムスタンプやトランザクション ID など) を使って変更を検出および調整することで実現します。順序が重要な場合は、コンシューマーはバッチ処理、タイムスタンプを使用したイベントの並べ替え、コミット時刻に基づく last-write-wins セマンティクスを適用できます。一部のテーブルのみを処理したい場合は、CDC ストリームにすべてのテーブルの変更が含まれるため、下流のコンシューマー側でフィルタリングロジックを適用してください。これらのパターンを踏まえてコンシューマーを設計することで、高スループットのストリーミング条件下でも信頼性と一貫性のあるデータ処理を実現できます。
クリーンアップ
CDC パイプラインが正しく動作し、Amazon Kinesis Data Streams へのデータベース変更のストリーミングを検証できたら、本ウォークスルーで作成したリソースをクリーンアップできます。
Amazon Aurora DSQL の CDC ストリームを削除しても、データベース内の既存データは維持されます。ストリームを削除すると、Kinesis データストリームへの新しい変更イベントの配信が停止するだけです。同様に、Kinesis ストリームを削除してもソースデータベースには影響しませんが、ストリームに保存されている未消費の CDC レコードは完全に削除されます。
本セクションでは、本記事で作成したリソースを削除する手順を案内します。これにより、不要なコストを避けつつ、AWS 環境をクリーンに保てます。
これらの手順を完了すると、CDC パイプライン用に作成したリソースが削除され、AWS 環境は元の状態に戻ります。
まとめ
Aurora DSQL Change Data Capture は、データベースの変更を外部システムにストリーミングするネイティブな仕組みを提供します。本記事では、データベースの変更を捕捉して Kinesis ストリームに発行する CDC パイプラインを構成しました。データベースの活動を発生させ、生成されたイベントを検証しました。Aurora DSQL CDC は独自のレプリケーションソリューションを不要にし、リアルタイムアーキテクチャの構築を簡素化します。Aurora DSQL をストリーミングシステムと統合することで、開発者はデータの変更にほぼリアルタイムで反応する応答性の高いアプリケーションを構築できます。Aurora DSQL Change Data Capture は、スケーラブルなイベント駆動システムやリアルタイム分析パイプラインを構築するための基盤となります。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の Koji Shinkubo がレビューしました。