Amazon Web Services ブログ
Amazon SageMaker ワークフローによるスケーラブルなエンドツーエンド ETL パイプラインのオーケストレーション
本記事は 2026 年 2 月 9 日 に公開された「Orchestrate end-to-end scalable ETL pipeline with Amazon SageMaker workflows」を翻訳したものです。
Amazon SageMaker Unified Studio は、データエンジニアとデータサイエンティストがエンドツーエンドのデータおよび機械学習 (ML) ワークフローで協働できるワークスペースです。SageMaker Unified Studio は、Amazon Managed Workflows for Apache Airflow (Amazon MWAA) との統合により、複数の AWS サービスにまたがる複雑なデータワークフローをオーケストレーションできます。プロジェクトオーナーは共有環境を作成し、チームメンバーと協力してワークフローを開発・デプロイでき、パイプライン実行も一元的に把握できます。統合されたアプローチでデータパイプラインを一貫して効率的に実行でき、プロセス全体を把握できます。チームはデータおよび ML プロジェクトでスムーズに協働できます。
本記事では、SageMaker Unified Studio ワークフローを使って、コードベースのアプローチで ETL (抽出・変換・ロード) パイプラインを構築・管理する方法を紹介します。Amazon EMR、AWS Glue、Amazon Redshift、Amazon MWAA などの AWS サービスを使い、単一の統合インターフェースでデータ準備からオーケストレーションまで、データ処理の各工程を扱う方法を示します。
ユースケース例: E コマースプラットフォームの顧客行動分析
ある E コマース (EC) 企業が顧客の取引データを分析し、顧客サマリーレポートを作成したいとします。データは複数のソースから取得されます。
- CSV ファイルに保存された顧客プロファイルデータ
- JSON 形式の取引履歴
- 半構造化ログファイル形式の Web サイトクリックストリームデータ
同社は以下を実施したいと考えています。
- これらのソースからデータを抽出する。
- データをクレンジング・変換する。
- 品質チェックを実施する。
- 処理済みデータをデータウェアハウスにロードする。
- パイプラインを毎日実行するようにスケジュールする。
ソリューション概要
以下の図は、本記事で実装するアーキテクチャを示しています。
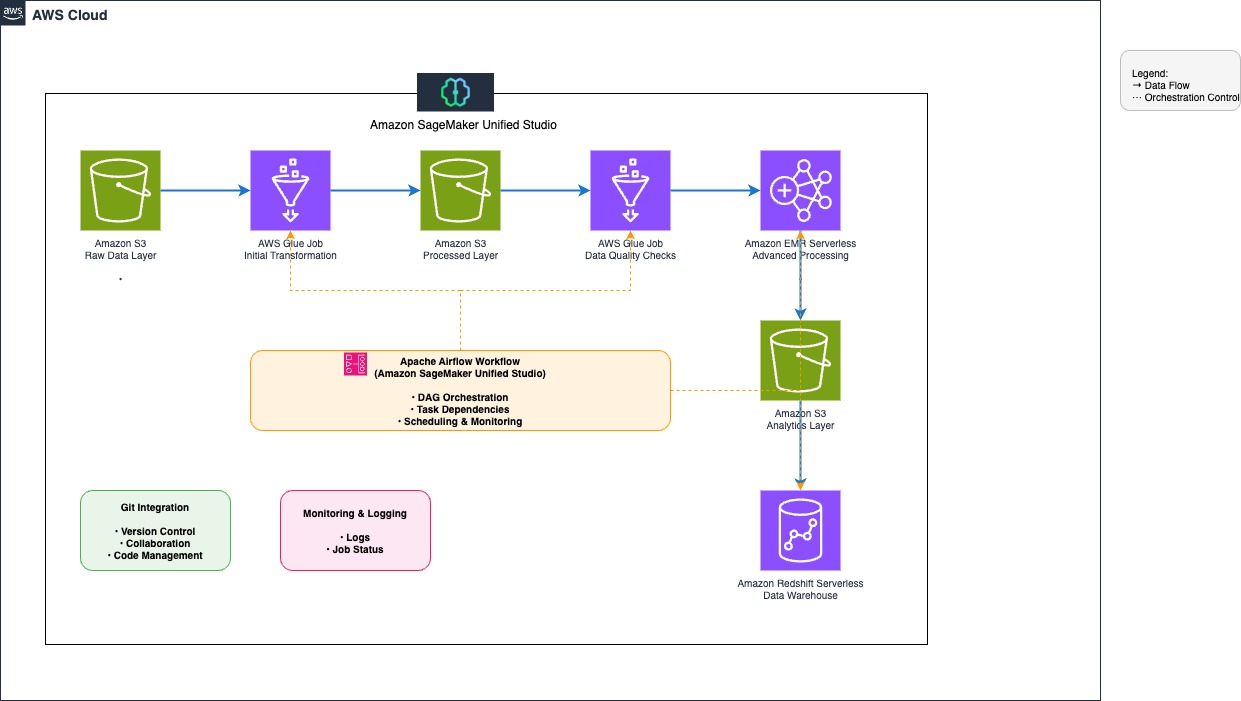
ワークフローは以下の手順で構成されます。
- Amazon Simple Storage Service (Amazon S3) バケットを作成し、顧客データ、取引履歴、クリックストリームログ用に整理されたフォルダ構造でデータリポジトリを構築し、SageMaker Unified Studio と連携するためのアクセスポリシーを設定します。
- AWS Glue ジョブを使って S3 バケットからデータを抽出します。
- AWS Glue と Amazon EMR Serverless でデータをクレンジング・変換します。
- AWS Glue Data Quality でデータ品質の検証を実施します。
- 処理済みデータを Amazon Redshift Serverless にロードします。
- Identity Center ベースのドメインで SageMaker Unified Studio を使ってワークフロー環境を作成・管理します。
注: Amazon SageMaker Unified Studio は 2 つのドメイン設定モデルをサポートします。IAM Identity Center (IdC) ベースドメインと IAM ロールベースドメインです。IAM ベースドメインはロールドリブンのアクセス管理とビジュアルワークフローを実現しますが、本記事は特に Identity Center ベースドメインにフォーカスします。このドメインでは、ユーザーは IdC 経由で認証し、プロジェクトはプロジェクトロールと ID ベースの認可を使ってデータとリソースにアクセスします。
前提条件
開始前に、以下のリソースを用意してください。
- AWS アカウント
- AWS アカウントで AWS IAM Identity Center を有効化し、ユーザーとグループを作成しておくこと。詳細な手順は IAM Identity Center の開始方法 と Amazon SageMaker Unified Studio へのアクセス を参照してください。
Amazon SageMaker Unified Studio ドメインの設定
本ソリューションでは、us-east-1 AWS リージョンに SageMaker Unified Studio ドメインが必要です。SageMaker Unified Studio は複数のリージョンで利用可能ですが、本記事では一貫性のため us-east-1 を使用します。サポートされるリージョンの一覧は Amazon SageMaker Unified Studio がサポートされるリージョン を参照してください。
ドメインを設定する手順は以下のとおりです。
- AWS マネジメントコンソールにサインインし、Amazon SageMaker に移動して、左のナビゲーションペインから Domains セクションを開きます。
- SageMaker コンソールで Create domain を選択し、Quick setup を選択します。
- 「No VPC has been specifically set up for use with Amazon SageMaker Unified Studio」というメッセージが表示された場合は Create VPC を選択します。AWS CloudFormation スタックにリダイレクトされます。すべての設定をデフォルト値のまま、Create stack を選択します。
- Quick setup settings の Name にドメイン名 (たとえば etl-ecommerce-blog-demo) を入力します。選択された設定を確認します。
- Continue を選択して次に進みます。
- Create IAM Identity Center user ページで、SSO ユーザー (IAM Identity Center のアカウント) を作成するか、既存の SSO ユーザーを選択して Amazon SageMaker Unified Studio にログインします。ここで選択した SSO は、Amazon SageMaker Unified Studio で管理者として使われます。
- Create domain を選択します。
詳細な手順は SageMaker ドメインの作成 と Amazon SageMaker Unified Studio でのデータのオンボーディング を参照してください。
ドメインを作成すると、「Your domain has been created! You can now log in to Amazon SageMaker Unified Studio」というポップアップが表示されます。いったんこのポップアップは閉じて構いません。
プロジェクトの作成
ビジネスユースケースに対応する協働ワークスペースとなるプロジェクトを作成します。以下の手順を実施します。
- Open Unified Studio を選択し、Sign in with SSO オプションで SSO 資格情報を使ってサインインします。
- Create project を選択します。
- プロジェクト名を入力 (たとえば
ETL-Pipeline-Demo) し、All capabilities プロジェクトプロファイルで作成します。 - Continue を選択します。
- 設定パラメータはデフォルト値のまま、Continue を選択します。
- Create project を選択します。
プロジェクトの作成には数分かかる場合があります。作成が完了すると、データアクセスと処理用の環境が設定されます。
S3 バケットと SageMaker Unified Studio の統合
SageMaker Unified Studio で外部データを処理するため、S3 バケットとの統合を設定します。S3 バケットのセットアップ、権限設定、プロジェクトとの統合手順を説明します。
S3 バケットの作成・設定
バケットを作成する手順は以下のとおりです。
- 新しいブラウザタブで AWS マネジメントコンソールを開き、S3 を検索します。
- Amazon S3 コンソールで Create Bucket を選択します。
ecommerce-raw-layer-bucket-demo-<Account-ID>-us-east-1という名前でバケットを作成します。詳細な手順は ストレージ用の汎用 Amazon S3 バケットの作成を参照してください。- バケット内に以下のフォルダ構造を作成します。詳細な手順は フォルダの作成 を参照してください。
raw/customers/raw/transactions/raw/clickstream/processed/analytics/
サンプルデータのアップロード
顧客行動、取引履歴、Web サイトのやり取りをまとめて分析する典型的なビジネスシナリオを表すサンプル EC データをアップロードします。
raw/customers/customers.csv ファイルには、登録情報を含む顧客プロファイル情報が入っています。分析用の顧客ディメンションを確立するため最初に処理される構造化データです。
raw/transactions/transactions.json ファイルには、ネストされた製品配列を持つ購買取引が含まれます。半構造化データをフラット化し、顧客データと結合して購買パターンと顧客生涯価値の分析に使います。
raw/clickstream/clickstream.csv ファイルは、ユーザーの Web サイト操作と行動パターンを記録します。カスタマージャーニーとコンバージョンファネルの分析に使う時系列データです。
Amazon S3 にファイルをアップロードする詳細な手順は、オブジェクトのアップロード を参照してください。
CORS ポリシーの設定
SageMaker Unified Studio ドメインポータルからのアクセスを許可するため、バケットの Cross-Origin Resource Sharing (CORS) 設定を更新します。
- バケットの Permissions タブで、Cross-origin resource sharing (CORS) の Edit を選択します。

- 以下の CORS ポリシーを入力し、
domainUrlを SageMaker Unified Studio ドメイン URL (たとえばhttps://<domain-id>.sagemaker.us-east-1.on.aws) に置き換えます。URL は SageMaker Unified Studio コンソールのドメイン詳細ページの上部にあります。
詳細は Amazon S3 データの追加とプロジェクトロールを使用したアクセス を参照してください。
SageMaker プロジェクトロールへの Amazon S3 アクセス付与
SageMaker Unified Studio が外部 Amazon S3 のロケーションにアクセスできるようにするには、対応する AWS Identity and Access Management (IAM) プロジェクトロールに必要な権限を追加する必要があります。以下の手順を実施します。
- IAM コンソールで、ナビゲーションペインの Roles を選択します。
- プロジェクトロール Amazon Resource Name (ARN) の最後のセグメントでプロジェクトロールを検索します。この情報は、SageMaker Unified Studio の Project overview ページにあります (たとえば
datazone_usr_role_1a2b3c45de6789_abcd1efghij2kl)。
- プロジェクトロールを選択して、ロールの詳細ページを開きます。
- Permissions タブで Add permissions を選択し、Create inline policy を選択します。
- JSON エディタを使って、Amazon S3 ロケーションへのアクセスをプロジェクトロールに付与するポリシーを作成します。
- 以下の JSON ポリシーで、プレースホルダー値を実際の環境の値に置き換えます。
<BUCKET_PREFIX>を S3 バケット名のプレフィックス (たとえばecommerce-raw-layer) に置き換え<AWS_REGION>を AWS Glue Data Quality ルールセットを作成する AWS リージョン (たとえばus-east-1) に置き換え<AWS_ACCOUNT_ID>を AWS アカウント ID に置き換え
- 更新した JSON ポリシーを JSON エディタにペーストします。
- Next を選択します。
- ポリシー名 (たとえば
etl-rawlayer-access) を入力し、Create policy を選択します。 - 再度 Add permissions を選択し、Create inline policy を選択します。
- JSON エディタで、S3 Access Grants を管理する 2 つ目のポリシーを作成します。
<BUCKET_PREFIX>を S3 バケット名のプレフィックス (たとえばecommerce-raw-layer) に置き換えて、以下の JSON ポリシーをペーストします。 - Next を選択します。
- ポリシー名 (たとえば
s3-access-grants-policy) を入力し、Create policy を選択します。
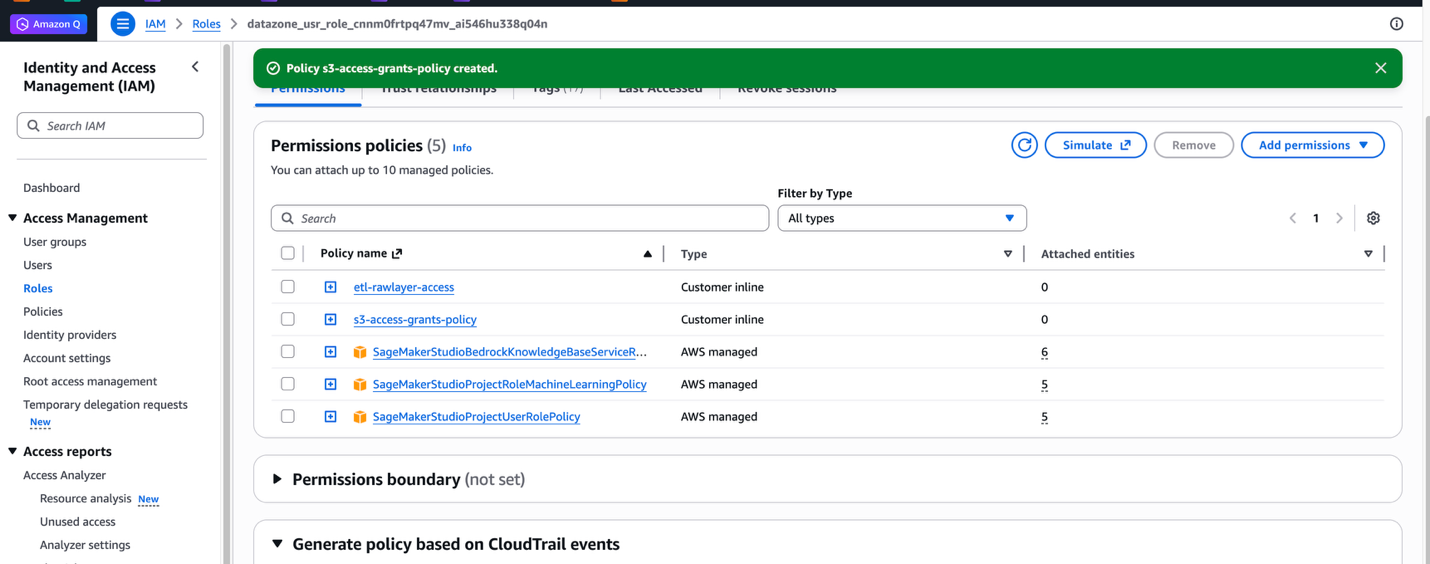
S3 Access Grants の詳細は Amazon S3 データの追加 を参照してください。
プロジェクトへの S3 バケットの追加
プロジェクトロールに Amazon S3 リソースへのアクセス用ポリシーを追加したら、以下の手順で S3 バケットを SageMaker Unified Studio プロジェクトに統合します。
- SageMaker Unified Studio で、Your projects から作成したプロジェクトを開きます。
- ナビゲーションペインで Data を選択します。
- Add を選び、続いて Add S3 location を選択します。
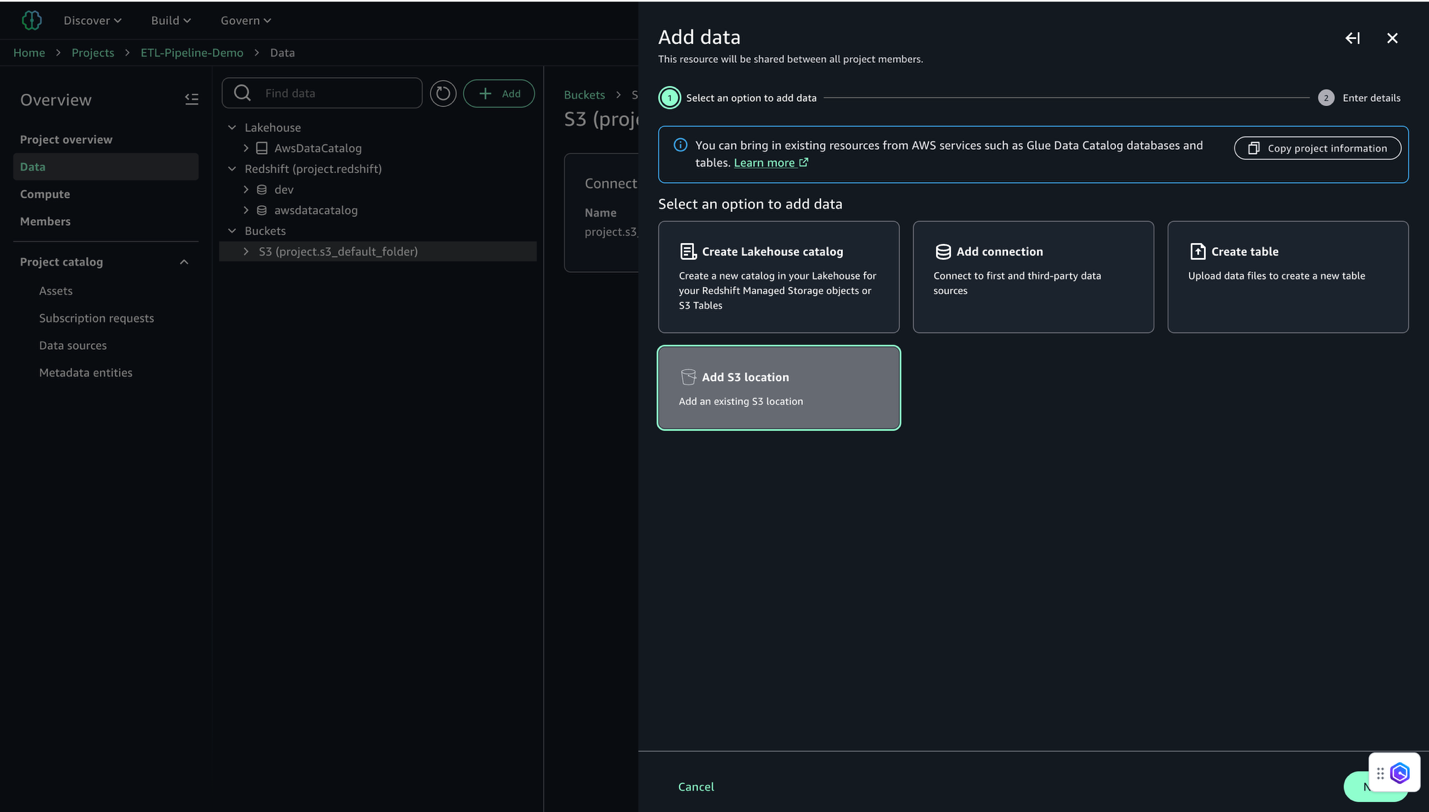
- S3 ロケーションを設定します。
- Name に分かりやすい名前 (たとえば
E-commerce_Raw_Data) を入力します。 - S3 URI にバケット URI (たとえば
s3://ecommerce-raw-layer-bucket-demo-<Account-ID>-us-east-1/) を入力します。 - AWS Region にリージョン (本例では
us-east-1) を入力します。 - Access role ARN は空のままにします。
- Add S3 Location を選択します。
- Name に分かりやすい名前 (たとえば
- 統合が完了するまで待ちます。
- プロジェクトのデータカタログに S3 ロケーションが表示されることを確認します (Project overview ページの Data タブで Buckets ペインを開き、バケットとフォルダを確認します)。
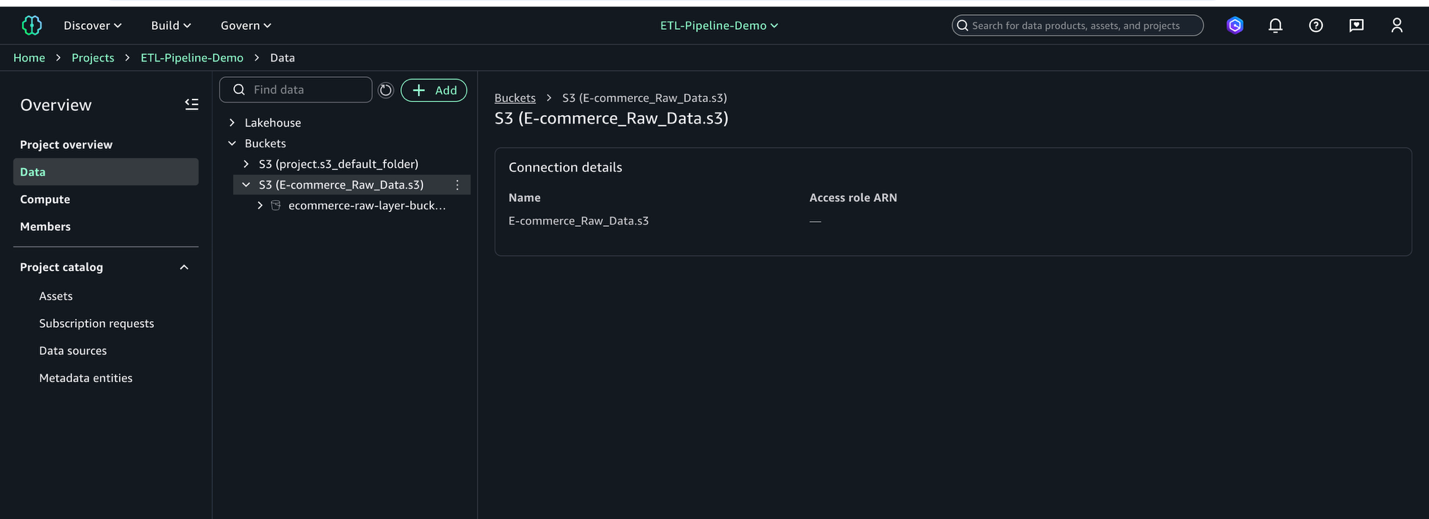
S3 バケットが SageMaker Unified Studio に接続され、データを分析に使える状態になります。
ジョブスクリプト用ノートブックの作成
データ処理ジョブを作成する前に、データの生成と処理を行うスクリプトを開発するためのノートブックをセットアップします。以下の手順を実施します。
- SageMaker Unified Studio の上部メニューで Build の下の JupyterLab を選択します。
- Configure Space を選択し、インスタンスタイプ ml.t3.xlarge を選びます。JupyterLab インスタンスに少なくとも 4 vCPU と 4 GiB メモリが確保されます。
- Configure and Start Space または Save and Restart を選択して環境を起動します。
- インスタンスの準備完了まで少し待ちます。
- File、New、Notebook を選び、新しいノートブックを作成します。
- Kernel を Python 3、Connection type を PySpark、Compute を
Project.spark.compatibilityに設定します。
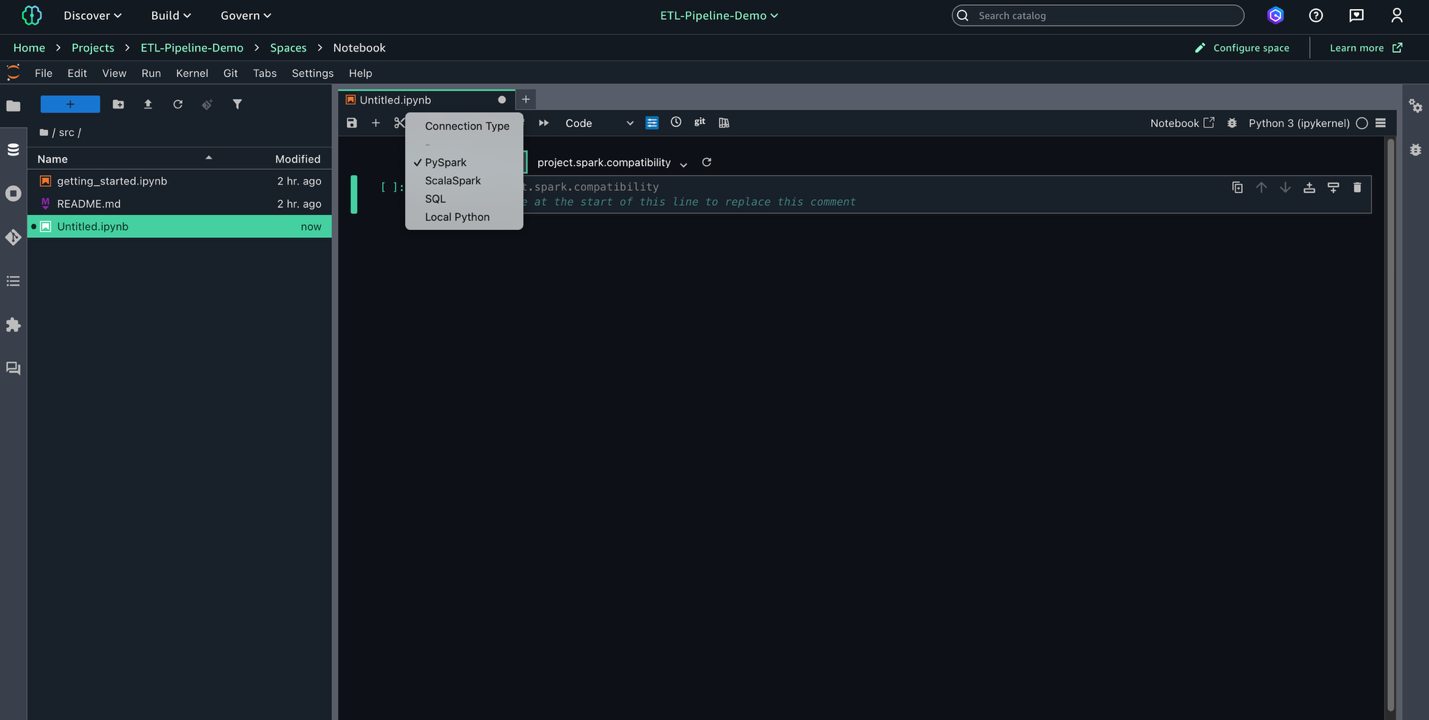
- ノートブックに以下のスクリプトを入力します。AWS Glue ジョブで後から使います。このスクリプトは、S3 データレイクの 3 つのソースから生データを処理し、日付を標準化してデータ型を変換し、最適なストレージとクエリのためにクレンジング済みデータを Parquet 形式で保存します。
- スクリプト内の
<Bucket-Name>を実際の S3 バケット名に置き換えます。Amazon S3 の raw レイヤーにある顧客、取引、クリックストリームのデータを処理し、processed レイヤーに Parquet ファイルとして保存します。
- File、Save Notebook As を選び、
shared/etl_initial_processing_job.ipynbとして保存します。
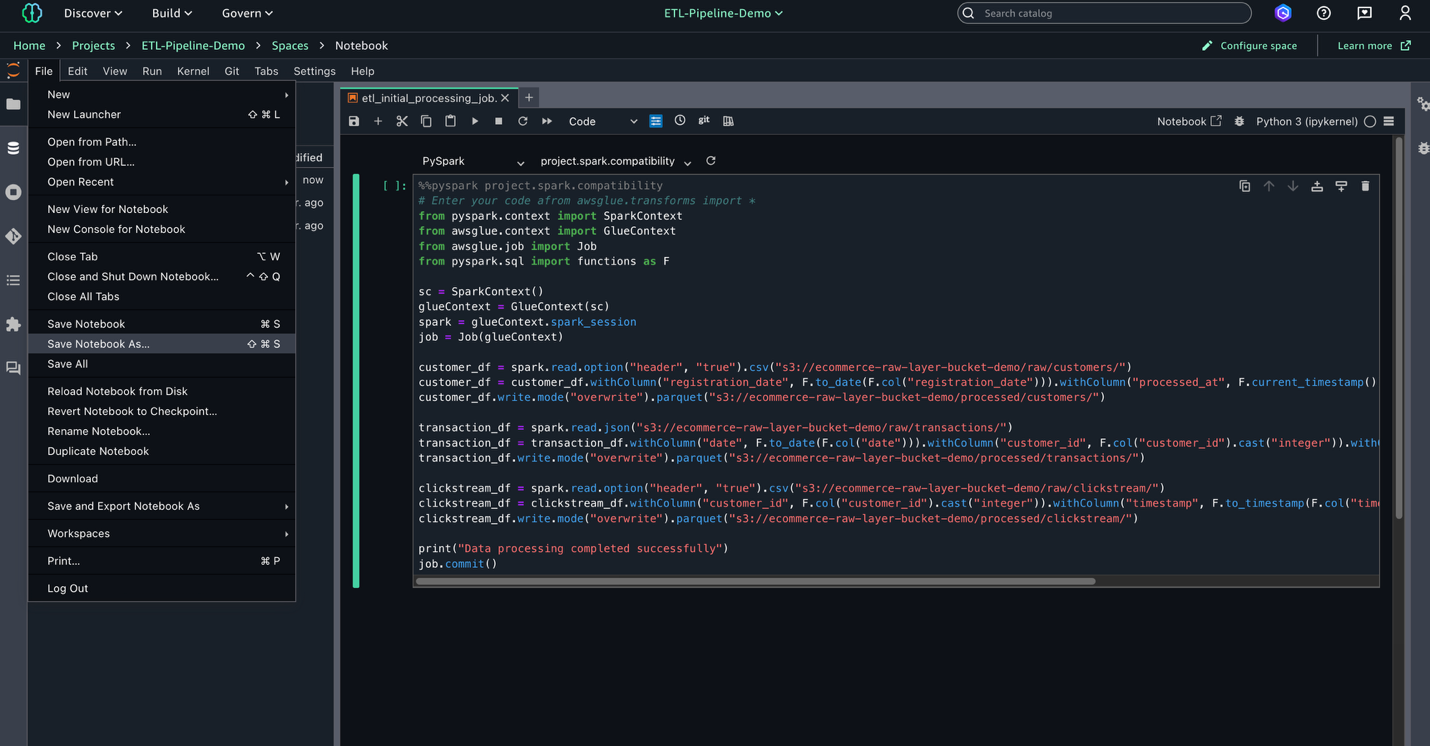
AWS Glue Data Quality 用ノートブックの作成
初期データ処理スクリプトを作成したら、次のステップとして AWS Glue でデータ品質チェックを実施するノートブックをセットアップします。データ品質チェックにより、後続処理の前にデータの整合性と完全性を検証できます。以下の手順を実施します。
- File、New、Notebook を選び、新しいノートブックを作成します。
- Kernel を Python 3、Connection type を PySpark、Compute を
Project.spark.compatibilityに設定します。
- この新しいノートブックに、AWS Glue の
EvaluateDataQualityメソッドを使ったデータ品質チェックスクリプトを追加します。スクリプト内の<Bucket-Name>を実際の S3 バケット名に置き換えます。 - File、Save Notebook As を選び、
shared/etl_data_quality_job.ipynbとして保存します。
AWS Glue ジョブの作成とテスト
SageMaker Unified Studio のジョブにより、AWS Glue を使ったスケーラブルで柔軟な ETL パイプラインを実現できます。効率的でガバナンスの効いたデータ変換に向けて、データ処理ジョブの作成とテスト手順を説明します。
初期データ処理ジョブの作成
ETL パイプラインの最初の処理ジョブとして、生の顧客、取引、クリックストリームデータを変換し、クレンジング済みの出力を Parquet 形式で Amazon S3 に書き込みます。ジョブを作成する手順は以下のとおりです。
- SageMaker Unified Studio でプロジェクトを開きます。
- 上部メニューで Build を選択し、Data Analysis & Integration の下の Data processing jobs を選択します。

- Create job from notebooks を選択します。
- Choose project files の下の Browse files を選択します。
etl_initial_processing_job.ipynb(先ほど JupyterLab で保存したノートブック) を見つけて選択し、Select、続いて Next を選択します。
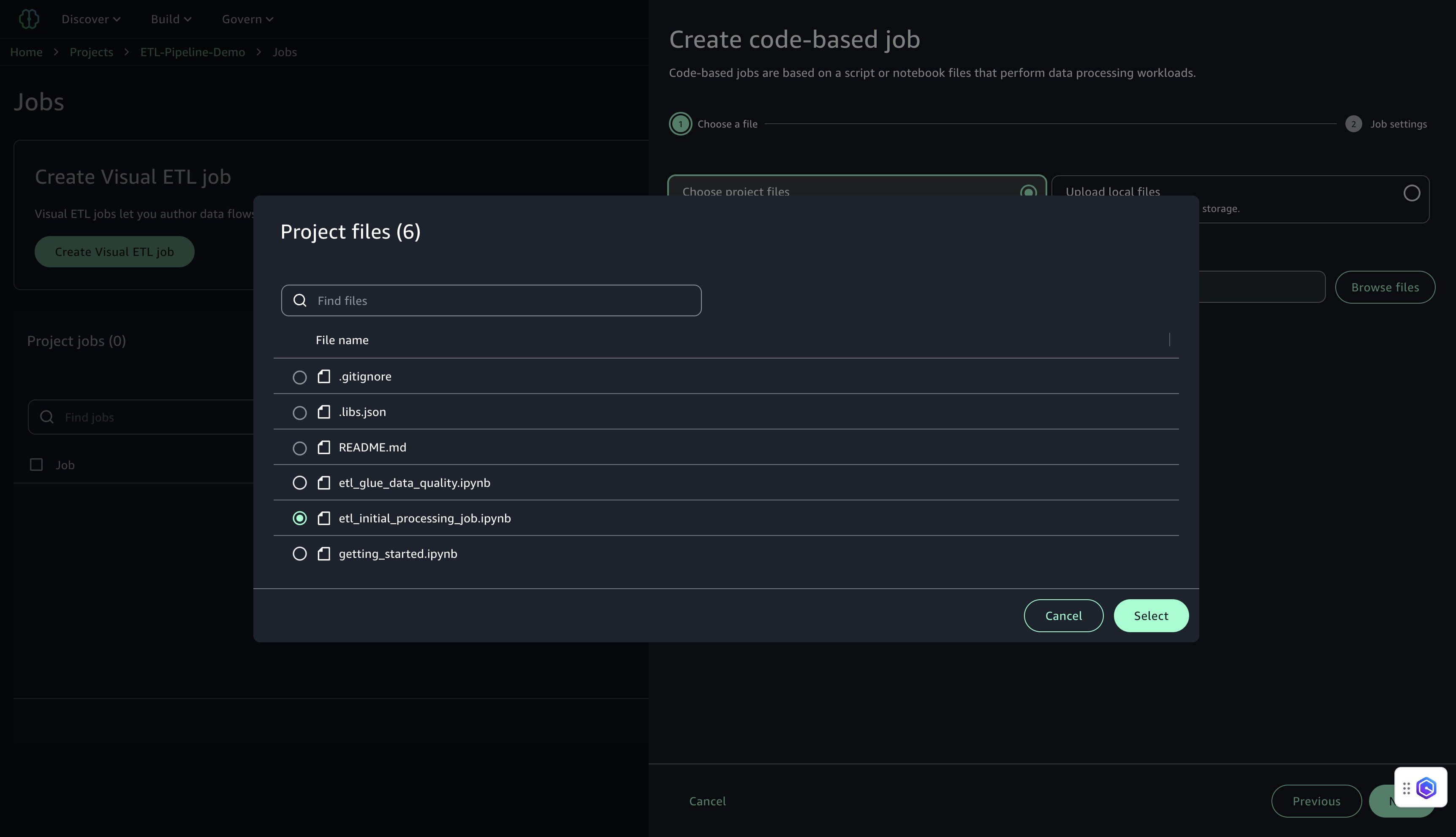
- ジョブ設定を構成します。
- Name に名前 (たとえば
job-1) を入力します。 - Description に説明 (たとえば
Initial ETL job for customer data processing) を入力します。 - IAM Role でプロジェクトロール (デフォルト) を選択します。
- Type で Spark を選択します。
- AWS Glue version はバージョン 5.0 を使用します。
- Language で Python を選択します。
- Worker type は G.1X を使用します。
- Number of Instances は 10 に設定します。
- Number of retries は 0 に設定します。
- Job timeout は 480 に設定します。
- Compute connection で
project.spark.compatibilityを選択します。 - Advanced settings で Continuous logging をオンにします。
- Name に名前 (たとえば
- 残りの設定はデフォルトのまま、Submit を選択します。
ジョブが作成されると、job-1 が正常に作成されたことを示す確認メッセージが表示されます。
AWS Glue Data Quality ジョブの作成
変換済みデータセットに対して AWS Glue Data Quality によるデータ品質チェックを実行します。ルールセットで主要フィールドの完全性と一意性を検証します。ジョブを作成する手順は以下のとおりです。
- SageMaker Unified Studio でプロジェクトを開きます。
- 上部メニューで Build を選び、Data Analysis & Integration の下の Data processing jobs を選択します。
- Create job、Code-based job、Create job from files を選択します。
- Choose project files の下の Browse files を選択します。
etl_glue_data_quality.ipynbを見つけて選択し、Select、続いて Next を選択します。- ジョブ設定を構成します。
- Name に名前 (たとえば
job-2) を入力します。 - Description に説明 (たとえば
Data quality checks using AWS Glue Data Quality) を入力します。 - IAM Role でプロジェクトロールを選択します。
- Type で Spark を選択します。
- AWS Glue version はバージョン 5.0 を使用します。
- Language で Python を選択します。
- Worker type は G.1X を使用します。
- Number of Instances は 10 に設定します。
- Number of retries は 0 に設定します。
- Job timeout は 480 に設定します。
- Compute connection で
project.spark.compatibilityを選択します。 - Advanced settings で Continuous logging をオンにします。
- 残りの設定はデフォルトのまま、Submit を選択します。
ジョブが作成されると、job-2 が正常に作成されたことを示す確認メッセージが表示されます。
AWS Glue ジョブのテスト
両方のジョブをテストして、正常に実行されることを確認します。
- SageMaker Unified Studio でプロジェクトを開きます。
- 上部メニューで Build を選び、Data Analysis & Integration の下の Data processing jobs を選択します。
job-1を選び、Run job を選択します。- ジョブの実行状況を監視し、正常に完了することを確認します。
- 同様に、
job-2を選び、Run job を選択します。 - ジョブの実行状況を監視し、正常に完了することを確認します。
EMR Serverless コンピュートの追加
ETL パイプラインでは、大規模データセットに対する計算負荷の高い変換と集計に EMR Serverless を使います。ワークロードに応じてリソースが自動スケールし、運用がシンプルなまま高いパフォーマンスを発揮します。EMR Serverless を SageMaker Unified Studio と統合することで、サーバーレス環境で Jupyter ノートブックから Spark ジョブを対話的に実行できます。
SageMaker Studio 内で EMR Serverless コンピュートを設定し、分散データ処理ジョブの実行に使う手順を説明します。
SageMaker Unified Studio での EMR Serverless の設定
プロジェクトで EMR Serverless を使って処理を行うには、以下の手順を実施します。
- Project Overview のナビゲーションペインで Compute を選択します。
- Data processing タブで Add compute、Create new compute resources を選択します。
- EMR Serverless を選び、Next を選択します。
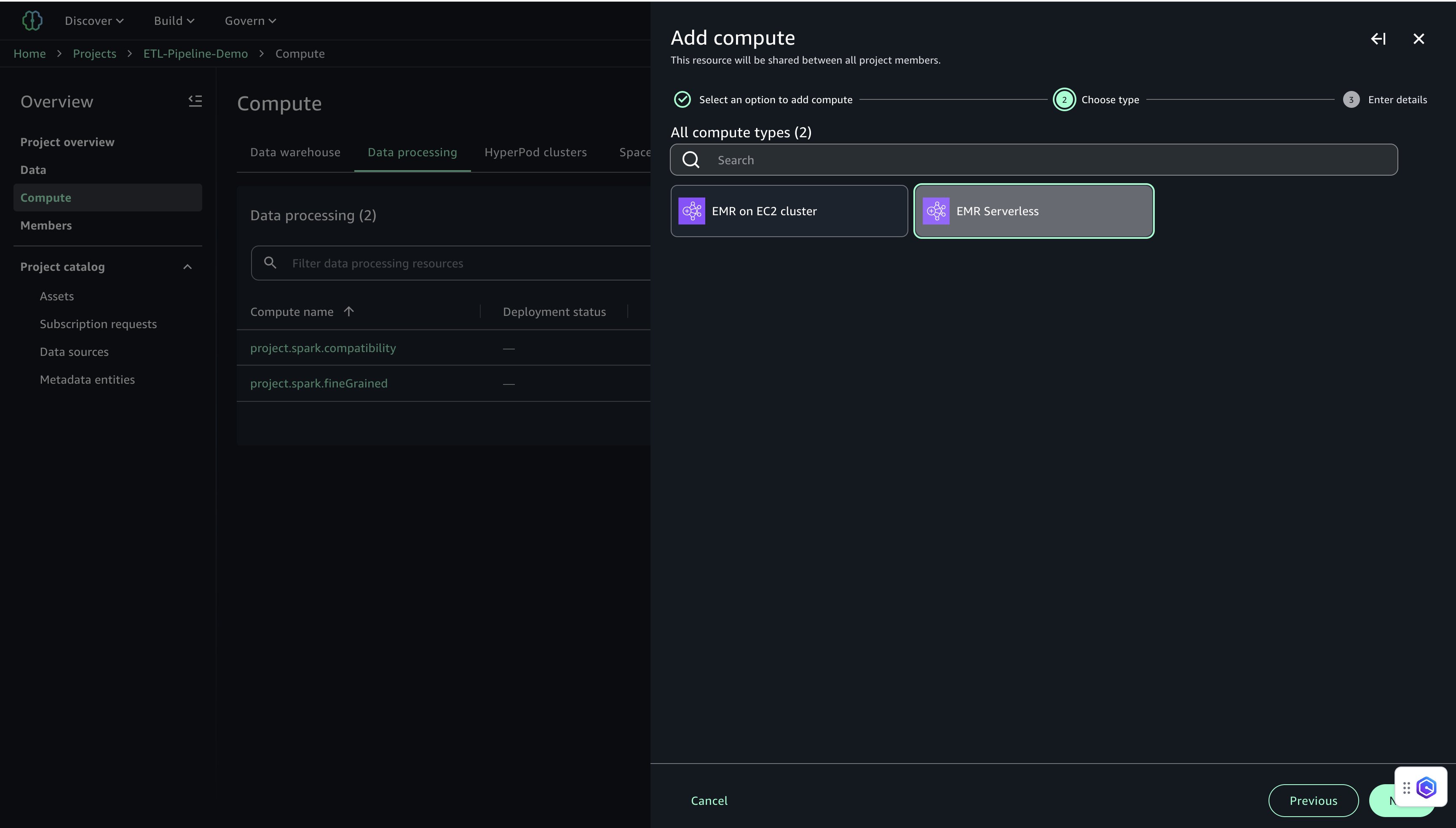
- EMR Serverless の設定を行います。
- Compute name に名前 (たとえば
etl-emr-serverless) を入力します。 - Description に説明 (たとえば
EMR Serverless for advanced data processing) を入力します。 - Release label で emr-7.8.0 を選択します。
- Permission mode で Compatibility を選択します。
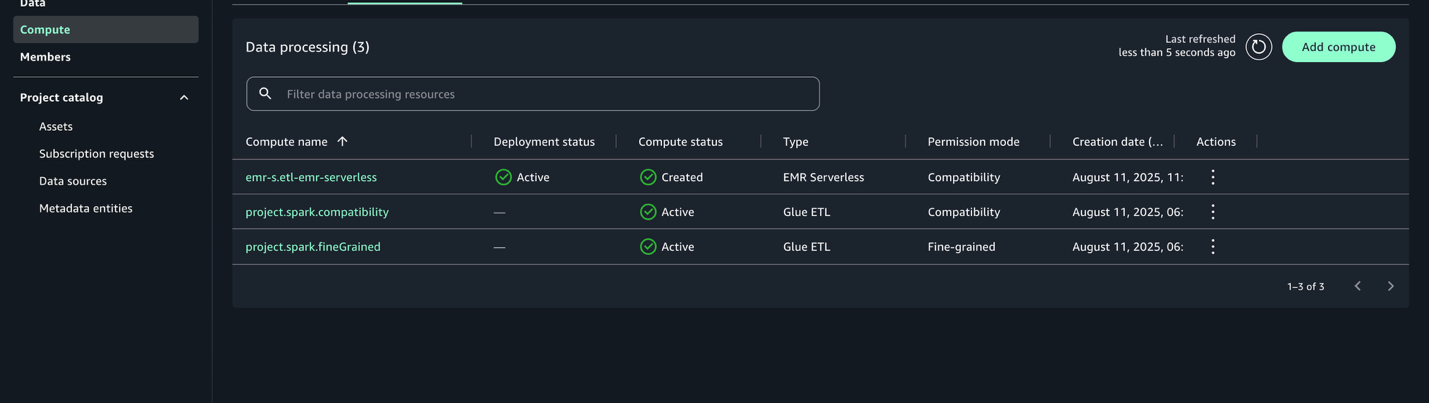
- Add Compute を選択してセットアップを完了します。
設定が完了すると、EMR Serverless コンピュートはデプロイステータス Active で一覧に表示されます。
EMR Serverless でのノートブックの作成と実行
EMR Serverless コンピュートを作成したら、Jupyter ノートブックで PySpark ベースのデータ変換ジョブを実行し、大規模データ変換を行えます。クレンジング済みの顧客、取引、クリックストリームデータセットを Amazon S3 から読み込み、集計とスコアリングを行い、最終的な分析出力を Parquet と CSV の両形式で Amazon S3 に書き戻します。EMR Serverless 処理用ノートブックを作成する手順は以下のとおりです。
- 上部メニューで Build の下の JupyterLab を選択します。
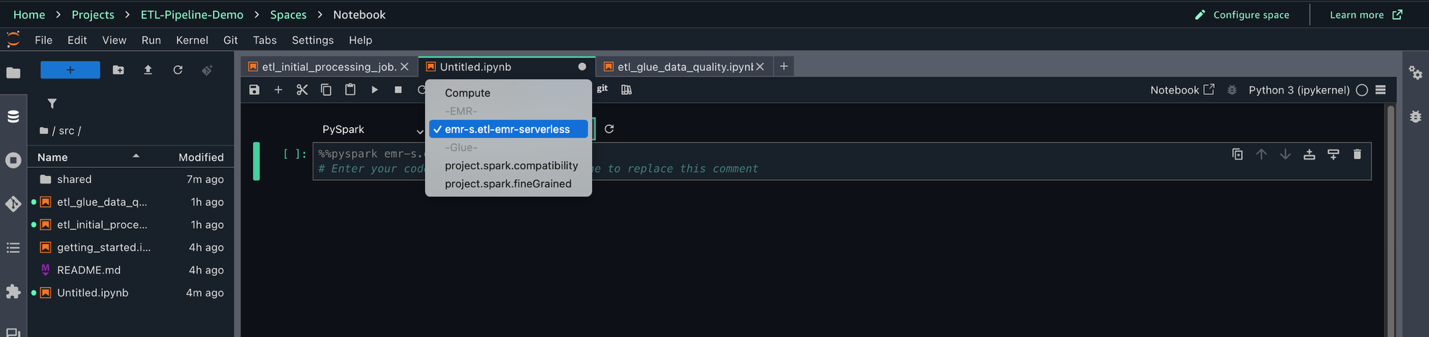
- File、New、Notebook を選択します。
- Kernel を Python 3、Connection type を PySpark、Compute を
emr-s.etl-emr-serverlessに設定します。
- EMR Serverless でデータ変換ジョブを実行するため、以下の PySpark スクリプトを入力します。S3 バケット名を指定します。
- File、Save Notebook As を選び、
shared/emr_data_transformation_job.ipynbとして保存します。 - Run Cell を選択してスクリプトを実行します。
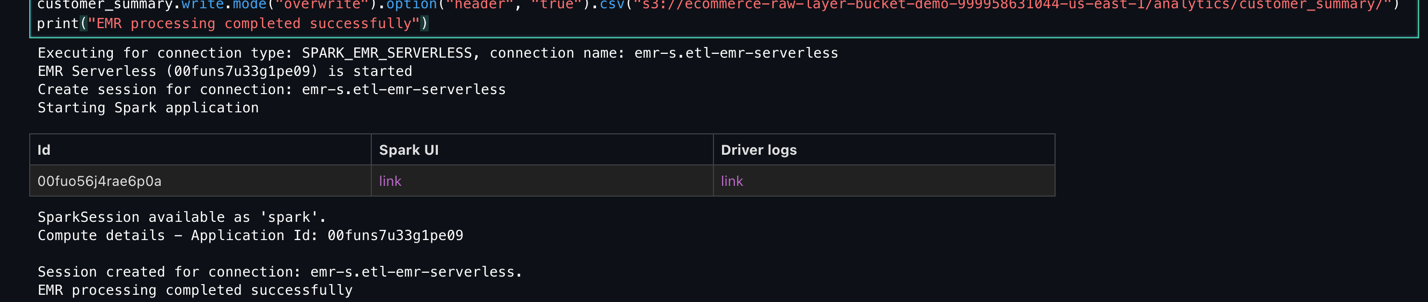
- スクリプトの実行状況を監視し、正常に完了することを確認します。
- Spark ジョブの実行状況を監視し、エラーなく完了することを確認します。
Redshift Serverless コンピュートの追加
Redshift Serverless により、インフラを管理せずにデータウェアハウスワークロードを実行・スケールできます。Amazon S3 からデータをクエリしたり、中央ウェアハウスに統合したりする分析ユースケースに適しています。本ステップでは、パイプラインの前段階で生成された処理済みの顧客分析データをロード・クエリするため、Redshift Serverless をプロジェクトに追加します。Redshift Serverless の詳細は Amazon Redshift Serverless を参照してください。
SageMaker Unified Studio での Redshift Serverless コンピュートのセットアップ
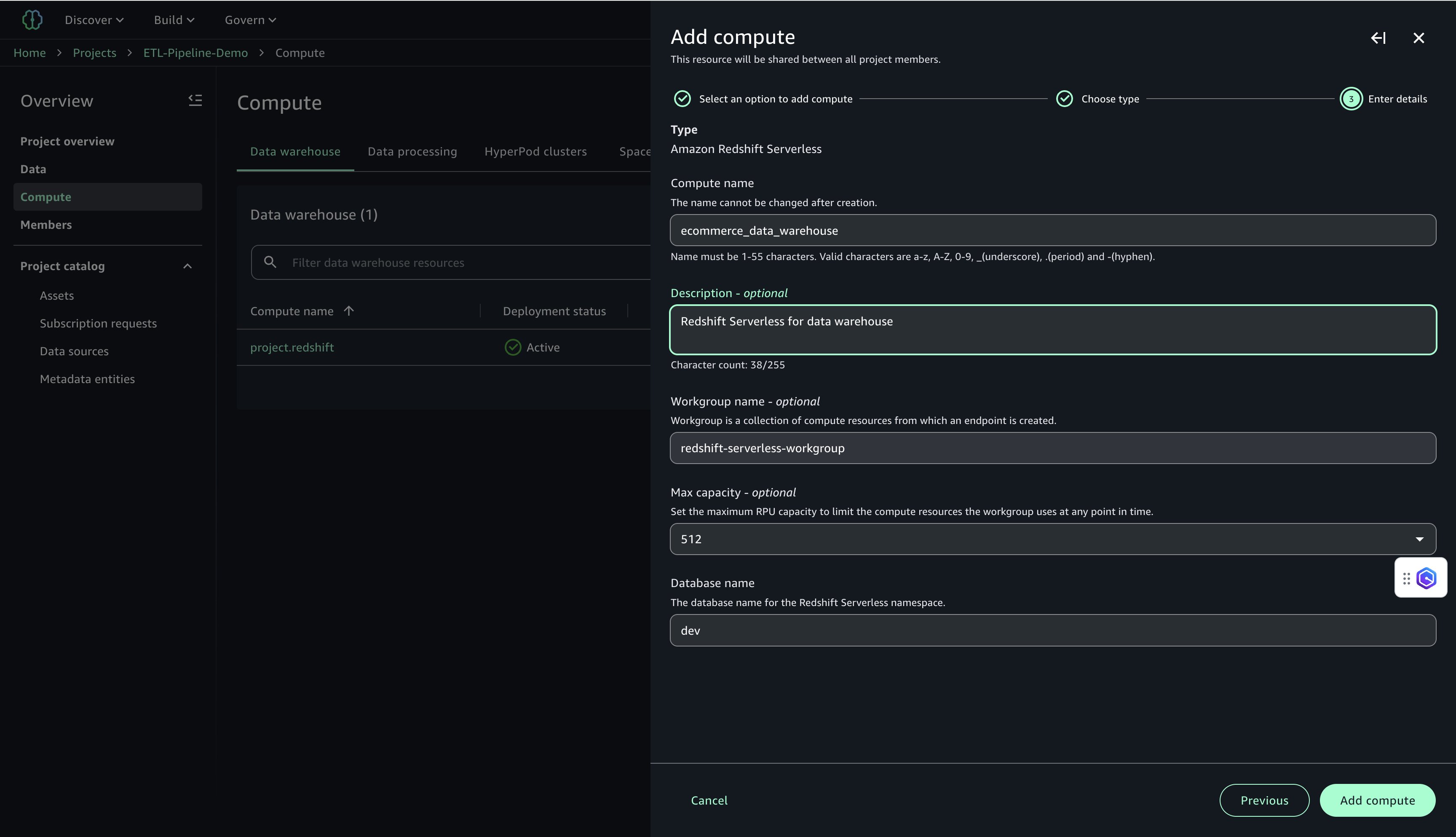
Redshift Serverless コンピュートをセットアップする手順は以下のとおりです。
- SageMaker Unified Studio のプロジェクトワークスペース (
ETL-Pipeline-Demo) で Compute タブを選択します。 - SQL analytics タブで Add compute、続いて Create new compute resources を選択し、コンピュート環境の設定を開始します。
- Amazon Redshift Serverless を選択します。
- 以下を設定します。
- Compute name に名前 (たとえば
ecommerce_data_warehouse) を入力します。 - Description に説明 (たとえば
Redshift Serverless for data warehouse) を入力します。 - Workgroup name に名前 (たとえば
redshift-serverless-workgroup) を入力します。 - Maximum capacity は 512 RPU に設定します。
- Database name に
devを入力します。
- Compute name に名前 (たとえば
- Add Compute を選択して Redshift Serverless リソースを作成します。
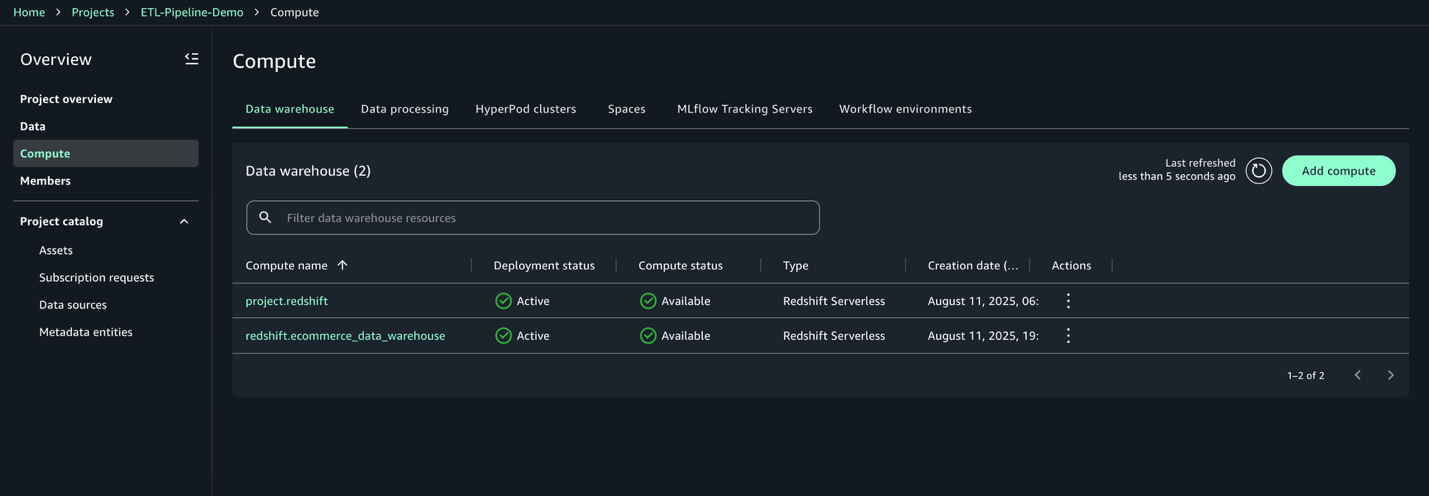
コンピュートを作成したら、Amazon Redshift 接続をテストできます。
- Data warehouse タブで、
redshift.ecommerce_data_warehouseが表示されていることを確認します。
- コンピュート
redshift.ecommerce_data_warehouseを選択します。 - Permissions タブで IAM ロール ARN をコピーします。次のステップで Redshift の COPY コマンドに使います。

クエリブックの作成・実行による Amazon Redshift へのデータロード
本ステップでは、処理済みの顧客サマリーデータを Amazon S3 から Redshift テーブルにロードする SQL スクリプトを作成します。顧客セグメンテーション、生涯価値の算出、マーケティングキャンペーン向けの分析が可能になります。以下の手順を実施します。
- Build メニューの Data Analysis & Integration の下で Query editor を選択します。
- クエリブックに以下の SQL を入力し、public スキーマに
customer_summaryテーブルを作成します。 - Add SQL を選択して新しい SQL スクリプトを追加します。
- クエリブックに以下の SQL を入力します。
注: COPY コマンドを実行する前に、既存のレコードを削除し、S3 からの最新の集計データを重複なくクリーンに再ロードするため、
customer_summaryテーブルを TRUNCATE します。 - Add SQL を選択して新しい SQL スクリプトを追加します。
- 以下の SQL を入力し、S3 バケットから Redshift Serverless にデータをロードします。S3 バケット名と Amazon Redshift 用の IAM ロール ARN を指定します。
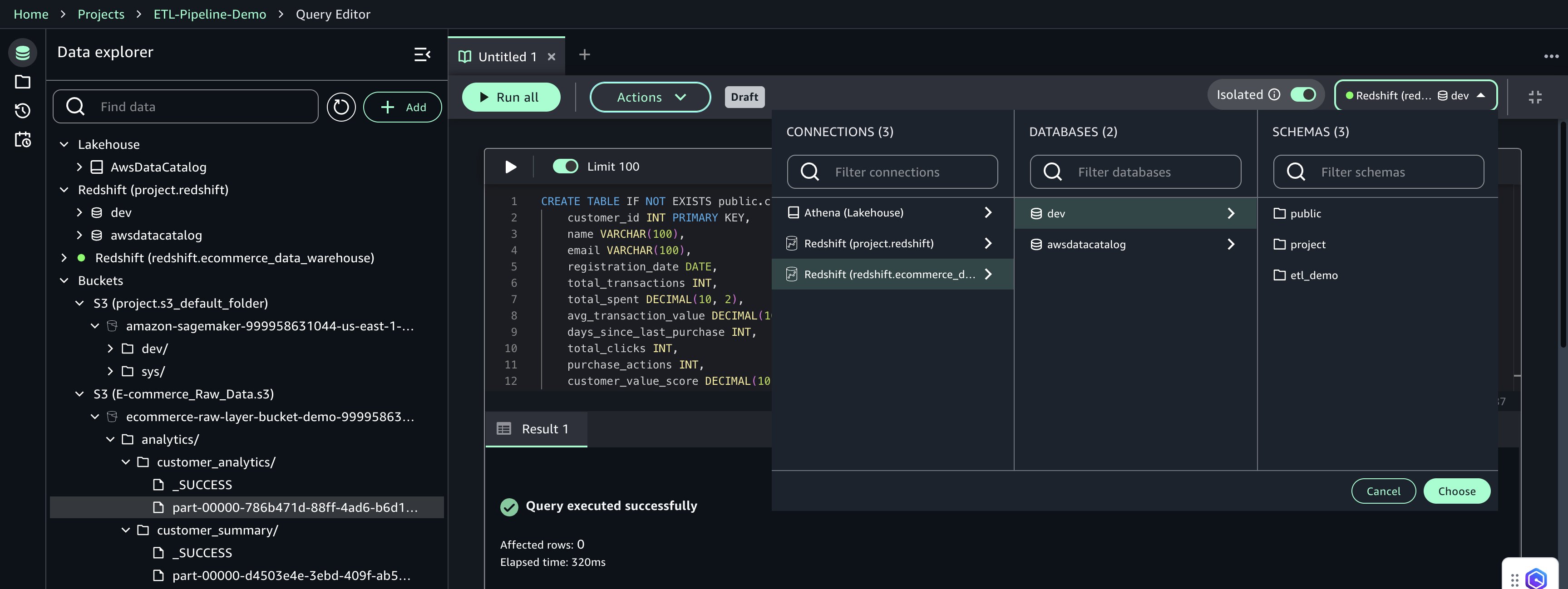
- Query Editor で以下を設定します。
- Connection:
redshift.ecommerce_data_warehouse - Database:
dev - Schema:
public
- Connection:
- Choose を選択して接続設定を適用します。
- 各セルで Run Cell を選択し、public スキーマに
customer_summaryテーブルを作成してから、Amazon S3 からデータをロードします。 - Actions、Save を選び、クエリブック名を
final_data_productとして Save changes を選択します。
これで、クエリブックを使った Redshift データプロダクトの作成と実行は完了です。
ワークフロー環境の作成と管理
共有ワークフロー環境の作成と、SageMaker Unified Studio 内の Apache Airflow を使って顧客データパイプラインを自動化するコードベースのワークフローの定義方法を説明します。共有環境でプロジェクトメンバー間の協働とワークフローの一元管理を実現できます。
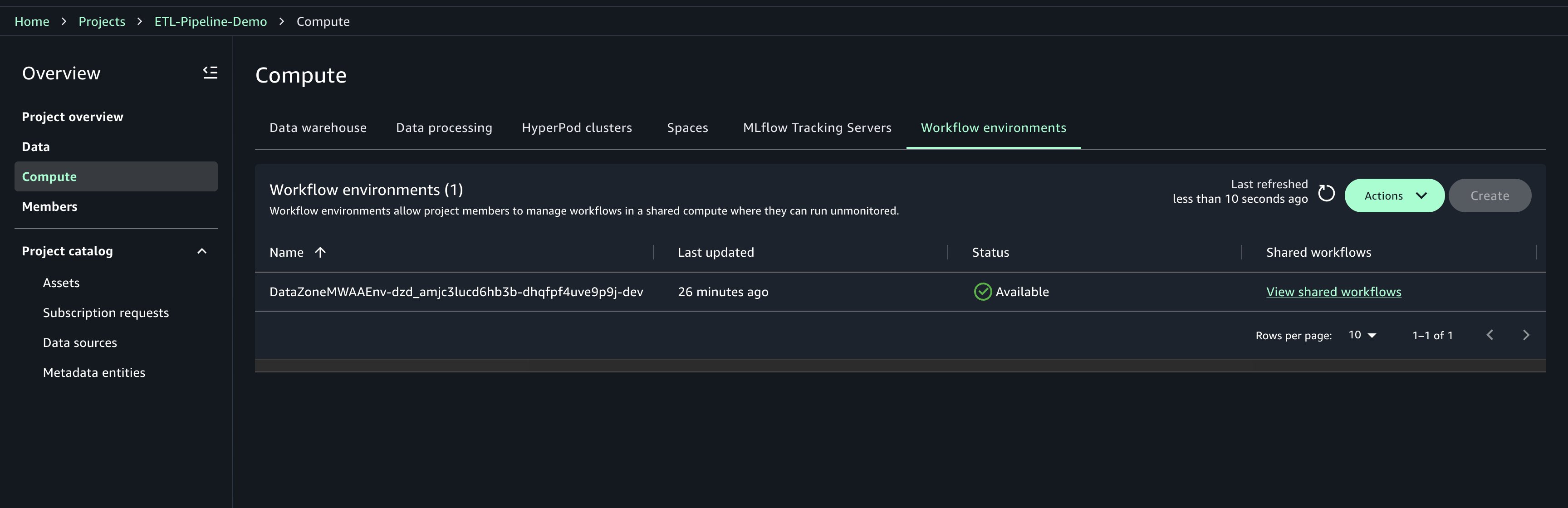
ワークフロー環境の作成
ワークフロー環境はプロジェクトオーナーが作成する必要があります。作成後、プロジェクトメンバーはワークフローを同期して利用できます。ワークフロー環境の更新・削除はプロジェクトオーナーのみが行えます。ワークフロー環境を作成する手順は以下のとおりです。
- プロジェクトの Compute を選択します。
- Workflow environments タブで Create を選択します。
- 設定パラメータを確認し、Create workflow environment を選択します。
- 環境のプロビジョニングが完了するまで待ちます。プロビジョニングには約 20 分かかります。
コードベースのワークフローの作成
ワークフロー環境の準備ができたら、Airflow を使ってコードベースの ETL パイプラインを定義します。AWS Glue、EMR Serverless、Redshift Serverless などのサービスにまたがる日次処理タスクを自動化するパイプラインを定義します。
- Build メニューの Orchestration の下で Workflows を選択します。
- Create new workflow を選び、Create workflow in code editor を選択します。
- Configure Space を選択し、インスタンスタイプ ml.t3.xlarge を選びます。JupyterLab インスタンスに少なくとも 4 vCPU と 4 GiB メモリが確保されます。
- Configure and Restart Space を選択して環境を起動します。

以下のスクリプトは、複数のアクションを自動化する日次スケジュールの ETL ワークフローを定義します。
- AWS Glue による初期データ変換
- AWS Glue (EvaluateDataQuality) によるデータ品質検証
- Jupyter ノートブックを使った EMR Serverless での高度なデータ処理
- クエリブックから Redshift Serverless への変換結果のロード
- デフォルトの DAG テンプレートを以下の定義に置き換えます。ジョブ名と入力パスは、プロジェクトで実際に使っているものに合わせてください。
- File、Save python file を選び、ファイル名を
shared/workflows/dags/customer_etl_pipeline.pyとして Save を選択します。
ワークフローのデプロイと実行
ワークフローを実行する手順は以下のとおりです。
- Build メニューで Workflows を選択します。
- ワークフロー
customer_etl_pipelineを選び、Run を選択します。
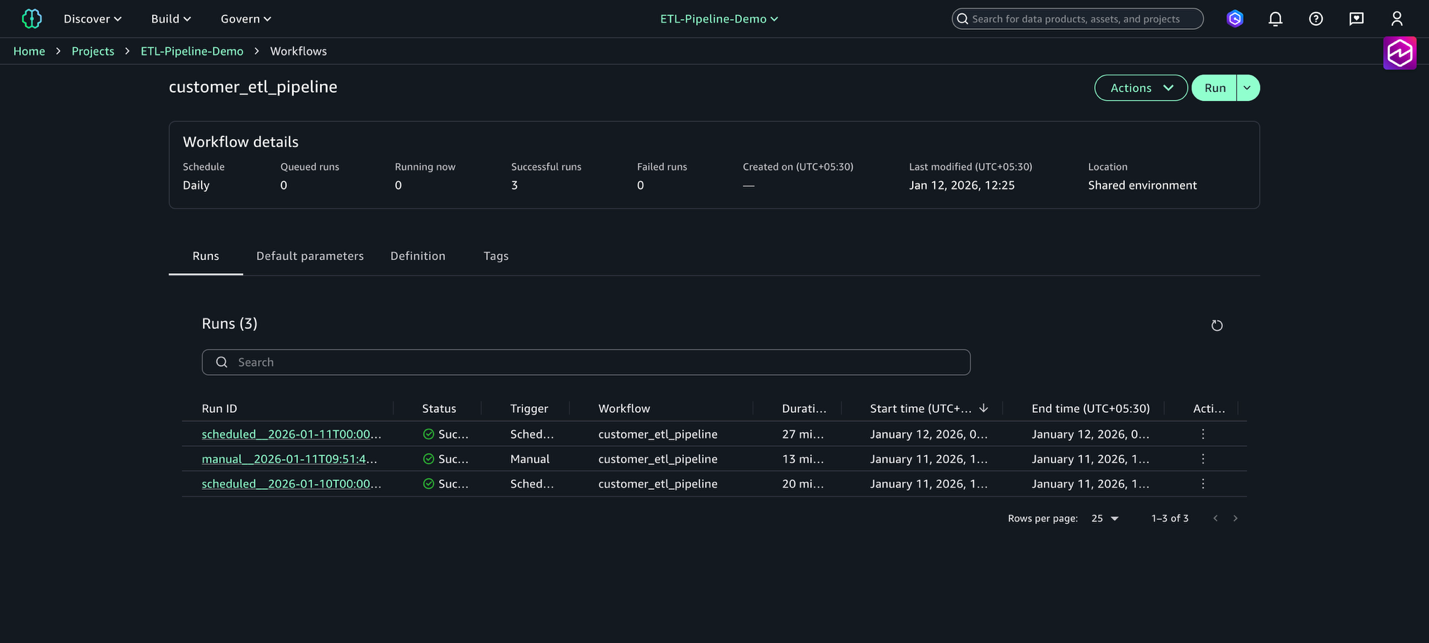
ワークフローを実行すると、Amazon SageMaker Unified Studio のアーティファクトをオーケストレーションするタスクがまとめて実行されます。Workflows ページに移動し、ワークフロー一覧テーブルでワークフロー名を選択すると、ワークフローの複数回の実行履歴を確認できます。
ワークフロー環境でワークフローを他のプロジェクトメンバーと共有するには、Amazon SageMaker Unified Studio ワークフロー環境で他のプロジェクトメンバーとコードワークフローを共有する を参照してください。
ワークフローの監視とトラブルシューティング
SageMaker Unified Studio にデプロイした Airflow ワークフローを信頼性の高い ETL 運用として維持するには、監視が欠かせません。統合された Amazon MWAA 環境は、使い慣れた Airflow Web インターフェースを通じてデータパイプラインの状態を把握でき、AWS の監視機能で強化されています。Amazon MWAA と SageMaker Unified Studio の統合により、DAG 実行のリアルタイム追跡、タスクの詳細ログ、パフォーマンス指標を確認でき、パイプラインの問題を素早く特定・解決できます。ワークフローを監視する手順は以下のとおりです。
- Build メニューで Workflows を選択します。
- ワークフロー
customer_etl_pipelineを選択します。 - View runs を選び、すべての実行を確認します。
- 特定の実行を選択して、タスクの詳細な状態を確認します。
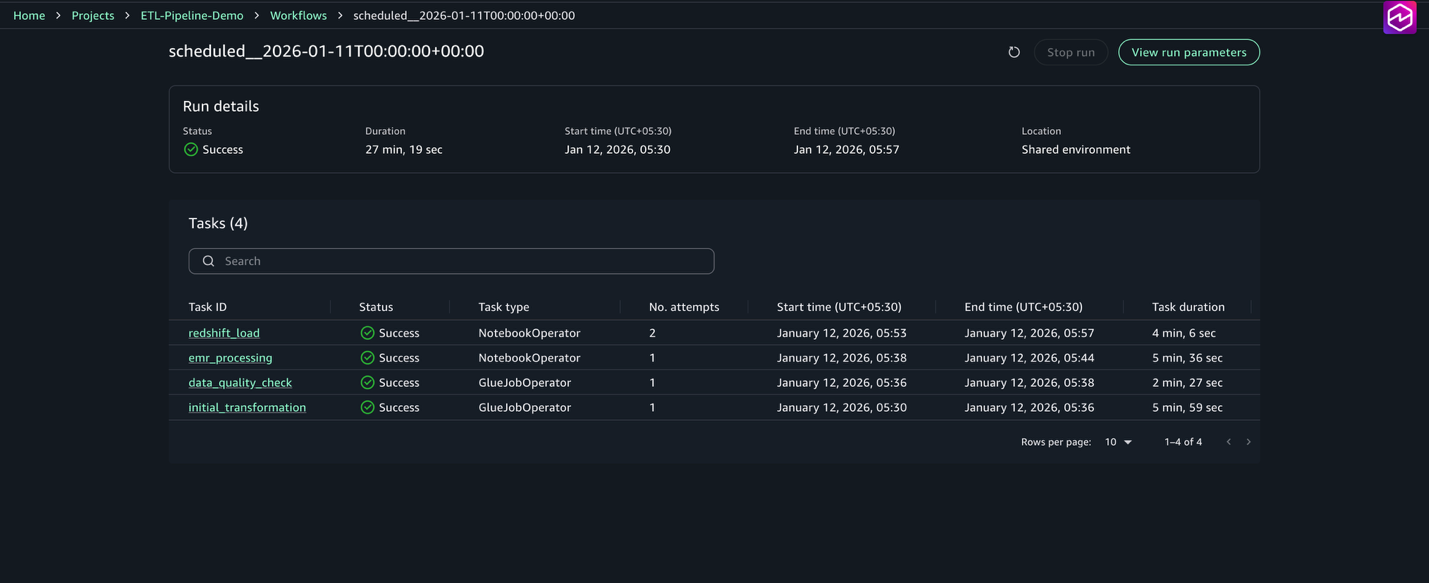
タスクごとに、状態 (Succeeded、Failed、Running)、開始・終了時刻、実行時間、ログと出力を確認できます。ワークフローは Airflow UI でも確認できます。ワークフロー環境からアクセスでき、DAG グラフの表示、タスク実行のリアルタイム監視、詳細ログへのアクセス、状態の確認が可能です。
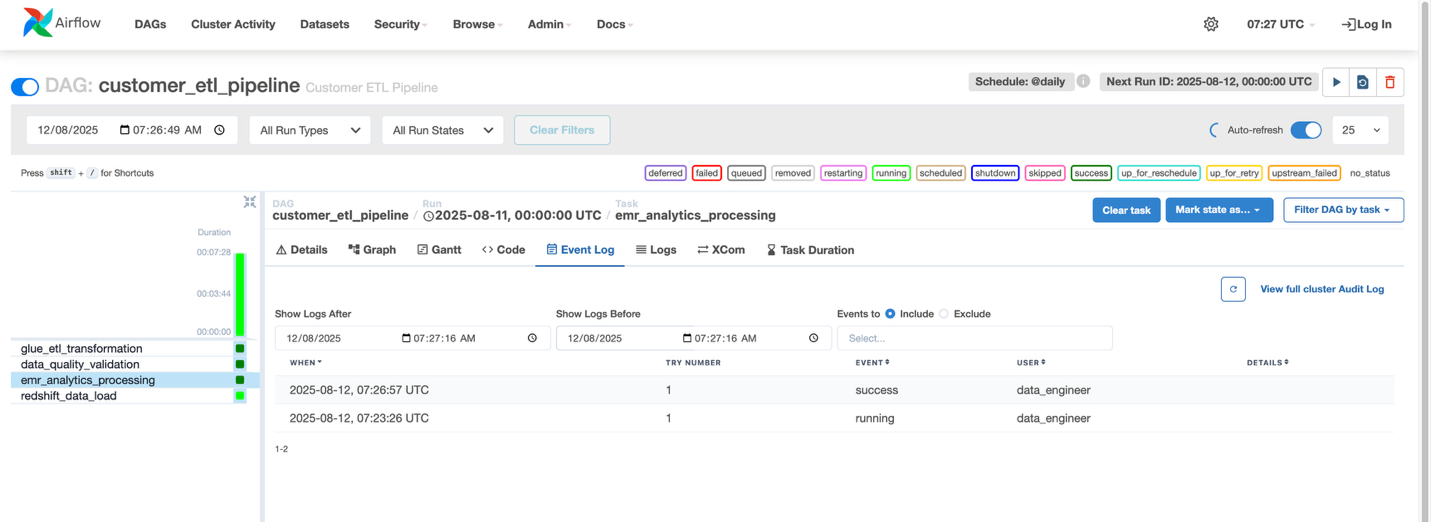
- Workflows に移動し、customer_etl_pipeline という名前のワークフローを選択します。
- Actions メニューで Open in Airflow UI を選択します。
ワークフローが正常に完了したら、クエリエディタでデータプロダクトをクエリできます。
- Build メニューの Data Analysis & Integration の下で Query editor を選択します。
select * from "dev"."public"."customer_summary"を実行します。
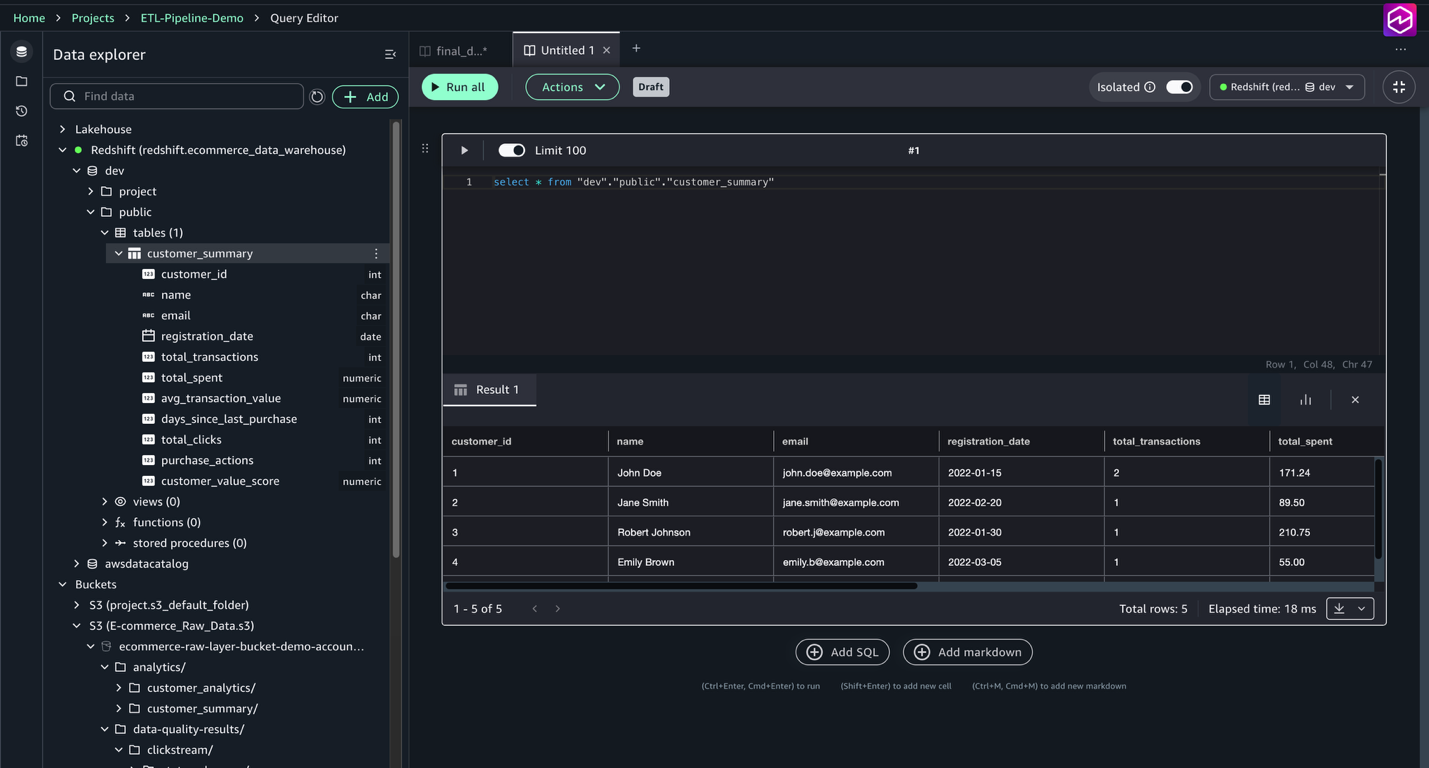
customer_summary テーブルの内容を確認します。総取引数、総利用額、平均取引額、クリック数、顧客価値スコアなどの集計された顧客指標が含まれます。ETL とデータ品質パイプラインがデータを正しくロード・変換したかを検証できます。
クリーンアップ
不要な料金を避けるため、以下の手順を実施してください。
- ワークフロー環境を削除します。
- 不要になった場合は、プロジェクトを削除します。
- プロジェクトを削除したあと、ドメインを削除します。
まとめ
本記事では、SageMaker Unified Studio ワークフローを使ってエンドツーエンドの ETL パイプラインを構築する方法を紹介しました。Amazon S3 の CORS 設定や IAM 権限など基礎的な AWS インフラのセットアップから、高度なデータ処理ワークフローの実装まで、開発ライフサイクル全体を通して解説しました。本ソリューションでは、初期データ変換と品質チェックに AWS Glue、高度な処理に EMR Serverless、データウェアハウジングに Redshift Serverless を組み合わせ、すべてを Airflow DAG でオーケストレーションしています。このアプローチは、必要なツールを集約する統一インターフェース、Python ベースのワークフローの柔軟性、AWS サービスのシームレスな統合、Git バージョン管理による協働開発、サーバーレス計算によるコスト効率の高いスケーリング、包括的な監視ツールなど、複数のメリットをもたらします。効率的で保守しやすいデータパイプラインを実現します。
SageMaker Unified Studio ワークフローを使うことで、エンタープライズレベルの信頼性とスケーラビリティを保ちつつ、データパイプライン開発を加速できます。SageMaker Unified Studio とその機能の詳細は Amazon SageMaker Unified Studio のドキュメントを参照してください。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の Woosuk Choi がレビューしました。