AWS 기술 블로그
Dedicated Log Volumes를 사용한 Amazon RDS for PostgreSQL의 벤치마크
이 글은 AWS Database Blog에 게시된 “Benchmark Amazon RDS for PostgreSQL with Dedicated Log Volumes”을 한국어 번역 및 편집하였습니다.
오늘날의 데이터 중심 환경에서 조직들은 성능 저하 없이 까다로운 워크로드를 처리할 수 있는 미션 크리티컬 데이터베이스를 확보해야 합니다. Amazon Relational Database Service(Amazon RDS)는 이러한 요구사항을 충족하는 비용 효율적이고 안정적이며 확장성이 뛰어난 관리형 서비스입니다.
PostgreSQL에서는 다른 많은 관계형 데이터베이스와 마찬가지로 트랜잭션이 별도의 WAL 세그먼트에 기록되기 전에 먼저 Write-Ahead Log(WAL) 버퍼에 로깅됩니다. 이 프로세스는 데이터 복구 및 복제에 매우 중요합니다. PostgreSQL 트랜잭션의 성능은 이러한 WAL 세그먼트가 저장되는 스토리지 시스템의 영향을 받습니다. 기본적으로 WAL을 포함한 모든 파일은 동일한 위치에 저장됩니다. 그러나 PostgreSQL 문서에서는 성능 향상을 위해 WAL을 별도의 스토리지에 배치하는 것을 권장합니다. “Amazon RDS 전용 로그 볼륨으로 데이터베이스 성능 향상” 포스트에서 자세히 설명된 바와 같이, Amazon은 고객이 WAL 세그먼트를 1,024 GiB의 고정 크기와 3,000 Provisioned IOPS를 가진 별도의 볼륨에 저장할 수 있도록 하는 Dedicated Log Volume(DLV) 기능을 도입했습니다.
DLV의 주요 장점 중 하나는 로그 쓰기를 더 크고 효율적인 IO 작업으로 그룹화하여 WAL의 전체 IOPS 요구량을 줄이는 쓰기 병합(write coalescing)을 가능하게 한다는 것입니다. 일반적인 스토리지 설정에서는 로그와 데이터 쓰기가 작고 빈번한 작업으로 혼재되어 있는 반면, DLV는 이들을 분리하여 로그를 더 큰 chunks로 쓸 수 있게 합니다. 이러한 분리는 처리량과 IO 효율성을 증가시켜 고성능 스토리지의 필요성을 줄이고 성능 저하 없이 비용을 절감할 수 있습니다.
이 포스트에서는 DLV(Dedicated Log Volume) 기능을 사용하여 Amazon RDS for PostgreSQL의 성능을 벤치마킹하는 과정을 안내합니다. 이를 위해 PostgreSQL 데이터베이스에서 벤치마크 테스트를 실행하는 도구인 pgbench를 사용합니다. pgbench는 여러 동시 데이터베이스 세션에서 정의된 SQL 명령 시퀀스를 반복적으로 실행합니다. 초당 트랜잭션 수로 측정되는 평균 트랜잭션 비율을 분석함으로써 RDS for PostgreSQL 배포의 성능 특성에 대한 귀중한 통찰력을 얻을 수 있습니다. 이를 통해Dedicated Log Volume(DLV) 기능이 활성화된 Amazon RDS for PostgreSQL과 그렇지 않은 경우의 성능을 직접 비교할 수 있습니다.
벤치마킹을 통해 DLV가 제공하는 성능 향상을 정량화하는 방법을 배우게 됩니다. 이제Dedicated Log Volume을 사용하는 Amazon RDS for PostgreSQL의 잠재력을 탐구해보겠습니다!
솔루션 개요
이 솔루션은 Amazon Elastic Compute Cloud(Amazon EC2)에서 벤치마킹 스크립트를 실행하는 것을 포함합니다. 이 스크립트는 하나는 DLV가 활성화되고 다른 하나는 DLV가 활성화되지 않은 두 개의 별도 RDS for PostgreSQL 인스턴스에 대해 성능을 테스트합니다.
다음 다이어그램은 고수준 아키텍처를 보여줍니다.
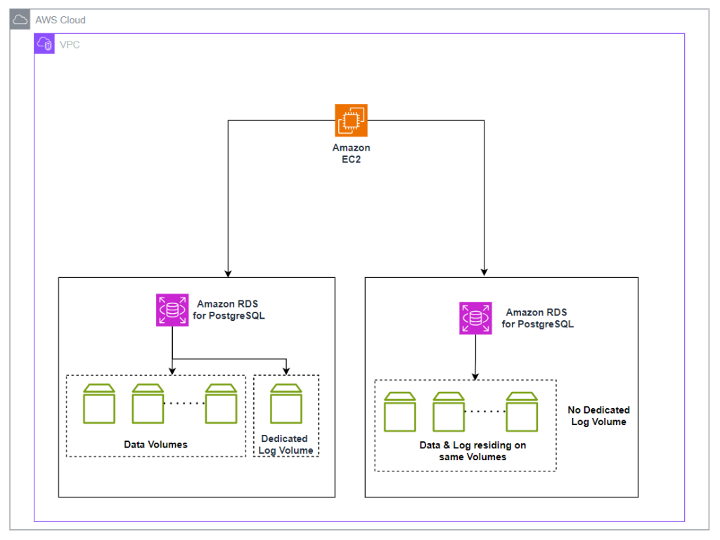
전제 조건
시작하기 전에 다음 전제 조건을 완료해야 합니다:
- Amazon EC2 Linux 인스턴스를 시작합니다. 네트워크 지연 시간을 최소화하기 위해 RDS 인스턴스와 동일한 Virtual Private Cloud(Amazon VPC)에서 인스턴스를 시작하는 것이 권장됩니다.
- EC2 인스턴스에
pgbench를 설치합니다. PostgreSQL 서버 설치 패키지에는 기본적으로pgbench유틸리티가 포함되어 있으므로, amazon extras 라이브러리에서 PostgreSQL을 설치할 수 있습니다. - Amazon RDS for PostgreSQL 인스턴스에 연결할 수 있는 psql 클라이언트가 필요합니다. 이전 단계의 PostgreSQL 서버 설치에도 기본적으로
psql클라이언트가 포함되어 있습니다. - DLV가 있는 것과 없는 것, 두 개의 Amazon RDS for PostgreSQL 인스턴스를 시작합니다.
인스턴스를 생성하려면 실제 AWS 리전과 AWS 계정 번호를 제공하여 다음 AWS Command Line Interface(AWS CLI) 명령을 사용하십시오. --dedicated-log-volume매개변수는 DLV 기능을 활성화하고, --no-dedicated-log-volume은 이를 비활성화합니다. 자세한 내용은 DB 인스턴스 생성 시 DLV 활성화를 참조하십시오. 다음 코드는 DLV가 있는 RDS for PostgreSQL 인스턴스를 생성합니다:
다음 코드는 DLV가 있는 RDS for PostgreSQL 인스턴스를 생성합니다:
--no-dedicated-log-volume 플래그는 인스턴스 생성 시 필요하지 않습니다. 인스턴스는 기본적으로 non-DLV로 생성되기 때문입니다. 다음 코드는 DLV가 없는 RDS for PostgreSQL 인스턴스를 생성합니다:
본 게시글 에서는 마스터 사용자 계정 비밀번호를 저장하기 위해 AWS Secrets Manager를 사용했습니다. RDS 인스턴스의 보안을 향상시키기 위해 Secrets Manager를 사용하는 방법에 대한 자세한 내용은 AWS Secrets Manager를 사용하여 Amazon RDS 마스터 데이터베이스 자격 증명의 보안 향상을 참조하십시오.
성능 벤치마킹
이 섹션에서는 DLV가 활성화된 RDS for PostgreSQL 인스턴스와 DLV가 없는 인스턴스 간의 성능을 비교하기 위해 실행한 벤치마크에 대해 논의합니다.
인프라스트럭처
다음 표는 벤치마킹 스크립트가 실행되는 EC2 인스턴스의 인프라를 요약합니다.
| Instance class | Operating System | vCPU | Memory (GiB) |
| r5.4xlarge | Amazon Linux 2023 | 16 | 128 |
다음 표는 각 RDS 인스턴스의 인프라를 요약합니다.
| Instance name | Instance class | vCPU | Memory (GiB) | Storage | Dedicated Log Volume |
| dlv | db.r5.16xlarge | 64 | 512 | IO2 (10,000 PIOPS) | On |
| withoutdlv | db.r5.16xlarge | 64 | 512 | IO2 (10,000 PIOPS) | Off |
데이터베이스 구성 파라미터
다른 관계형 데이터베이스 엔진과 마찬가지로 Amazon RDS for PostgreSQL의 성능은 데이터베이스 구성 매개변수에 직접적으로 영향을 받습니다. 커밋, 체크포인트, WAL 구성과 관련된 매개변수는 성능 평가에 필수적입니다. WAL에 대한 통계를 얻으려면 track_wal_io_timing 매개변수를 활성화해야 합니다. 테스트 전반에 걸쳐 Amazon RDS for PostgreSQL 15.5의 기본 매개변수가 사용되며, 다음은 주요 매개변수와 해당 설정의 목록입니다:
벤치마킹 스크립트
가장 정확한 성능 비교를 달성하기 위해 다음 스크립트를 사용하여 DLV와 non-DLV 인스턴스를 독립적으로 벤치마킹했습니다. 벤치마크 이전에 pg_stat_reset_shared 함수로 데이터베이스의 WAL 통계를 재설정하여 결과가 이전 활동이 아닌 특정 테스트 조건을 반영하도록 했습니다. 우리의 성능 평가는 pgbench도구를 사용하여 TPC-B와 유사한 워크로드를 생성했으며, 데이터 스케일(-s) 10,000에 대해 각각 50만 건의 트랜잭션을 처리하는 64개의 동시 클라이언트를 시뮬레이션 했습니다. TPC-B는 트랜잭션 처리량(초당 트랜잭션 수) 측정에 중점을 둔 널리 인정받는 업계 표준 벤치마크로, 서로 다른 데이터베이스 시스템의 성능을 비교하는 데 유용한 지표를 제공합니다.
다음은 스크립트입니다:
스크립트를 dlv_bm.sh라는 이름의 파일로 저장하고 실행 가능하게 만드십시오. 이 스크립트를 실행하려면 다음 명령을 사용하십시오. 필요에 따라 벤치마킹 매개변수를 조정할 수 있습니다:
- SCALE = 스케일 팩터, 즉 생성된 행 수에 스케일 팩터를 곱함
- NUM_TRANSACTIONS = 간격 내 트랜잭션 수
- NUM_CLIENTS = 동시 데이터베이스 세션 수
- NUM_THREADS = 워커 스레드 수
- AWS_ACCOUNT_ALIAS = AWS 계정 별칭
- AWS_REGION = 리소스가 위치한 리전
- DLV_INSTANCE = DLV가 있는 RDS 인스턴스 이름
- NON_DLV_INSTANCE = DLV가 없는 RDS 인스턴스 이름
예:
스크립트 완료 시 추가 분석을 위해 다음 세 개의 로그 파일이 생성됩니다:

비교를 위한 두 가지 주요 로그 파일은 dlv-blog-run-dlv-*.log와 dlv-blog-run-withoutdlv-*.log패턴을 가진 파일들입니다. 이들은 각각 Dedicated Log Volume이 활성화된 실행과 비활성화된 실행을 나타냅니다.
이 두 로그 파일에 대해 diff명령을 실행하면 pgbench에서 보고한 트랜잭션 성능 지표를 직접 비교할 수 있습니다.
예:
다음은 우리가 수행한 벤치마크 로그의 출력입니다:

DLV 모니터링
이 섹션에서는 DLV가 활성화된 RDS for PostgreSQL 인스턴스를 모니터링하는 다양한 기법을 탐구합니다.
Amazon CloudWatch를 사용한 DLV 모니터링
트랜잭션 로그(WAL)를 저장하는 DLV를 주시하는 것은 다른 데이터베이스 볼륨을 모니터링하는 것만큼 중요합니다. WAL 쓰기 속도가 트랜잭션 성능에 직접적으로 영향을 미치기 때문에 DLV의 IOPS, 지연 시간, 처리량을 모니터링하는 것은 전체 데이터베이스 성능을 이해하는 데 중요합니다. Amazon CloudWatch를 사용하여 이러한 지표를 모니터링할 수 있습니다. Amazon RDS 전용 로그 볼륨으로 데이터베이스 성능 향상 게시물에서 DLV 사용량 모니터링을 위한 관련 CloudWatch 지표를 보여줍니다.
PostgreSQL의 pg_stat_wal을 사용한 DLV 모니터링
CloudWatch 지표 외에도 버전 14 이후에서 사용 가능한 PostgreSQL 뷰 pg_stat_wal은 RDS for PostgreSQL 인스턴스에서 WAL 성능을 모니터링하는 데 도움이 될 수 있습니다. 이 뷰는 PostgreSQL의 누적 통계 시스템의 일부이며 WAL 활동에 대한 상세한 통계를 제공합니다.
성능 평가
데이터베이스 성능에 대한 DLV의 영향을 평가하기 위해 다음 지표를 검토했습니다:
- Runtime
- Transactions per second (TPS) and latency average recorded by pgbench
- PostgreSQL’s cumulative statistic, wal_sync_time and wal_write_time, captured from pg_stat_wal
- Graphs from Amazon RDS Performance Insights
런타임
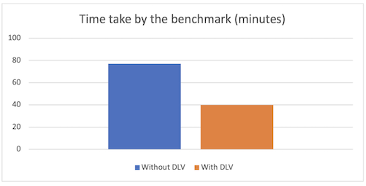
런타임은 pgbench를 사용하여 총 3,200만 건의 트랜잭션을 처리하는 데 필요한 기간을 나타내며, 각 클라이언트는 50만 건의 트랜잭션을 처리합니다. 런타임은 상당한 감소를 보였으며, DLV가 없는 인스턴스의 77분에서 DLV가 활성화된 인스턴스의 40분으로 거의 절반으로 줄어들었습니다. 이는 처리 시간에서 92.5%의 향상을 나타내며, DLV가 있는 인스턴스에 의해 구동되는 상당한 개선을 강조합니다.
| Metric | Without DLV | With DLV | % Improvement |
| Time taken by the benchmark (minutes) | 77 | 40 | 92.5% |
TPS 와 latency
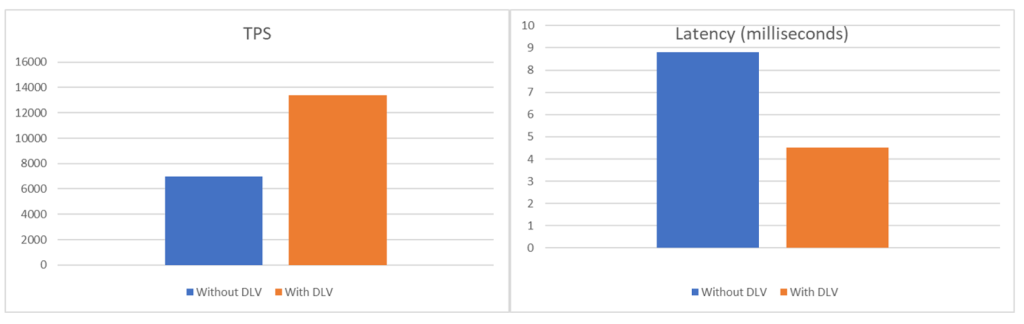
다음 표는 DLV가 활성화된 인스턴스의 성능 향상을 보여줍니다. TPS는 91.83% 증가하여 시스템의 트랜잭션 처리 용량이 거의 두 배가 되었습니다. 동시에 응답 시간의 척도인 지연 시간은 절반으로 줄어들어 95.56%의 향상을 보였습니다. 이러한 지연 시간 감소는 더 반응성이 좋고 효율적인 시스템으로 이어집니다. 전반적으로 DLV의 구현은 시스템 성능의 상당한 향상을 가져왔으며, 더 빠르고 더 많은 양의 작업을 처리할 수 있게 만들었습니다.
| Metric | Without DLV | With DLV | % Improvement |
| TPS | 6984 | 13397 | 91.83% |
| Latency average
(milliseconds) |
8.8 | 4.5 | 95.56% |
WAL 통계
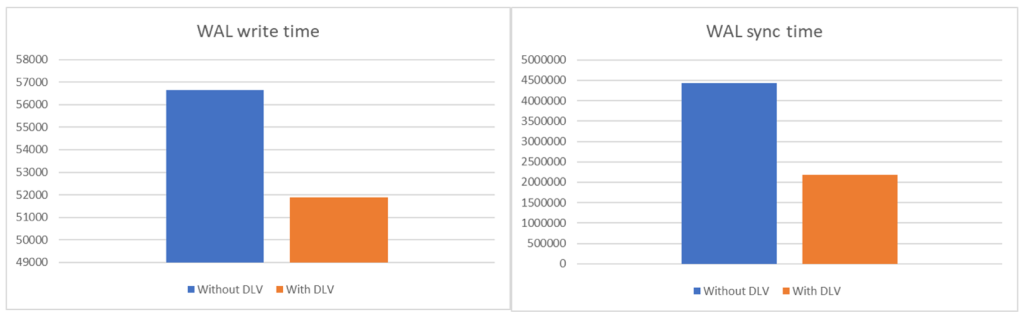
우리는 wal_write_time(WAL 버퍼를 디스크에 쓰는 데 소요된 총 시간)과 wal_sync_time(WAL 파일을 동기화하는 데 소요된 총 시간)과 같은 pg_stat_wal의 주요 WAL 통계를 면밀히 조사했습니다. DLV는 두 지표 모두에서 향상을 보였습니다: 우리 벤치마크에서 동기화 시간은 102.6%, 쓰기 시간은 9.2%의 개선을 보였습니다. 이는 더 빠른 트랜잭션 커밋과 전체 데이터베이스 응답성의 눈에 띄는 향상으로 이어지며, DLV를 트랜잭션이 많은 환경에서 PostgreSQL을 최적화하는 데 적합하게 만듭니다.
| Metric | Without DLV | With DLV | % Improvement |
| wal_write_time (milliseconds) | 56656.796 | 51882.614 | 9.2 |
| wal_sync_time (milliseconds) | 4431621.33 | 2186910.078 | 102.6 |
RDS Performance Insights
다음은 벤치마킹 기간 동안 RDS Performance Insights에서 캡처한 그래프입니다.
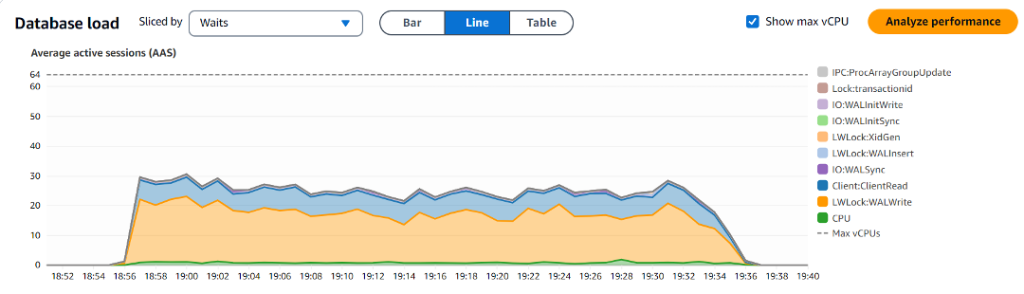
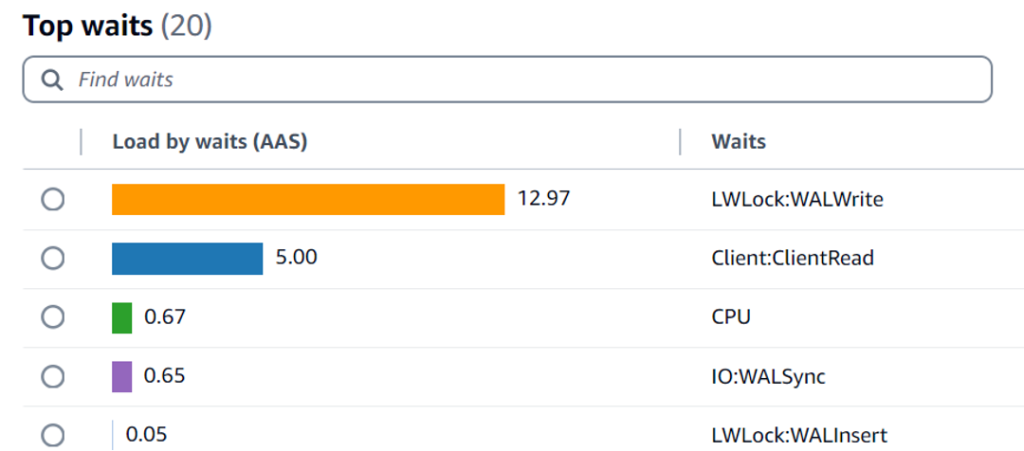
첫 번째 그래프는 DLV가 있는 상태에서의 데이터베이스 로드와 상위 대기를 보여줍니다.
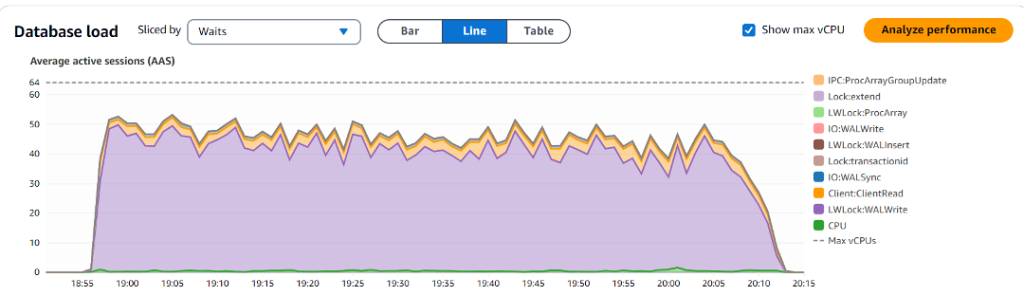
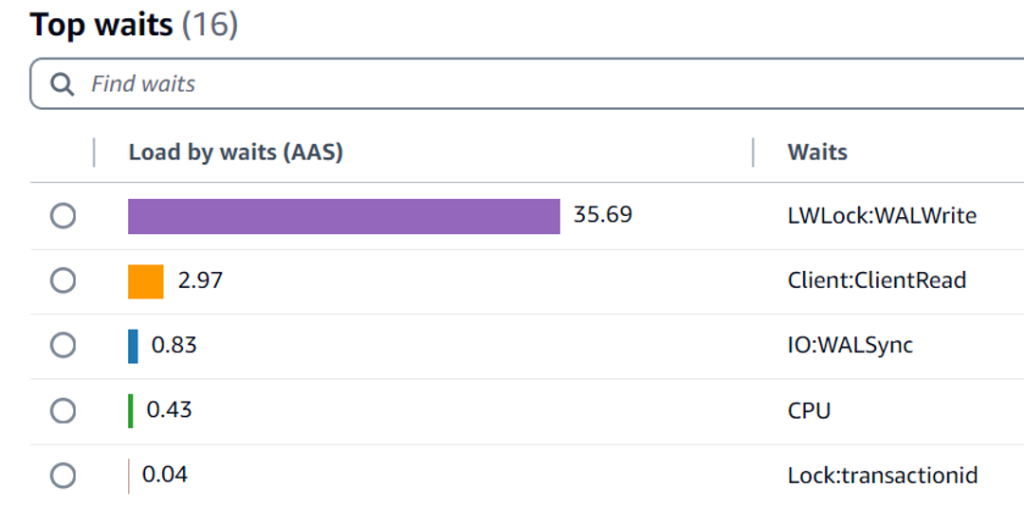
다음 그래프는 DLV가 없는 상태에서의 데이터베이스 로드와 상위 대기를 보여줍니다.
Performance Insights 데이터의 비교는 DLV와 non-DLV 인스턴스 간의 리소스 소비에서 상당한 차이가 드러났습니다. DLV가 활성화된 인스턴스는 지속적으로 더 낮은 평균 활성 세션 수를 보였으며, 이는 데이터베이스에 대한 전반적인 리소스 요구가 감소했음을 나타냅니다. 이러한 개선은 WAL 세그먼트 쓰기라는 까다로운 작업을 별도의 볼륨으로 오프로드하여 다른 작업을 위해 메인 데이터베이스 스토리지를 확보하는 DLV의 능력으로 인한 것입니다.
표준 RDS 인스턴스(DLV 없음)는 특히 경량 잠금(LWLock)과 관련된 대기 이벤트의 발생률이 더 높았습니다. 이는 종종 I/O 경합을 신호하며, 데이터베이스가 데이터 쓰기 요구를 따라잡기 위해 고군분투하고 있음을 나타냅니다. 반면, DLV가 활성화된 인스턴스는 이러한 대기 이벤트가 대폭 감소하여 더 효율적인 데이터 검색으로 이어졌습니다.
대기 세부사항은 다음과 같습니다:
- LWLock:WALWrite – 이 대기 이벤트는 DLV가 활성화된 인스턴스에서 (AAS의 12.97%) non-DLV 인스턴스(AAS의 35.69%)에 비해 상당히 낮았으며, WAL 관련 병목 현상을 완화하는 DLV의 효과를 강조합니다.
- IO:WALSync – 이 대기 이벤트는 non-DLV 인스턴스에서 AAS의 0.83%로 DLV 인스턴스의 0.65%에 비해 더 높았습니다. 덜 눈에 띄지만, 이 대기 이벤트는 여전히 non-DLV 인스턴스에서 약간 더 높았으며, WAL 쓰기 성능 향상에서 DLV의 역할을 더욱 뒷받침합니다.
벤치마킹 결과는 WAL 관련 대기 이벤트를 완화하는 DLV의 효과를 확인했으며, 이는 의도된 기능과 일치합니다. 이러한 검증은 WAL 쓰기를 오프로드하여 향상된 데이터베이스 성능으로 이어지는 DLV의 성공을 보여줍니다.
정리
이 솔루션을 테스트하는 경우 리소스를 제거하고 요금을 피하기 위해 다음 단계를 완료하십시오:
- Amazon EC2 콘솔에서 Linux EC2 인스턴스를 선택하고 Instance state 메뉴에서 Terminate instance를 선택합니다.
- Amazon RDS 콘솔에서 RDS for PostgreSQL 인스턴스를 선택하고 Actions 메뉴에서 Delete를 선택합니다.
결론
이 게시물에서는 DLV가 향상된 쓰기 성능으로 RDS 데이터베이스를 강화하여 쓰기 집약적 워크로드에서 흔한 병목 현상인 WAL 경합을 줄이는 방법을 보여주었습니다. WAL 쓰기를 전용 볼륨으로 오프로드 함으로써 DLV는 메인 데이터베이스 리소스를 확보하여 더 원활한 데이터 액세스와 전반적인 응답성 향상을 가능하게 합니다. 이는 더 빠른 쓰기 작업, 지연 시간 감소, 더 효율적인 데이터베이스 환경으로 이어지며, 이는 일관된 고성능을 요구하는 애플리케이션에 특히 중요합니다.
또한 DLV는 WAL 활동을 격리하여 스토리지 병목 현상을 완화하고, 중요한 쓰기 작업이 다른 데이터베이스 프로세스에 의해 방해받지 않도록 보장합니다. 이는 높은 부하 상황에서도 더 안정적이고 예측 가능한 성능을 제공합니다. RDS 워크로드가 빈번한 쓰기를 포함하거나 낮은 지연 시간의 트랜잭션을 요구하는 경우, DLV를 활성화하는 것은 데이터베이스의 잠재력을 최대한 활용하고 부하 상황에서 최적의 성능을 달성하기 위한 전략적 선택입니다.
DLV는 PIOPS 스토리지 유형(io1 및 io2 Block Express)과 호환되며 1,024 GiB의 고정 크기와 3,000 Provisioned IOPS로 프로비저닝됩니다. 모든 리전에서 Amazon RDS for PostgreSQL 버전 13.10 이상, 14.7 이상, 15.2 이상에서 지원됩니다.