Amazon Web Services ブログ
キヤノンIT ソリューションズ様と取り組むホテルのフードロス削減 – 時系列基盤モデル Chronos-2 で最適な提供量を予測する
本ブログは、キヤノンITソリューションズ株式会社とアマゾン ウェブ サービス ジャパン合同会社が共同で執筆いたしました。
みなさま、こんにちは。AWS ソリューションアーキテクトの戸塚、大久保、寺山です。
Amazon および AWS は、The Climate Pledge を通じた2040 年までのネットゼロカーボン達成のコミットメントや、再生可能エネルギー活用の拡大などを通じて、事業運営にサステナビリティを組み込む取り組みを継続しています。ホテル・外食産業や流通小売業界等では、需要予測や在庫最適化によるフードロス削減が環境負荷の低減と収益性向上の両面で重要性を増しており、AWS ではフードロス削減を支援するアーキテクチャやお客様事例をご紹介しています。こうした文脈の中で、Chronos-2 は、事前学習済みの時系列基盤モデルによるゼロショット推論を活用することで、個別モデル学習を必要とせず、計算リソースを抑えながら高精度な需要予測を実現します。さらに推論基盤として AWS Graviton プロセッサ搭載インスタンスを組み合わせることで、価格性能比および電力効率に優れた構成を採用でき、Well-Architected Framework の持続可能性の柱にも配慮したアーキテクチャとして、二酸化炭素排出量の抑制に貢献することが期待できます。
本ブログでは、こうした取り組みの一例として、キヤノンITソリューションズ様と共同で取り組んだ Chronos-2 による需要予測を起点としたフードロス削減 PoC について、アーキテクチャと技術的なポイントをご紹介します。
本取組の背景
令和 5 年度の日本全体のフードロスは約 464 万トンであり、そのうちホテルを含む外食産業由来のフードロスは約 66 万トンを占めています。中でもホテル業界では、以下のような特徴からフードロスが発生しやすい環境にあり、長年に渡り業界全体の課題となっていました。
- ビュッフェ提供における過剰提供・見栄え重視
- 婚礼・宴会における需要変動の大きさ
- 宿泊客数の予測不確実性
- サービス品質重視による欠品 NG の文化
ホテル業界では、仕入れ・調理・提供・食べ残しといった各工程でフードロスが発生する上に、昨今では SDGs への取り組みを企業側に期待する宿泊客も増加しています。フードロス削減はコスト削減・業務効率化・ブランド価値向上の観点からホテル経営における重要テーマとなっています。
30 年以上にわたり PMS(※1)を中心としたホテル向けシステムを手掛けてきたキヤノンITソリューションズ株式会社様(以下、キヤノン ITS)にも、近年お客さまから「データはあるが、具体的な削減施策にどう結びつければよいか」という相談が増えています。こうした声を受け、ホテル事業を営むお客さまにご協力いただきながら、Chronos-2 を用いた需要予測によるフードロス削減の PoCに取り組みました。
(※1)「Property Management System(プロパティ・マネジメント・システム)」の略で、「宿泊予約の管理」「客室の管理」「顧客管理」「売上・請求管理」「データ分析」まで、宿泊施設の運営を支援するホテル管理システム
フードロス削減のPoCについて
すでにホテルにおけるフードロス対策は数多く展開されているものの、持ち帰りや販売など余った料理を活用する方法は食品衛生の観点から、やることに不安を持つお客さまもいます。また、新しい業務が増えることによる現場スタッフの負荷増大の懸念もあります。
そのため、キヤノン ITS は「料理を余らせない」「現場の業務に影響が少ない」アプローチとして需要予測の精度向上による最適な発注量・提供量によるフードロス削減のPoCに取り組みました。
PoCでは、複数のホテルブランドを展開するキヤノン ITS のお客さまにご協力いただきました。このお客さまは、各店舗で発生しているロス量の記録はできていたものの、具体的な対策までは着手ができていませんでした。
そこで、ロス量の実績データを受領して朝食ビュッフェにおける各品目の消費量の予測を試みました。予測には、時系列基盤モデル Chronos-2 を利用しました。
Chronos-2とは
Chronos‑2 は、Amazon Science により開発された時系列基盤モデル(Time Series Foundation Model)です。大規模言語モデル(LLM)と同様に、膨大な時系列データで事前学習されており、個別データごとに学習モデルを構築・チューニングすることなく、過去データ(コンテキスト)を入力するだけで予測を実行できる(Zero‑shot forecasting)点が大きな特徴です。
Chronos-Bolt、Chronos も存在しますが、一番の大きな違いは、Chronos-2 では、複数系列・共変量・カテゴリ情報まで扱える「Universal Forecasting」モデルである点です。
今回 PoC で使用するモデルとして Chronos-2 を選定した理由は以下の通りです。
- 多変量予測:多品目 × 短期間データでも予測が可能
- 商品ごとにモデルを作り直す必要がなく、「クロワッサン・バターロール・ゆでたまご」といった複数品目を同一アプローチで扱える。
- 共変量付き予測:ターゲット(使用量)・日時情報に加えて、曜日・客数・朝食券配布数などの任意の共変量を入力として扱うことが可能
- 実績データに加え、業務的に意味のある指標を特徴量として投入することで精度向上が見込める
- ゼロショット予測:学習・再学習が不要なため、PoCから運用検討までが非常に短い
- モデル構築にコストをかけず、業務データを手軽に試すことができる
上記よりホテルの朝食ビュッフェのように「日次・多品目・需要振れが大きい」業務データに適した時系列予測モデルであると判断し、採用しました。
実行環境と検証アプローチ
今回の精度検証では、データ加工・可視化・分析を反復的に行う必要があったため、Amazon SageMaker AI の Notebook インスタンスを実行基盤として採用しました。Notebook 上では Python 環境を用い、前処理・予測・評価までを一貫して実施しています。
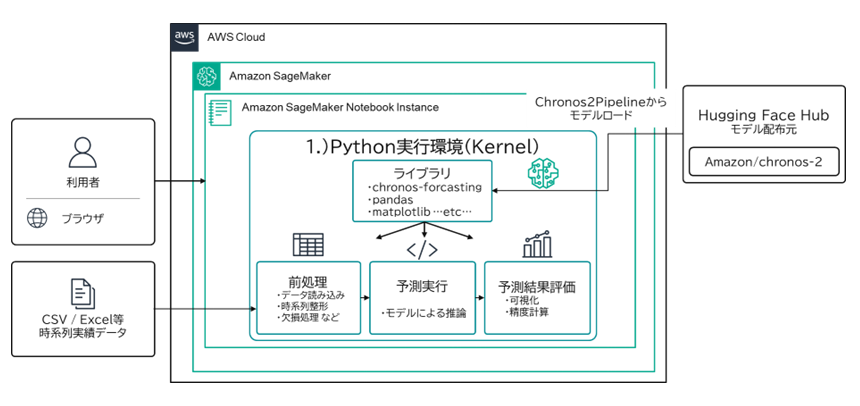
図1:Chronos-2の検証用実行環境
具体的には、CSV や Excel といった時系列データを取り込み、欠損補完や時系列整形などの前処理を行った上で、Chronos-2 を用いた予測処理を実行し、結果の可視化および精度評価を行いました。この一連の流れにより、モデルの挙動やデータ特性を対話的に確認しながら、仮説検証を高速に回すことが可能となります。
Chronos-2 は以下のようにライブラリをインストールすることで簡単に利用できます。
!pip install -U 'chronos-forecasting==2.2.0'
# 予測の実行
import pandas as pd
from chronos import BaseChronosPipeline
from chronos import Chronos2Pipeline
pipeline = Chronos2Pipeline.from_pretrained(
"amazon/chronos-2",
device_map="cpu“,
)
test_df = test_df.drop(columns=["使用量"])
predict_df = pipeline.predict_df(
train_df, #コンテキストとなるデータ
future_df=test_df, # 予測対象のデータ
prediction_length=30, # 予測期間
quantile_levels=[0.1, 0.5, 0.9], # 確率的予測のための分位点(Quantiles)
id_column="item", # 異なる系列を表すカラム(カテゴリカラムなど)
timestamp_column="date", # 時系列情報を表すカラム
target="target", # 予測対象となる時系列の値を格納するカラム(複数可)
)PoCから実運用への展開
一方で、Notebook インスタンス上での実行は、PoCや探索的分析には適しているものの、定常的な業務オペレーションとしての運用には必ずしも最適とは言えません。たとえば、定期実行やシステム連携、スケーラビリティといった観点ではより本番環境に適した構成が求められます。
そのため実運用においては、Amazon SageMaker JumpStart を活用して Chronos-2 モデルを推論エンドポイントとしてデプロイする構成も有効です。これにより、PoC で検証した予測ロジックを業務プロセスへも容易に組み込むことができます。
PoC実施結果
本 PoC では、ご協力いただいたホテル様よりご提供いただいた過去約 3 年分の日次実績データを活用し、朝食ビュッフェにおける主要 3 品目(クロワッサン、バターロール、ゆでたまご)を対象として検証を実施しました。
本検証の特徴として、単に 1 回の予測を行うのではなく、精度がどの要素によって改善されるのかを確認するため、段階的なアプローチを採用し、以下の 3 ステップで検証を進めました。
Step1:最小構成によるベースライン予測
まず最もシンプルな構成として、以下の最小限のデータのみを用いて予測モデルを構築します。
- 日付
- 品名
- 使用量(ターゲット)
このステップでは、モデルの性能評価に先立ち特に重要となる「時系列データの整備」を重点的に行いました。
Chronos‑2 では、入力データが一定間隔の時系列として整っていることが前提条件となるため、以下の前処理を行い分析に適したデータセットを整備しました。
- 品目ごとのデータにおける日付の欠損確認
- 損日付に対する補完レコードの追加
結果
このベースラインモデルの結果は以下の通りです。
| MAPE | MAE | 80%区間被覆率(※2) |
| 約56.6% | 約13.4 | 約68.9% |
(※2) 80%区間被覆率とは予測された「80%の確率でこの範囲に収まる」とされる区間に、実測値がどれだけ含まれているかを示す指標
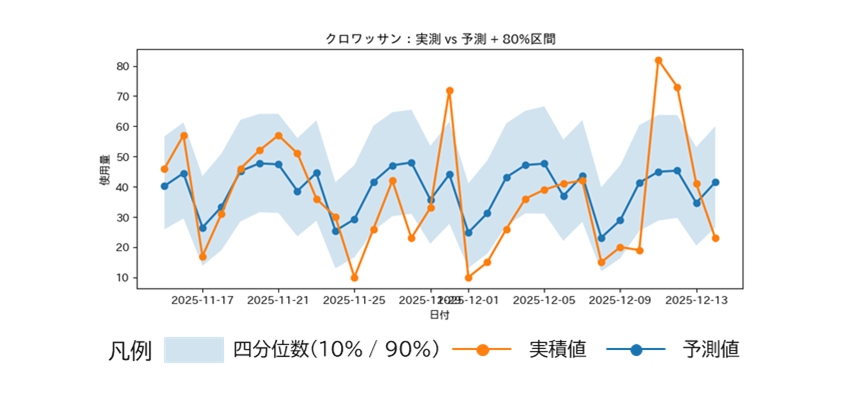
図2:ベースライン予測結果(予測 対 実測)
数値変動の大まかな傾向は捉えられているものの、以下 3 点の実業務における重要な要因を考慮できておらず、 業務で活用するには精度が不十分であることが確認されました。
- 平日と週末の需要差
- 宿泊客数による需要変動
- 直近の消費傾向
Step2:業務データを考慮した予測モデル
次に、実際のホテル業務において使用量を判断する際に利用されている情報を特徴量として追加し予測を行いました。追加したデータは以下の通りです。
- 前日宿泊者数
- 朝食券配布枚数
これらの項目は、単なる補助情報ではなく現場において「今日は宿泊者が多いから多めに作る」といった意思決定に直接使用されている重要な指標です。
また、特徴量の選定にあたって以下の観点で絞り込みを行いました。
- 使用量との相関確認
- 予測時点で取得可能なデータのみを利用(リーケージ防止)
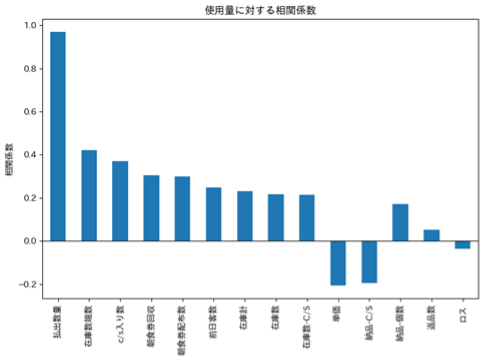
図3:使用量に対する各特徴量の相関係数
結果
| MAPE | MAE | 80%区間被覆率 |
| 約28.3% | 約7.1 | 約78.9% |
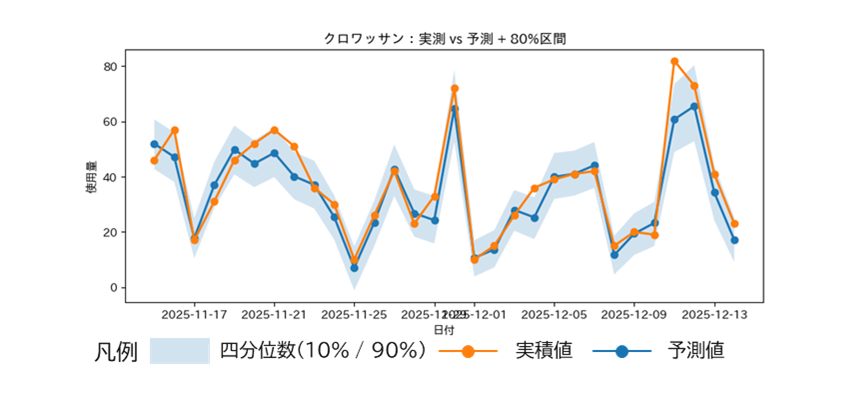
図4:重要指標を特徴量へ追加後の予測結果(予測 対 実測)
ベースラインと比較して、誤差は約50%改善し、以下が適切に反映されるようになりました。
- 平日/週末の傾向
- 来客規模の影響
この結果から、業務知識に基づく特徴量の追加が予測精度に大きく寄与することが明確に確認することができました。
Step3:ラグ特徴量による最終的な精度向上
さらに精度向上を図るため、時系列データ特有のパターンである「連続性」と「周期性」をモデルに取り込むことを目的として、ラグ特徴量を追加しました。
本PoCでは、ラグ特徴量の追加を感覚的に行うのではなく、事前に以下の分析を行いました。
- 自己相関分析
- 偏自己相関分析
- 曜日単位の周期性の確認
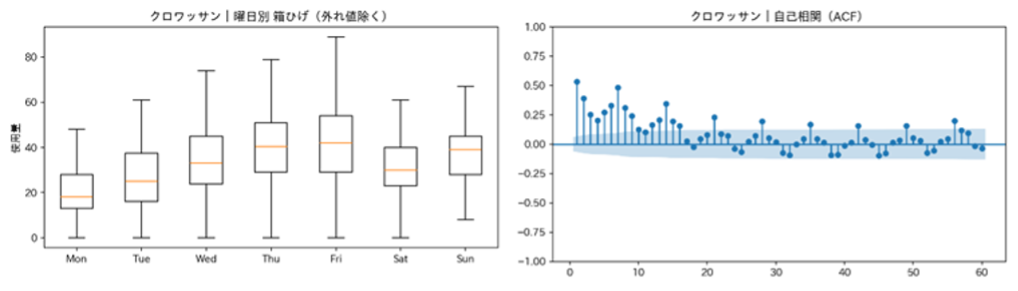
図5:曜日周期性の確認と自己相関
この結果から、以下のような「連続性」と「周期性」を確認することができました。
- 「前日の影響を受ける(連続性)」
- 「1週間単位で繰り返される(曜日周期)」
朝食ビュッフェの需要特性を踏まえた上で、下記の特徴量を追加して予測を行いました。
- 使用量_lag1(前日の使用量)
- 使用量_lag7(1週間前の使用量)
結果
最終モデルの結果は以下の通りです。
| MAPE | MAE | 80%区間被覆率 |
| 約20.3% | 約5.05 | 約82.2% |
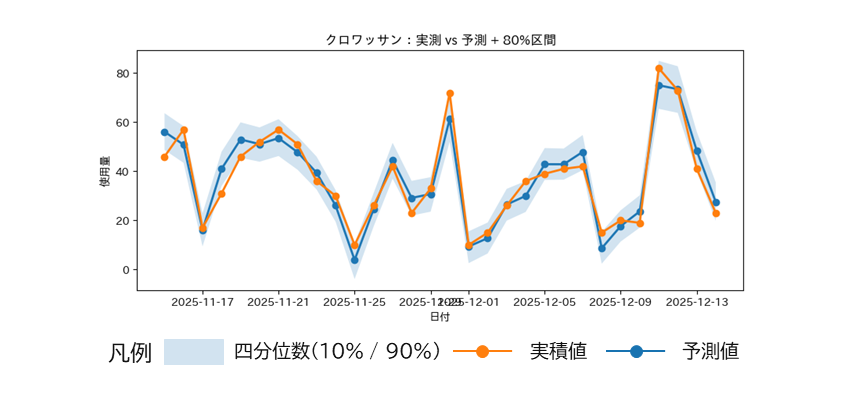
図6:ラグ特徴量追加後の予測結果(予測 対 実測)
この結果から、予測精度のさらなる向上と予測の信頼性(区間被覆率)の改善実運用への適用が十分に検討可能な水準に到達することが確認できました。また、グラフ上でも、週末の需要ピークや品目ごとの変動特性が再現されており、モデルが単なる数値補間ではなく、需要構造そのものを捉えることができました。
技術的なポイント
Chronos-2 における時系列カラムの注意点
Chronos‑2 を利用した時系列予測では、コンテキストとして入力されるデータが「一定間隔の時系列として整備されていること」が前提条件となります。例えば、日次データであれば、時系列カラム×種類カラム(今回の場合は、日付×品目)において、すべての日付が抜け漏れなく並んでいる必要があります。また、予測は、各種類カラムの最終日付から指定した日付分の予測が行われる点にも注意が必要です。
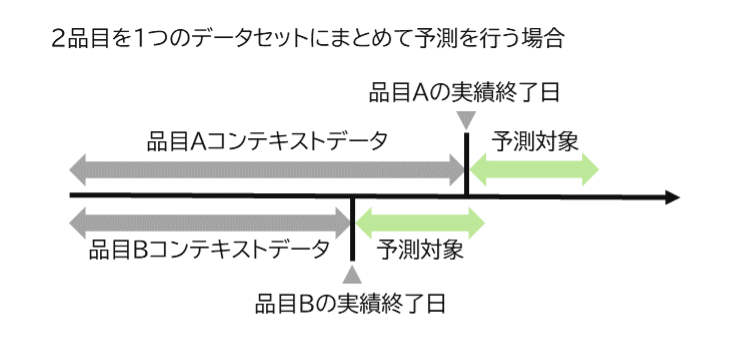
図7:異なる期間のデータを用いた場合の予測対象期間
実運用データでは、非営業日や記録漏れなどにより日付が欠損しているというケースも少なくありませんが、そのまま Chronos-2 に投入すると時系列として正しく解釈されず、エラーが発生する可能性が高いため注意が必要です。

図8:データ抜け日の確認と欠損補完イメージ
このため、本 PoC では品目ごとに日付の連続性を確認し、欠損している日については 補完レコード(使用量 0 または NULL)を追加する前処理を行っています。Chronos‑2 を活用する際は、モデル以前に「時系列を等間隔に整えるデータ整備」もポイントになります。
リーケージを防ぐ設計
時系列予測や機械学習において注意すべき点のひとつがリーケージ(データリーケージ)です。リーケージとは、予測時点では本来入手できない未来の情報を、誤って特徴量として使用してしまうことを指します。
リーケージが発生すると、一見すると非常に高い予測精度が出るが、実際の業務運用では同じデータが取得できないため、検証時の精度が再現できないモデルになってしまうため注意が必要です。
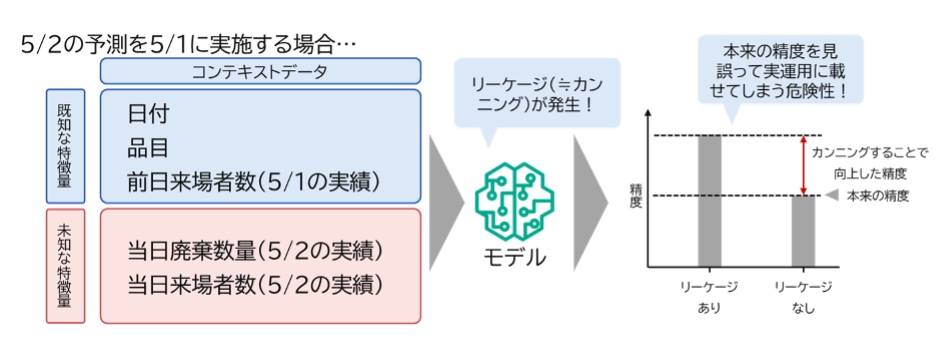
図9:リーケージの危険性
本 PoC では、「前日終業時点で翌日の朝食使用量を予測する」という業務シナリオを前提とし、前日宿泊者数や朝食券配布枚数など、予測時点で確実に取得可能な情報のみを特徴量として使用しました。機械学習モデリングでも同様ですが、Chronos‑2 を業務に適用する際には、「その情報はいつ取得できるのか?」を意識し、リーケージを防ぐ設計が不可欠です。
ラグ特徴量の有効性
時系列予測では、過去の値が将来の値に影響するという特性をモデルに取り込むため、過去の値をずらして特徴量として使用する「lag 特徴量」がよく用いられます。lag 特徴量を追加することで、直前の傾向(連続性)や、曜日などによる周期的なパターンを表現することができます。
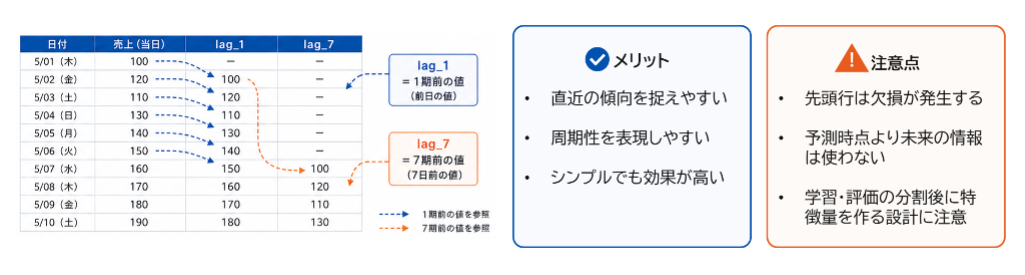
図10:ラグ特徴量のメリットと注意点
本 PoC では、自己相関の結果に基づき、lag1:前日の使用量、lag7:7日前(同じ曜日)の使用量を特徴量として追加しました。
これにより今回の検証では、短期的な増減や曜日単位の周期性を捉えやすくなり予測精度が向上しました。
一方で、lag 特徴量は設定次第でリーケージにつながる可能性があるため、「いつ予測を行うのか」という業務前提を明確にした上で、実運用で取得可能な範囲の lag のみを採用することもが重要になります。
Chronos-2 に関する考察
- 機械学習モデルの予測精度向上施策を打つことで、Chronos-2 でも同様に予測結果が向上させることが可能
- 機械学習モデリングの時と同様にコンテキストに含めるデータ項目が多いとより精度向上施策に幅がでて、精度改善に寄与することができる可能性が広がる
- FineTuningやクロースラーニングなどさらなる精度向上施策を手軽に試せる点も非常に使い勝手が良い
本検証の総括
今回の取り組みを通じ、ホテル業界におけるフードロスは「やむを得ないもの」ではなく、データ活用により削減可能であることを実感しました。現在の、食数予測においてはホテル従業員の経験や勘に依存する部分も多く、その結果として過剰な仕込みやロスが発生しやすい傾向にありましたが、今回の Chronos-2 による需要予測を用いることで需要変動の傾向が可視化され、ロス削減の余地があることが分かりました。
一方で、予測の結果だけですべてが解決するわけではありません。実際の現場では、お客さまへの満足度を考慮してある程度の余剰を持たせる運用が不可欠です。そのため、単に予測結果を提供するのではなく、「予測結果をどう使うか」「どこまでなら調整が出来るか」といった現場に寄り添った運用面もあわせて合わせて考えることが重要です。
今後は、予約状況やイベントなどの外部情報も取り入れながら精度を高めるとともに、予測結果を発注業務などに連携させる仕組みを作ることがより一層重要になると考えます。引き続き、現場に寄り添いながら、ホテル業界全体のフードロス削減に貢献できるよう取り組んで参ります。
まとめと今後の展望
今回の取り組みでは、Amazon Science が発表した時系列基盤モデル Chronos-2 が、ホテルの朝食ビュッフェという「日次・多品目・需要変動が大きい」業務領域において有効に機能することを検証しました。学習不要で即座に予測を開始できることに加え、特徴量の工夫により追加学習なしでも本番業務で活用できる精度に達することを実証しました。これにより、PoC から本番運用への移行を短期間かつ低コストで実現する道筋が示されたと考えています。
AWS では、Amazon SageMaker AI をはじめとする AI/ML サービスを通じて、Chronos-2 のような時系列基盤モデルを本番環境でスケーラブルに運用するための基盤を提供しています。本ブログで紹介した需要予測のアプローチは、ホテル業界に限らず、外食・流通小売・食品製造など、フードロスが課題となる幅広い業種への適用が期待されます。また、こうした需要予測での発生抑制に閉じるのではなく、スマート廃棄物管理など多面的なアプローチがフードロス削減を目指す上では不可欠です。
Amazon は、The Climate Pledge を通じて2040年までにネットゼロカーボンを達成することをコミットしており、AWS はその実現に向けて、エネルギー効率に優れたクラウドインフラストラクチャの提供、カーボンフリーエネルギーへの移行推進、そしてお客様のワークロード最適化による環境負荷低減の支援を行っています。本ブログでご紹介した需要予測によるフードロス削減も、テクノロジーを活用した持続可能性への貢献の一つです。同様の取り組みを検討されている皆さまの一助となれば幸いです。
執筆者
  |
キヤノンITソリューションズ株式会社ホテル業界向けのシステム開発を30年以上手掛けています (左から) 大原 諭 (Satoshi Ohara)流通業界・サービス業界向けおよびデータマネジメントソリューションのマーケティング・企画担当 大竹 智礼 (Tomonori Otake)データマネジメント領域におけるデータサイエンティストとして、主に流通業界向けのデータ分析、
辻 夏子(Natsuko Tsuji)ホテル業界向けソリューションのマーケティング・商品企画担当。本取り組みの推進リーダー |
  |
戸塚 智哉(Tomoya Tozuka) /@tottu22飲食やフィットネス、ホテル業界全般のお客様をご支援しているソリューションアーキテクトで、AI/ML、IoT を得意としています。最近ではAWSを活用したサステナビリティについてお客様に訴求することが多いです。
|
  |
大久保 裕太 (Yuta Okubo)外食業界や飲料メーカーのお客様を支援しているソリューションア―キテクトです。好きなAWSサービスは AWS IoT Core。
|
  |
寺山 怜志 (Satoshi Terayama)外食業界や百貨店業界のお客様を支援しているソリューションア―キテクトです。
|