Amazon Web Services 한국 블로그
Amazon DataZone 정식 출시 – 기업 내부 팀간 데이터 프로젝트 공동 작업
오늘 AWS는 조직의 데이터 생산자와 소비자 간에 데이터를 분류, 검색, 분석, 공유 및 관리하는 새로운 데이터 관리 서비스인 Amazon DataZone의 정식 출시를 발표합니다.
 AWS re:Invent 2022에서는 Amazon DataZone을 사전 발표했고, 2023년 3월에는 공개 평가판 이용 기간을 가졌었습니다.
AWS re:Invent 2022에서는 Amazon DataZone을 사전 발표했고, 2023년 3월에는 공개 평가판 이용 기간을 가졌었습니다.
지난 re:Invent의 기조 연설에서 AWS의 Databases, Analytics, and Machine Learning VP인 Swami Sivasubramanian은 “저는 판매 파이프라인 및 수익 예측에서 얻은 데이터를 수집하여 비즈니스 전략을 수립하는 AWS 주간 비즈니스 검토 회의를 운영하는 등 DataZone 초기 고객으로서의 이점을 누렸습니다.”라고 말했습니다.
기조 연설 중에 Amazon DataZone Head of Product인 Shikha Verma는 데모를 주도하며 조직에서 이 제품을 사용하여 보다 효과적인 광고 캠페인을 만들고 데이터를 최대한 활용할 수 있는 방법을 시연했습니다.
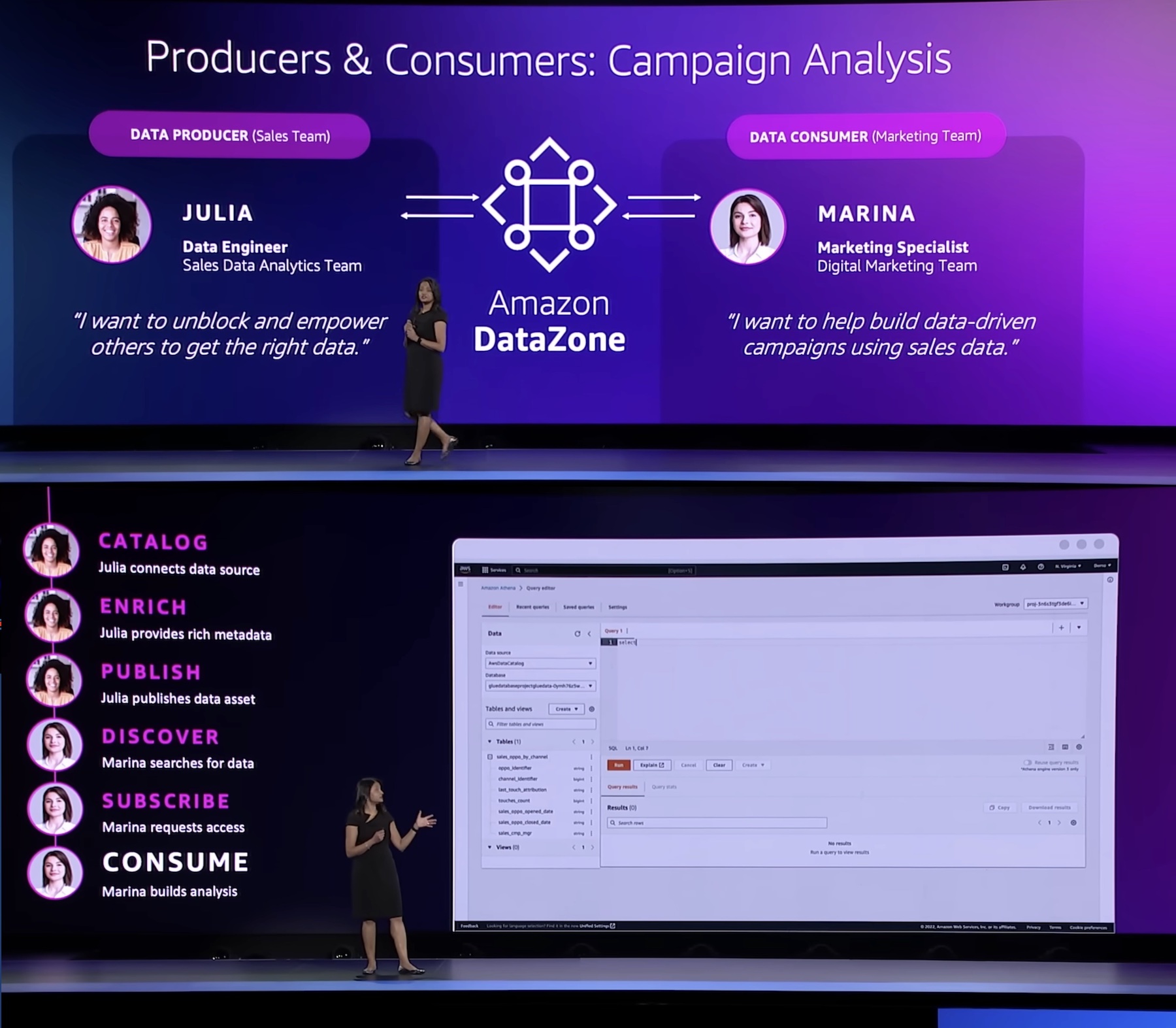
“모든 기업은 다양한 데이터 저장소에서 데이터를 소유하고 사용하는 여러 팀으로 구성되어 있습니다. 데이터 사용자는 이러한 데이터를 함께 가져와야 하지만 데이터에 쉽게 액세스할 수 있는 방법이 없거나 해당 데이터에 대한 가시성도 없습니다. DataZone은 데이터 생산자부터 소비자에 이르기까지 조직의 모든 사람이 관리형 방식으로 데이터에 액세스하고 공유할 수 있는 통합 환경을 제공합니다.”
Amazon DataZone을 통해 데이터 생산자는 데이터 카탈로그에 AWS Glue 데이터 카탈로그 및 Amazon Redshift 테이블의 정형 데이터 자산을 입력합니다. 데이터 소비자는 데이터 카탈로그의 데이터 자산을 검색 및 구독하고 다른 비즈니스 사용 사례 공동 작업자와 공유합니다. 소비자는 Amazon DataZone 포털에서 직접 액세스할 수 있는 Amazon Redshift 또는 Amazon Athena 쿼리 편집기와 같은 도구를 사용하여 구독한 데이터 자산을 분석할 수 있습니다. 통합 게시 및 구독 워크플로는 프로젝트 전반에 걸쳐 액세스 감사 기능을 제공합니다.
Amazon DataZone 소개
아직 Amazon DataZone에 익숙하지 않은 사용자를 위해 주요 개념과 기능을 소개하겠습니다.
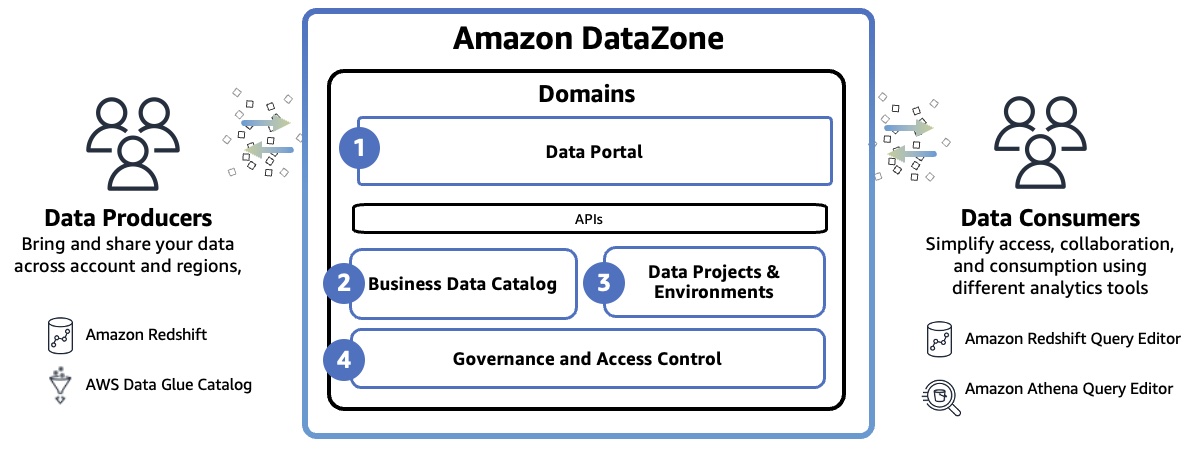
Amazon DataZone 도메인은 자체 데이터 자산, 자체 데이터 정의 또는 비즈니스 용어를 포함하여 자체 데이터를 관리할 수 있고 자체 관리 표준을 가질 수 있는 조직 내 LOB(기간 업무) 또는 비즈니스 영역의 뚜렷한 경계를 나타냅니다. 도메인에는 데이터 포털, 비즈니스 데이터 카탈로그, 프로젝트 및 환경, 기본 제공 워크플로와 같은 모든 핵심 구성 요소가 포함됩니다.
- 데이터 포털(AWS Management Console 외부) – 다양한 사용자가 셀프 서비스 방식으로 데이터를 카탈로그화, 검색, 관리, 공유 및 분석할 수 있는 웹 애플리케이션입니다. 데이터 포털은 AWS IAM Identity Center를 사용하여 AWS Identity and Access Manager(IAM) 보안 인증 또는 ID 공급자의 기존 보안 인증으로 사용자를 인증합니다.
- 비즈니스 데이터 카탈로그 – 카탈로그에서 분류 또는 비즈니스 용어집을 정의할 수 있습니다. 이 구성 요소를 사용하여 비즈니스 컨텍스트와 함께 조직 전체의 데이터를 카탈로그화하면 조직의 모든 사람이 데이터를 빠르게 찾고 이해할 수 있습니다.
- 데이터 프로젝트 및 환경 – 프로젝트를 사용하여 사람, 데이터 자산 및 분석 도구를 비즈니스 사용 사례별로 그룹화으로써 AWS 분석에 대한 액세스를 간소화할 수 있습니다. Amazon DataZone 프로젝트는 프로젝트 구성원이 협업하고, 데이터를 교환하고, 데이터 자산을 공유할 수 있는 공간을 제공합니다. 프로젝트 구성원이 쉽게 새 데이터를 생성하거나 액세스 권한이 있는 데이터를 사용할 수 있도록 분석 도구 및 스토리지와 같은 필요한 인프라를 프로젝트 구성원에게 제공하는 환경을 프로젝트 내에서 만들 수 있습니다.
- 거버넌스 및 액세스 제어 – 조직 내 사용자가 카탈로그의 데이터에 대한 액세스를 요청하고 데이터 소유자가 해당 구독 요청을 검토 및 승인할 수 있는 기본 제공 워크플로를 사용할 수 있습니다. 구독 요청이 승인되면 Amazon DataZone은 AWS Lake Formation 및 Amazon Redshift와 같은 기본 데이터 저장소에서 권한을 관리하여 액세스 권한을 자동으로 부여할 수 있습니다.
자세한 내용은 Amazon DataZone 용어 및 개념을 참조하세요.
Amazon DataZone 시작하기
시작하려면 제품 마케팅 팀이 캠페인을 실행하여 제품 채택을 유도하고자 하는 시나리오를 생각해 봐야 합니다. 이를 위해 마케팅 팀은 영업 팀이 소유한 제품 판매 데이터를 분석해야 합니다. 이 단계별 안내에서는 데이터 생산자 역할을 하는 영업 팀이 Amazon DataZone에 판매 데이터를 게시합니다. 그런 다음 데이터 소비자 역할을 하는 마케팅 팀이 판매 데이터를 구독하고 분석하여 캠페인 전략을 수립합니다.
DataZone의 작동 방식을 이해하기 위해 Amazon DataZone용 시작 안내서의 요약 버전을 살펴보겠습니다.
1. 도메인 생성
DataZone을 처음 사용하기 시작할 때는 먼저 도메인을 만듭니다. 그렇게 하면 데이터 포털의 비즈니스 데이터 카탈로그, 프로젝트, 환경과 같은 모든 핵심 구성 요소가 해당 도메인 내에 존재하게 됩니다. Amazon DataZone 콘솔로 이동하여 도메인 생성을 선택합니다.
도메인 이름과 설명을 입력하고 다른 모든 값은 기본값으로 둡니다.
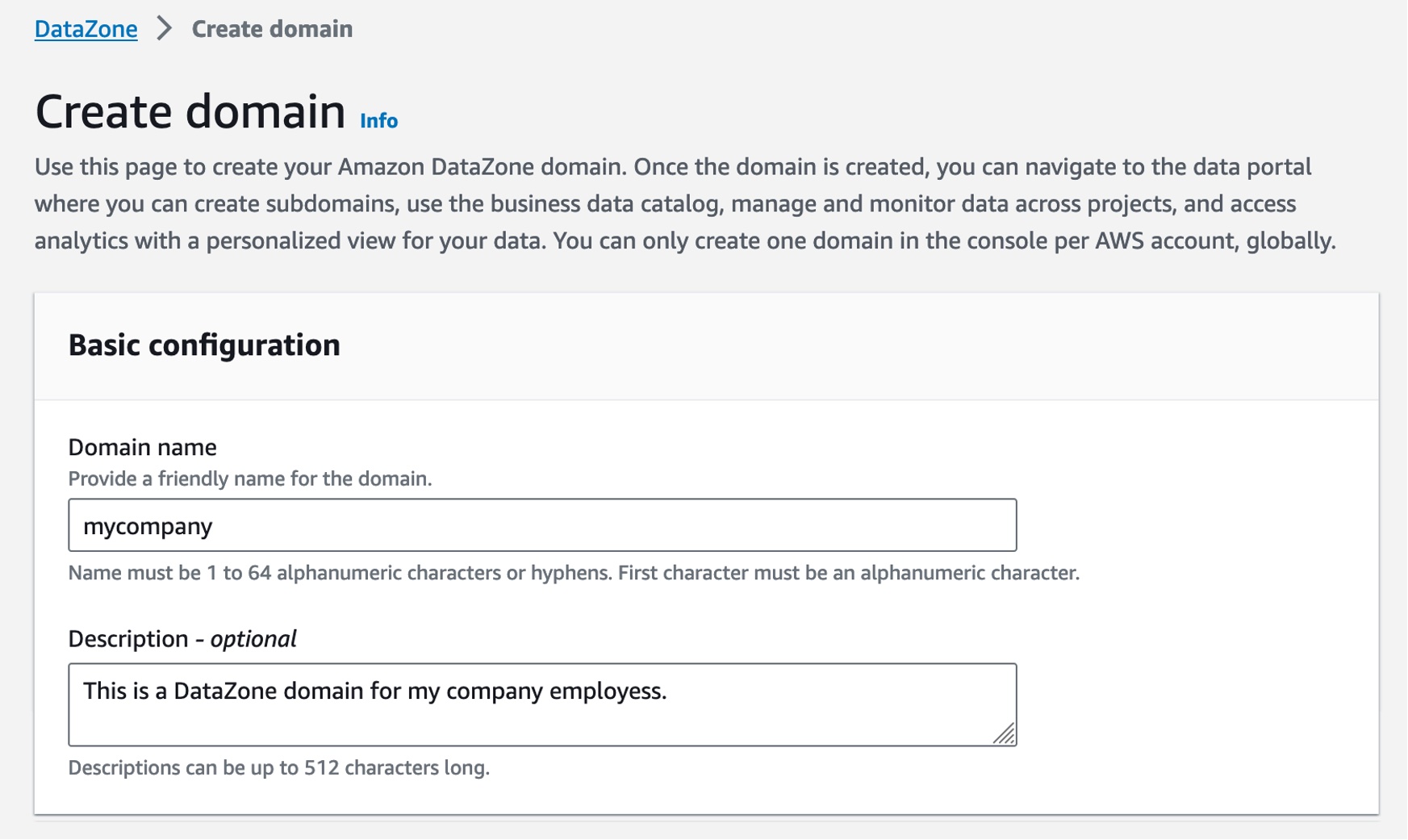
예를 들어 서비스 액세스 섹션에서 기본적으로 새 역할 생성 및 사용을 선택하면 Amazon DataZone이 도메인 내 사용자를 대신하여 API 호출을 수행할 수 있는 필수 권한을 가진 새 역할을 자동으로 생성합니다. DataZone이 모든 설정 단계를 처리할 수 있는 빠른 설정 옵션을 선택합니다.
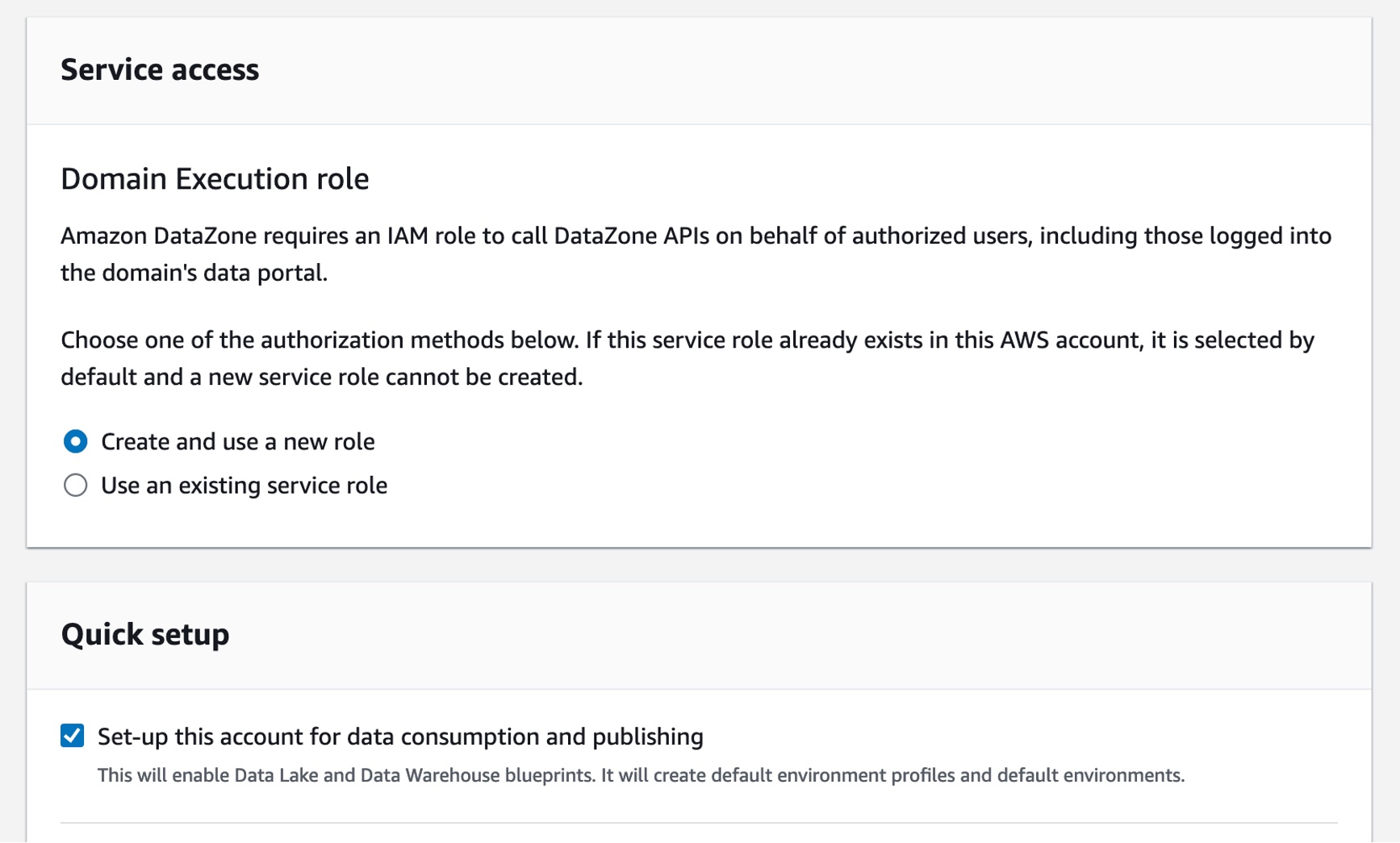
마지막으로 엔드포인트 생성을 선택합니다. Amazon DataZone은 필요한 IAM 역할을 생성하고, 이 도메인이 계정 내에서 AWS Glue 데이터 카탈로그, Amazon Redshift 및 Amazon Athena와 같은 리소스를 사용할 수 있도록 지원합니다. 도메인 생성을 완료하는 데 몇 분 정도 걸릴 수 있습니다. 도메인이 사용 가능 상태가 될 때까지 기다립니다.
2. 데이터 포털에서 프로젝트 및 환경 만들기
도메인이 성공적으로 생성되면 도메인을 선택하고 도메인의 요약 페이지에서 루트 도메인의 데이터 포털 URL을 기록해 둡니다. 이 URL을 사용하여 Amazon DataZone 데이터 포털에 액세스할 수 있습니다. 데이터 포털 열기를 선택합니다.
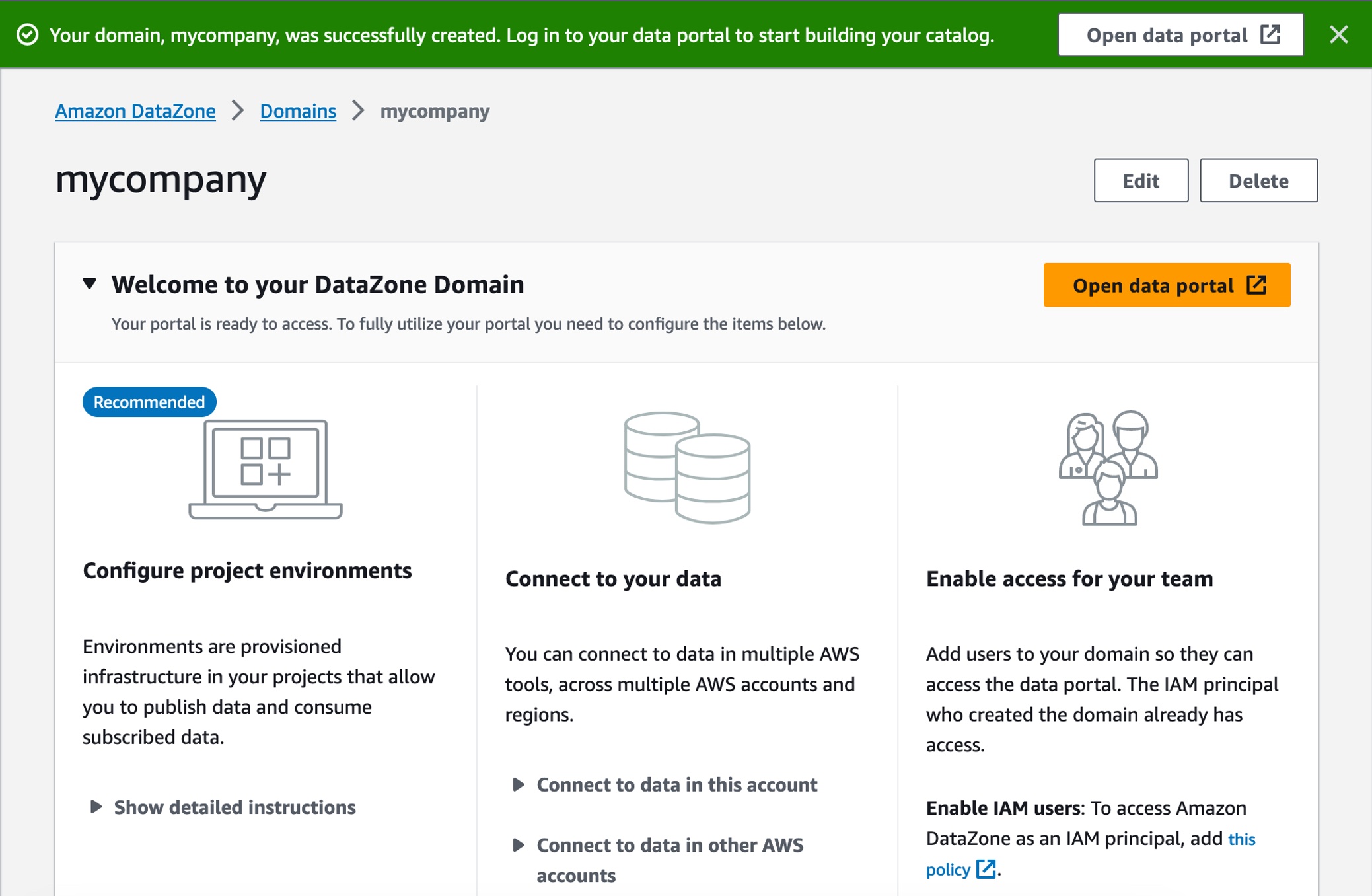
영업 팀이 판매 데이터를 게시하는 것처럼 새 데이터 프로젝트를 만들려면 프로젝트 만들기를 선택합니다.

대화 상자에서 이름에 ‘판매 생산자 프로젝트’를 입력한 다음 이 프로젝트에 대한 설명을 입력하고 만들기를 선택합니다.

프로젝트가 만들어지면 이 프로젝트에서 Amazon Athena 또는 Amazon Redshift와 같은 데이터 및 분석 도구를 사용할 수 있는 환경을 만들어야 합니다. 환경 만들기를 개요 페이지에서 선택하거나 환경 탭을 클릭하여 선택합니다.

이름에 ‘publish-environment’를 입력한 다음 이 환경에 대한 설명을 입력하고 환경 프로필을 선택합니다. 환경 프로필은 프로젝트에 추가되는 AWS 계정, 리전, VPC 세부 정보, 리소스 및 도구와 같은 환경을 만드는 데 필요한 기술 정보가 포함된 사전 정의된 템플릿입니다.
몇 가지 기본 환경 프로필을 선택할 수 있습니다. DataLakeProfile을 선택하면 Amazon S3 및 AWS Glue 기반 데이터 레이크의 데이터를 게시할 수 있습니다. 또한 Amazon Athena를 사용하여 액세스할 수 있는 AWS Glue 테이블을 간단하게 쿼리할 수 있습니다.

그런 다음 모든 선택적 매개변수를 무시하고 환경 만들기를 선택합니다. 환경에서는 IAM 역할, Amazon S3 접미사, AWS Glue 데이터베이스 및 Athena 작업 그룹과 같은 특정 리소스를 AWS 계정에 생성하는 데 1분 정도 소요되므로 프로젝트 구성원이 데이터 레이크에서 데이터를 쉽게 생성하고 사용할 수 있습니다.
3. 데이터 포털에 데이터 게시
환경에서는 AWS Glue 테이블에 데이터를 게시할 수 있습니다. Amazon Athena에서 이 테이블을 생성하려면 환경 페이지 오른쪽에 있는 Athena 링크를 사용하여 데이터 쿼리를 선택합니다.
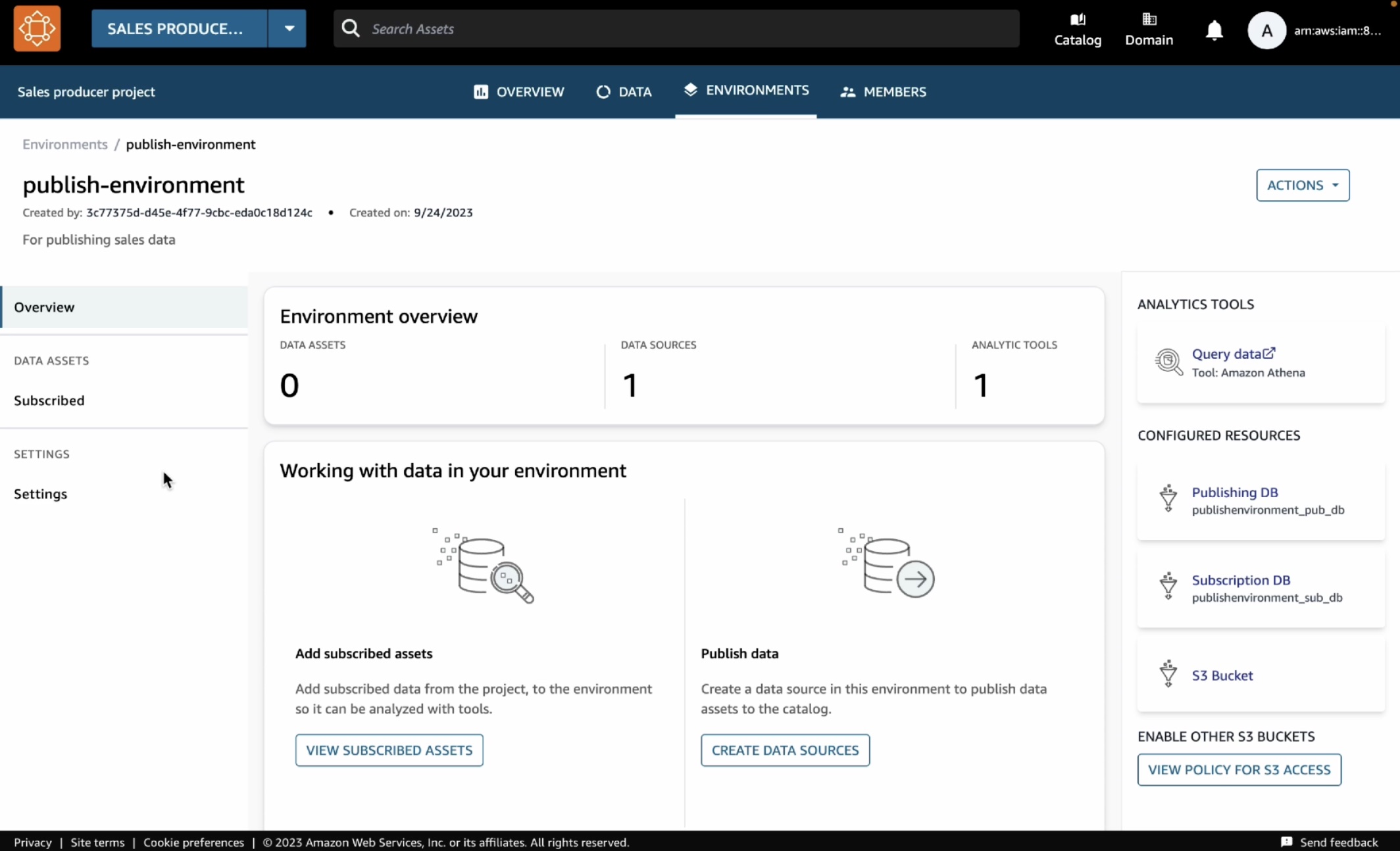
그러면 Athena 쿼리 편집기가 새 탭에서 열립니다. 데이터베이스 드롭다운에서 publishenvironment_pub_db를 선택한 후 다음 쿼리를 쿼리 편집기에 붙여넣습니다. 그러면 환경의 AWS Glue 데이터베이스에 catalog_sales라는 테이블이 생성됩니다.
CREATE TABLE catalog_sales AS
SELECT 146776932 AS order_number, 23 AS quantity, 23.4 AS wholesale_cost, 45.0 as list_price, 43.0 as sales_price, 2.0 as discount, 12 as ship_mode_sk,13 as warehouse_sk, 23 as item_sk, 34 as catalog_page_sk, 232 as ship_customer_sk, 4556 as bill_customer_sk
UNION ALL SELECT 46776931, 24, 24.4, 46, 44, 1, 14, 15, 24, 35, 222, 4551
UNION ALL SELECT 46777394, 42, 43.4, 60, 50, 10, 30, 20, 27, 43, 241, 4565
UNION ALL SELECT 46777831, 33, 40.4, 51, 46, 15, 16, 26, 33, 40, 234, 4563
UNION ALL SELECT 46779160, 29, 26.4, 50, 61, 8, 31, 15, 36, 40, 242, 4562
UNION ALL SELECT 46778595, 43, 28.4, 49, 47, 7, 28, 22, 27, 43, 224, 4555
UNION ALL SELECT 46779482, 34, 33.4, 64, 44, 10, 17, 27, 43, 52, 222, 4556
UNION ALL SELECT 46779650, 39, 37.4, 51, 62, 13, 31, 25, 31, 52, 224, 4551
UNION ALL SELECT 46780524, 33, 40.4, 60, 53, 18, 32, 31, 31, 39, 232, 4563
UNION ALL SELECT 46780634, 39, 35.4, 46, 44, 16, 33, 19, 31, 52, 242, 4557
UNION ALL SELECT 46781887, 24, 30.4, 54, 62, 13, 18, 29, 24, 52, 223, 4561드롭다운 메뉴에서 두 데이터베이스를 볼 수 있습니다. publishenvironment_pub_db는 새 데이터를 생성하고 이를 DataZone 카탈로그에 게시하도록 선택할 수 있는 공간을 제공합니다. publishenvironment_sub_db라는 다른 데이터베이스는 프로젝트 구성원이 해당 프로젝트 내 카탈로그의 데이터를 구독하거나 액세스할 때 사용할 수 있습니다.
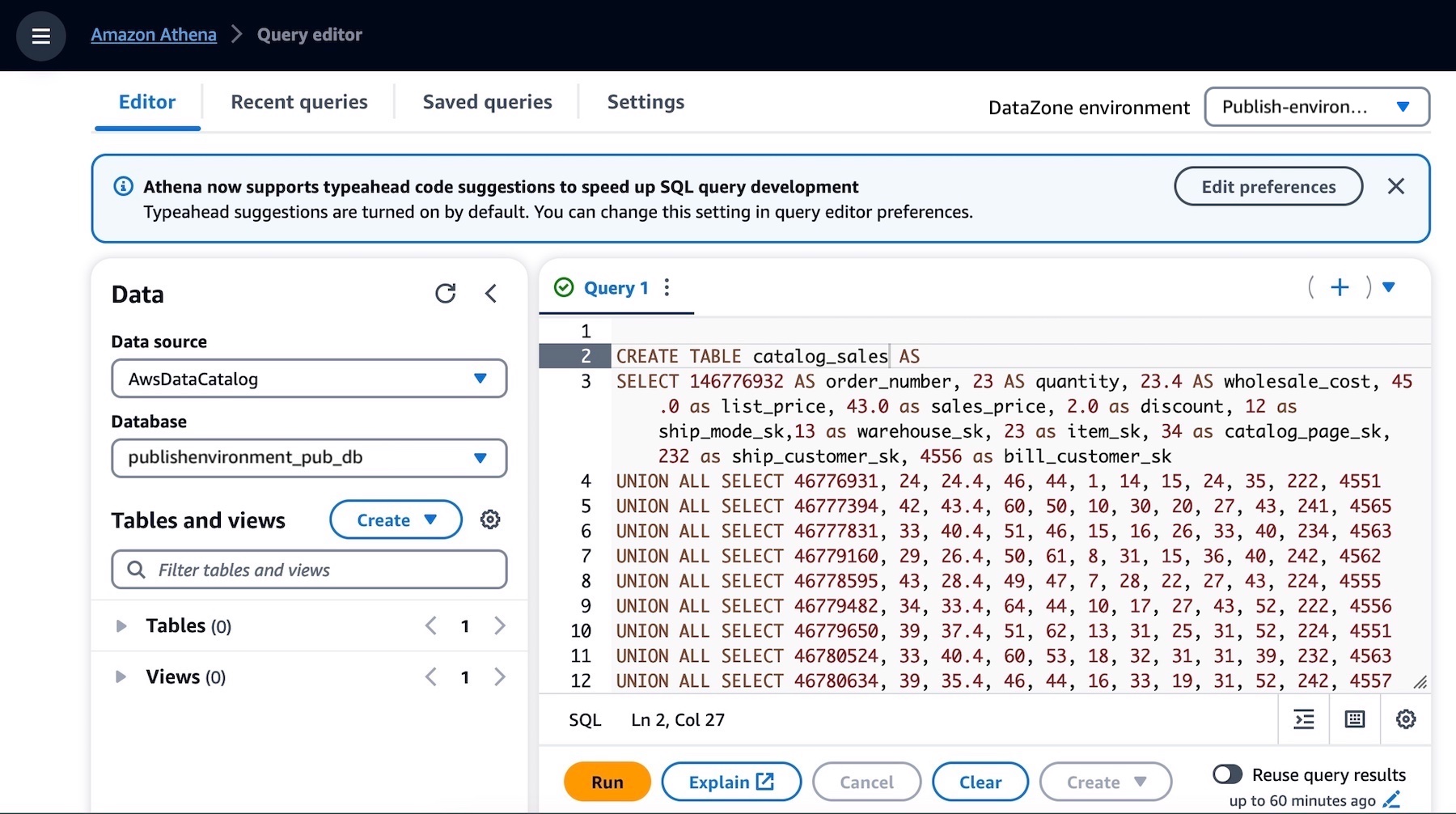
catalog_sales 테이블이 성공적으로 생성되었는지 확인하십시오. 이제 Amazon DataZone 카탈로그에 게시할 수 있는 데이터 자산이 생겼습니다.
이제 데이터 생산자는 데이터 포털로 돌아가서 이 테이블을 DataZone 카탈로그에 게시할 수 있습니다. 상단 메뉴에서 데이터 탭을 선택하고 왼쪽 탐색 창에서 데이터 소스를 선택합니다.
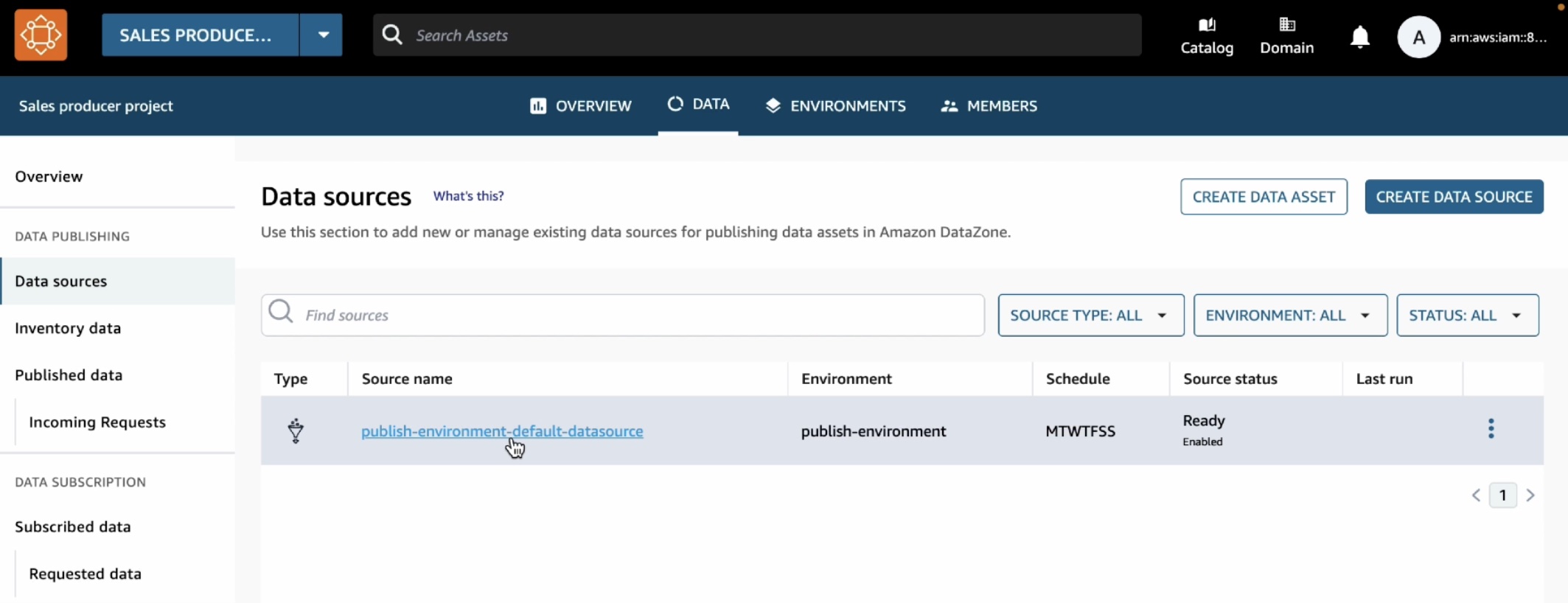
사용자 환경에서 자동으로 생성된 기본 데이터 소스를 볼 수 있습니다. 이 데이터 소스를 열면 방금 catalog_sales 테이블을 만든 사용자 환경의 게시 데이터베이스가 보입니다.
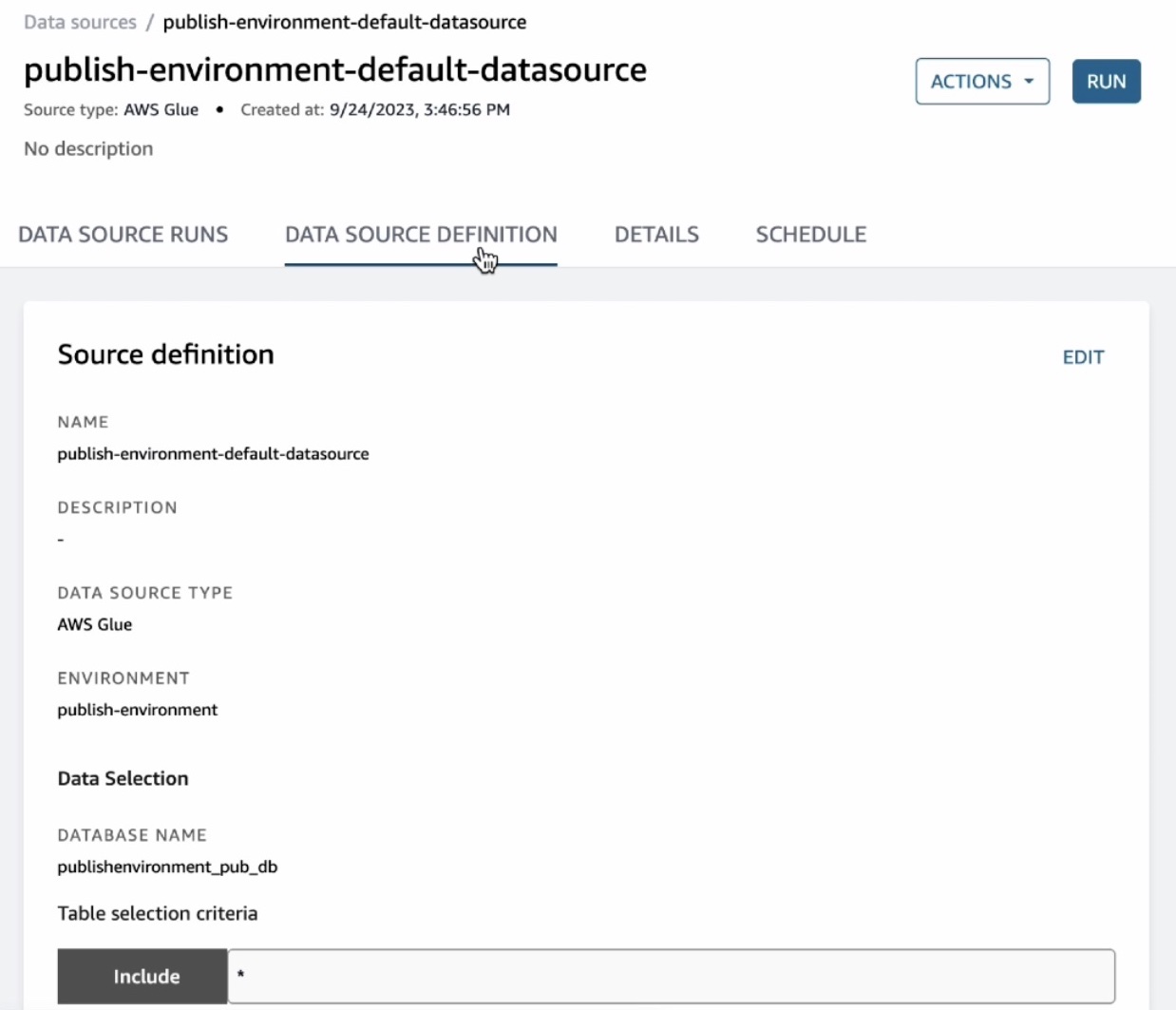
이 데이터 소스는 게시 데이터베이스에서 찾은 모든 테이블을 DataZone으로 가져옵니다. 기본적으로 자동 메타데이터 생성이 활성화되어 있습니다. 따라서 데이터 소스는 DataZone으로 가져오는 모든 자산은 해당 자산에 대한 테이블 및 열의 비즈니스 이름을 자동으로 생성합니다. 이 데이터 소스에서 실행을 선택합니다.
데이터 소스 실행이 완료되면 데이터 소스 실행에서 카탈로그 판매 테이블을 볼 수 있습니다.
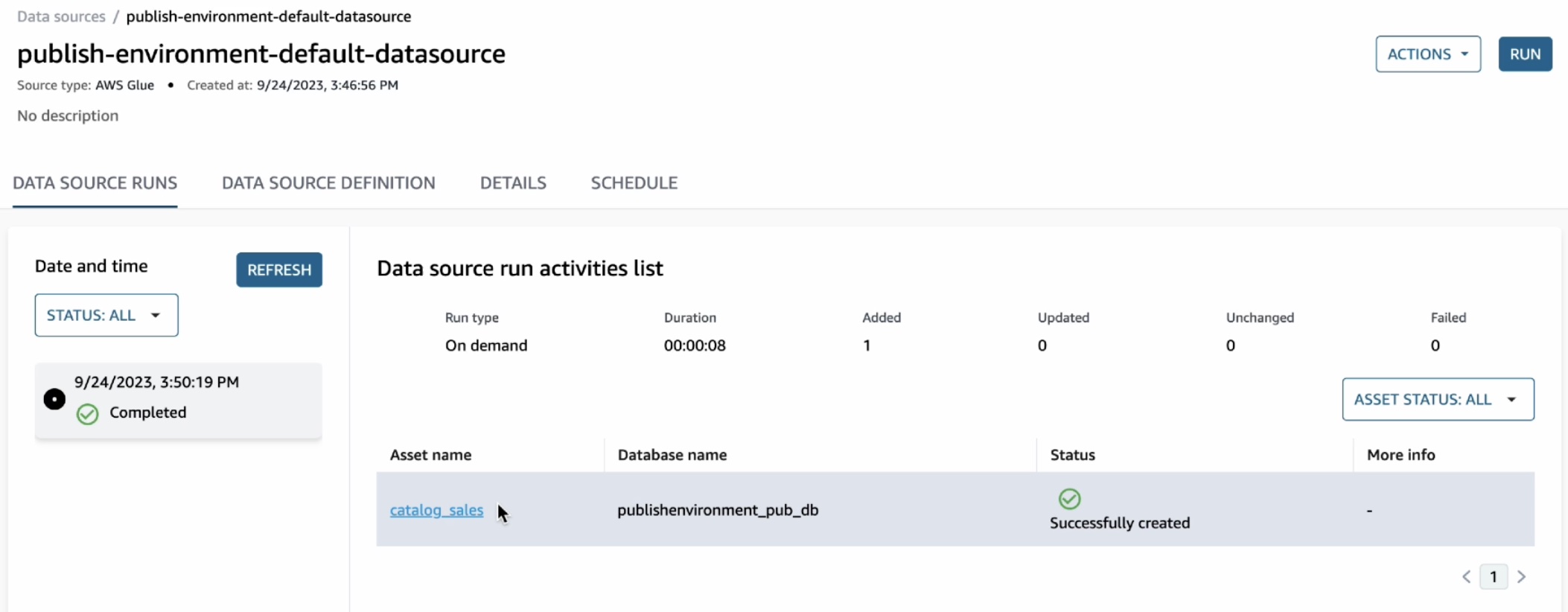
이 자산을 열면 게시 작업을 통해 테이블의 스키마와 AWS 계정, 리전, 데이터의 물리적 위치와 같은 기타 여러 기술 정보가 포함된 기술 메타데이터가 자동으로 추출되는 것을 확인할 수 있습니다.
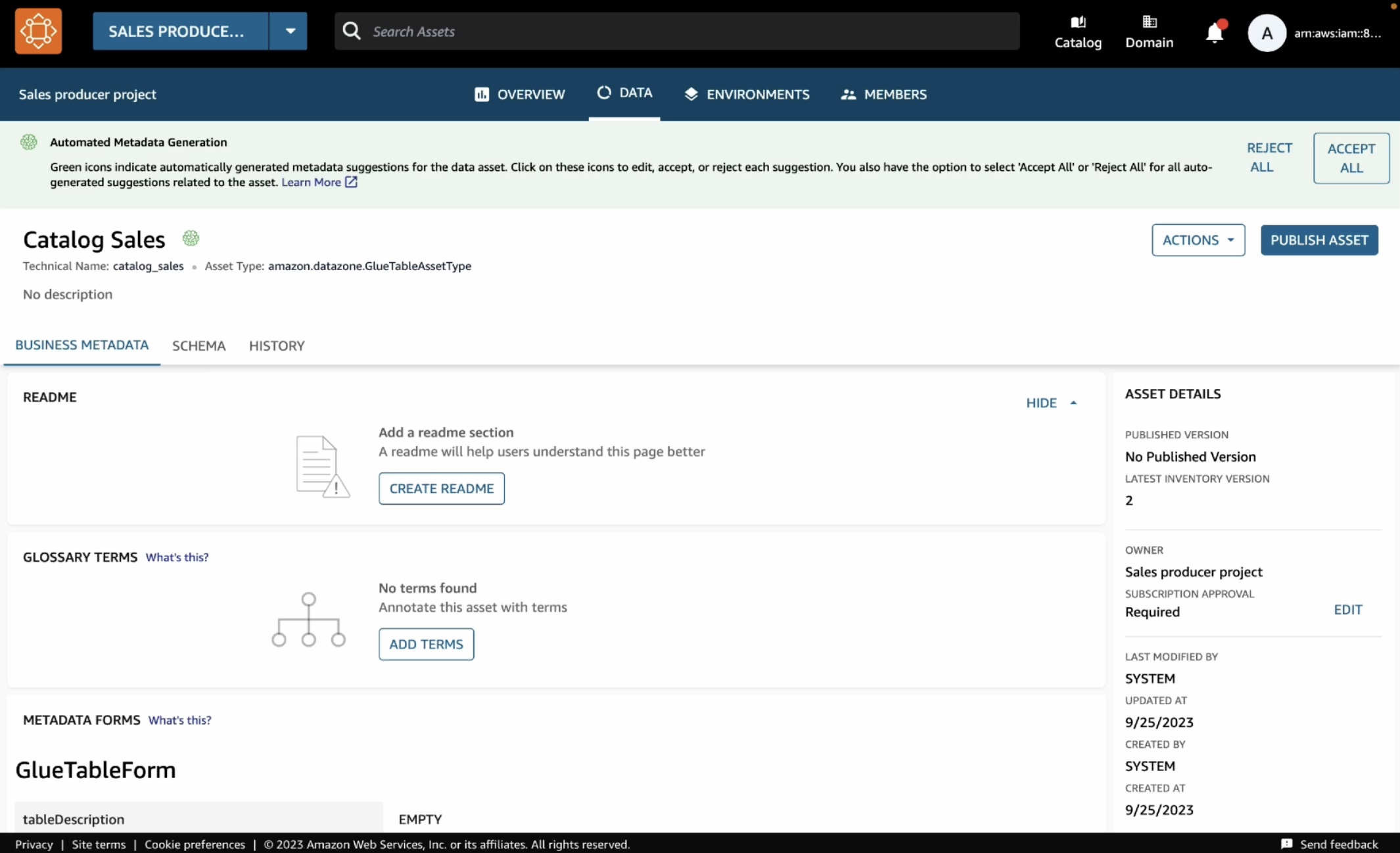
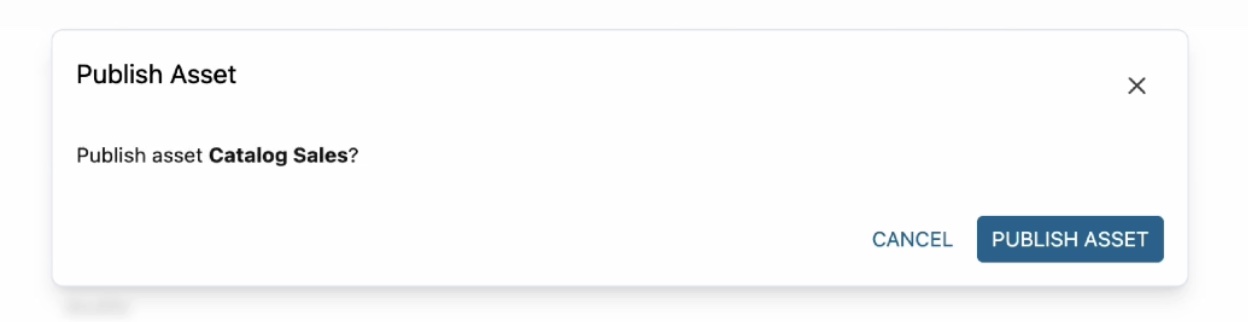
올바로 된 것처럼 보이면 각 권장 항목의 두뇌 아이콘을 클릭하거나 모든 권장 사항의 모두 수락 버튼을 클릭하여 이러한 권장 사항을 수락할 수 있습니다. 게시할 준비가 되면 자산 게시를 선택하고 대화 상자에서 다시 확인합니다.
4. 데이터 소비자로서 데이터 구독하기
이제 마케팅 팀으로 역할을 바꾸어 이 테이블을 구독하거나 이 테이블에 대한 액세스를 요청하는 방법을 살펴보겠습니다. 작업을 반복하여 이전과 동일한 단계를 사용하여 ‘마케팅 소비자 프로젝트’라는 새 프로젝트와 ‘구독자 환경’이라는 새 환경을 데이터 소비자로 생성합니다.
새로 만든 프로젝트에서 검색 창에 ‘카탈로그 판매’를 입력하면 검색 결과에 게시된 테이블을 볼 수 있습니다. 카탈로그 판매 데이터를 선택합니다.
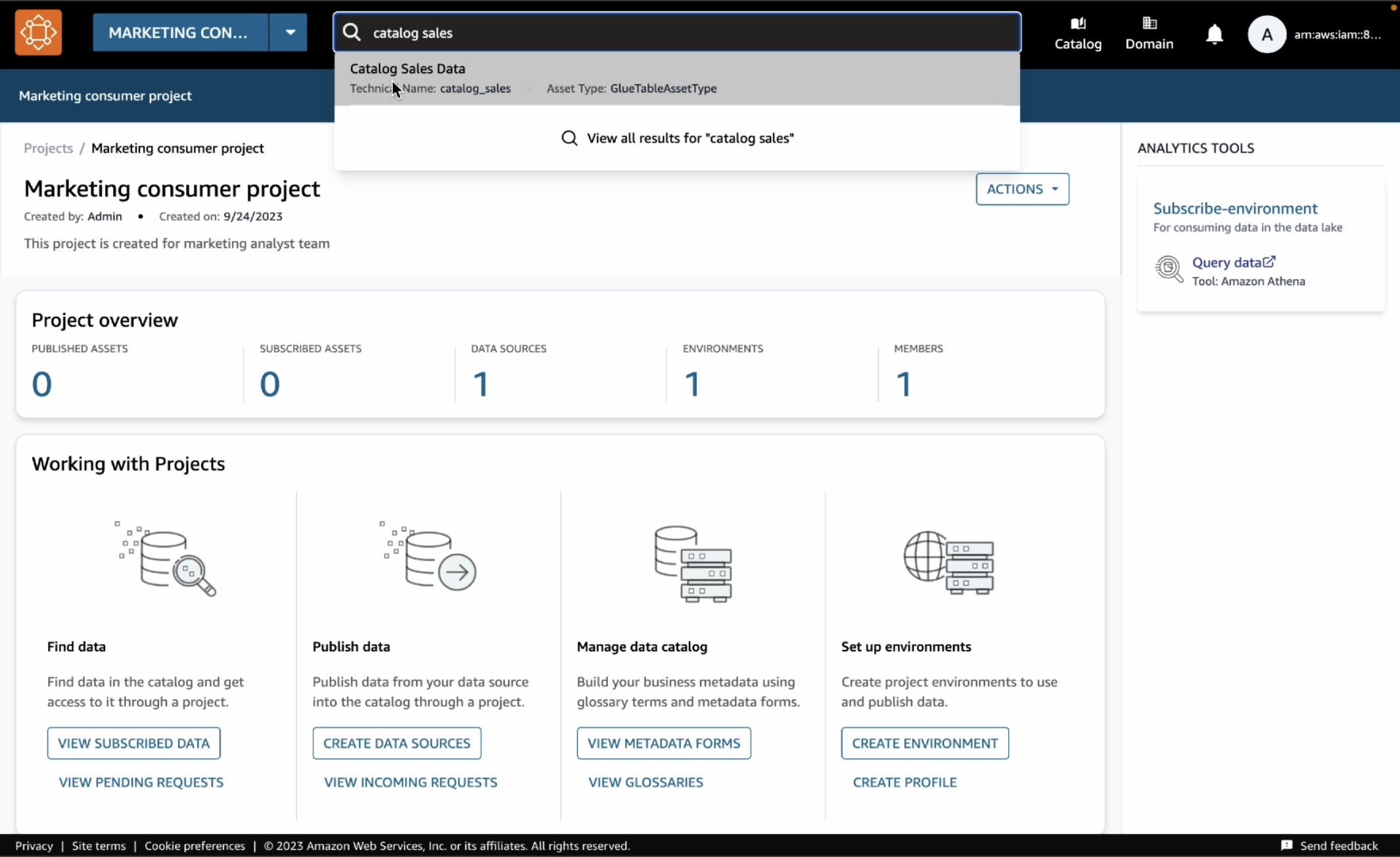
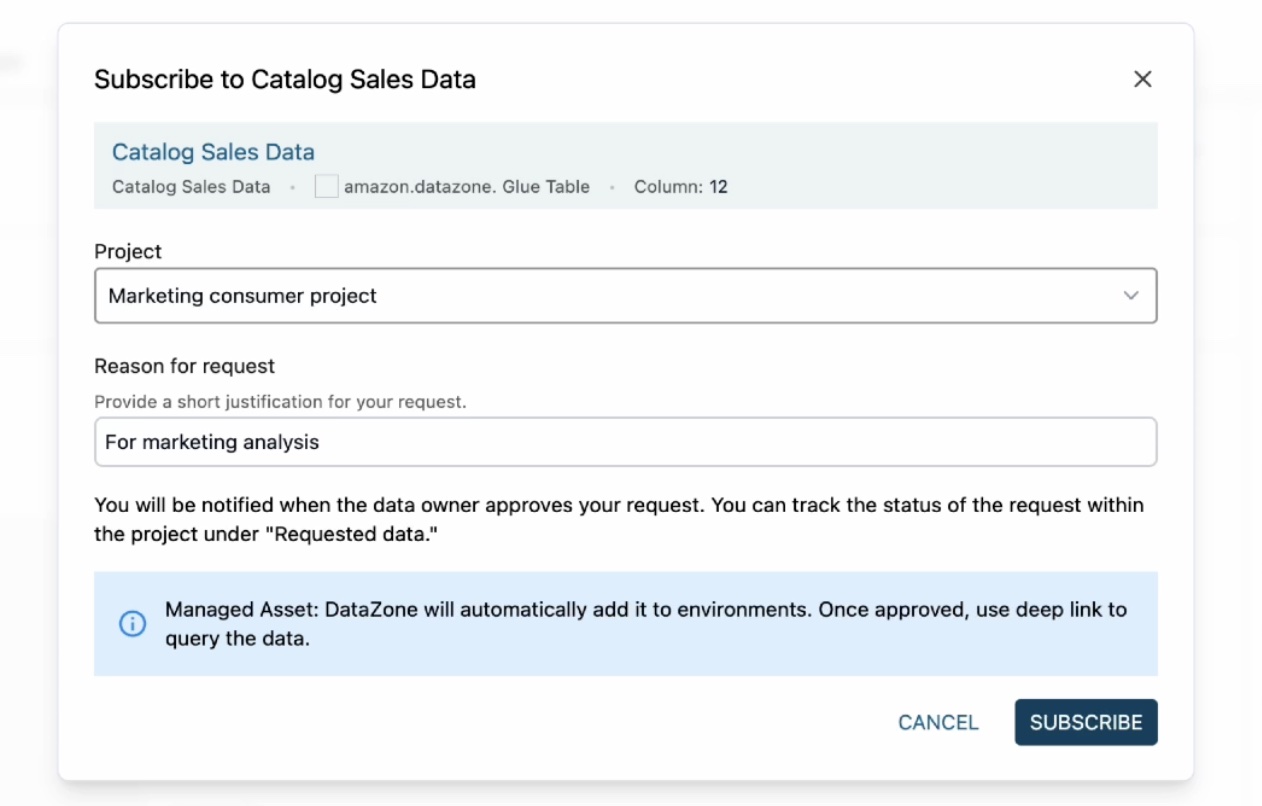
카탈로그에서 구독을 선택합니다.
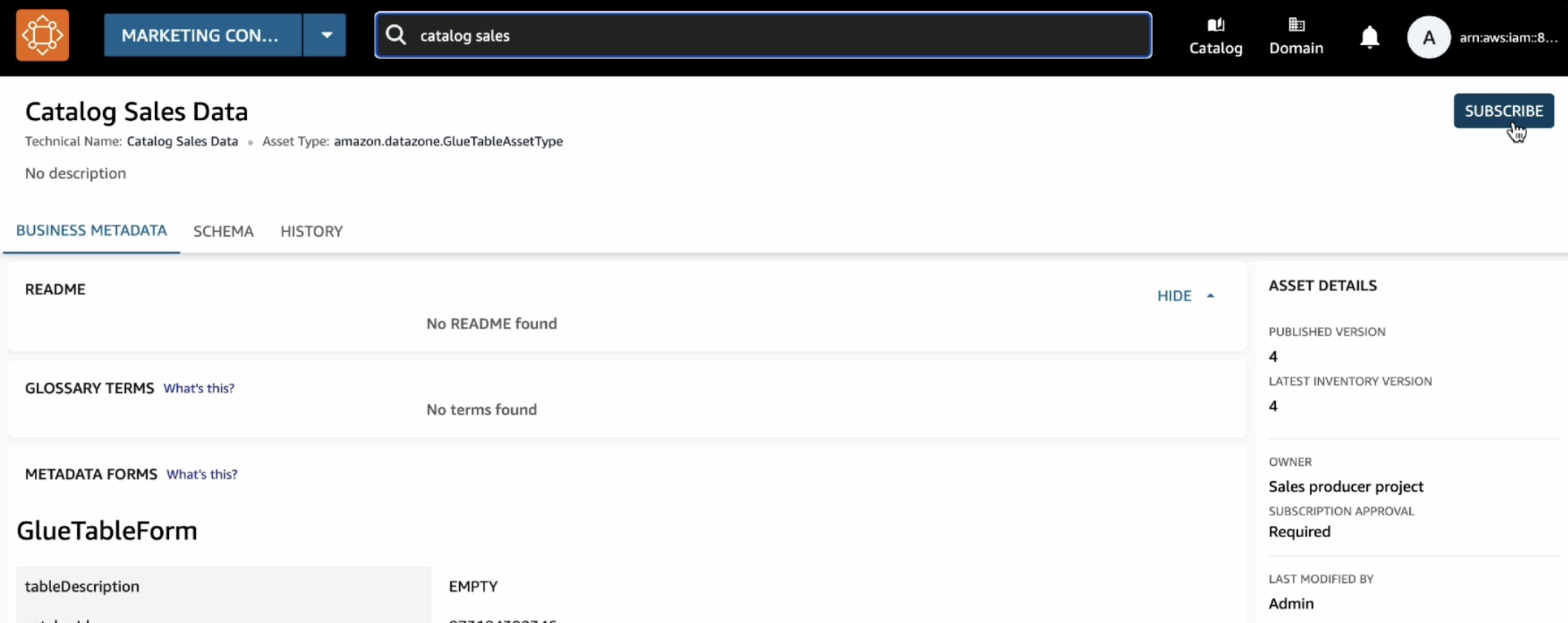
카탈로그 판매 데이터 구독 창에서 마케팅 소비자 프로젝트를 선택하고 구독 요청 이유를 입력한 다음 구독을 선택합니다.
데이터 생산자로서 구독 요청을 받으면 판매 생산자 프로젝트의 작업을 통해 알림이 발송됩니다. 여기서는 구독자 겸 게시자 역할을 모두 수행하므로 알림이 표시됩니다.
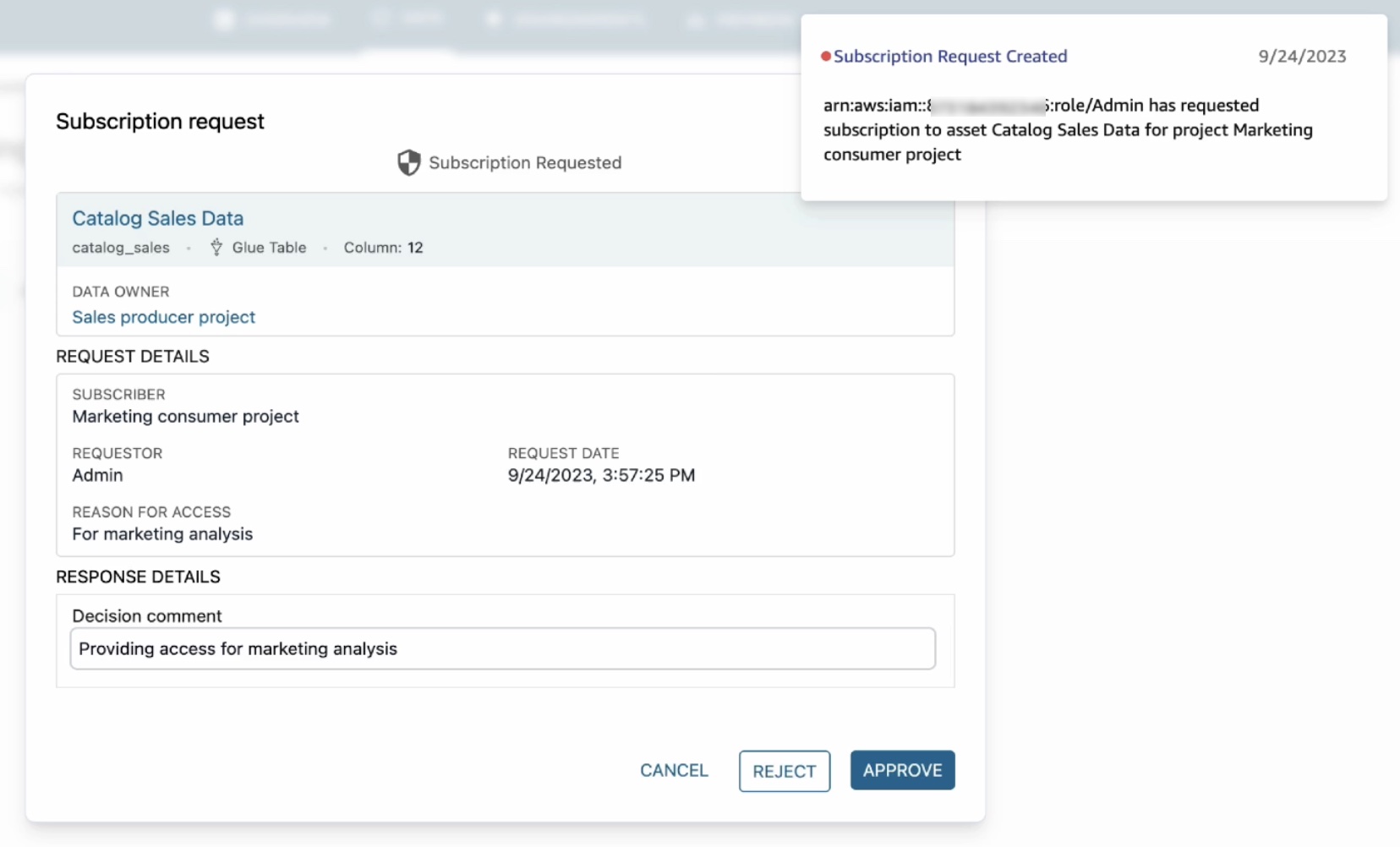
이 알림을 클릭하면 액세스를 요청한 프로젝트, 요청자, 액세스가 필요한 이유를 포함하여 구독 요청이 열립니다. 승인을 선택하고 승인 사유를 입력합니다.
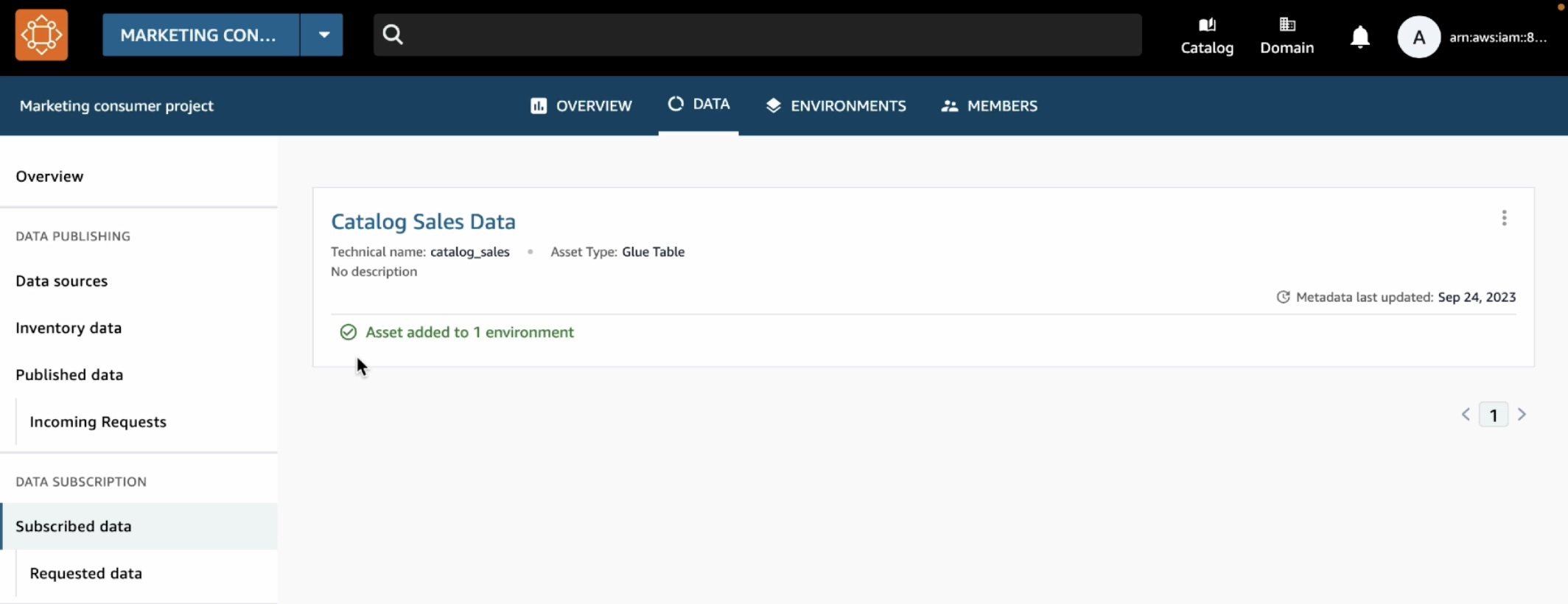
구독이 승인되었으므로 마케팅 소비자 프로젝트에서 카탈로그 판매 데이터를 볼 수 있습니다. 이를 확인하려면 상단 메뉴에서 데이터 탭을 선택하고 왼쪽 탐색 창에서 데이터 소스를 선택합니다.
구독 데이터를 분석하려면 상단 메뉴에서 환경 탭을 선택하고 마케팅 소비자 프로젝트에서 만든 구독 환경을 선택합니다. 그러면 오른쪽 창에 새 쿼리 데이터 링크가 표시됩니다.
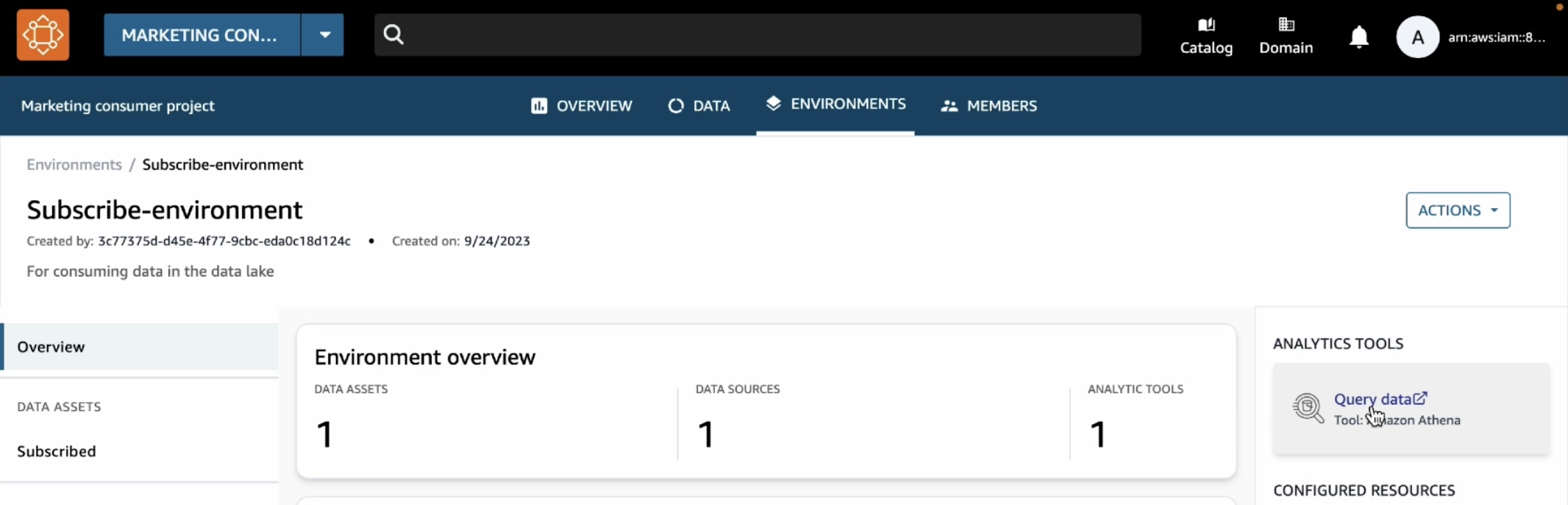
카탈로그 판매 테이블이 구독 데이터베이스 아래에 표시되는 것을 볼 수 있습니다.
이 테이블에 액세스할 수 있도록 테이블을 미리 보고 쿼리가 성공적으로 실행되는지 확인할 수 있습니다.
그러면 Athena 쿼리 편집기가 새 탭에서 열립니다. 데이터베이스 드롭다운에서 subscribeenvironment_sub_db를 선택한 다음 쿼리 편집기에 쿼리를 입력합니다.
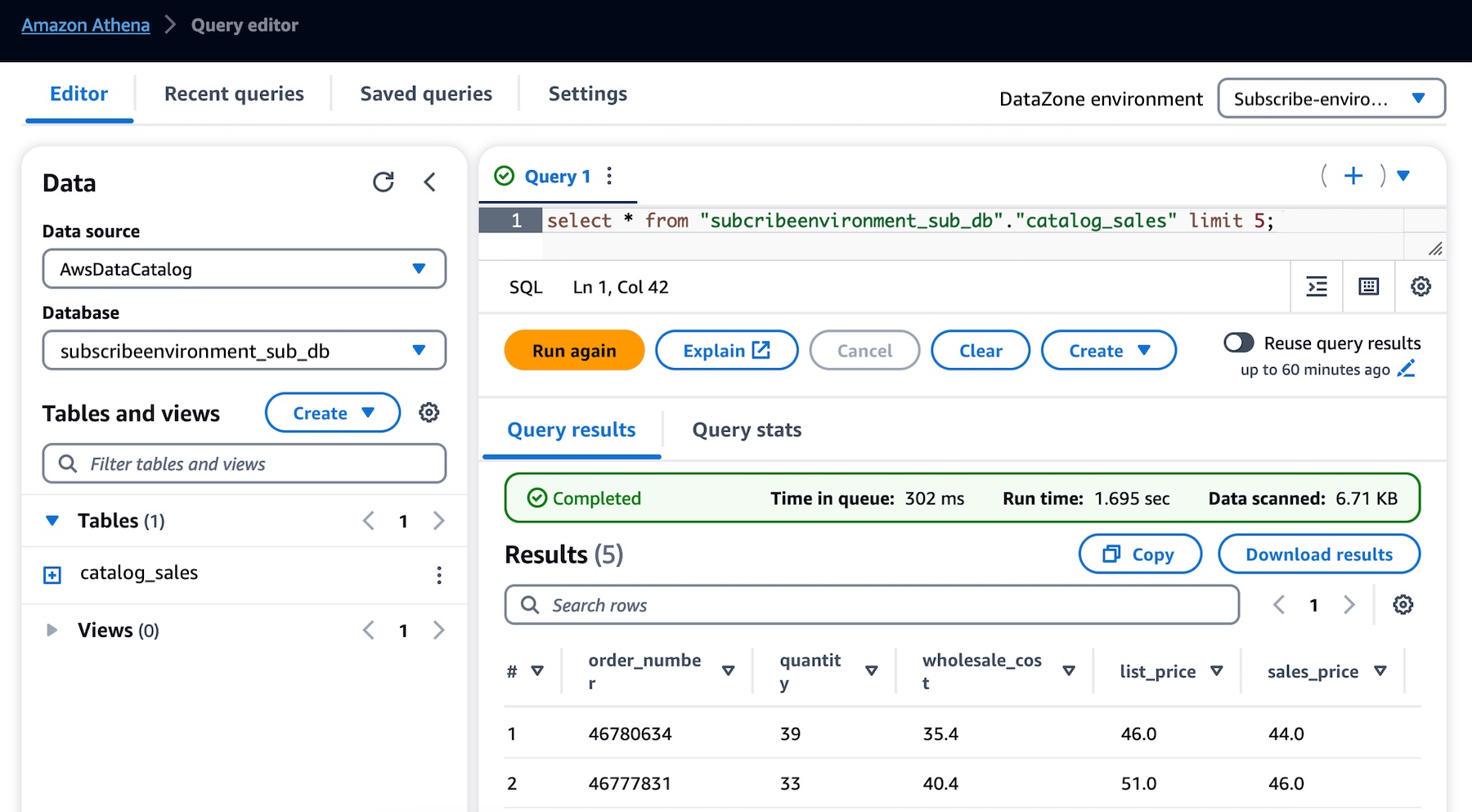
이제 소비자(마케팅 팀)로서 구독하고 생산자(영업 팀)가 비즈니스 데이터 카탈로그에 게시한 판매 데이터 테이블에서 모든 쿼리를 실행할 수 있습니다.
AWS Glue 테이블 및 Amazon Redshift 테이블 게시 및 보기와 같은 자세한 데모는 YouTube 재생 목록을 참조하세요.
정식 버전의 새로운 소식
평가판 이용 기간 동안 고객들로부터 많은 관심과 좋은 피드백을 받았습니다. 따라서 빠르게 기능을 검토하고 몇 가지 개선 사항을 소개하고자 합니다.
엔터프라이즈 레디 비즈니스 카탈로그 – 비즈니스 컨텍스트를 추가하고 조직의 모든 사용자가 데이터를 검색할 수 있도록 하려면 기계 학습을 사용하여 데이터 자산의 비즈니스 이름과 해당 자산 내에 열을 자동으로 생성하는 자동 메타데이터 생성을 통해 카탈로그를 사용자 지정하면 됩니다. 메타데이터 큐레이션 기능도 개선했습니다. 정식 버전에서는 여러 비즈니스 용어집을 자산에 연결하고 용어집 용어를 자산의 개별 열에 연결할 수 있습니다.
데이터 사용자를 위한 셀프 서비스 – 사용자가 데이터를 게시하고 사용할 수 있도록 데이터 자율성을 제공하려면 API를 사용하여 모든 유형의 자산을 사용자 지정하고 카탈로그에 가져오면 됩니다. 데이터 게시자는 데이터 수집을 통해 메타데이터 검색을 자동화하거나 Amazon Simple Storage Service(S3)에서 파일을 수동으로 게시할 수 있습니다. 데이터 소비자는 패싯 검색을 사용하여 데이터를 빠르게 찾고 이해할 수 있습니다. 사용자는 시스템의 업데이트 또는 대응 조치에 대해 알림을 받을 수 있습니다. 이러한 이벤트는 Amazon EventBridge를 사용하여 작업을 사용자 지정하는 고객의 이벤트 버스로 전송됩니다.
간소화된 분석 액세스 – 정식 버전에서 프로젝트는 비즈니스 사용 사례 기반 논리적 컨테이너 역할을 합니다. 프로젝트를 만들고 특정 비즈니스 사용 사례 기반 사용자, 데이터 및 분석 도구를 그룹화하여 협업할 수 있습니다. 프로젝트 구성원이 쉽게 새 데이터를 생성하거나 액세스 권한이 있는 데이터를 사용할 수 있도록 분석 도구 및 스토리지와 같은 필요한 인프라를 프로젝트 구성원에게 제공하는 환경을 프로젝트 내에서 만들 수 있습니다. 이를 통해 사용자는 필요에 따라 동일한 프로젝트에 여러 기능과 분석 도구를 추가할 수 있습니다.
관리형 데이터 공유 – 데이터 생산자는 소비자가 액세스를 요청하고 데이터 소유자가 승인할 수 있는 구독 승인 워크플로를 통해 데이터에 대한 액세스를 소유하고 관리합니다. 이제 구독 약관이 게시될 때 자산에 연결되도록 설정하고, 다른 소스를 위해 EventBridge 이벤트를 사용하는 사용자 지정을 통해 AWS 관리형 데이터 레이크 및 Amazon Redshift에 대한 구독 권한 이행을 자동화할 수 있습니다.
정식 출시
Amazon DataZone은 이제 미국 동부(오하이오), 미국 동부(버지니아 북부), 미국 서부(오레곤), 아시아 태평양(싱가포르), 아시아 태평양(시드니), 아시아 태평양(도쿄), 캐나다(중부), 유럽(프랑크푸르트), 유럽(아일랜드), 유럽(스톡홀름), 남아메리카(상파울루) 등 11개 AWS 리전에서 정식 출시됩니다.
Amazon DataZone의 무료 평가판은 처음 3개월 동안 추가 비용 없이 50명의 사용자가 사용할 수 있습니다. AWS 계정에서 Amazon DataZone 도메인을 처음 생성할 때 무료 평가판이 시작됩니다. 평가판 이용 기간 중 월간 사용자 수를 초과할 경우 표준 요금이 부과됩니다.
자세한 내용은 제품 페이지 및 사용 설명서를 참조하세요. 일반 AWS Support 문의처 또는 AWS re:Post for Amazon DataZone으로 피드백을 보내시면 됩니다.
— Channy