Aravind Kodandaramaiah は AWS パートナープログラムのパートナーソリューションアーキテクトです。
はじめに
AWS ワークロードを実行するお客様は Amazon DynamoDB と Amazon Aurora の両方を使用していることがよくあります。Amazon DynamoDB は、どのような規模でも、一貫した、数ミリ秒台にレイテンシーを抑える必要のあるアプリケーションに適した、高速で柔軟性の高い NoSQL データベースサービスです。データモデルの柔軟性が高く、パフォーマンスが信頼できるため、モバイル、ウェブ、ゲーム、広告、IoT、他の多くのアプリケーションに最適です。
Amazon Aurora は、MySQL と互換性のあるリレーショナルデータベースエンジンで、オープンソースデータベースのコスト効率性と簡素性を備えた、高性能の商用データベースの可用性とスピードをあわせもったエンジンです。Amazon Aurora は、MySQL よりも最大 5 倍のパフォーマンスを発揮するだけでなく、商用データベースのセキュリティ、可用性、および信頼性を 10 分の 1 のコストで実現します。
DynamoDB と Aurora を連携させるために、カスタムウェブ解析エンジンを構築して、毎秒数百万のウェブクリックが DynamoDB に登録されるようにしたとします。Amazon DynamoDB はこの規模で動作し、データを高速に取り込むことができます。また、このクリックストリームデータを Amazon Aurora などのリレーショナルデータベース管理システム (RDBMS) にレプリケートする必要があるとします。さらに、ストアドプロシージャまたは関数内で SQL の機能を使用して、このデータに対してスライスアンドダイスや、さまざまな方法でのプロジェクションを行ったり、他のトランザクション目的で使用したりするとします。
DynamoDB から Aurora に効率的にデータをレプリケートするには、信頼性の高いスケーラブルなデータレプリケーション (ETL) プロセスを構築する必要があります。この記事では、AWS Lambda と Amazon Kinesis Firehose によるサーバーレスアーキテクチャを使用して、このようなプロセスを構築する方法について説明します。
ソリューションの概要
以下の図に示しているのは、このソリューションのアーキテクチャです。このアーキテクチャの背後には、次のような動機があります。
- サーバーレス – インフラストラクチャ管理を AWS にオフロードすることで、メンテナンスゼロのインフラストラクチャを実現します。ソリューションのセキュリティ管理を簡素化します。これは、キーやパスワードを使用する必要がないためです。また、コストを最適化します。さらに、DynamoDB Streams のシャードイテレーターに基づいた Lambda 関数の同時実行により、スケーリングを自動化します。
- エラー発生時に再試行可能 – データ移動プロセスには高い信頼性が必要であるため、プロセスは各ステップでエラーを処理し、エラーが発生したステップを再試行できる必要があります。このアーキテクチャではそれが可能です。
- 同時データベース接続の最適化 – 間隔またはバッファサイズに基づいてレコードをバッファすることで、Amazon Aurora への同時接続の数を減らすことができます。この方法は、接続タイムアウトを回避するのに役立ちます。
- 懸念部分の分離 – AWS Lambda を使用すると、データレプリケーションプロセスの各懸念部分を分離できます。たとえば、抽出フェーズを DynamoDB ストリームの処理として、変換フェーズを Firehose-Lambda 変換として、ロードフェーズを Aurora への一括挿入として分離できます。
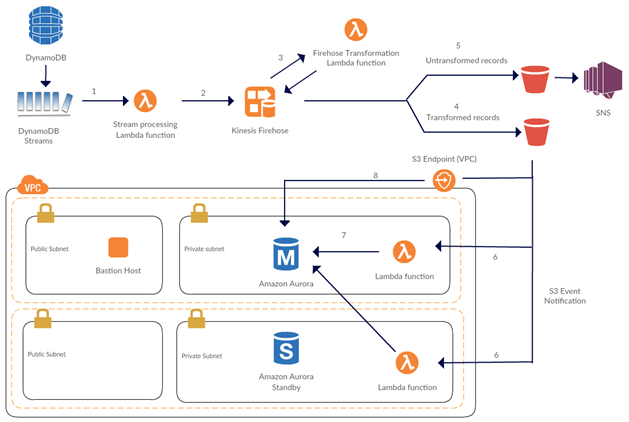
以下に示しているのは、このソリューションのしくみです。
- DynamoDB Streams がデータソースです。DynamoDB Streams を使用すると、DynamoDB テーブル内の項目が変更されたときに、その変更を取得できます。AWS Lambda は、新しいストリームレコードを検出すると、Lambda 関数を同期的に呼び出します。
- Lambda 関数は、DynamoDB テーブルに新たに追加された項目をバッファし、これらの項目のバッチを Amazon Kinesis Firehose に送ります。
- Firehose は、受け取ったデータを Lambda 関数により変換して、Amazon S3 に配信します。Firehose に対してデータ変換を有効にしていると、Firehose は受け取ったデータをバッファし、バッファしたデータのバッチごとに、指定された Lambda 関数を非同期的に呼び出します。変換されたデータは Lambda から Firehose に返されてバッファされます。
- Firehose は変換されたすべてのレコードを S3 バケットに配信します。
- Firehose は変換されないすべてのレコードも S3 バケットに配信します。ステップ 4 と 5 は同時に実行されます。Amazon SNS トピックをこの S3 バケットに登録して、以降の通知、修復、再処理に使用できます (通知に関する詳細はこのブログ記事では取り上げません)。
- Firehose が変換されたデータを S3 に正常に配信するたびに、S3 はイベントを発行することで Lambda 関数を呼び出します。この Lambda 関数は VPC 内で実行されます。
- Lambda 関数は Aurora データベースに接続し、SQL 式を実行して、S3 から直接テキストファイルにデータをインポートします。
- Aurora (VPC プライベートサブネット内で実行) は、S3 VPC エンドポイントを使用して S3 からデータをインポートします。
ソリューションの実装とデプロイ
次に、このソリューションを機能させるために必要な手順について説明します。以下の手順では、AWS CloudFormation スタックを起動して一連の AWS CLI コマンドを実行することで、VPC 環境を作成する必要があります。
AWS サービスを使用してこれらの手順を実行している間、AWS サービスの料金が適用されることがあります。
ステップ 1: ソリューションのソースコードをダウンロードする
このブログ記事で概説したソリューションでは、多くの Lambda 関数を使用し、また、多くの AWS Identity and Access Management (IAM) ポリシーおよびロールを作成します。このソリューションのソースコードは以下の場所からダウンロードします。
git clone https://github.com/awslabs/dynamoDB-data-replication-to-aurora.git
このリポジトリには、以下のフォルダ構造があります。このブログ記事の後続の手順を実行するために、lambda_iam フォルダに移動します。

ステップ 2: Firehose 配信用の S3 バケットを作成する
Amazon Kinesis Firehose を使用すると、Amazon S3 にリアルタイムのストリーミングデータを配信できます。そのためには、まず S3 バケットを作成します。次に、レコードの処理に失敗した場合に備えて、変換された最終のレコードとデータバックアップを保存するフォルダを作成します。
aws s3api create-bucket --bucket bucket_name
aws s3api put-object \
--bucket bucket_name \
--key processed/
aws s3api put-object \
--bucket bucket_name
--key tranformation_failed_data_backup/
ステップ 3: IAM ポリシー、S3 イベント通知、Firehose-S3 配信設定ファイルを変更する
次に、以下のファイルで、プレースホルダー AWS_REGION、
AWS_ACCOUNT_NUMBER、BUCKET_NAME をそれぞれ、お客様の AWS リージョン ID、AWS アカウント番号、ステップ 2 で作成した S3 バケットの名前に置き換えます。
· aurora-s3-access-Policy.json
· DynamoDb-Stream-lambda-AccessPolicy.json
· firehose_delivery_AccessPolicy.json
· lambda-s3-notification-config.json
· s3-destination-configuration.json
· firehose_delivery_trust_policy.json
ステップ 4: CloudFormation を使用して Aurora クラスターを設定する
次に、[Launch Stack] ボタンをクリックして AWS CloudFormation スタックを起動します。CloudFormation テンプレートは、VPC を作成し、その VPC のパブリックおよびプライベートサブネットを設定します。また、このテンプレートは、プライベートサブネット内で Amazon Aurora データベースクラスターを起動し、パブリックサブネット内でパブリック IP を割り当てた踏み台ホストも起動します。

ステップ 5: Aurora DB クラスターを設定する
CloudFormation スタックが完成したら、S3 バケット内のテキストファイルから DB クラスターにデータをロードするように、Aurora クラスターを変更する必要があります。以下に示しているのは、そのための手順です。
Amazon Aurora が Amazon S3 にアクセスできるようにします。そのためには、IAM ロールを作成し、先ほど作成した信頼およびアクセスポリシーをそのロールにアタッチします。
auroraS3Arn=$(aws iam create-role \
--role-name aurora_s3_access_role \
--assume-role-policy-document file://aurora-s3-Trust-Policy.json \
--query 'Role.Arn' \
--output text)
aws iam put-role-policy \
--role-name aurora_s3_access_role \
--policy-name aurora-s3-access-Policy \
--policy-document file://aurora-s3-access-Policy.json
その IAM ロールを Aurora DB クラスターに関連付けます。そのためには、新しい DB クラスターパラメータグループを作成し、その DB クラスターに関連付けます。
aws rds add-role-to-db-cluster \
--db-cluster-identifier Output AuroraClusterId from CloudFormation Stack \
--role-arn $auroraS3Arn
aws rds create-db-cluster-parameter-group \
--db-cluster-parameter-group-name webAnayticsclusterParamGroup \
--db-parameter-group-family aurora5.6 \
--description 'Aurora cluster parameter group - Allow access to Amazon S3'
aws rds modify-db-cluster-parameter-group \
--db-cluster-parameter-group-name webAnayticsclusterParamGroup \
--parameters "ParameterName=aws_default_s3_role,ParameterValue= $auroraS3Arn,ApplyMethod=pending-reboot"
aws rds modify-db-cluster \
--db-cluster-identifier Output AuroraClusterId from CloudFormation Stack \
--db-cluster-parameter-group-name webAnayticsclusterParamGroup
プライマリ DB インスタンスを再起動します。
aws rds reboot-db-instance \
--db-instance-identifier Output PrimaryInstanceId from CloudFormationF Stack
ステップ 6: DynamoDB ストリームと、そのストリームを処理する Lambda 関数を設定する
1. ストリームを有効にして新しい DynamoDB テーブルを作成します。以降の手順では、AWS Lambda 関数をストリームに関連付けることで、トリガーを作成します。
aws dynamodb create-table \
--table-name web_analytics \
--attribute-definitions AttributeName=page_id,AttributeType=S AttributeName=activity_dt,AttributeType=S \
--key-schema AttributeName=page_id,KeyType=HASH AttributeName=activity_dt,KeyType=RANGE \
--provisioned-throughput ReadCapacityUnits=50,WriteCapacityUnits=50 \
--stream-specification StreamEnabled=true,StreamViewType=NEW_IMAGE
2. Lambda 実行ロールを作成します。
DdbStreamLambdaRole=$(aws iam create-role \
--role-name DdbStreamLambdaRole \
--assume-role-policy-document file://DynamoDB-Stream-lambda-Trust-Policy.json \
--query 'Role.Arn' \
--output text)
aws iam put-role-policy \
--role-name DdbStreamLambdaRole \
--policy-name DdbStreamProcessingAccessPolicy \
--policy-document file://DynamoDb-Stream-lambda-AccessPolicy.json
3. DynamoDB ストリームを処理する Lambda 関数を作成します。
aws lambda create-function \
--function-name WebAnalyticsDdbStreamFunction \
--zip-file fileb://ddbStreamProcessor.zip \
--role $DdbStreamLambdaRole \
--handler ddbStreamProcessor.handler \
--timeout 300 \
--runtime nodejs4.3
4. その Lambda 関数を DynamoDB ストリームに関連付けることで、トリガーを作成します。
tableStreamArn=$(aws dynamodb describe-table --table-name web_analytics --query 'Table.LatestStreamArn' --output text)
aws lambda create-event-source-mapping \
--function-name WebAnalyticsDdbStreamFunction \
--event-source-arn $tableStreamArn \
--batch-size 100 \
--starting-position LATEST
ステップ 7: Firehose のデータ変換 Lambda 関数を作成して設定する
Lambda 実行ロールを作成します。
transRole=$(aws iam create-role \
--role-name firehose_delivery_lambda_transformation_role \
--assume-role-policy-document file://firehose_lambda_transformation_trust_policy.json \
--query 'Role.Arn' --output text)
aws iam put-role-policy \
--role-name firehose_delivery_lambda_transformation_role \
--policy-name firehose_lambda_transformation_AccessPolicy \
--policy-document file://firehose_lambda_transformation_AccessPolicy.json
2. データ変換 Lambda 関数を作成します。
aws lambda create-function \
--function-name firehoseDeliveryTransformationFunction \
--zip-file fileb://firehose_delivery_transformation.zip \
--role $transRole \
--handler firehose_delivery_transformation.handler \
--timeout 300 \
--runtime nodejs4.3 \
--memory-size 1024
この関数は、受け取ったストリームのレコードを JSON スキーマに対して検証します。スキーマに一致したら、受け取った JSON レコードを解析し、カンマ区切り値 (CSV) 形式に変換します。
'use strict';
var jsonSchema = require('jsonschema');
var schema = { "$schema": "http://json-schema.org/draft-04/schema#", "type": "object", "properties": { "Hits": { "type": "integer" }, "device": { "type": "object", "properties": { "make": { "type": "string" }, "platform": { "type": "object", "properties": { "name": { "type": "string" }, "version": { "type": "string" } }, "required": ["name", "version"] }, "location": { "type": "object", "properties": { "latitude": { "type": "string" }, "longitude": { "type": "string" }, "country": { "type": "string" } }, "required": ["latitude", "longitude", "country"] } }, "required": ["make", "platform", "location"] }, "session": { "type": "object", "properties": { "session_id": { "type": "string" }, "start_timestamp": { "type": "string" }, "stop_timestamp": { "type": "string" } }, "required": ["session_id", "start_timestamp", "stop_timestamp"] } }, "required": ["Hits", "device", "session"] };
exports.handler = (event, context, callback) => {
let success = 0; // Number of valid entries found
let failure = 0; // Number of invalid entries found
const output = event.records.map((record) => {
const entry = (new Buffer(record.data, 'base64')).toString('utf8');
var rec = JSON.parse(entry);
console.log('Decoded payload:', entry);
var milliseconds = new Date().getTime();
var payl = JSON.parse(rec.payload.S);
var jsonValidator = new jsonSchema.Validator();
var validationResult = jsonValidator.validate(payl, schema);
console.log('Json Schema Validation result = ' + validationResult.errors);
if (validationResult.errors.length === 0) {
const result = `${milliseconds},${rec.page_id.S},${payl.Hits},
${payl.session.start_timestamp},
${payl.session.stop_timestamp},${payl.device.location.country}` + "\n";
const payload = (new Buffer(result, 'utf8')).toString('base64');
console.log(payload);
success++;
return {
recordId: record.recordId,
result: 'Ok',
data: payload,
};
}
else {
failure++;
return {
recordId: record.recordId,
result: 'ProcessingFailed',
data: record.data,
}
}
});
console.log(`Processing completed. Successful records ${success}, Failed records ${failure}.`);
callback(null, { records: output });
};
ステップ 8: Firehose 配信ストリームを作成し、S3 にデータを配信するように設定する
Amazon S3 ターゲットを使用するとき、Firehose は S3 バケットにデータを配信します。配信ストリームを作成するには、IAM ロールが必要です。Firehose はその IAM ロールを引き受けることで、指定したバケットとキーにアクセスする権限を取得します。Firehose はまた、その IAM ロールを使用することで、Amazon CloudWatch ロググループにアクセスし、データ変換 Lambda 関数を呼び出す権限を取得します。
1. S3 バケット、キー、CloudWatch ロググループ、データ変換 Lambda 関数にアクセスする権限を付与する IAM ロールを作成します。
aws iam create-role \
--role-name firehose_delivery_role \
--assume-role-policy-document file://firehose_delivery_trust_policy.json
aws iam put-role-policy \
--role-name firehose_delivery_role \
--policy-name firehose_delivery_AccessPolicy \
--policy-document file://firehose_delivery_AccessPolicy.json
2. S3 ターゲット設定を指定して、Firehose 配信ストリームを作成します。
aws firehose create-delivery-stream \
--delivery-stream-name webAnalytics \
--extended-s3-destination-configuration='CONTENTS OF s3-destination-configuration.json file'
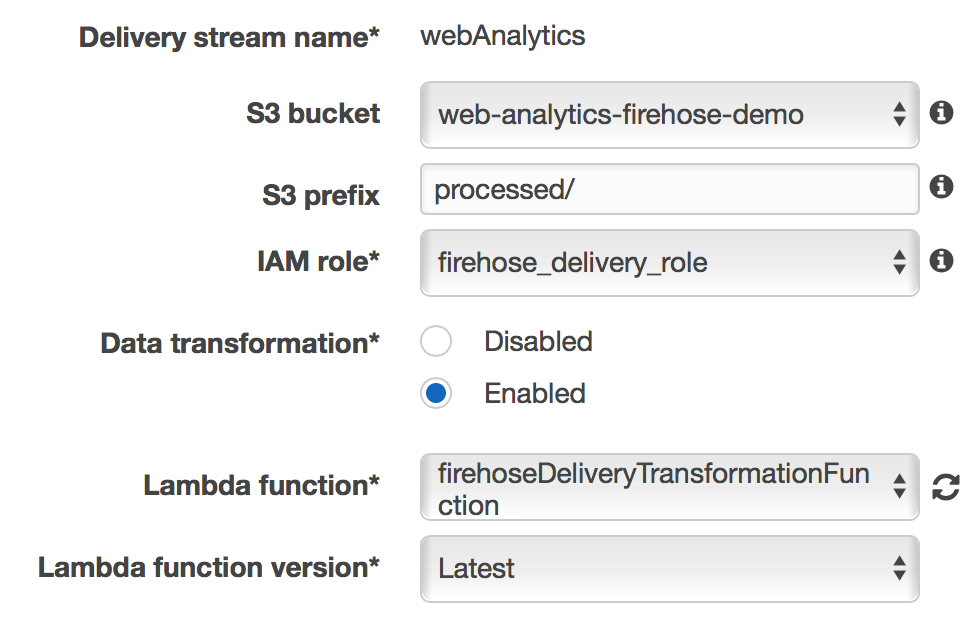
3. AWS マネジメントコンソールにサインインし、Firehose コンソールに移動します。webAnalytics という名前の配信ストリームを選択します。[Details] タブで、[Edit] を選択します。[Data transformation] で [Enabled] を、[IAM role] で [firehose_delivery_role] を選択します。[Lambda function] で、[firehoseDeliveryTransformationFunction] を選択します。次に、[Save] を選択してこの設定を保存します。
ステップ 8: Lambda 関数を作成して、VPC リソースにアクセスするように設定する
S3 バケットから Amazon Aurora にデータをインポートするには、VPC 内のリソースにアクセスするように Lambda 関数を設定します。
1. Lambda 関数の IAM 実行ロールを作成します。
auroraLambdaRole=$(aws iam create-role \
--role-name lambda_aurora_role \
--assume-role-policy-document file://lambda-aurora-Trust-Policy.json \
--query 'Role.Arn' --output text)
aws iam put-role-policy \
--role-name lambda_aurora_role \
--policy-name lambda-aurora-AccessPolicy \
--policy-document file://lambda-aurora-AccessPolicy.json
2. プライベートサブネットやセキュリティグループなどの VPC 設定を指定する Lambda 関数を作成します。CLI の実行中に渡される環境変数 AuroraEndpoint、dbUser (データベースユーザー)、dbPassword (データベースパスワード) に正しい値を設定していることを確認します。これらの値については、CloudFormation スタック出力を参照してください。
aws lambda create-function \
--function-name AuroraDataManagementFunction \
--zip-file fileb://AuroraDataMgr.zip \
--role $auroraLambdaRole \
--handler dbMgr.handler \
--timeout 300 \
--runtime python2.7 \
--vpc-config SubnetIds='Output PrivateSubnets from CloudFormation stack',SecurityGroupIds='Output DefaultSecurityGroupId from CloudFormation stack' \
--memory-size 1024 \
--environment='
{
"Variables": {
"AuroraEndpoint": "Output AuroraEndpoint from CloudFormation stack",
"dbUser": "Database User Name",
"dbPassword": "Database Password"
}
}'
Lambda 関数は Aurora データベースに接続します。この関数は、LOAD DATA FROM S3 SQL コマンドを実行して、S3 バケット内のテキストファイルから Aurora DB クラスターにデータをロードします。
import logging import pymysql import boto3 import sys import os
# rds settings
db_name = "Demo"
dbUser = os.environ['dbUser']
dbPassword = os.environ['dbPassword']
AuroraEndpoint = os.environ['AuroraEndpoint']
logger = logging.getLogger()
logger.setLevel(logging.INFO)
s3_client = boto3.client('s3')
try:
conn = pymysql.connect(AuroraEndpoint, user=dbUser, passwd=dbPassword, db=db_name, connect_timeout=5)
except:
logger.error("ERROR: Unexpected error: Could not connect to Aurora instance.")
sys.exit()
logger.info("SUCCESS: Connection to RDS Aurora instance succeeded")
def handler(event, context):
for record in event['Records']:
bucket = record['s3']['bucket']['name']
key = record['s3']['object']['key']
s3location = 's3://' + bucket + '/' + key
logger.info(s3location)
sql = "LOAD DATA FROM S3 '" + s3location + "' INTO TABLE Demo.WebAnalytics FIELDS TERMINATED BY ',' " \
"LINES TERMINATED BY '\\n' (timestarted, page_id, hits, start_time, end_time, country_code);"
logger.info(sql)
with conn.cursor() as cur:
cur.execute(sql)
conn.commit()
logger.info('Data loaded from S3 into Aurora')
ステップ 9: S3 イベント通知を設定する
最後に、S3 がイベントを発行することで、前のステップで作成した Lambda 関数を呼び出すように、その関数を設定します。このプロセスの最初の手順は、Lambda 関数を呼び出すアクセス権限を S3 に付与することです。
1. Lambda 関数を呼び出すアクセス権限を S3 に付与します。
aws lambda add-permission \
--function-name AuroraDataManagementFunction \
--action “lambda:InvokeFunction” \
--statement-id Demo1234 \
--principal s3.amazonaws.com \
--source-arn ‘ARN of S3 Bucket created in Step 2’ \
--source-account ‘AWS Account Id’
2. S3 バケット通知を設定します。
aws s3api put-bucket-notification-configuration \
--bucket 'Name of S3 Bucket created in step 2' \
--notification-configuration=' CONTENTS OF lambda-s3-notification-config.json '
ステップ 10: ソリューションをテストする
最後のステップは、ソリューションをテストすることです。
- このブログ記事のソースコードの TestHarness フォルダには、テストハーネスがあります。このテストハーネスは DynamoDB テーブルにデータを読み込みます。まず、TestHarness フォルダに移動し、コマンドノード loadDataToDDb.js を実行します。
- Secure Shell (SSH) を使用して、踏み台ホストに接続します。SSH を使用した接続の詳細については、EC2 のドキュメントを参照してください。
- 踏み台ホストのブートストラッププロセス中に MySQL クライアントがインストールされたため、以下のコマンドを使用して Aurora データベースに接続できます。パラメータ値を適切に変更していることを確認します。
/usr/bin/mysql -h DatabaseEndpoint -u DatabaseUsername --password=DatabasePassword
4. コネクションが成功したら、以下のコマンドを実行します。
mysql> select count(*) from Demo.WebAnalytics;
このコマンドを実行した後、テーブルにレコードが読み込まれています。
テーブルにレコードが読み込まれていない場合、Firehose はそれらのレコードを S3 に送信する前にバッファしている可能性があります。これを回避するには、1 分くらい後に同じ SQL コードを再試行してください。この間隔は、現在設定されている S3 バッファ間隔の値に基づきます。このコードを再試行した後、Amazon Aurora にレコードが挿入されています。
まとめ
DynamoDB Streams と、Amazon Kinesis Firehose のデータ変換関数を使用すると、DynamoDB から Amazon Aurora などのデータソースにデータをレプリケートする強力でスケーラブルな方法を得られます。このブログ記事では、DynamoDB から Aurora へのデータのレプリケートを取り上げましたが、同じ一般的なアーキテクチャパターンを使用すれば、他のストリーミングデータを変換して、Amazon Aurora に取り込むことができます。
さらに、以下の関連するブログ記事を参照してください。