AWS 기술 블로그
Strands와 AgentCore를 활용해 Amazon RDS for SQL Server용 에이전틱 AI 구축하기
이 글은 AWS Database Blog의 “Building agentic AI for Amazon RDS for SQL Server with Strands and AgentCore” by Sudhir Amin 게시글을 번역한 글입니다.
Amazon Relational Database Service (Amazon RDS) for SQL Server 인스턴스를 관리한다면, 수년에 걸쳐 진단 스크립트들을 축적했을 것입니다. 이 스크립트들은 blocking 세션을 조회하고, 느린 프로시저를 식별하며, 디스크 공간을 모니터링하고, 인덱스 사용량을 분석합니다. 이는 수년간의 데이터베이스 트러블슈팅 경험을 통해 축적되었거나, 심야/긴급 장애 대응의 결과로 만들어진 경우도 많을 것입니다. 이제 이러한 스크립트들은 지속적으로 작동하는 AI 에이전트의 기반이 될 수 있습니다. Amazon Bedrock AgentCore Runtime과 Strands Agents를 사용하면 기존 T-SQL 지식을 자율적인 데이터베이스 관리 시스템으로 전환할 수 있습니다. AI 모델을 목적에 맞게 구축된 AI 에이전트와 결합하면, 컨텍스트를 이해하고, 근거 있는 판단을 내리며, 복잡한 작업을 자율적으로 실행하는 에이전트를 만들 수 있습니다.
이 글에서는 Amazon RDS for SQL Server에서 Blocking과 Deadlock을 조사하는 에이전트 구축 과정을 안내합니다. 이 두 가지 문제는 애플리케이션 성능에 직접적인 영향을 미치고, 트랜잭션 실패를 야기하며, 타임아웃을 발생시킵니다. Strands Agents 프레임워크를 사용하여 DBA가 이러한 조사에 사용하던 T-SQL 쿼리를 에이전트 도구로 변환하고, 이를 단일 에이전트로 결합한 후 AgentCore Runtime에 배포합니다.
먼저 에이전트와 툴이 무엇인지 설명하고, 일반적인 DBA 시나리오를 통해 툴이 이를 어떻게 해결하는지 살펴보겠습니다. 그런 다음 툴을 구축하고, 시스템 프롬프트로 에이전트를 정의하며, AgentCore Runtime에 배포합니다.
에이전트란?
에이전트는 AI를 사용하여 추론하고 계획하며, 사람이나 시스템을 대신해 작업을 완료하는 소프트웨어 시스템입니다. 데이터베이스 운영에서 에이전트는 질문이나 알람 페이로드를 받아 호출할 툴을 결정하고 이를 실행하며, 결과를 해석하여 진단합니다. Strands Agents 프레임워크에 대한 자세한 내용은 Introducing Strands Agents: An Open Source AI Agents SDK를 참조하세요.
모든 Strands 에이전트의 핵심에는 에이전트 루프가 있습니다. AI 서비스를 호출하고, 호출할 툴을 결정하고, 툴을 실행한 다음 결과와 함께 서비스를 다시 호출합니다. 이 사이클은 모델이 최종 응답을 생성할 때까지 반복됩니다.
각 이터레이션은 채팅 히스토리에 추가됩니다. 에이전트는 원본 요청뿐만 아니라, 호출한 툴과 받은 결과 모두를 추적합니다. 이렇게 축적된 컨텍스트 덕분에 다단계 추론이 가능해집니다. 예를 들어, 에이전트는 Deadlock을 확인한 다음 Blocking 체인을 분석하고, 두 결과를 연관시켜 진단을 내릴 수 있습니다.
툴이란?
에이전트의 추론 방법에 이어, 에이전트가 사용하는 구성 요소를 살펴보겠습니다. 에이전틱 AI 시스템에서 툴은 에이전트가 외부 시스템과 상호 작용하거나, 데이터를 검색하거나, 작업을 수행하기 위해 호출할 수 있는 함수입니다. 툴 덕분에 에이전트는 텍스트 생성을 넘어, 그 이상의 기능까지 수행할 수 있게 됩니다. 데이터베이스 쿼리, API 호출, 시스템 모니터링, 알림 전송 등이 그 예입니다. 툴은 에이전트의 추론 능력과 현실 세계 사이의 다리 역할을 합니다.
Strands에서 도구는 @tool 데코레이터가 적용된 Python 함수입니다. 함수의 docstring은 에이전트에게 이 툴을 언제, 왜 호출해야 하는지 알려줍니다. 에이전트는 툴의 docstring을 읽고 사용자의 질문과 매칭시켜, 이 함수를 호출할지 결정합니다. 즉, DBA가 이미 사용하는 진단 스크립트를 Python 함수로 래핑하고 @tool 데코레이터를 붙이면, 에이전트를 위한 툴로 만들 수 있음을 의미합니다.
@tool 데코레이터는 함수를 에이전트에 등록합니다. 타입 힌트는 입력/출력 스키마를 정의하고 docstring은 에이전트가 이 툴을 언제 호출할지 결정하는 데 사용되므로, 이들을 런북 항목처럼 작성하는 것을 권장합니다.
일반적인 DBA 시나리오
에이전트와 툴을 정의했으니, 해결하고자 하는 구체적인 데이터베이스 문제들을 살펴보겠습니다.
Deadlock(교착 상태). Deadlock이 발생하면 관련된 세션들, 각 세션이 실행하고 있던 SQL 문, 경합 중인 락 유형과 객체, 그리고 희생자 세션을 식별해야 합니다. Amazon RDS for SQL Server에서 Deadlock 정보는 두 가지 방법으로 캡처됩니다.
- Trace flag 1204 및 1222 — 이 플래그들은 교착 상태 세부 정보를 SQL Server 오류 로그에 기록합니다. 플래그는 사용자 정의 DB 파라미터 그룹을 통해 활성화할 수 있으며, 오류 로그는 Amazon CloudWatch Logs에 게시할 수 있습니다. 설정 단계는 Monitor deadlocks in Amazon RDS for SQL Server를 참조하세요.
- system_health Extended Event 세션 — 이 내장 세션은 기본적으로
xml_deadlock_report이벤트를 통해 Deadlock 그래프를 캡처합니다. SQL 문, 잠금 유형, 객체를 포함한 Deadlock의 양 측면이 모두D:\rdsdbdata\log의 XE 파일에 기록됩니다.
Blocking(차단). 애플리케이션이 타임아웃을 보고할 때에는, Head Blocker(헤드 블로커, Blocking 체인의 루트에 있는 세션)와 해당 SQL 문, 그 뒤에서 대기 중인 세션 수, 그리고 얼마나 오래 대기하고 있는지를 찾아야 합니다. RDS for SQL Server에서는, 필요한 정보의 세부 수준에 따라 캡처하는 방법이 다릅니다.
- 현재 Blocking — DMV
sys.dm_exec_requests와sys.dm_exec_sql_text는 블로커와 차단된 세션 ID, 대기 유형, SQL 텍스트를 포함한 현재 Blocking 상태를 제공합니다. 이 데이터는 추가 구성 없이도 사용할 수 있습니다. - 과거 Blocking (차단된 세션만) — system_health 세션은
wait_info이벤트를 통해 30초를 초과하는 락 대기를 캡처합니다. 이는 차단된 세션의 ID와 SQL 텍스트를 기록하지만, 블로커가 어떤 세션인지는 기록하지 않습니다. CloudWatch Logs에는 system_health 데이터가 포함되지 않으며, SQL Server 오류 로그만 수신합니다. - 과거 Blocking (양쪽 모두) — 사후에 블로커와 차단된 세션을 모두 캡처하려면, DB 파라미터 그룹에서
blocked process threshold를 설정하고blocked_process_report에 대한 사용자 정의 Extended Event 세션을 생성하세요. system_health 세션은 이 이벤트를 캡처하지 않습니다. 구성 세부 사항은 Using extended events with Amazon RDS for Microsoft SQL Server를 참조하세요.
툴로 해결하기
이제 각 시나리오를 에이전트가 호출할 수 있는 툴에 매핑해 보겠습니다.
| 툴 | 기능 | 데이터 소스 |
|---|---|---|
get_deadlock_graphs |
전체 세부 정보가 포함된 Deadlock 그래프 읽기 | system_health Extended Event(XE) 파일 (xml_deadlock_report) |
get_blocking_chains |
현재 Blocking 계층 구조를 탐색하여, Head Blocker와 해당 SQL 식별 | DMV (sys.dm_exec_requests, sys.dm_exec_sql_text) |
get_session_details |
특정 세션의 로그인, 호스트, 프로그램, SQL 검색 | DMV (sys.dm_exec_sessions) |
send_diagnostic_report |
에이전트의 발견 및 권장 사항을 DBA 팀에 전송 | Amazon SNS |
get_blocked_process_reports |
Blocker와 Blocked 세션 모두를 포함한 과거 Blocking 세부 정보 읽기 | 사용자 정의 XE 세션 (blocked_process_report) |
툴 코드
이제 툴이 Python 코드로 어떻게 변환되는지 살펴보겠습니다. 각 툴은 Strands @tool 데코레이터를 사용하여 기존 SQL Server 진단 쿼리를 래핑합니다.
툴들은 AWS Secrets Manager에서 자격 증명을 검색하는 연결 헬퍼를 공유합니다.
Deadlock 탐지. system_health XE 파일에서 Deadlock 그래프를 읽습니다.
Blocking 체인 분석. 재귀 CTE를 사용하여 Blocking 계층 구조를 탐색합니다.
세션 세부 정보. 특정 세션의 컨텍스트를 검색합니다.
진단 보고서. SNS를 통해 발견 사항을 전송합니다.
과거 차단된 프로세스 보고서. 사용자 정의 XE 세션에서 블로커와 차단된 세션 세부 정보를 읽습니다. DB 파라미터 그룹에 설정된 blocked process threshold와 파일 대상으로 blocked_process_report를 캡처하는 사용자 정의 Extended Event 세션이 필요합니다. 세션 생성에 대해서는 Using extended events with Amazon RDS for Microsoft SQL Server를 참조하세요.
참고: 모든 코드 예제는 SQL Injection을 방지하기 위해 매개변수화된 쿼리(%s 플레이스홀더)를 사용합니다.
에이전트 정의: 시스템 프롬프트와 툴
툴을 구축했으니, 이제 에이전트 자체를 정의합니다. 시스템 프롬프트는 에이전트가 문제를 어떻게 추론하는지 정의하고, 툴 목록은 사용 가능한 기능을 알려줍니다.
솔루션 워크플로우
아래 세 가지 주요 기술을 통합하여 이 변환의 핵심을 구성합니다.
- Strands 에이전트 & 툴 — 기존 T-SQL 전문 지식을 ‘데이터베이스 상태에 대해 추론하고 자동으로 응답을 실행하는 지능형 에이전트’로 래핑합니다.
- AgentCore Runtime — 내장된 스케일링과 observability를 갖춘 VPC에 에이전트를 안전하게 배포합니다.
- AgentCore Memory — 세션 간에 발견 사항을 유지하여 에이전트가 과거 조사에서 학습할 수 있도록 합니다.
다음 다이어그램은 운영자 프롬프트에서 진단 보고서까지의 엔드투엔드(E2E) 워크플로를 보여줍니다.
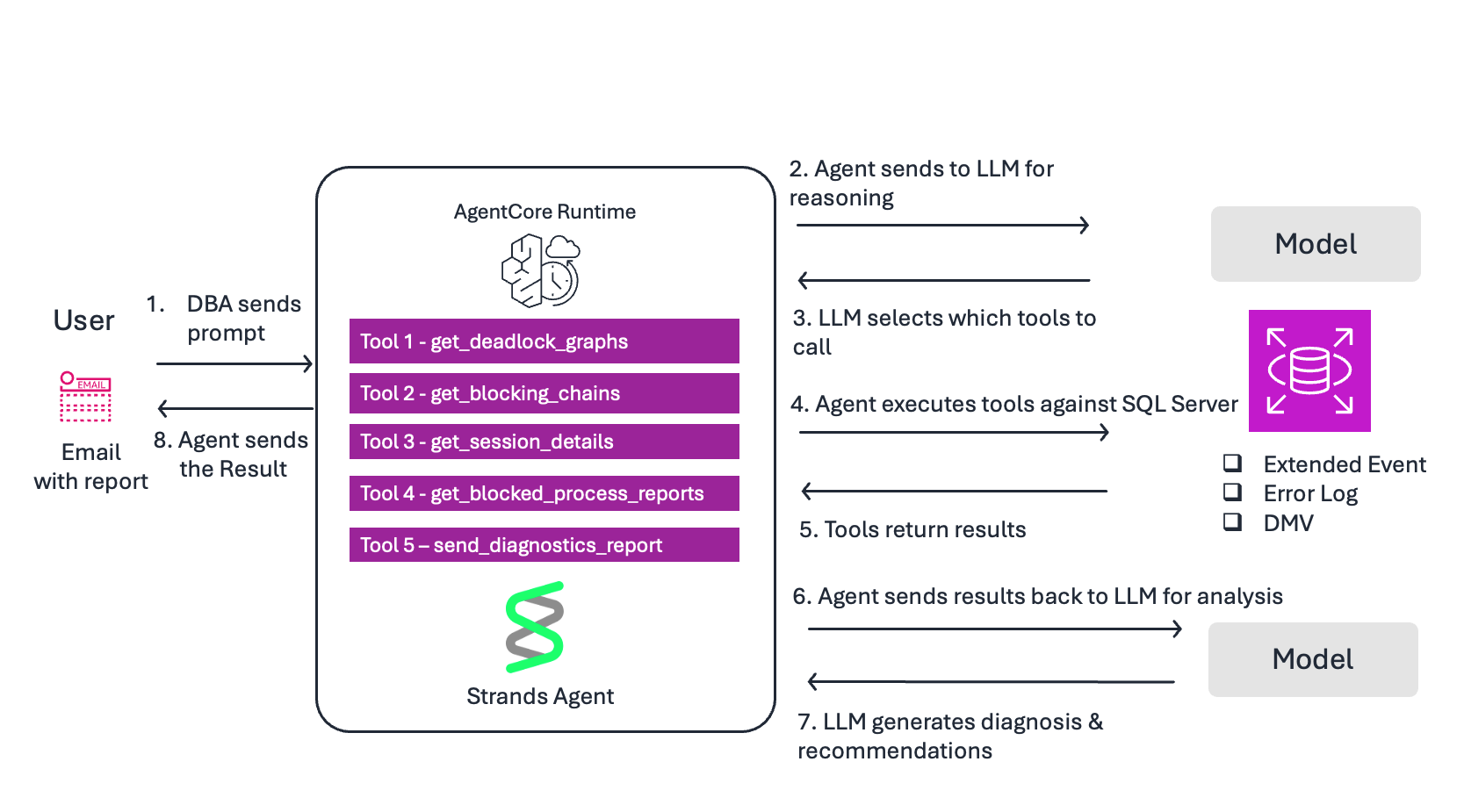
흐름:
- DBA가 프롬프트를 전송 — “지난 24시간 동안의 Deadlock을 확인하고 SNS를 통해 진단 보고서를 전송하세요”.
- 에이전트가 추론을 위해 LLM에 전송 — 모델이 프롬프트와 시스템 프롬프트를 읽어 작업을 이해합니다.
- LLM의 툴 선택 — docstring을 기반으로 먼저
get_deadlock_graphs툴을 호출하기로 결정합니다. - 에이전트의 툴 실행 — Amazon RDS for SQL Server의 system_health XE 파일에서
xml_deadlock_report이벤트를 쿼리합니다. - 툴 결과 반환 — 세션 ID, SQL 문, 락 유형, 객체가 포함된 Deadlock 그래프.
- 에이전트가 결과를 LLM에 전송하여 분석 — 모델이 raw Deadlock XML을 해석하고 근본 원인을 식별합니다.
- LLM 응답 생성 — 심각도, 근본 원인, 영향받은 쿼리, 해결 단계가 포함된 진단을 생성합니다. SNS를 통해 발견 사항을 전달하기 위해
send_diagnostic_report툴을 호출하기로 결정합니다. - 에이전트가 DBA에게 응답 반환 — DBA는 인라인 응답과 전체 진단 보고서가 포함된 이메일을 받습니다.
AgentCore Runtime에 배포하기
에이전트를 정의했으며, 툴이 준비되었습니다. 에이전트 구현, IAM 정책, 배포 지침을 포함한 전체 소스 코드는 GitHub에서 확인할 수 있습니다. An AI Agent for Deadlock Analysis on Amazon RDS for SQL Server를 참조하세요.
AgentCore Runtime에서 실행하는 과정을 살펴보겠습니다.
사전 요구사항
실행을 위해서는 다음 리소스가 필요합니다. 기존 리소스를 사용하거나 새로 생성할 수 있습니다. 각 리소스는 배포 중에 사용되는 환경 변수에 매핑됩니다.
Amazon RDS for SQL Server
DB_INSTANCE_ID— RDS for SQL Server 인스턴스 (Standard 또는 Enterprise Edition)- 사용자 정의 DB 파라미터 그룹을 통해 활성화된 Trace flag 1204와 1222. Monitor deadlocks in Amazon RDS for SQL Server를 참조하세요.
- 과거 Blocking 캡처를 위한
blocked_process_report용 사용자 정의 Extended Event 세션. Using extended events with Amazon RDS for Microsoft SQL Server를 참조하세요. DB_SECRET_ID— 전용 최소 권한 데이터베이스 로그인을 포함하는 AWS Secrets Manager에 저장된 데이터베이스 자격 증명SNS_TOPIC_NAME— 활성 구독이 있는 Amazon Simple Notification Service (Amazon SNS) 토픽
Amazon Bedrock AgentCore
AWS_REGION— 해당 AWS 리전에서 활성화된 Amazon Bedrock 파운데이션 모델에 대한 액세스AGENTCORE_ROLE_ARN— Bedrock, Secrets Manager, SNS, CloudWatch Logs에 대한 권한이 있는 IAM Role(역할). AgentCore Runtime 권한을 참조하세요.SUBNET1, SUBNET2, SECURITY_GROUP_ID— 프라이빗 서브넷과 1433 포트에서 RDS로의 아웃바운드 트래픽을 허용하는 보안 그룹이 있는 VPC. AgentCore VPC 구성을 참조하세요.
개발 환경
- Python 3.10 이상
- 적절한 권한으로 구성된 AWS Command Line Interface (AWS CLI)
1단계: 클론 및 설치
2단계: 환경 변수 설정
배포를 위해 다음 환경 변수를 설정하세요. 이는 전제 조건에서 생성된 리소스를 참조합니다:
3단계: 구성 및 배포
AgentCore CLI를 사용하여 에이전트를 VPC에 구성하고 배포합니다.
4단계: 배포된 에이전트 테스트
먼저 두 개의 테이블(##Employees와 ##Suppliers)을 생성하고 반대 순서로 업데이트하는 두 개의 동시 트랜잭션을 실행하여 Deadlock을 시뮬레이션합니다. 세션 1은 ##Employees를 먼저 업데이트한 다음 ##Suppliers를 업데이트하고, 세션 2는 ##Suppliers를 먼저 업데이트한 다음 ##Employees를 업데이트합니다. 이로 인해 SQL Server가 하나의 트랜잭션을 종료하여 해결하는 락 순서에 충돌이 발생합니다. Testing with a simulated deadlock의 단계를 따르세요.
그런 다음 에이전트를 호출합니다:
에이전트는 system_health에서 Deadlock 그래프를 읽고, 두 세션과 해당 SQL 문을 식별하며, 활성 Blocking 체인과 상관 분석합니다. 그 후 근본 원인 분석 및 해결 단계가 포함된 진단 보고서를 SNS를 통해 전송합니다.
모범 사례
세션 간 메모리. 메모리가 없으면 모든 호출이 처음부터 시작됩니다. AgentCore Memory를 사용하면, 두 가지 보완적인 시스템을 통해 세션 간 발견 사항을 유지할 수 있습니다: 단기 메모리(STM)는 세션 연속성을 위해 원시 대화 이벤트를 저장하고, 장기 메모리(LTM)는 여러 호출에 걸쳐 유지되는 인사이트를 추출합니다.
LTM은 여러 추출 전략을 지원합니다. 의미론적(semantic) 전략은 시간이 지나도 관련성이 유지되는 사실을 캡처합니다: “반대 잠금 순서로 인한 Employees와 Suppliers 업데이트 간의 반복적인 Deadlock.” 요약(summary) 전략은 조사 세션을 요약합니다: “조사 결과 ##Employees와 ##Suppliers 테이블과 관련된 6건의 Deadlock과 인덱스 리빌드로 인한 14개 세션 Blocking 체인 발견.” 현재 CPU 사용률과 같은 일시적인 메트릭은 자동으로 제외하며, 지속적인 패턴만 유지합니다.
두 전략을 모두 사용하여 메모리 리소스를 생성합니다.
메모리 통합에는 agent.py에 대한 코드 변경이 필요합니다. AgentCoreMemorySessionManager를 세션 관리자로 추가합니다. 전체 예제는 agent_with_memory.py를 참조하세요.
- 월요일에는 에이전트가
##Employees와##Suppliers테이블의 반대 잠금 순서 업데이트와 관련된 6건의 Deadlock을 발견하고, SNS를 통해 진단 보고서를 전송합니다. - 화요일에는 DBA가 에이전트의 권장 사항을 기반으로 잠금 순서 수정을 배포합니다.
- 수요일에 알람이 다시 발생합니다. 에이전트는 메모리에서 월요일의 발견 사항을 회상하고, 새로운 조사를 실행하여 비교합니다. “Employees/Suppliers 교착 상태 패턴이 중지되었습니다. 다른 테이블 간에 새로운 Deadlock이 감지되었습니다.”
관찰 가능성(Observability)
관찰 가능성을 활성화하려면,
requirements.txt파일에 aws-opentelemetry-distro를 추가하세요.- 배포 중에 환경 변수
AGENT_OBSERVABILITY_ENABLED=true를 설정하세요. - AgentCore가 자동으로 트레이스, 토큰 사용량, 요청 지속 시간을 계측합니다.
- 코드 변경이 필요하지 않습니다.
- CloudWatch GenAI Observability 대시보드에서 메트릭을 확인합니다.
추가 툴 확장
동일한 @tool 패턴을 다른 진단 스크립트에도 적용할 수 있습니다.
- Query Store를 통한 느린 쿼리 분석
sys.dm_db_missing_index_details의 인덱스 권장 사항- TempDB 문제 해결
Strands는 Model Context Protocol (MCP)도 지원하므로, 에이전트가 외부 툴 서버에 연결하고 에이전트 코드를 수정하지 않고도 기능을 확장할 수 있습니다.
핵심 요약
- system_health Extended Event 세션은 기본적으로 Deadlock 그래프를 캡처합니다. 에이전트는 이를 읽고 근본 원인 분석을 제공합니다.
- Blocking 체인 분석은 DMV를 사용하여 Head Blocker와 해당 SQL을 식별합니다. 과거 Blocker를 확인하려면
blocked process threshold와 사용자 정의 Extended Event 세션이 필요합니다. @tool데코레이터는 기존 T-SQL 쿼리를 LLM에 연결합니다. docstring이 에이전트가 각 툴을 언제 호출할지 결정합니다.- 데이터 소스 간의 상관 분석 — Deadlock을 트랜잭션 오류에 연결하고 Blocking을 타임아웃에 연결하는 것 — 이것이 에이전트를 단순 스크립트와 차별화하는 부분입니다.
- Strands Agents는 툴 프레임워크를 제공하고, AgentCore Runtime은 관리형 배포를 제공하며, 이들이 함께 기존 T-SQL 전문 지식을 프로덕션 준비된 에이전트로 전환합니다.
- 집중적이고(한 가지를 잘 수행), 효율적이며(필요한 데이터만 반환), 안정적이고(오류를 우아하게 처리), 빠르며(신속하게 실행), 명확한(잘 문서화된) 툴을 설계하세요. 좋은 툴 설계가 에이전트를 효과적으로 만드는 요소입니다.
정리
리소스를 정리하려면 다음 단계를 완료하세요:
- Amazon RDS 콘솔의 탐색 창에서 데이터베이스를 선택합니다.
- 삭제할 DB 인스턴스를 선택합니다.
- Actions 메뉴에서 삭제를 선택합니다.
- 삭제를 확인하기 위해
delete me를 입력한 다음 삭제를 선택합니다. - 최종 스냅샷 생성 및 자동 백업 유지 여부를 묻는 메시지가 표시되면, 필요에 따라 옵션을 선택합니다.
AgentCore Runtime 리소스를 삭제하려면:
AgentCore Memory 리소스를 삭제하려면:
결론
이 글에서는 Strands Agents와 Amazon Bedrock AgentCore를 사용하여 기존 T-SQL 진단 스크립트를 AI 기반 데이터베이스 운영 에이전트로 변환하는 방법을 다루었습니다. 에이전트는 Amazon RDS for SQL Server에서 Deadlock과 Blocking을 조사하고, 데이터 소스 간의 발견 사항을 상관 분석하며, 수동 개입 없이 실행 가능한 권장 사항을 제공합니다.
시작하려면 샘플 저장소를 복제하고 자신의 RDS for SQL Server 인스턴스에 에이전트를 배포하세요. Query Store 분석, 인덱스 권장 사항, TempDB 문제 해결과 같은 가장 일반적인 진단 워크플로우를 위한 추가 툴로 확장해 보실 수 있습니다.