AWS 기술 블로그
분산 트레이닝 관점에서의 AWS 인터커넥트 기술 소개 – AWS의 인터커넥트 기반 기술, ENI 소개
지난 블로그에서는 AWS가 인피니밴드 대신 EFA를 선택한 이유와 두 기술의 철학적 차이에 대해 살펴보았습니다. 이번 블로그에서는 한 단계 더 들어가, EFA가 EC2 인스턴스에 연결되는 기반 구조인 ENI(Elastic Network Interface)에 대해 소개하고자 합니다.
EFA의 성능을 제대로 활용하려면 ENI가 무엇인지, 그리고 네트워크 카드와 ENI가 어떤 관계를 가지는지를 이해하는 것이 선행되어야 합니다. 특히 p5.48xlarge, p6-b300.48xlarge과 같은 고성능 GPU 인스턴스에서는 수십 개의 네트워크 카드와 ENI를 어떻게 구성하느냐에 따라 실제 분산 트레이닝 성능이 크게 달라집니다. 이 블로그를 통해 ENI의 구조와 할당 규칙, 그리고 실제 인스턴스 구성 방법까지 단계적으로 이해할 수 있기를 기대합니다.
시리즈 블로그 보기
- 분산 트레이닝 관점에서의 AWS 인터커넥트 기술 소개 – AWS는 왜 인터커넥트 기술로 EFA를 사용하는가?
- 분산 트레이닝 관점에서의 AWS 인터커넥트 기술 소개 – AWS의 인터커넥트 기반 기술, ENI 소개
- 분산 트레이닝 관점에서의 AWS 인터커넥트 기술 소개 – AWS 환경에서 NCCL을 이용한 GPU간 통신
- 분산 트레이닝 관점에서의 AWS 인터커넥트 기술 소개 – 분산 트레이닝을 위해 알아야 할GPU 간 고속 통신 기술
ENI의 역할과 구조
온프레미스 환경에서 서버는 물리적인 네트워크 어댑터를 통해 네트워크에 연결됩니다. 이더넷 환경에서는 NIC(Network Interface Card), 인피니밴드 환경에서는 HCA(Host Channel Adapter)가 이 역할을 담당합니다. 각 서버에는 하나 이상의 네트워크 어댑터가 장착되어 있으며, 이 어댑터는 스위치와 같은 네트워크 패브릭에 직접 연결되어 노드 간 통신을 처리합니다. 분산 트레이닝 환경에서는 고속 인터커넥트(예: 인피니밴드 HDR/NDR)를 통해 GPU 서버들이 직접 연결되며, 네트워크 구성은 하드웨어 사양에 따라 고정적으로 결정됩니다. 즉, 서버에 네트워크 어댑터가 몇 장 꽂혀 있느냐가 곧 네트워크 연결 수를 결정하며, 이를 변경하려면 물리적인 하드웨어 교체가 필요합니다.
AWS에서는 이러한 물리적 NIC의 역할을 ENI가 대신합니다. ENI는 소프트웨어 계층에서 동작하는 가상 네트워크 인터페이스로, EC2 인스턴스에 가상 네트워크 카드 역할을 수행합니다. 온프레미스 환경과는 달리 ENI는 소프트웨어적으로 생성·삭제·재연결이 가능하며, 인스턴스 간 이동도 유연하게 처리할 수 있습니다. EC2 인스턴스가 네트워크 통신을 하기 위해서는 반드시 최소 하나 이상의 ENI가 필요하며, 하나의 인스턴스에 여러 개의 ENI를 연결하는 것도 가능합니다. 단, 인스턴스 유형에 따라 연결 가능한 최대 ENI 개수가 정해져 있습니다.
Nitro 기반 인스턴스를 기준으로, 개별 ENI는 ENA(Elastic Network Adapter) 또는 EFA(Elastic Fabric Adapter, ENA의 확장) 속성 중 하나를 가집니다. 분산 트레이닝을 수행하거나 고성능의 엔지니어링 시뮬레이션이 필요하다면 EFA 사용은 필수입니다.
모든 EC2 인스턴스에는 반드시 Primary ENI가 존재합니다. Primary ENI는 인스턴스가 시작될 때 자동으로 생성되며, 인스턴스가 종료될 때 함께 삭제됩니다. 일반 ENI와 달리 Primary ENI는 인스턴스에서 분리(detach)할 수 없으며, 인스턴스의 생명주기와 함께 존재합니다. Primary ENI는 SSH 접속, AWS API 호출 등 인스턴스 관리 및 제어 트래픽의 기본 통신 경로를 담당합니다. Primary ENI는 인스턴스 시작 시 EFA 활성화 여부에 따라 일반 ENI(ENA) 또는 EFA with ENA로 구성됩니다.
ENI의 유형은 다음 세 가지로 구분됩니다.
- 일반 ENI(ENA): 표준 IP 기반 네트워크 통신만 지원합니다. 인스턴스 내에서 eth0 디바이스(실제로 리눅스에는 ens5 등으로 확인됨)로 표시됩니다. EFA를 활성화하지 않은 경우 이 유형이 적용됩니다.
- EFA with ENA: ENA(IP 네트워크 기능)와 EFA(고성능 HPC용 SRD 프로토콜 기능)가 복합된 네트워크 인터페이스입니다. IP 기반의 일반 통신과 RDMA 기반의 고성능 HPC 통신을 동시에 지원합니다. Primary ENI 또는 Secondary ENI로 사용 가능합니다.
- EFA-only: EFA 전용 인터페이스로, IP 네트워킹 기능은 없으며 오직 고성능 HPC 통신(SRD 프로토콜)만 지원합니다. IP 통신 오버헤드가 없기 때문에 순수 HPC 워크로드에서 더 낮은 레이턴시를 달성할 수 있습니다. Primary ENI에는 적용할 수 없으며, Secondary ENI로만 사용 가능합니다.
여기서 한 가지 중요한 제약이 있습니다. “EFA with ENA”와 “EFA-only”는 동일한 네트워크 카드(NetworkCardIndex)에 동시에 연결할 수 없습니다. 즉, 하나의 네트워크 카드에는 두 유형 중 하나만 선택하여 할당해야 합니다.
네트워크 카드와 ENI: 두 계층의 이해
여기서 독자들이 혼동하기 쉬운 개념이 있습니다. 바로 네트워크 카드(Network Card)와 ENI(네트워크 인터페이스)의 차이입니다.
온프레미스에서는 물리적 NIC 하나가 네트워크 연결의 모든 것을 담당합니다. 그러나 AWS에서는 이 역할이 두 계층으로 분리됩니다. 네트워크 카드(Network Card)는 EC2 인스턴스 내에서 논리적으로 구분된 네트워크 하드웨어 단위입니다. 실제 PCIe 버스에 연결된 물리적 Nitro 카드를 하이퍼바이저가 논리적 인덱스(NetworkCardIndex)로 추상화한 것으로, 각 NetworkCardIndex는 독립적인 물리적 네트워크 자원에 매핑됩니다.
물리적 Nitro 카드 #1 ←→ NetworkCardIndex 0
물리적 Nitro 카드 #2 ←→ NetworkCardIndex 1
물리적 Nitro 카드 #3 ←→ NetworkCardIndex 2
…
물리적 Nitro 카드 #N ←→ NetworkCardIndex N-1
사용자와 소프트웨어는 물리적 하드웨어에 직접 접근하는 것이 아니라, 이 논리적 인덱스를 통해 각 네트워크 카드를 식별하고 ENI를 할당합니다. 각 네트워크 카드는 독립적인 대역폭 자원을 가지며, 인스턴스 유형에 따라 1개 또는 여러 개를 가질 수 있습니다.
ENI는 네트워크 카드 위에서 동작하는 소프트웨어 계층의 가상 네트워크 인터페이스입니다. IP 주소, MAC 주소, 보안 그룹 등 실제 네트워크 속성을 담고 있으며, 하나의 네트워크 카드에 여러 개의 ENI를 연결할 수 있습니다. 하나의 네트워크 카드에 연결할 수 있는 최대 ENI 수는 인스턴스 전체의 최대 ENI 수와 마찬가지로 인스턴스 타입별로 정의되어 있습니다.
이 두 계층의 분리 덕분에 AWS는 온프레미스의 고정적인 네트워크 구성과 달리, 소프트웨어적으로 유연하고 세밀한 네트워크 제어를 가능하게 합니다.
대부분의 일반 EC2 인스턴스는 1개의 네트워크 카드를 가지고 있습니다. 반면, 고성능 컴퓨팅을 위한 인스턴스는 여러 개의 네트워크 카드를 탑재하고 있습니다. 앞서 언급한 p5.48xlarge 인스턴스는 표1과 같이 32개의 네트워크 카드(NetworkCardIndex 0~31)를 보유하고 있으며, 이를 통해 대규모 분산 트레이닝 워크로드에서 요구되는 높은 네트워크 대역폭과 병렬 통신을 효율적으로 처리할 수 있습니다. 아래 표는 주요 고성능 인스턴스 유형별 네트워크 카드와 ENI 구성을 보여줍니다. 이 표를 보면 인스턴스 세대별로 흥미로운 설계 철학의 변화를 읽을 수 있습니다.
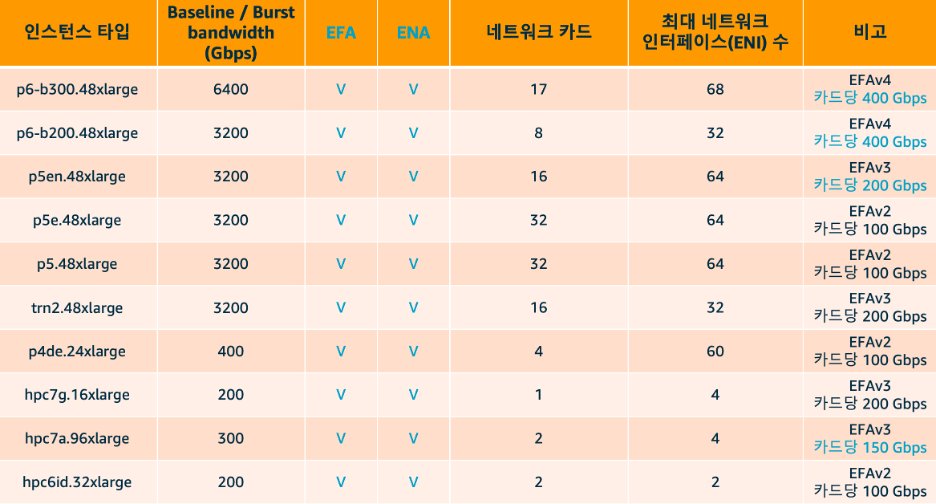
<표1. 주요 인스턴스 타입별 네트워크 카드 및 최대 네트워크 인터페이스 개수>
p5.48xlarge와 p5e.48xlarge는 32개의 네트워크 카드를 가지고 있으며, 카드당 2개의 ENI를 허용하여 총 64개의 ENI를 가집니다. p6-b200.48xlarge의 경우, 8개의 네트워크 카드(NetworkCardIndex 0~7)가 있고 카드당 최대 4개의 ENI를 연결할 수 있어 총 32개의 ENI를 가집니다. 각 네트워크 카드는 400 Gbps의 대역폭을 제공하며, 8개 카드의 합산으로 총 3,200 Gbps의 네트워크 대역폭을 달성합니다. 최신 인스턴스 세대로 올수록 네트워크 카드 수를 줄이는 대신, 카드당 대역폭을 대폭 늘리는 방향으로 설계가 진화하고 있음을 알 수 있습니다. 이는 더 적은 수의 고성능 Nitro 카드로 동일하거나 더 높은 총 대역폭을 달성하는 하드웨어 효율화 전략입니다.
ENI 할당 규칙
ENI 할당에는 몇 가지 중요한 규칙이 적용됩니다.
첫째, Primary ENI는 반드시 NetworkCardIndex 0에 할당되어야 합니다. NetworkCardIndex 0은 물리적 Nitro 카드 #1에 대응하는 첫 번째 네트워크 카드로, 인스턴스의 기본 네트워크 통신 경로를 보장하기 위한 필수 조건입니다. 이 규칙은 인스턴스 유형에 관계없이 모든 EC2 인스턴스에 공통으로 적용됩니다.
둘째, EFA ENI는 네트워크 카드당 최대 1개만 허용됩니다. 이는 EFA가 RDMA 기반의 고성능 통신을 위해 물리적 Nitro 카드와 긴밀하게 연동되기 때문입니다. 나머지 슬롯은 필요에 따라 선택적으로 일반 ENA ENI로 채울 수 있습니다. 예를 들어 카드당 4개의 ENI를 허용하는 인스턴스라면 1개의 EFA ENI와 최대 3개의 일반 ENA ENI를, 카드당 2개의 ENI를 허용하는 인스턴스라면 1개의 EFA ENI와 최대 1개의 일반 ENA ENI를 구성할 수 있습니다. 물론 EFA를 사용하지 않는다면 허용된 ENI 슬롯을 모두 일반 ENA ENI로 구성하는 것도 가능합니다.
셋째, Primary ENI에 EFA를 할당하는 경우, 해당 ENI는 EFA-only 타입이 될 수 없습니다. Primary ENI는 반드시 EFA with ENA 타입으로 구성되어야 하며, 이를 통해 IP 기반의 일반 통신과 RDMA 기반의 고성능 통신을 동시에 지원합니다. 이는 인스턴스의 기본 관리 통신(SSH 접속, AWS API 호출 등)이 항상 IP 기반으로 동작해야 하기 때문입니다.
DeviceIndex 라는 개념 이해하기
EC2 네트워크 구성에서 혼란을 주는 개념 중 하나가 바로 DeviceIndex입니다.
EC2 인스턴스의 네트워크 구성을 이해하기 위해서는 추가적인 핵심 인덱스 개념을 명확히 구분해야 합니다. 이 인덱스는 ENI가 인스턴스에 연결되는 방식을 정의하며, 인스턴스 타입에 따라 서로 다른 동작 방식을 보입니다.
DeviceIndex는 ENI가 인스턴스에 연결되는 순서를 나타내는 인덱스입니다. 운영체제 관점에서 네트워크 인터페이스가 인식되는 순서를 의미하며, 인스턴스 내부에서 eth0, eth1, eth2와 같은 디바이스 이름으로 매핑됩니다. 단, 인스턴스 유형에 따라 이 인덱스가 전역적인 연결 순서를 반영하기도 하고, 각 네트워크 카드 내의 로컬 순서를 나타내기도 합니다. 이 차이는 뒤에서 자세히 설명합니다.
Primary ENI는 NetworkCardIndex=0, DeviceIndex=0으로 할당되는 인스턴스당 하나만 존재하는 필수 ENI입니다. 인스턴스의 기본 네트워크 통신 경로를 담당하며, 인스턴스 시작 시 자동으로 생성되고 인스턴스가 종료될 때까지 삭제할 수 없습니다. SSH 접속, AWS API 호출 등 모든 기본 관리 통신이 이 Primary ENI를 통해 이루어집니다.
Primary ENI를 제외한 나머지 ENI는 모두 Secondary ENI로 분류됩니다. 단일 네트워크 카드 인스턴스에서는 DeviceIndex=1 이상이 Secondary ENI가 되고, 다중 네트워크 카드 인스턴스에서는 다른 NetworkCardIndex에 연결된 ENI가 DeviceIndex 값과 관계없이 Secondary ENI가 됩니다. Secondary ENI는 필요에 따라 동적으로 연결하거나 분리할 수 있어, 네트워크 구성의 유연성을 제공합니다.
대부분의 범용 인스턴스는 앞서 언급한 대로 하나의 네트워크 카드만 보유하고 있습니다. 이러한 일반 인스턴스에서는 모든 ENI가 동일한 네트워크 카드(NetworkCardIndex=0)에 연결되며, DeviceIndex는 0, 1, 2, 3과 같이 순차적으로 증가합니다.
예를 들어, 그림1과 같이 t3.xlarge 인스턴스에 4개의 ENI를 연결하는 경우를 살펴보겠습니다. 첫 번째 ENI는 NetworkCardIndex=0, DeviceIndex=0으로 Primary ENI가 됩니다. 두 번째 ENI는 NetworkCardIndex=0, DeviceIndex=1로 설정되며, 세 번째와 네 번째 ENI는 각각 DeviceIndex=2, DeviceIndex=3을 가지게 됩니다. 모든 ENI는 동일한 네트워크 카드를 공유하므로, 네트워크 대역폭도 모든 ENI 간에 공유됩니다. 단일 네트워크 카드에 여러 ENI를 순차적으로 연결하는 방식이므로, DeviceIndex가 전역적인 연결 순서를 명확하게 반영합니다.
고성능 컴퓨팅을 위한 인스턴스는 여러 개의 네트워크 카드를 보유하며, 각 카드에 여러 개의 ENI를 연결할 수 있습니다. 이 경우 DeviceIndex의 동작 방식이 일반 인스턴스와 크게 달라집니다.
p5.48xlarge 인스턴스를 예로 들어보겠습니다. 이 인스턴스는 32개의 네트워크 카드를 보유하고 있으며, 카드당 최대 2개의 ENI를 연결할 수 있어 총 64개의 ENI를 지원합니다.
EFA 구성 방식은 Primary ENI의 InterfaceType에 따라 두 가지 패턴으로 나뉩니다.
첫 번째 패턴은 Primary ENI를 EFA with ENA(InterfaceType=efa)로 설정하는 방식입니다. 이 경우 하나의 ENI에서 EFA와 ENA를 모두 지원하므로, NetworkCardIndex=0에는 이 ENI 하나만 연결됩니다. 같은 카드에 EFA-only를 추가로 붙일 수 없기 때문입니다. 나머지 카드(NetworkCardIndex 1부터 31)에는 각각 EFA-only ENI가 DeviceIndex=0 으로 설정됩니다.
두 번째 패턴은 Primary ENI를 ENA 전용(InterfaceType=interface)으로 설정하는 방식입니다. 이 경우 같은 카드에 EFA-only ENI를 추가로 연결할 수 있으므로, NetworkCardIndex=0에 ENA(DeviceIndex=0)와 EFA-only(DeviceIndex=1) 두 개의 ENI가 붙습니다. 나머지 카드에는 EFA-only ENI가 DeviceIndex=0으로 설정됩니다. 현재 AWS 공식 문서에서는 이 두 번째 패턴을 기본 구성으로 안내하고 있습니다.
어떤 패턴을 사용하든 DeviceIndex는 각 네트워크 카드 내에서의 로컬 인덱스라는 원칙은 동일합니다. 인스턴스 유형과 용도에 따른 자세한 구성 패턴은 AWS 공식 문서를 참고하시기 바랍니다.

<그림1. 인스턴스 유형별 NetworkCardIndex와 DeviceIndex 할당 구조 >
쉽게 설명하자면, 단일 네트워크를 갖는 일반 인스턴스는 1개 동(NetworkCardIndex=0)으로 구성된 아파트 단지입니다. 1개의 동에 여러 세대(ENI)가 존재합니다. 101호(DeviceIndex=0, Primary), 102호(DeviceIndex=1), 103호(DeviceIndex=2) 순으로 순차적으로 번호가 증가합니다. 이와는 반대로 p5.48xlarge(다중 네트워크 카드)는 32개 동으로 구성된 대규모 아파트 단지입니다. 그러나 각 동마다 1개 세대만 존재합니다. (경우에 따라 첫번째 동은 2개 세대 존재 가능)
- 1동: DeviceIndex=0 (Primary ENI) + DeviceIndex=1 (EFA-only) 또는 DeviceIndex=0 (EFA with ENA)
- 2동: DeviceIndex=0 (EFA-only)
- 3동: DeviceIndex=0 (EFA-only)
- …
- 32동: DeviceIndex=0 (EFA-only)
일반 인스턴스와 EFA 지원 다중 네트워크 카드 인스턴스의 설계 철학은 근본적으로 다릅니다. 일반 인스턴스는 단일 네트워크 카드에 여러 ENI를 순차적으로 연결하는 방식으로, DeviceIndex가 전역적인 연결 순서를 반영합니다. 네트워크 대역폭이 모든 ENI 간에 공유되며, 주로 다중 서브넷 연결이나 보안 그룹 분리 등의 용도로 사용됩니다.
반면, EFA 지원 다중 네트워크 카드 인스턴스는 각 네트워크 카드가 독립적인 물리적 경로를 제공하도록 설계되었습니다. 네트워크 대역폭이 카드별로 분리되어 병렬 처리가 가능합니다. 이는 고성능 HPC 워크로드를 위한 최적화된 구조로, 대규모 분산 트레이닝이나 시뮬레이션 작업에서 노드 간 통신 성능을 극대화하기 위한 설계입니다.
이러한 구조적 차이는 고성능 컴퓨팅 워크로드에서 매우 중요한 의미를 가집니다. p5.48xlarge의 경우 총 3,200 Gbps의 네트워크 대역폭을 32개 네트워크 카드에 분산하여, 카드당 100 Gbps씩 독립적으로 활용할 수 있습니다. 각 카드가 독립적으로 동작하므로 병목 현상이 최소화되며, 대규모 분산 트레이닝에서 수백 개의 노드가 동시에 통신할 때도 안정적인 성능을 유지할 수 있습니다.
EFA 최적화 측면에서도 중요한 의미를 가집니다. 각 네트워크 카드에 하나의 EFA ENI만 할당하여 RDMA 통신의 효율성을 극대화할 수 있으며, 카드 간 간섭 없이 순수한 OS-bypass 통신이 가능합니다. 이는 MPI 기반의 고성능 컴퓨팅 애플리케이션에서 레이턴시를 마이크로초 단위로 줄이는 데 결정적인 역할을 합니다.
또한 관리 트래픽과 HPC 트래픽을 명확하게 분리할 수 있습니다. Primary ENI(NetworkCardIndex=0)는 관리 트래픽 겸용으로 사용하고, 나머지 31개 카드는 순수 HPC 워크로드 전용으로 분리함으로써, SSH 접속이나 모니터링 작업이 고성능 통신에 영향을 주지 않도록 격리할 수 있습니다.
이러한 설계 철학은 AWS가 고성능 인스턴스에서 네트워크 성능을 극대화하기 위해 채택한 핵심 전략입니다. 다음 섹션에서는 이러한 구조가 실제 분산 트레이닝 환경에서 어떻게 활용되는지 구체적으로 살펴보겠습니다.
p5.48xlarge 인스턴스 EFA 구성 실전 가이드
앞서 설명한 ENI 할당 규칙을 실제로 어떻게 적용하는지, p5.48xlarge 인스턴스를 예시로 살펴보겠습니다. p5.48xlarge는 앞서 언급한 것처럼, 32개의 네트워크 카드를 보유한 고성능 HPC 인스턴스로, 대규모 분산 트레이닝 워크로드에 최적화된 네트워크 구성을 제공합니다.
p5.48xlarge의 32개 네트워크 카드는 역할에 따라 명확하게 분리됩니다. 첫 번째 네트워크 카드(NetworkCardIndex=0)에는 2개의 ENI가 할당됩니다. DeviceIndex=0에는 Primary ENI로 InterfaceType=interface(ENA)를 설정하여 SSH 접속, AWS API 호출 등 IP 기반의 관리 통신을 담당하고, DeviceIndex=1에는 InterfaceType=efa-only를 설정하여 고성능 HPC 통신을 전담합니다. 이를 통해 관리 트래픽과 HPC 트래픽이 동일한 네트워크 카드 내에서도 ENI 레벨에서 분리됩니다. 이전에는 InterfaceType=efa(EFA with ENA)를 사용하여 하나의 ENI에서 IP 통신과 RDMA 통신을 동시에 처리하는 방식이 사용되었으나, 현재 AWS 권장 구성은 ENA와 EFA-only를 별도 ENI로 분리하는 방식입니다. EFA-only는 IP 스택 오버헤드 없이 순수 RDMA 통신만 처리하므로, 더 낮은 레이턴시를 달성할 수 있습니다.
나머지 31개의 네트워크 카드(NetworkCardIndex=1-31)는 각각 DeviceIndex=0에 InterfaceType=efa-only로 구성됩니다. 이들은 순수 OS-bypass RDMA 통신만 전담하며, IP 스택을 거치지 않기 때문에 오버헤드가 최소화되어, 대규모 분산 트레이닝에서 요구되는 극도로 낮은 레이턴시와 높은 처리량을 달성할 수 있습니다.
아래 예제는 p5.48xlarge 인스턴스의 실제 EFA 상세 구성 내용을 보여줍니다.
보안 그룹과 서브넷 설정도 중요합니다. 클러스터 내 모든 노드가 동일한 보안 그룹과 서브넷을 사용하는 것을 권장합니다. 이는 노드 간 통신을 단순화하고 네트워크 구성을 일관되게 유지하는 데 도움이 됩니다. 특히 EFA 통신을 위해서는 동일 보안 그룹 내 모든 트래픽(All Traffic)을 허용하는 인바운드 규칙이 필수입니다. EFA의 SRD 프로토콜은 표준 TCP/UDP 포트가 아닌 별도의 전송 경로를 사용하므로, 특정 포트만 허용하는 방식으로는 EFA 통신을 정상적으로 지원할 수 없습니다.
또한 실제 프로덕션 환경에서 p5.48xlarge 인스턴스를 배포할 때는 몇 가지 중요한 고려사항이 있습니다.
첫째, 자동화가 필수적입니다. 32개의 네트워크 인터페이스를 수동으로 구성하는 것은 매우 비효율적이며 오류가 발생하기 쉽습니다. CloudFormation 템플릿이나 Terraform 스크립트를 활용하여 네트워크 구성을 자동화하는 것을 강력히 권장합니다. 클러스터 구성이 궁극적 목적이라면 AWS ParallelCluster를 사용하면 이러한 복잡한 네트워크 구성이 자동으로 처리되며, HPC 클러스터 관리에 필요한 다른 많은 기능도 함께 제공됩니다.
둘째, 모든 EFA ENI를 활성화해야 최대 성능을 발휘합니다. p5.48xlarge는 32개의 EFA ENI를 모두 구성했을 때 총 3,200 Gbps의 네트워크 대역폭을 온전히 활용할 수 있습니다. 일부 EFA ENI만 구성하면 그만큼 사용 가능한 대역폭이 줄어들기 때문에, 대규모 분산 트레이닝 워크로드에서는 32개 EFA ENI를 모두 구성하는 것을 권장합니다.
셋째, 인스턴스 시작 후 RDMA 디바이스가 올바르게 구성되었는지 확인해야 합니다. ibv_devices 명령어를 사용하면 시스템에서 인식된 RDMA 디바이스 목록을 확인할 수 있습니다. 즉, 출력에서 확인된 rdma 디바이스 수가 구성한 EFA ENI 수와 일치하는지 확인이 필요합니다.
넷째, 모니터링과 문제 해결을 위한 준비가 필요합니다. 초기 구성 검증을 위해서는 libfabric 유틸리티(fi_info, fi_pingpong)나 nccl-tests와 같은 벤치마크 도구를 사용하여 네트워크 대역폭, 레이턴시, 그리고 다중 노드 간 통신 성능을 측정할 수 있습니다. 프로덕션 환경에서는 각 컴퓨트 노드에 “EFA node exporter”를 설치하여 지속적인 모니터링 체계를 구축하는 것을 권장합니다. CloudWatch Agent를 통해 네트워크 처리량, 패킷 손실률 등의 시스템 메트릭을 수집하고, EFA node exporter를 통해 EFA 디바이스 상태(RDMA read/write, rx_drops, tx_pkts 등)를 실시간으로 수집할 수 있습니다. 수집된 메트릭은 헤드노드나 별도의 모니터링 노드에 설치된 Grafana 대시보드로 시각화하여 클러스터 전체의 네트워크 성능을 한눈에 파악할 수 있습니다. 또한 CloudWatch Alarms를 설정하여 성능 저하나 장애 발생 시 즉시 알림을 받을 수 있어, 대규모 분산 트레이닝 작업의 안정적인 운영이 가능합니다.
이러한 고려사항들을 종합적으로 적용하면, p5.48xlarge 인스턴스의 강력한 네트워크 성능을 최대한 활용하여 대규모 분산 트레이닝 워크로드를 효율적으로 실행할 수 있습니다.
p6-b300.48xlarge 인스턴스 EFA 구성 실전 가이드
p5.48xlarge에 이어, 2025년 출시된 p6-b300.48xlarge 인스턴스(NVIDIA B200 GPU 탑재)는 한 단계 더 진화한 네트워크 구성을 제공합니다. p6-b300.48xlarge은 17개의 네트워크 카드(1개 Primary + 16개 Secondary)를 탑재하며, EFA v4 기반으로 최대 6,400 Gbps의 EFA 대역폭과 최대 3,870 Gbps의 ENA 대역폭을 제공합니다.
p6-b300.48xlarge의 네트워크 카드 구성은 p5.48xlarge와 몇 가지 중요한 차이가 있습니다. Primary 카드(NCI 0)는 ENA 인터페이스만 지원하며 최대 350 Gbps의 대역폭을 제공합니다. Secondary 카드(NCI 1-16)는 각각 EFA 400 Gbps와 ENA 220 Gbps를 지원합니다. 한 가지 주의할 점은 EFA와 ENA 트래픽이 동일한 물리적 리소스를 공유한다는 것입니다. 한쪽의 대역폭 사용이 늘어나면 다른 쪽의 가용 대역폭이 줄어드는 구조입니다.
p6-b300.48xlarge은 워크로드 특성에 따라 두 가지 구성 방식을 선택할 수 있습니다.
Use Case 1은 IP 주소 절약 구성입니다. ML/AI 모델 학습이 주 목적이고 IP 주소 사용을 최소화하고 싶을 때 적합합니다. NCI 0은 ENA 인터페이스(350 Gbps)로, NCI 1-16은 모두 EFA-only 인터페이스(각 400 Gbps)로 구성합니다. 인스턴스당 IP 주소는 1개만 사용하면서도 EFA 6,400 Gbps의 최대 대역폭을 확보할 수 있습니다. ENA 대역폭은 Primary 카드의 350 Gbps만 사용 가능합니다.
Use Case 2는 최대 대역폭 구성입니다. EFA와 ENA 트래픽을 모두 많이 사용하는 워크로드, 또는 IP 주소 제약이 없는 환경에 적합합니다. NCI 0은 ENA 인터페이스(350 Gbps)로 구성하고, NCI 1-16은 각 카드에 EFA-only 인터페이스(DeviceIndex=0, 최대 400 Gbps)와 ENA 인터페이스(DeviceIndex=1, 최대 220 Gbps)를 별도로 생성합니다. 즉, 하나의 네트워크 카드에 2개의 개별 ENI를 할당하는 구조입니다. 인스턴스당 17(=16+1)개의 private IP를 사용하며, EFA는 최대 6,400 Gbps, ENA는 최대 3,870 Gbps(= 350 + 16×220 Gbps)까지 각각 활용할 수 있습니다. 다만 각 보조 카드 내에서 EFA와 ENA는 물리적 리소스를 공유하므로, 두 대역폭을 동시에 각각의 최대치로 사용하는 것은 불가능합니다.
대부분의 분산 트레이닝 워크로드에서는 Use Case 1이 권장됩니다. EFA 통신이 주를 이루는 환경에서는 IP 주소를 절약하면서도 최대 EFA 성능을 확보할 수 있기 때문입니다. Use Case 2는 EFA 통신과 함께 노드 간 대용량 데이터 전송(체크포인트 저장, 데이터 로딩 등)이 빈번하게 발생하는 환경에서 고려할 수 있습니다.
Use case 별 p6-b300.48xlarge인스턴스의 실제 EFA 상세 구성 내용은 다음 링크를 확인하시기 바랍니다.
맺음말
지금까지 ENI의 기본 개념부터 네트워크 카드와의 관계, ENI 할당 규칙, 그리고 p5.48xlarge와 p6-b300.48xlarge 인스턴스의 실제 EFA 구성 방법까지 살펴보았습니다.
이 블로그에서 가장 중요한 인사이트를 정리하면 다음과 같습니다.
첫째, ENI와 네트워크 카드는 다른 개념입니다. 네트워크 카드는 물리적 Nitro 카드를 소프트웨어가 논리적 인덱스(NetworkCardIndex)로 추상화한 것이고, ENI는 그 위에서 동작하는 가상 네트워크 인터페이스입니다. 이 두 계층의 분리가 AWS가 온프레미스의 고정적인 네트워크 구성과 달리 유연하고 세밀한 네트워크 제어를 가능하게 하는 핵심입니다.
둘째, 고성능 GPU 인스턴스에서 EFA 성능을 최대한 끌어내려면 단순히 EFA를 활성화하는 것만으로는 부족합니다. 네트워크 카드별로 ENI를 올바르게 할당하고, 관리 트래픽과 HPC 트래픽을 명확히 분리하며, 워크로드 특성에 맞는 구성 방식(EFA-only vs EFA with ENA)을 선택하는 것이 실질적인 성능 차이를 만들어냅니다.
셋째, p6-b300.48xlarge처럼 최신 인스턴스로 올수록 네트워크 카드 수를 줄이는 대신 카드당 대역폭을 대폭 늘리는 방향으로 설계가 진화하고 있습니다. 이는 더 적은 수의 고성능 Nitro 카드로 동일하거나 더 높은 총 대역폭을 달성하는 하드웨어 효율화 전략으로, 앞으로도 이 방향은 계속될 것입니다.
넷째, p6-b300.48xlarge에서 새롭게 도입된 EFA와 ENA의 물리적 리소스 공유 구조는 워크로드 특성에 따라 구성 방식을 신중하게 선택해야 함을 의미합니다. 분산 트레이닝이 주 목적이라면 EFA-only 구성(Use Case 1)으로 IP 주소를 절약하면서 최대 EFA 성능을 확보하는 것이 권장됩니다.
다음 블로그에서는 이렇게 구성된 EFA 네트워크 위에서 실제 GPU 간 통신이 어떻게 이루어지는지, 그 핵심에 있는 NCCL(NVIDIA Collective Communications Library)에 대해 소개할 예정입니다.