Amazon Web Services 한국 블로그
Amazon SageMaker Inference, 사용자 지정 Amazon Nova 모델 추론 서비스 제공
AWS NY Summit 2025에서 Amazon SageMaker AI의 Amazon Nova 사용자 지정 기능을 발표한 이래, 고객들은 Amazon SageMaker Inference에서 오픈 웨이트 모델을 사용자 지정할 때와 동일한 기능을 Amazon Nova에서도 요구해 왔습니다. 또한 프로덕션 워크로드에 요구되는 인스턴스 유형, 오토 스케일링 정책, 컨텍스트 길이, 동시성 설정 등에 대해 사용자 지정 모델 추론을 더 효과적으로 제어하고 더 높은 유연성을 갖기를 원했습니다.
오늘 저희는 풀랭크로 사용자 지정된 Nova 모델을 배포하고 확장할 수 있는 프로덕션 수준의 구성 가능하며 비용 효율적인 관리형 추론 서비스인 Amazon SageMaker Inference에서 사용자 지정 Nova 모델 지원 기능을 정식 출시하게 되었음을 발표합니다. 이제 Amazon SageMaker 훈련 작업 또는 Amazon HyperPod를 사용하여 추론 기능을 갖춘 Nova Micro, Nova Lite 및 Nova 2 Lite 모델을 훈련하고 Amazon SageMaker AI의 관리형 추론 인프라를 통해 원활하게 배포하는 엔드 투 엔드 사용자 지정 여정을 경험할 수 있습니다.
사용자 지정 Nova 모델용 Amazon SageMaker 추론을 사용하면 P5 인스턴스보다 최적화된 Amazon Elastic Compute Cloud(Amazon EC2) G5 및 G6 인스턴스의 GPU 활용도, 5분 동안의 사용량 패턴을 기준으로 한 오토 스케일링 조정, 구성 가능한 추론 파라미터 등을 통해 추론 비용을 줄일 수 있습니다. 이 기능을 사용하면 사용 사례에 맞게 지속적인 사전 훈련, 감독형 미세 조정 또는 강화 미세 조정을 통해 맞춤형 Nova 모델을 배포할 수 있습니다. 또한 컨텍스트 길이, 동시성, 배치 크기에 대한 고급 구성을 설정하여 특정 워크로드의 지연 시간과 비용 정확도 간의 절충을 최적화할 수 있습니다.
SageMaker AI 실시간 엔드포인트에 사용자 지정 Nova 모델을 배포하고, 추론 파라미터를 구성하고, 테스트를 위해 모델을 간접적으로 호출하는 방법을 살펴보겠습니다.
SageMaker Inference에서 사용자 지정 Nova 모델 배포
AWS re:Invent 2025에서, Nova 모델을 비롯한 인기 AI 모델을 지원하는 Amazon SageMaker AI의 새로운 서버리스 사용자 지정 기능을 소개한 바 있습니다. 몇 번의 클릭만으로 모델 및 사용자 지정 기술을 원활하게 선택하고 모델 평가와 배포를 처리할 수 있습니다. 훈련된 사용자 지정 Nova 모델 아티팩트가 이미 있는 경우, SageMaker Studio 또는 SageMaker AI SDK를 통해 SageMaker Inference에 모델을 배포할 수 있습니다.
SageMaker Studio의 모델 메뉴에서, 훈련된 Nova 모델을 선택합니다. 배포 버튼, SageMaker AI 및 새 엔드포인트 생성을 차례로 선택하여 모델을 배포할 수 있습니다.
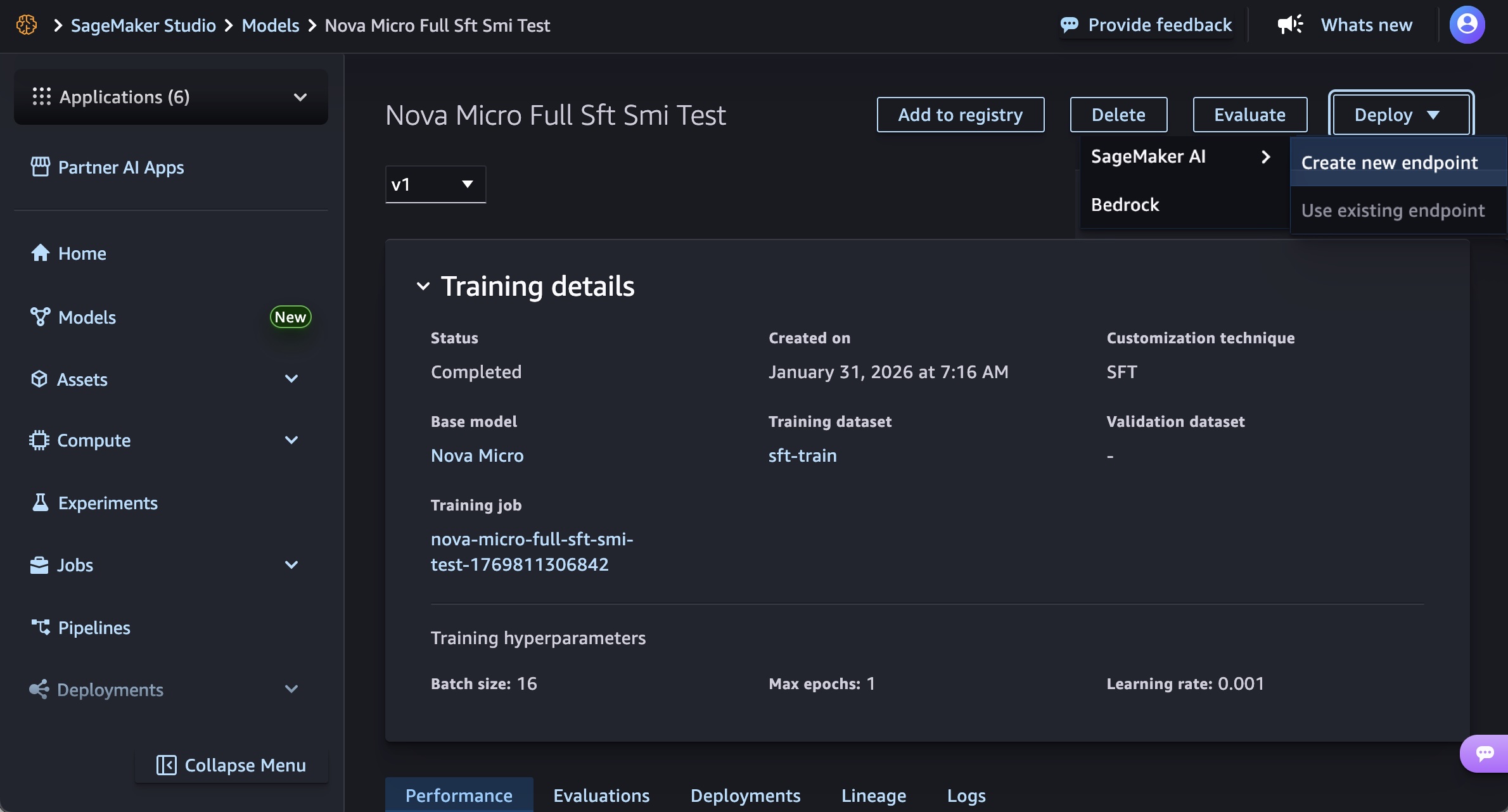
엔드포인트 이름, 인스턴스 유형, 고급 옵션(예: 인스턴스 수, 최대 인스턴스 수, 권한 및 네트워킹, 배포 버튼)을 선택합니다. GA 출시 시점에는 Nova Micro 모델에 g5.12xlarge, g5.24xlarge, g5.48xlarge, g6.12xlarge, g6.24xlarge, g6.48xlarge, p5.48xlarge 인스턴스 유형, Nova Lite 모델에 g5.48xlarge, g6.48xlarge , p5.48xlarge 인스턴스 유형, Nova 2 Lite 모델에 p5.48xlarge를 각각 사용할 수 있습니다.
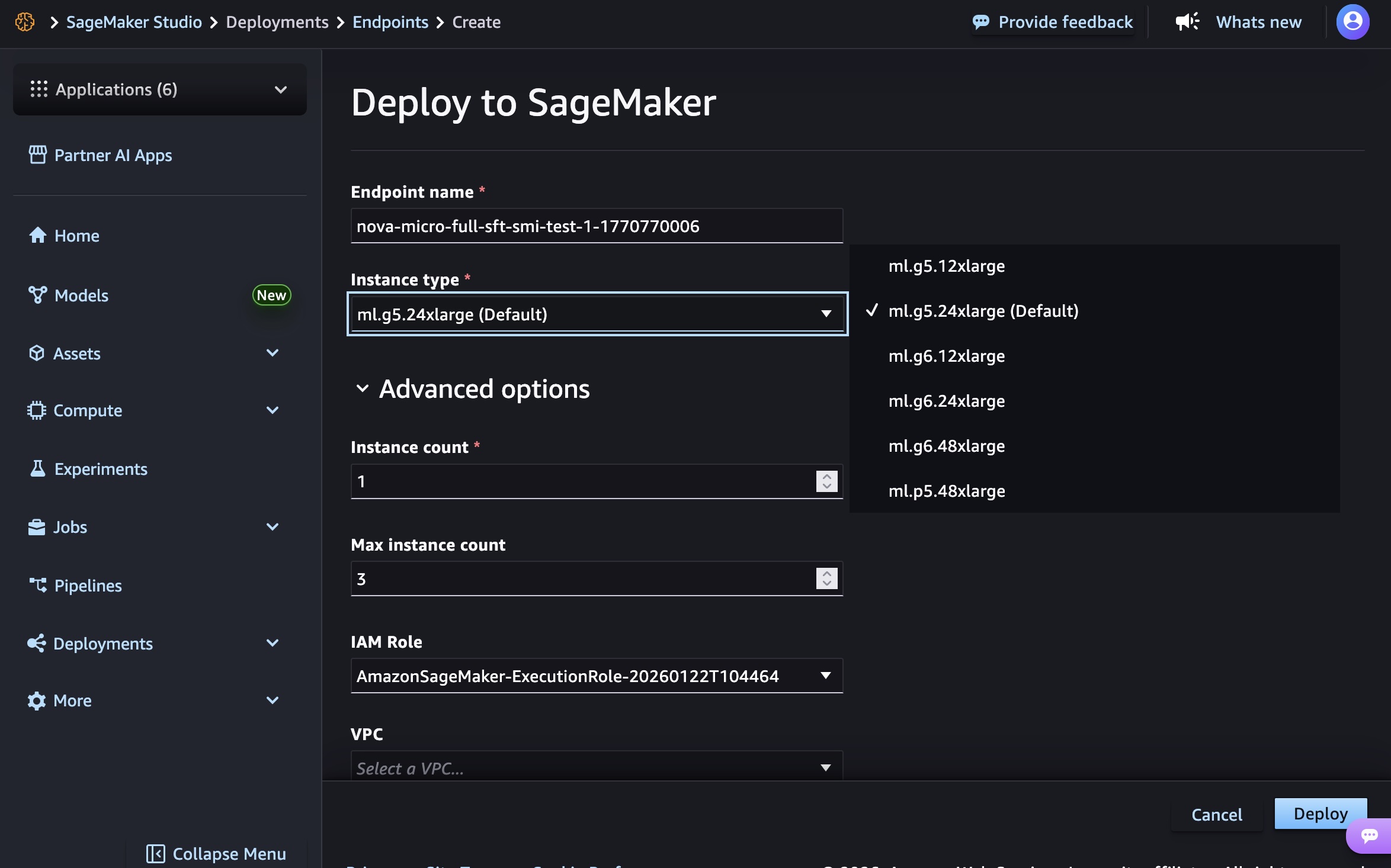
엔드포인트를 생성하려면 인프라를 프로비저닝하고, 모델 아티팩트를 다운로드하고, 추론 컨테이너를 초기화하는 데 시간이 소요됩니다.
모델 배포가 완료되고 엔드포인트 상태가 InService로 표시되면 새 엔드포인트를 사용하여 실시간 추론을 수행할 수 있습니다. 모델을 테스트하려면 Playground 탭을 선택하고 채팅 모드에서 프롬프트를 입력합니다.
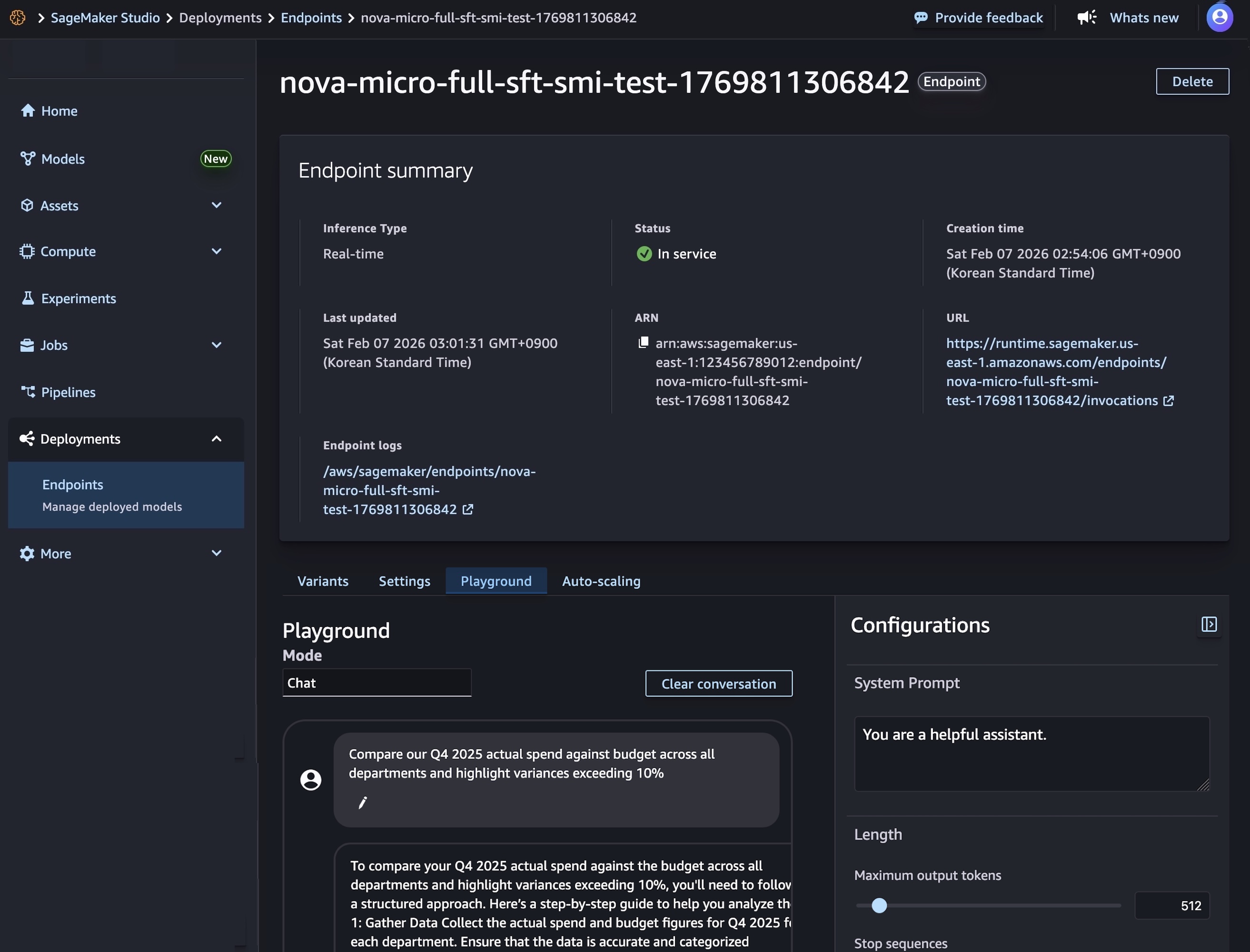
또한 SageMaker AI SDK를 사용하여 두 가지 리소스, 즉 Nova 모델 아티팩트를 참조하는 SageMaker AI 모델 객체와 모델 배포 방법을 정의하는 엔드포인트 구성을 생성할 수 있습니다.
다음 코드는 이 Nova 모델 아티팩트를 참조하는 SageMaker AI 모델을 생성합니다.
# Create a SageMaker AI model
model_response = sagemaker.create_model(
ModelName= 'Nova-micro-ml-g5-12xlarge',
PrimaryContainer={
'Image': '123456789012.dkr.ecr.us-east-1.amazonaws.com/nova-inference-repo:v1.0.0',
'ModelDataSource': {
'S3DataSource': {
'S3Uri': 's3://your-bucket-name/path/to/model/artifacts/',
'S3DataType': 'S3Prefix',
'CompressionType': 'None'
}
},
# 모델 파라미터
'Environment': {
'CONTEXT_LENGTH': 8000,
'MAX_CONCURRENCY': 16,
'DEFAULT_TEMPERATURE': 0.0,
'DEFAULT_TOP_P': 1.0
}
},
ExecutionRoleArn=SAGEMAKER_EXECUTION_ROLE_ARN,
EnableNetworkIsolation=True
)
print("Model created successfully!")다음으로 배포 인프라를 정의하는 엔드포인트 구성을 생성하고, SageMaker AI 실시간 엔드포인트를 생성하여 Nova 모델을 배포합니다. 이 엔드포인트는 모델을 호스팅하고 추론 요청을 위한 보안 HTTPS 엔드포인트를 제공합니다.
# Create Endpoint Configuration
production_variant = {
'VariantName': 'primary',
'ModelName': 'Nova-micro-ml-g5-12xlarge',
'InitialInstanceCount': 1,
'InstanceType': 'ml.g5.12xlarge',
}
config_response = sagemaker.create_endpoint_config(
EndpointConfigName= 'Nova-micro-ml-g5-12xlarge-Config',
ProductionVariants= production_variant
)
print("Endpoint configuration created successfully!")
# Noval 모델 배포
endpoint_response = sagemaker.create_endpoint(
EndpointName= 'Nova-micro-ml-g5-12xlarge-endpoint',
EndpointConfigName= 'Nova-micro-ml-g5-12xlarge-Config'
)
print("Endpoint creation initiated successfully!")
엔드포인트가 생성되고 나면, 추론 요청을 전송하여 사용자 지정 Nova 모델에서 예측을 생성할 수 있습니다. Amazon SageMaker AI는 스트리밍/비스트리밍 모드를 통해 동기식 엔드포인트를 실시간으로 지원하고 배치 처리를 위한 비동기식 엔드포인트도 지원합니다.
예를 들어 다음 코드는 텍스트 생성을 위한 스트리밍 완료 형식을 생성합니다.
# Streaming chat request with comprehensive parameters
streaming_request = {
"messages": [
{"role": "user", "content": "Compare our Q4 2025 actual spend against budget across all departments and highlight variances exceeding 10%"}
],
"max_tokens": 512,
"stream": True,
"temperature": 0.7,
"top_p": 0.95,
"top_k": 40,
"logprobs": True,
"top_logprobs": 2,
"reasoning_effort": "low", # Options: "low", "high"
"stream_options": {"include_usage": True}
}
invoke_nova_endpoint(streaming_request)
def invoke_nova_endpoint(request_body):
"""
자동 스트리밍 감지를 통해 Nova 엔드포인트를 호출합니다.
Args:
request_body (dict): 프롬프트와 매개변수가 포함된 요청 페이로드
Returns:
dict: 모델의 응답(비스트리밍 요청의 경우)
None: 스트리밍 요청의 경우(출력 직접 인쇄)
"""
body = json.dumps(request_body)
is_streaming = request_body.get("stream", False)
try:
print(f"Invoking endpoint ({'streaming' if is_streaming else 'non-streaming'})...")
if is_streaming:
response = runtime_client.invoke_endpoint_with_response_stream(
EndpointName=ENDPOINT_NAME,
ContentType='application/json',
Body=body
)
event_stream = response['Body']
for event in event_stream:
if 'PayloadPart' in event:
chunk = event['PayloadPart']
if 'Bytes' in chunk:
data = chunk['Bytes'].decode()
print("Chunk:", data)
else:
# 비스트리밍 추론
response = runtime_client.invoke_endpoint(
EndpointName=ENDPOINT_NAME,
ContentType='application/json',
Accept='application/json',
Body=body
)
response_body = response['Body'].read().decode('utf-8')
result = json.loads(response_body)
print("✅ Response received successfully")
return result
except ClientError as e:
error_code = e.response['Error']['Code']
error_message = e.response['Error']['Message']
print(f"❌ AWS Error: {error_code} - {error_message}")
except Exception as e:
print(f"❌ Unexpected error: {str(e)}")전체 코드 예제를 사용하려면 Customizing Amazon Nova models on Amazon SageMaker AI를 참조하세요. 모델 배포 및 관리에 대한 모범 사례를 자세히 알아보려면 SageMaker AI 모범 사례를 참조하세요.
정식 출시
사용자 지정 Nova 모델용 Amazon SageMaker Inference는 현재 미국 동부(버지니아 북부) 및 미국 서부(오레곤) AWS 리전에서 사용할 수 있습니다. 리전별 이용 가능 여부와 향후 로드맵은 리전별 AWS 기능을 참조하세요.
이 기능은 오토 스케일링을 지원하는 EC2 G5, G6 및 P5 인스턴스에서 실행되며 추론 기능을 제공하는 Nova Micro, Nova Lite 및 Nova 2 Lite 모델을 지원합니다. 사용한 컴퓨팅 인스턴스에 대해서만, 최소 약정 없이 시간당 요금이 청구됩니다. 자세한 내용은 Amazon SageMaker AI 요금 페이지를 참조하세요.
Amazon SageMaker AI 콘솔에서 사용해 보시고 AWS re:Post for SageMaker 또는 일반 AWS Support 문의로 피드백을 보내주세요.
– Channy