Amazon Web Services ブログ
Amazon SageMaker を使用して、機械学習でエネルギー価格を予測する Kinect Energy
Amazon ML Solutions Lab は最近 Kinect Energy と協働し、機械学習 (ML) に基づいて将来のエネルギー価格を予測するパイプラインを構築しました。Amazon SageMaker と AWS Step Functions でデータの自動取り込みと推論パイプラインを作成し、エネルギー価格の予測を自動化およびスケジューリングできるようにしました。
このプロセスでは、Amazon SageMaker DeepAR 予測アルゴリズムを特別に使用します。深層学習予測モデルで現在の手動プロセスをこれに置き換えることで、Kinect Energy の時間を節約し、安定したデータ主導での方法を導入できました。
次の図は、エンドツーエンドのソリューションを示しています。
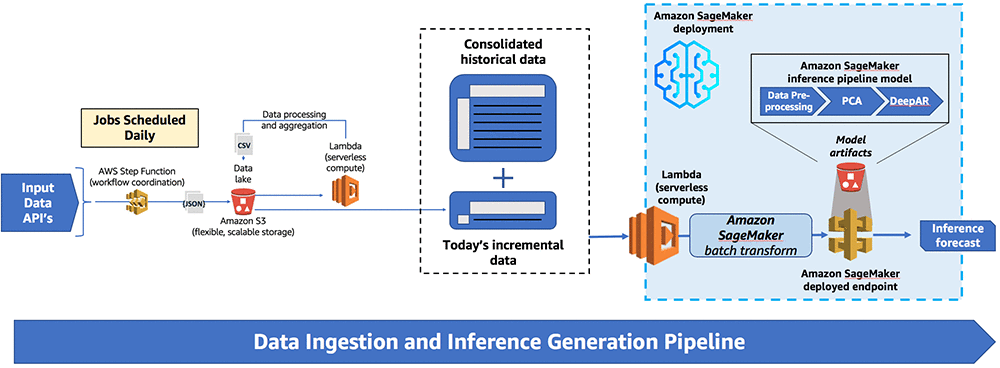
データの取り込みは毎日データをロードして処理し、Amazon S3 のデータレイクに保管するステップ関数を使用して調整します。その後、データを Amazon SageMaker に渡し、Amazon SageMaker は推論パイプラインモデルをトリガーするバッチ変換呼び出しを介して推論生成を処理します。
プロジェクトが生まれたわけ
自然電力市場は消費者の需要を満たすため、風力、水力、原子力、石炭、および石油/ガスといった資源に依存しています。需要に応えるために利用する電力資源の実際の組み合わせは、その日の各エネルギー資源の価格によって変化します。価格はその日の電力需要によって変わります。そして投資家が電力の価格を公開市場で取引します。
Kinect Energy はエネルギーを売買しています。そのビジネスモデルの中でも、エネルギー価格から派生した金融契約の取引は重要な部分です。これには、エネルギー価格の正確な予測が必要です。
そのため Kinect Energy は過去に手動で行われた予測プロセスを、ML を使って改善し自動化したいと考えていました。現物価格は現在の商品価格、つまり現物を将来引き渡しするための売買価格で、先物価格やフォワード価格とは異なります。予測した現物価格と先物価格を比較することで、Kinect Energy チームは現在の予測に基づいて将来の価格変動をヘッジする機会を得ることが可能となります。
データの要件
このソリューションでは、1 時間間隔で 4 週間を見通した現物価格を予測しようとしました。プロジェクトの主要な課題の 1 つに、必要なデータを自動的に収集し処理するシステムを作成することがありました。パイプラインには 2 つの主要なデータのコンポーネントが必要でした。
- 過去の現物価格
- エネルギー生産と消費率、および現物価格に影響するその他の外部要因
(生産率と消費率を外部データとしています。)
堅牢な予測モデルを構築するには、モデルをトレーニングするのに十分な履歴データ (できれば複数年にわたる) を収集する必要がありました 。さらに市場は新しい情報を生成するため、データを毎日更新しなければなりません。予測を行う全期間にわたって、外部データコンポーネントの予測にモデルがアクセスできることも必要でした。
ベンダーは 1 時間ごとの現物価格を、外部データフィードに毎日更新します。他のさまざまなエンティティが生産率や消費率に関するデータコンポーネントを提供しており、いろんなスケジュールでデータを公開しています。
Kinect Energy チームのアナリストが取引戦略を策定するには、特定の時刻の現物価格予測が必要です。そのため、複数の API アクションを定期的に呼び出せる堅牢なデータパイプラインを構築する必要がありました。これらのアクションでデータを収集し、必要な前処理を行ってから、予測モデルがアクセスする Amazon S3 データレイクに保存します。
データ取り込みと推論生成パイプライン
パイプラインは AWS Step Function ステートマシンが調整した主要な 3 ステップ (データ取り込み、データストレージ、推論生成) で構成されています。Amazon CloudWatch イベントはステートマシンをトリガーして毎日のスケジューリングで実行し、消費データを準備します。
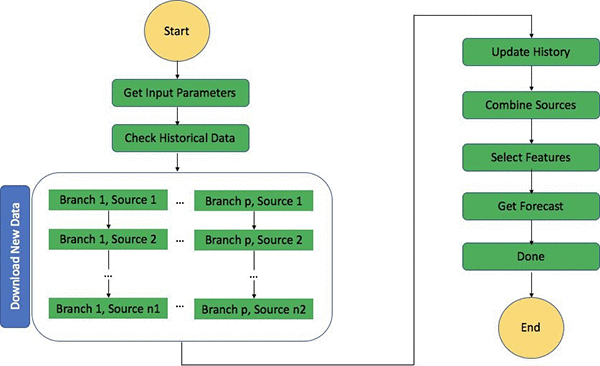
上記のフローチャートは、ステップ関数全体を構成している各ステップの詳細を示しています。ステップ関数は新しいデータのダウンロード、履歴データの更新、新しい推論の生成を調整して、プロセス全体を単一の連続したワークフローで実行できるようにします。
ステートマシンは毎日のスケジュールに沿って構築しましたが、2 つのモードのデータ取得を採用しています。デフォルトでは、ステートマシンは毎日データをダウンロードします。ユーザーはプロセスを手動でトリガーして、完全な履歴データをオンデマンドでダウンロードしたり、セットアップまたはリカバリを行うことが可能です。ステップ関数は複数の API アクションを呼び出し、それぞれ異なるレイテンシーのデータを収集します。データ収集プロセスが並列で行われます。このステップでは必要とされるあらゆる前処理も実行し、タイムスタンプ付きのプレフィックスで整理してある S3 にデータを保存します。
次の手順では、それぞれの日次要素を追加して、各コンポーネントの履歴データを更新します。追加の処理を行って DeepAR が必要とする形式でデータを準備し、データを指定された別のフォルダーに送信します。
次に、モデルは Amazon SageMaker バッチ変換ジョブをトリガーします。このジョブはその場所からデータを取得し、予測を生成し、最終的に別のタイムスタンプ付きフォルダーに結果を保存します。Amazon QuickSight ダッシュボードが予測をピックアップし、アナリストに表示します。
必要な依存関係を AWS Lambda 関数にパッケージする
Python pandas と scikit-learn (sklearn) ライブラリをセットアップして、データ前処理のほとんどを行います。Step Function が呼び出す Lambda 関数にインポートするため、これらのライブラリはデフォルトでは使用できません。これを解決するために、Lambda 関数の Python スクリプトとその必要なインポートを .zip ファイルにパッケージしました。
この追加コードは、.zip ファイルをターゲットの Lambda 関数にアップロードします。
例外処理
本番用の堅牢なコードを記述する際によく起こる課題の 1 つに、どうやって考えられる障害メカニズムを予測し、それらを軽減するかがあります。異常なイベントを処理するための指示がないと、パイプラインが崩壊する可能性があります。
このパイプラインには 大きな失敗の可能性が 2 つあります。1 つは、データの取り込みを外部 API データフィードに依存しているため、ダウンタイムが発生し、クエリが失敗する可能性があることです。この場合、プロセスがデータフィードを一時的に使用不可としてマークする前に、一定回数の再試行を設定します。2 つ目は、フィードが更新したデータではなく古い情報を返す場合があることです。この場合、API アクションはエラーを返さないため、情報が新しいかどうかを自分で判断する機能がプロセスに必要となります。
Step Functions はプロセスを自動化するための再試行オプションを提供しています。例外の性質に応じて、連続する 2 度の試行の間隔 (IntervalSeconds) とアクションを試行する最大回数 (MaxAttempts) を設定できます。パラメータ BackoffRate=1 は一定の間隔で試行を調整しますが、BackoffRate=2 はすべての間隔が前の間隔の 2 倍の長さであることを意味します。
データ取得モードの柔軟性
Step Function ステートマシンでは、2 つの異なるデータ取得モードの機能を提供しています。
- データの既存の履歴全体を取得するための履歴データプル
- 増分日次データを取得するための更新データプル
通常、Step Function は履歴データを最初に 1 度だけ抽出し、S3 データレイクに保存します。ステートマシンが新しい日次データを追加すると、保存データが増えていきます。履歴データを更新するためのオプションは、パラメータ full_history_download を True に Lambda 関数 (CheckHistoricalDataステップが呼び出す) で設定することです。これで、データセット全体が更新されます。
予測モデルの構築
今回、Amazon SageMaker で ML モデルを構築しました。S3 の履歴データのコレクションをまとめた後、pandas や sklearn などの一般的な Python ライブラリを使用して、データをクリーンアップおよび準備しました。
主成分分析 (PCA) と呼ばれる別の Amazon SageMaker ML アルゴリズムを使用して、機能エンジニアリングを実行しました。情報を保持し、望ましい特徴を作成しながら、特徴空間の範囲を縮小するため、予測モデルをトレーニングする前にデータセットに PCA を適用しました。
予測モデルには、DeepAR と呼ばれる別の Amazon SageMaker ML アルゴリズムを使用しました。DeepARは、時系列データの処理に特化したカスタムの予測アルゴリズムです。Amazonはもともと、製品の需要予測にアルゴリズムを使用していました。アルゴリズムは時間データとさまざまな外部要因に基づいて消費者の需要を予測できるため、利用量に基づくエネルギー価格の変動を予測するには強力な選択肢となりました。
次の図は、いくつかのモデリング結果を示しています。履歴データでモデルをトレーニング後、利用可能な 2018 年のデータでテストしました。DeepAR モデルを使用する利点は、予測範囲の提供に 10%〜90% の信頼区間を返すことです。さまざまな予測期間に注目すると、実際の価格レコードと比較して、DeepAR が過去の定期的な時間パターンの再現に優れていることが分かります。
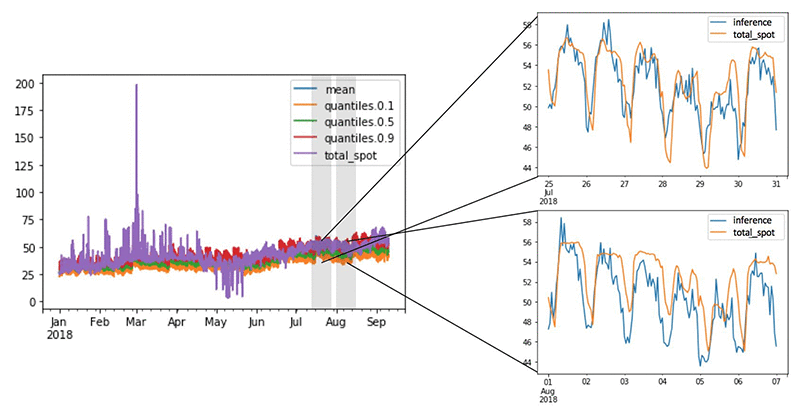
上記は、DeepAR モデルで予測された値と、2018 年 1 月から 9 月の間のテストセットにおける実際の値との比較を示しています。
Amazon SageMaker ではハイパーパラメータ最適化 (HPO) を簡単に実行できます。モデルのトレーニング後、モデルのハイパーパラメータを調整して、モデルのパフォーマンスを段階的に向上させました。Amazon SageMaker HPO はベイジアン最適化を使用してハイパーパラメータ空間を検索し、いろいろなモデルの理想的なパラメータを特定します。
Amazon SageMaker HPO API では、トレーニングジョブの数やプロセスに割り当てられる計算能力などのリソースを簡単に指定できます。ドロップアウト率、埋め込み分析コード、ニューラルネットワークのレイヤー数など、DeepAR 構造にとって重要な共通パラメータの範囲をテストしました。
Sklearn コンテナを使用したモデリング手順を、Amazon SageMaker 推論パイプラインにパッケージする
ML モデルを効果的に実装しデプロイするには、推論からのデータ入力形式と処理がモデルトレーニングに使用する形式と処理に一致していることを確認する必要がありました。
このモデルパイプラインは、DeepAR でトレーニングを行う前の PCA 機能エンジニアリングのステップと同様に、データ処理と変換に sklearn 関数を使用します。このプロセスを自動化したパイプラインで保持するため、Amazon SageMaker と Amazon SageMaker 推論パイプラインモデル内で事前に作成した sklearn コンテナを使用しました。
Amazon SageMaker SDK 内では、一連の sklearn クラスがカスタム sklearn コードのエンドツーエンドのトレーニングとデプロイを処理します。たとえば、次のコードは管理された環境において sklearn スクリプトを実行する sklearn Estimator を示しています。管理された sklearn 環境とは、entry_point Python スクリプトで定義した機能を実行する Amazon Docker コンテナのことです。前処理スクリプトを .py ファイルパスとして提供しています。Amazon SageMaker sklearn モデルをトレーニングデータに適合したら、同じ適合済みモデルが推論時にデータを必ず処理します。
この後、Amazon SageMaker 推論パイプラインでモデリングシーケンスを組み合わせました。Amazon SageMaker SDK 内の PipelineModel クラスは、データ推論のリクエストを処理するため、2〜5 個のコンテナの線形シーケンスで Amazon SageMaker モデルを作成します。これで、トレーニング済み Amazon SageMaker アルゴリズムまたは Docker コンテナにパッケージしたカスタムアルゴリズムの任意の組み合わせを定義してデプロイできるようになります。
他の Amazon SageMaker モデルエンドポイントと同様、プロセスは HTTP リクエストのシーケンスとしてパイプラインモデルの呼び出しを処理します。パイプラインの最初のコンテナが最初のリクエストを処理し、次に 2 番目のコンテナが中間応答を処理していきます。パイプラインの最後のコンテナは、最終的にクライアントに最終応答を返します。
PipelineModel を構築する際には、各コンテナの入力と出力の両方のデータ形式に注意することが重要です。たとえば DeepAR モデルでは、トレーニング中の入力データには特定のデータ構造が必要で、推論には JSON Lines データ形式が必要です。この形式は、予測モデルが開始日や時系列データの時間間隔といった追加のメタデータを必要とするため、教師あり ML モデルとは異なります。
パイプラインモデル作成後にこれを使用すると、推論生成を処理できる単一のエンドポイントとしての恩恵を受けます。つまり、トレーニングデータの前処理が推論時に必ず一致するだけでなく、データ入力から推論生成までのワークフロー全体を実行する単一のエンドポイントをデプロイできるようになるのです。
バッチ変換を使用したモデルのデプロイ
ここでは Amazon SageMaker バッチ変換で推論生成を処理しました。次の 2 つの方法のいずれかでも、Amazon SageMaker にモデルをデプロイできます。
- モデルがリアルタイム推論を提供する永続的な HTTPS エンドポイントを作成する。
- Amazon SageMaker バッチ変換ジョブを実行して、エンドポイントを開始し、保存したデータセットで推論を生成し、推論予測を出力してから、エンドポイントをシャットダウンする。
このエネルギー予測プロジェクトの仕様により、バッチ変換技術がより好ましい選択であることが証明されました。Kinect Energy はリアルタイムの予測を行うのではなく、毎日のデータ収集と予測をスケジューリングし、この出力を取引分析に使用したいと考えました。このソリューションでは、Amazon SageMaker が必要とされるリソースの起動、管理、シャットダウンを処理します。
DeepAR のベストプラクティスでは、トレーニングと推論の両方において、ターゲット機能と動的機能の履歴時系列全体をモデルに提供することを推奨しています。なぜなら、モデルがもっと古いデータポイントを使用して遅れた機能を生成し、入力データセットが非常に大きくなる可能性があるためです。
通常の 5 MB のリクエストボディ制限を回避するため、推論パイプラインモデルでバッチ変換を作成し、max_payload 引数を使用して入力データサイズの制限を設定しました。次に、トレーニングデータで使用したのと同じ関数で入力データを生成し、S3 フォルダに追加しました。これで、バッチ変換ジョブにこの場所を指定して、その入力データの推論を生成できます。
推論生成の自動化
最後に、毎日の予測を生成する Lambda 関数を作成しました。これを行うために、コードを Boto3 API に変換し、Lambda を使用できるようにします。
Amazon SageMaker SDK ライブラリを使用すれば、トレーニング済みの ML モデルにアクセスして呼び出すことができますが、Lambda 関数に含めるための 50 MB の制限をはるかに超えてしまいます。そこで、ネイティブで利用可能な Boto3 ライブラリを使用しました。
まとめ
Kinect Energy チームの協力のもと、データの自動取り込みと推論生成パイプラインを作成できました。AWS Lambda と AWS Step Functions を使用して、プロセス全体を自動化およびスケジューリングしました。
Amazon SageMaker プラットフォームを使って、電力現物価格を予測する DeepAR 予測モデルを構築、トレーニング、テストしました。Amazon SageMaker 推論パイプラインは、前処理、機能エンジニアリング、そしてモデル出力ステップを組み合わせたものです。単一の Amazon SageMaker バッチ変換ジョブで、モデルを本番に投入し、推論を生成できます。これらの推論で、Kinect Energy は現物価格をより正確に予測できるようになり、電力価格取引の能力が向上しました。
Amazon ML Solutions Lab のエンゲージメントモデルのおかげで、本番環境向け ML モデルの提供が実現しました。さらに、Kinect Energy チームはデータサイエンスの実践の場でトレーニングするチャンスを得たため、ML の取り組みの維持、反復、改善が可能となりました。Kinect Energy は与えられたリソースを使用して、他の将来のユースケースにも拡張できます。
今すぐ始めましょう Amazon SageMaker コンソールにアクセスすると、Amazon SageMaker の詳細を学べ、独自の機械学習ソリューションを開始できるようになります。
著者について
 Han Man は、AWS プロフェッショナルサービスのデータサイエンティストです。ノースウェスタン大学で工学博士号を取得した後、経営コンサルタントとして多岐にわたる業界からのクライアントをサポートした経験があります。現在は、お客様と密接に協力しながら、AWS で機械学習、深層学習、AI ソリューションを開発、実装しています。余暇には、バスケットボールをしたり、ブルドッグのトリュフとのビーチでの散歩を楽しんでいます。
Han Man は、AWS プロフェッショナルサービスのデータサイエンティストです。ノースウェスタン大学で工学博士号を取得した後、経営コンサルタントとして多岐にわたる業界からのクライアントをサポートした経験があります。現在は、お客様と密接に協力しながら、AWS で機械学習、深層学習、AI ソリューションを開発、実装しています。余暇には、バスケットボールをしたり、ブルドッグのトリュフとのビーチでの散歩を楽しんでいます。
 Arkajyoti Misra は、AWS プロフェッショナルサービスびデータサイエンティストです。機械学習アルゴリズムの研究や、深層学習の最新知識に関する本を読むことが大好きです。
Arkajyoti Misra は、AWS プロフェッショナルサービスびデータサイエンティストです。機械学習アルゴリズムの研究や、深層学習の最新知識に関する本を読むことが大好きです。
 Matt McKenna は、Amazon Alexa の機械学習をメインとしたデータサイエンティストであり、統計や機械学習を使って現実世界の問題を解決することに情熱を傾けています。余暇には、ギターの演奏、ランニング、ビール作り、ボストンのスポーツチームの応援を楽しんでいます。
Matt McKenna は、Amazon Alexa の機械学習をメインとしたデータサイエンティストであり、統計や機械学習を使って現実世界の問題を解決することに情熱を傾けています。余暇には、ギターの演奏、ランニング、ビール作り、ボストンのスポーツチームの応援を楽しんでいます。
プロジェクトに携わった Kinect Energy チームに感謝します。とりわけ、このブログ投稿を奨励しレビューしていただいた Kinect Energy のリーダーにお礼申し上げます。
- Tulasi Beesabathuni 氏: Beesabathuni 氏は World Fuel Services の人工知能/機械学習、および Box/OCR (コンテンツ管理) のチームリードです。 電力予測モデルの開始、開発、デプロイを統括し、彼の技術とリーダーシップのスキルを用いて、新しいテクノロジーを使ったチーム初のユースケースを完成させました。
- Andrew Stypa 氏: Stypa 氏は、World Fuel Services の人工知能/機械学習チームのリードビジネスアナリストです。これまでのビジネス経験を活用してユースケースを開始し、開発チームが取引チームからの要求を満足させることができるよう監督しています。